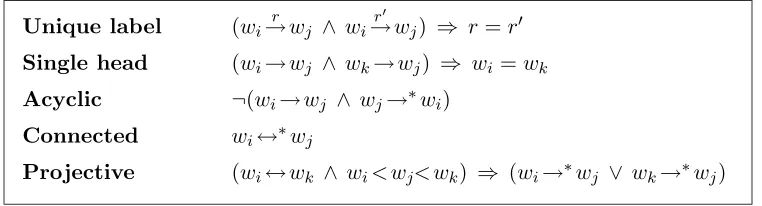Incrementality in Deterministic Dependency Parsing
Joakim NivreSchool of Mathematics and Systems Engineering V¨axj¨o University
SE-35195 V¨axj¨o Sweden
Abstract
Deterministic dependency parsing is a robust and efficient approach to syntactic parsing of unrestricted natural language text. In this pa-per, we analyze its potential for incremental processing and conclude that strict incremen-tality is not achievable within this framework. However, we also show that it is possible to min-imize the number of structures that require non-incremental processing by choosing an optimal parsing algorithm. This claim is substantiated with experimental evidence showing that the al-gorithm achieves incremental parsing for 68.9% of the input when tested on a random sample of Swedish text. When restricted to sentences that are accepted by the parser, the degree of incrementality increases to 87.9%.
1 Introduction
Incrementality in parsing has been advocated for at least two different reasons. The first is mainly practical and has to do with real-time applications such as speech recognition, which require a continually updated analysis of the in-put received so far. The second reason is more theoretical in that it connects parsing to cog-nitive modeling, where there is psycholinguis-tic evidence suggesting that human parsing is largely incremental (Marslen-Wilson, 1973; Fra-zier, 1987).
However, most state-of-the-art parsing meth-ods today do not adhere to the principle of in-crementality, for different reasons. Parsers that attempt to disambiguate the input completely — full parsing — typically first employ some kind of dynamic programming algorithm to de-rive a packed parse forest and then applies a probabilistic top-down model in order to select the most probable analysis (Collins, 1997; Char-niak, 2000). Since the first step is essentially nondeterministic, this seems to rule out incre-mentality at least in a strict sense. By contrast,
parsers that only partially disambiguate the in-put — partial parsing — are usually determin-istic and construct the final analysis in one pass over the input (Abney, 1991; Daelemans et al., 1999). But since they normally output a se-quence of unconnected phrases or chunks, they fail to satisfy the constraint of incrementality for a different reason.
Deterministic dependency parsing has re-cently been proposed as a robust and effi-cient method for syntactic parsing of unre-stricted natural language text (Yamada and Matsumoto, 2003; Nivre, 2003). In some ways, this approach can be seen as a compromise be-tween traditional full and partial parsing. Es-sentially, it is a kind of full parsing in that the goal is to build a complete syntactic analysis for the input string, not just identify major con-stituents. But it resembles partial parsing in being robust, efficient and deterministic. Taken together, these properties seem to make de-pendency parsing suitable for incremental pro-cessing, although existing implementations nor-mally do not satisfy this constraint. For exam-ple, Yamada and Matsumoto (2003) use a multi-pass bottom-up algorithm, combined with sup-port vector machines, in a way that does not result in incremental processing.
In this paper, we analyze the constraints on incrementality in deterministic dependency parsing and argue that strict incrementality is not achievable. We then analyze the algorithm proposed in Nivre (2003) and show that, given the previous result, this algorithm is optimal from the point of view of incrementality. Fi-nally, we evaluate experimentally the degree of incrementality achieved with the algorithm in practical parsing.
2 Dependency Parsing
PP P˚a (In
?
adv
NN 60-talet the-60’s
?
pr
VB m˚alade painted
PN han he
?
sub
JJ dj¨arva
bold
?
att
NN tavlor pictures
?
obj
HP som which
?
att
VB retade annoyed ?
sub
PM Nikita Nikita
?
obj
PM Chrusjtjov. Chrustjev.)
?
[image:2.595.137.473.89.165.2]id
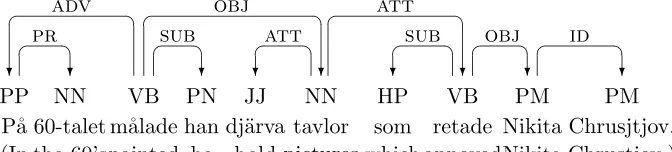
Figure 1: Dependency graph for Swedish sentence
means that the structure can be represented as a directed graph, with nodes representing word tokens and arcs representing dependency rela-tions. In addition, arcs may be labeled with specific dependency types. Figure 1 shows a labeled dependency graph for a simple Swedish sentence, where each word of the sentence is beled with its part of speech and each arc la-beled with a grammatical function.
