One Sense Per Discourse
Full text
Figure
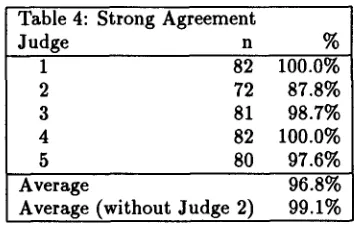
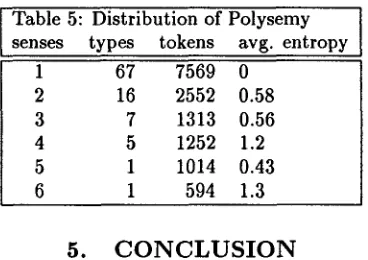
Related documents
Wang et al EURASIP Journal on Advances in Signal Processing 2013, 2013 119 http //asp eurasipjournals com/content/2013/1/119 RESEARCH Open Access Counteracting geometrical attacks on
The aim of this study was therefore to investigate the prevalence of musculoskeletal disorders (MSD), including pain and medically diagnosed injuries and self-perceived health, in
Background: We compared the functional outcome between conventional and high-flexion total knee arthroplasty (TKA) using kneeling and sit-to-stand tests at 1 year post-operative..
Thus our authors close their studies of England from the Conquest to the Magna Carta, expressing the most provocative views on the legal history of that period in
GPRS module can be used to monitor and con- trol the appliances of multiple devices like lights, fans, coolers etc using predefined weblink. The project can also be extended
In recent years, the electrical power generation from renewable energy sources, such as wind, is increasingly attraction interest because of environmen- tal problem and shortage
In reading the parable through the lens of patronage and clientism and against the background of the relationship between royal ideology and debt release attested in