In the following, we will restrict our atten-tion tounlabeled dependency graphs, i.e. graphs without labeled arcs, but the results will ap-ply to labeled dependency graphs as well. We will also restrict ourselves to projective depen-dency graphs (Mel’cuk, 1988). Formally, we de-fine these structures in the following way:
1. A dependency graph for a string of words
W = w1· · ·wn is a labeled directed graph
D= (W, A), where
(a) W is the set of nodes, i.e. word tokens in the input string,
(b) Ais a set of arcs (wi, wj) (wi, wj ∈W).
We write wi < wj to express that wi pre-cedes wj in the string W (i.e., i < j); we write wi → wj to say that there is an arc fromwitowj; we use→∗ to denote the flexive and transitive closure of the arc re-lation; and we use↔and↔∗ for the
corre-sponding undirected relations, i.e.wi↔wj iffwi →wj orwj →wi.
2. A dependency graph D = (W, A) is well-formed iff the five conditions given in Fig-ure 2 are satisfied.
The task of mapping a string W = w1· · ·wn to a dependency graph satisfying these condi-tions is what we call dependency parsing. For a more detailed discussion of dependency graphs and well-formedness conditions, the reader is re-ferred to Nivre (2003).
3 Incrementality in Dependency Parsing
Having defined dependency graphs, we may now consider to what extent it is possible to construct these graphs incrementally. In the strictest sense, we take incrementality to mean that, at any point during the parsing process, there is a single connected structure represent-ing the analysis of the input consumed so far. In terms of our dependency graphs, this would mean that the graph being built during parsing is connected at all times. We will try to make this more precise in a minute, but first we want to discuss the relation between incrementality and determinism.
It seems that incrementality does not by itself imply determinism, at least not in the sense of never undoing previously made decisions. Thus, a parsing method that involves backtrackingcan
be incremental, provided that the backtracking is implemented in such a way that we can always maintain a single structure representing the in-put processed up to the point of backtracking. In the context of dependency parsing, a case in point is the parsing method proposed by Kro-mann (KroKro-mann, 2002), which combines heuris-tic search with different repair mechanisms.
In this paper, we will nevertheless restrict our attention to deterministic methods for depen-dency parsing, because we think it is easier to pinpoint the essential constraints within a more restrictive framework. We will formalize deter-ministic dependency parsing in a way which is inspired by traditional shift-reduce parsing for context-free grammars, using a buffer of input tokens and a stack for storing previously pro-cessed input. However, since there are no non-terminal symbols involved in dependency pars-ing, we also need to maintain a representation of the dependency graph being constructed during processing.
Unique label (wi→r wj ∧ wi r
0
→wj) ⇒ r=r0
Single head (wi→wj ∧ wk→wj) ⇒ wi=wk
Acyclic ¬(wi→wj ∧ wj→∗wi)
Connected wi↔∗wj
[image:3.595.117.498.72.175.2]Projective (wi↔wk ∧ wi< wj< wk) ⇒ (wi→∗wj ∨ wk→∗wj)
Figure 2: Well-formedness conditions on dependency graphs
triples hS, I, Ai, where S is the stack (repre-sented as a list),Iis the list of (remaining) input tokens, and A is the (current) arc relation for the dependency graph. (Since the nodes of the dependency graph are given by the input string, only the arc relation needs to be represented ex-plicitly.) Given an input stringW, the parser is initialized tohnil, W,∅iand terminates when it reaches a configuration hS,nil, Ai (for any list
S and set of arcs A). The input string W is
accepted if the dependency graph D = (W, A) given at termination is well-formed; otherwise
W is rejected.
In order to understand the constraints on incrementality in dependency parsing, we will begin by considering the most straightforward parsing strategy, i.e. left-to-right bottom-up parsing, which in this case is essentially equiva-lent to shift-reduce parsing with a context-free grammar in Chomsky normal form. The parser is defined in the form of a transition system, represented in Figure 3 (where wi and wj are arbitrary word tokens):
1. The transitionLeft-Reducecombines the two topmost tokens on the stack, wi and
wj, by a left-directed arc wj →wi and re-duces them to the headwj.
2. The transition Right-Reduce combines the two topmost tokens on the stack, wi and wj, by a right-directed arc wi → wj and reduces them to the headwi.
3. The transitionShiftpushes the next input tokenwi onto the stack.
The transitions Left-Reduce and Right-Reduce are subject to conditions that ensure that theSingle headcondition is satisfied. For Shift, the only condition is that the input list is non-empty.
As it stands, this transition system is non-deterministic, since several transitions can
of-ten be applied to the same configuration. Thus, in order to get a deterministic parser, we need to introduce a mechanism for resolving transi-tion conflicts. Regardless of which mechanism is used, the parser is guaranteed to terminate after at most 2n transitions, given an input string of lengthn. Moreover, the parser is guar-anteed to produce a dependency graph that is acyclic and projective (and satisfies the single-head constraint). This means that the depen-dency graph given at termination is well-formed if and only if it is connected.
We can now define what it means for the pars-ing to be incremental in this framework. Ide-ally, we would like to require that the graph (W −I, A) is connected at all times. How-ever, given the definition of Left-Reduce and Right-Reduce, it is impossible to connect a new word without shifting it to the stack first, so it seems that a more reasonable condition is that the size of the stack should never exceed 2. In this way, we require every word to be at-tached somewhere in the dependency graph as soon as it has been shifted onto the stack.
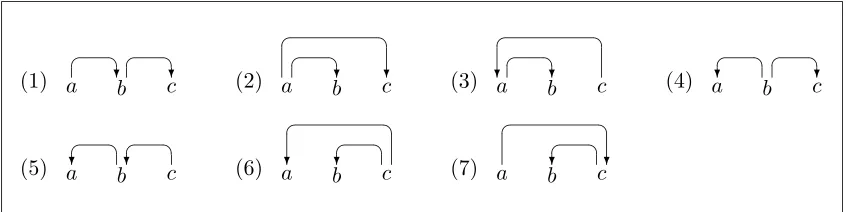
We may now ask whether it is possible to achieve incrementality with a left-to-right bottom-up dependency parser, and the answer turns out to be no in the general case. This can be demonstrated by considering all the possible projective dependency graphs containing only three nodes and checking which of these can be parsed incrementally. Figure 4 shows the rele-vant structures, of which there are seven alto-gether.
Initialization hnil, W,∅i
Termination hS,nil, Ai
Left-Reduce hwjwi|S, I, Ai → hwj|S, I, A∪ {(wj, wi)}i ¬∃wk(wk, wi)∈A
Right-Reduce hwjwi|S, I, Ai → hwi|S, I, A∪ {(wi, wj)}i ¬∃wk(wk, wj)∈A
[image:4.595.103.509.75.217.2]Shift hS, wi|I, Ai → hwi|S, I, Ai
Figure 3: Left-to-right bottom-up dependency parsing
(1) a b c
?
? (2)
a b c
?
? (3)
a b c
?
? (4)
a b c
?
?
(5) a b c
?
? (6)
a b c
?
? (7)
a b c
?
?
Figure 4: Projective three-node dependency structures
shifted onto the stack before the first reduction. However, the reason why we cannot parse the structure incrementally is different in (1) com-pared to (6–7).
In (6–7) the problem is that the first two to-kens are not connected by a single arc in the final dependency graph. In (6) they are sisters, both being dependents on the third token; in (7) the first is the grandparent of the second. And in pure dependency parsing without non-terminal symbols, every reduction requires that one of the tokens reduced is the head of the other(s). This holds necessarily, regardless of the algorithm used, and is the reason why it is impossible to achieve strict incrementality in dependency parsing as defined here. However, it is worth noting that (2–3), which are the mir-ror images of (6–7)can be parsed incrementally, even though they contain adjacent tokens that are not linked by a single arc. The reason is that in (2–3) the reduction of the first two to-kens makes the third token adjacent to the first. Thus, the defining characteristic of the prob-lematic structures is that precisely the leftmost tokens are not linked directly.
The case of (1) is different in that here the problem is caused by the strict bottom-up
strat-egy, which requires each token to have found all its dependents before it is combined with its head. For left-dependents this is not a problem, as can be seen in (5), which can be processed by alternating ShiftandLeft-Reduce. But in (1) the sequence of reductions has to be per-formed from right to left as it were, which rules out strict incrementality. However, whereas the structures exemplified in (6–7) can never be pro-cessed incrementally within the present frame-work, the structure in (1) can be handled by modifying the parsing strategy, as we shall see in the next section.
It is instructive at this point to make a com-parison with incremental parsing based on ex-tended categorial grammar, where the struc-tures in (6–7) would normally be handled by some kind of concatenation (or product), which does not correspond to any real semantic com-bination of the constituents (Steedman, 2000; Morrill, 2000). By contrast, the structure in (1) would typically be handled by function compo-sition, which corresponds to a well-defined com-positional semantic operation. Hence, it might be argued that the treatment of (6–7) is only pseudo-incremental even in other frameworks.
[image:4.595.95.518.259.365.2]ap-proach, it can be noted that the algorithm de-scribed in this section is essentially the algo-rithm used by Yamada and Matsumoto (2003) in combination with support vector machines, except that they allow parsing to be performed in multiple passes, where the graph produced in one pass is given as input to the next pass.1 The main motivation they give for parsing in multi-ple passes is precisely the fact that the bottom-up strategy requires each token to have found all its dependents before it is combined with its head, which is also what prevents the incremen-tal parsing of structures like (1).
4 Arc-Eager Dependency Parsing
In order to increase the incrementality of deter-ministic dependency parsing, we need to com-bine bottom-up and top-down processing. More precisely, we need to process left-dependents bottom-up and right-dependents top-down. In this way, arcs will be added to the dependency graph as soon as the respective head and depen-dent are available, even if the dependepen-dent is not complete with respect to its own dependents. Following Abney and Johnson (1991), we will call thisarc-eager parsing, to distinguish it from the standard bottom-up strategy discussed in the previous section.
Using the same representation of parser con-figurations as before, the arc-eager algorithm can be defined by the transitions given in Fig-ure 5, where wi and wj are arbitrary word to-kens (Nivre, 2003):
1. The transition Left-Arc adds an arc
wj r
→ wi from the next input token wj to the token wi on top of the stack and pops the stack.
2. The transition Right-Arc adds an arc
wi →r wj from the token wi on top of the stack to the next input token wj, and pushes wj onto the stack.
3. The transitionReducepops the stack.
4. The transitionShift(SH) pushes the next input tokenwi onto the stack.
The transitionsLeft-Arcand Right-Arc, like their counterparts Left-Reduce and Right-Reduce, are subject to conditions that ensure
1A purely terminological, but potentially confusing,
difference is that Yamada and Matsumoto (2003) use the termRightfor what we callLeft-Reduceand the term
LeftforRight-Reduce(thus focusing on the position of the head instead of the position of the dependent).
that the Single head constraint is satisfied, while the Reduce transition can only be ap-plied if the token on top of the stack already has a head. The Shifttransition is the same as before and can be applied as long as the input list is non-empty.
Comparing the two algorithms, we see that the Left-Arc transition of the arc-eager algo-rithm corresponds directly to theLeft-Reduce transition of the standard bottom-up algorithm. The only difference is that, for reasons of sym-metry, the former applies to the token on top of the stack and the next input token instead of the two topmost tokens on the stack. If we compare Right-Arc to Right-Reduce, how-ever, we see that the former performs no re-duction but simply shifts the newly attached right-dependent onto the stack, thus making it possible for this dependent to have right-dependents of its own. But in order to allow multiple right-dependents, we must also have a mechanism for popping right-dependents off the stack, and this is the function of the Re-duce transition. Thus, we can say that the action performed by the Right-Reduce tran-sition in the standard bottom-up algorithm is performed by aRight-Arctransition in combi-nation with a subsequentReducetransition in the arc-eager algorithm. And since the Right-Arc and the Reduce can be separated by an arbitrary number of transitions, this permits the incremental parsing of arbitrary long right-dependent chains.
Defining incrementality is less straightfor-ward for the arc-eager algorithm than for the standard bottom-up algorithm. Simply consid-ering the size of the stack will not do anymore, since the stack may now contain sequences of tokens that form connected components of the dependency graph. On the other hand, since it is no longer necessary to shift both tokens to be combined onto the stack, and since any tokens that are popped off the stack are connected to some token on the stack, we can require that the graph (S, AS) should be connected at all times, whereAS is the restriction ofAtoS, i.e.
AS={(wi, wj)∈A|wi, wj ∈S}.
Initialization hnil, W,∅i
Termination hS,nil, Ai
Left-Arc hwi|S, wj|I, Ai → hS, wj|I, A∪ {(wj, wi)}i ¬∃wk(wk, wi)∈A
Right-Arc hwi|S, wj|I, Ai → hwj|wi|S, I, A∪ {(wi, wj)}i ¬∃wk(wk, wj)∈A
Reduce hwi|S, I, Ai → hS, I, Ai ∃wj(wj, wi)∈A
[image:6.595.93.515.78.242.2]Shift hS, wi|I, Ai → hwi|S, I, Ai
Figure 5: Left-to-right arc-eager dependency parsing
is shown by the following transition sequence:
hnil, abc,∅i
↓ (Shift)
ha, bc,∅i
↓ (Right-Arc)
hba, c,{(a, b)}i
↓ (Right-Arc)
hcba,nil,{(a, b),(b, c)}i
We conclude that the arc-eager algorithm is op-timal with respect to incrementality in depen-dency parsing, even though it still holds true that the structures (6–7) in Figure 4 cannot be parsed incrementally. This raises the question how frequently these structures are found in practical parsing, which is equivalent to asking how often the arc-eager algorithm deviates from strictly incremental processing. Although the answer obviously depends on which language and which theoretical framework we consider, we will attempt to give at least a partial answer to this question in the next section. Before that, however, we want to relate our results to some previous work on context-free parsing.
First of all, it should be observed that the termstop-downandbottom-uptake on a slightly different meaning in the context of dependency parsing, as compared to their standard use in context-free parsing. Since there are no nonter-minal nodes in a dependency graph, top-down construction means that a head is attached to a dependent before the dependent is attached to (some of) its dependents, whereas bottom-up construction means that a dependent is at-tached to its head before the head is atat-tached to its head. However, top-down construction of de-pendency graphs does not involve theprediction
of lower nodes from higher nodes, since all nodes are given by the input string. Hence, in terms of what drives the parsing process, all algorithms discussed here correspond to bottom-up algo-rithms in context-free parsing. It is interest-ing to note that if we recast the problem of de-pendency parsing as context-free parsing with a CNF grammar, then the problematic structures (1), (6–7) in Figure 4 all correspond to right-branching structures, and it is well-known that bottom-up parsers may require an unbounded amount of memory in order to process right-branching structure (Miller and Chomsky, 1963; Abney and Johnson, 1991).
Moreover, if we analyze the two algorithms discussed here in the framework of Abney and Johnson (1991), they do not differ at all as to the order in which nodes are enumerated, but only with respect to the order in whicharcs are enumerated; the first algorithm isarc-standard
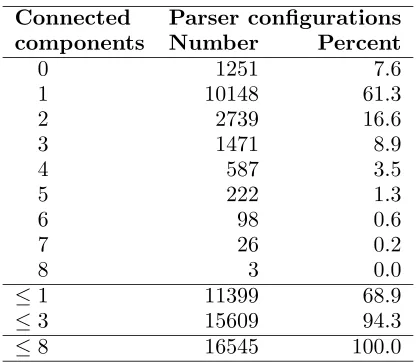
Connected Parser configurations
components Number Percent
0 1251 7.6
1 10148 61.3
2 2739 16.6
3 1471 8.9
4 587 3.5
5 222 1.3
6 98 0.6
7 26 0.2
8 3 0.0
≤1 11399 68.9
≤3 15609 94.3
[image:7.595.202.412.69.250.2]≤8 16545 100.0
Table 1: Number of connected components in (S, AS) during parsing
5 Experimental Evaluation
In order to measure the degree of incremental-ity achieved in practical parsing, we have eval-uated a parser that uses the arc-eager parsing algorithm in combination with a memory-based classifier for predicting the next transition. In experiments reported in Nivre et al. (2004), a parsing accuracy of 85.7% (unlabeled attach-ment score) was achieved, using data from a small treebank of Swedish (Einarsson, 1976), di-vided into a training set of 5054 sentences and a test set of 631 sentences. However, in the present context, we are primarily interested in the incrementality of the parser, which we mea-sure by considering the number of connected components in (S, AS) at different stages dur-ing the parsdur-ing of the test data.
The results can be found in Table 1, where we see that out of 16545 configurations used in parsing 613 sentences (with a mean length of 14.0 words), 68.9% have zero or one connected component on the stack, which is what we re-quire of a strictly incremental parser. We also see that most violations of incrementality are fairly mild, since more than 90% of all configu-rations have no more than three connected com-ponents on the stack.
Many violations of incrementality are caused by sentences that cannot be parsed into a well-formed dependency graph, i.e. a single projec-tive dependency tree, but where the output of the parser is a set of internally connected com-ponents. In order to test the influence of incom-plete parses on the statistics of incrementality, we have performed a second experiment, where we restrict the test data to those 444 sentences
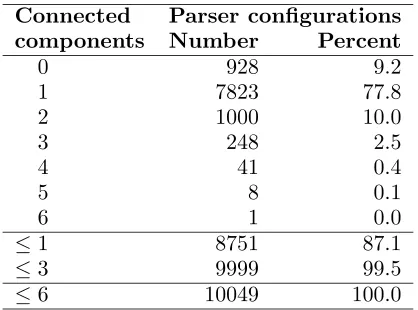
(out of 613), for which the parser produces a well-formed dependency graph. The results can be seen in Table 2. In this case, 87.1% of all configurations in fact satisfy the constraints of incrementality, and the proportion of configu-rations that have no more than three connected components on the stack is as high as 99.5%.
It seems fair to conclude that, although strict word-by-word incrementality is not possible in deterministic dependency parsing, the arc-eager algorithm can in practice be seen as a close ap-proximation of incremental parsing.
6 Conclusion
Connected Parser configurations
components Number Percent
0 928 9.2
1 7823 77.8
2 1000 10.0
3 248 2.5
4 41 0.4
5 8 0.1
6 1 0.0
≤1 8751 87.1
≤3 9999 99.5
[image:8.595.202.411.70.225.2]≤6 10049 100.0
Table 2: Number of connected components in (S, AS) for well-formed trees
Acknowledgements
The work presented in this paper was sup-ported by a grant from the Swedish Re-search Council (621-2002-4207). The memory-based classifiers used in the experiments were constructed using the Tilburg Memory-Based Learner (TiMBL) (Daelemans et al., 2003). Thanks to three anonymous reviewers for con-structive comments on the submitted paper.
References
Steven Abney and Mark Johnson. 1991. Mem-ory requirements and local ambiguities of parsing strategies. Journal of Psycholinguis-tic Research, 20:233–250.
Steven Abney. 1991. Parsing by chunks. In Principle-Based Parsing, pages 257–278. Kluwer.
Eugene Charniak. 2000. A maximum-entropy-inspired parser. In Proceedings NAACL-2000.
Michael Collins. 1997. Three generative, lexi-calised models for statistical parsing. In Pro-ceedings of the 35th Annatual Meeting of the Association for Computational Linguistics, pages 16–23, Madrid, Spain.
Walter Daelemans, Sabine Buchholz, and Jorn Veenstra. 1999. Memory-based shallow pars-ing. In Proceedings of the 3rd Conference on Computational Natural Language Learn-ing (CoNLL), pages 77–89.
Walter Daelemans, Jakub Zavrel, Ko van der Sloot, and Antal van den Bosch. 2003. Timbl: Tilburg memory based learner, ver-sion 5.0, reference guide. Technical Report ILK 03-10, Tilburg University, ILK.
Jan Einarsson. 1976. Talbankens skriftspr˚ aks-konkordans. Lund University.
Lyn Frazier. 1987. Syntactic processing: Ev-idence from Dutch. Natural Language and Linguistic Theory, 5:519–559.
Matthias Trautner Kromann. 2002. Optimality parsing and local cost functions in Discontin-uous Grammar. Electronic Notes of Theoret-ical Computer Science, 52.
William Marslen-Wilson. 1973. Linguistic structure and speech shadowing at very short latencies. Nature, 244:522–533.
Igor Mel’cuk. 1988. Dependency Syntax: The-ory and Practice. State University of New York Press.
George A. Miller and Noam Chomsky. 1963. Finitary models of language users. In R. D. Luce, R. R. Bush, and E. Galanter, editors,
Handbook of Mathematical Psychology. Vol-ume 2. Wiley.
Glyn Morrill. 2000. Inremental processing and acceptability. Computational Linguis-tics, 26:319–338.
Joakim Nivre, Johan Hall, and Jens Nils-son. 2004. Memory-based dependency pars-ing. In Proceedings of the 8th Conference on Computational Natural Language Learn-ing (CoNLL), pages 49–56.
Joakim Nivre. 2003. An efficient algorithm for projective dependency parsing. In Pro-ceedings of the 8th International Workshop on Parsing Technologies (IWPT), pages 149– 160.
Mark Steedman. 2000. The Syntactic Process. MIT Press.