International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 8, Issue 2, February 2018)
48
An Effective Intrusion Detection System Using Machine
Learning Library of Spark
Pradeep Laxkar
1, Prasun Chakrabarti
2, Amrit Ghosh
3, Avinash Panwar
4 1PhD Scholar, 2Professor, 3,4Assistant Professor, Department of CSE, SPSU Udaipur, India
Abstract—now a day’s computer network security problems are becoming serious with the growth of Internet. Network is hacked by many network attacks like DoS, U2R, R2L etc. These attacks take advantage of a networks vulnerability to gain illegal access to the important information or sometimes create a flood to prevent genuine users from accessing it. Network attackers used massive volumes of network traffic in tiny time to create victim host unavailable also fast and efficient network intrusion detection is a very challenging issue because the size of network traffic has turn into increasingly big and complex. An intrusion detection system should be able to process huge size of network data quickly in order to detect intrusion in the network as early as possible. In this paper we will discuss about how network intrusions can be detected with association rule generation and quadric classification (big data analytical techniques).We will execute the system in spark environment to process data very fast.
Keywords: IDS, attacks, feature, spark
I. Introduction
An Intrusion Detection System (IDS) is a network security technology developed to detect vulnerability exploits against a target application or computer in a computer network.
IDS are divided in to two [8]fold one is based on Detection method relates to signature-based versus anomaly-based IDS, while other is placement relates essentially to host-based (HIDS) versus network-based IDS (NIDS).
i. Signature-based IDS: The IDS identifies known intrusive behavior. Other behavior is by default not reported, that is, these systems provide a default outcome of permit (or legal). Such IDS rely on statically or dynamically compiled libraries of attack signatures or attack signature types which are matched, either post hoc or in real-time, to a candidate activity trace.
ii. Anomaly-based systems: this type of IDS identifies devi-ations from normal behavior. They use a model of normal behavior and report any activity which does not conform to the normal behaviour, thus providing a default outcome of deny (or illegal).
iii. Signature-based IDS: These types of IDS constrain the range of attacks that can possibly be detected in return for an acceptable error rate in detection.
iv. Anomaly-based IDS: it covers the entire attack space, at the cost of increased error rates. The latter is due to the fundamental problem that an anomaly is not necessarily an attack, something alluded to earlier. It is indeed often not an attack, and this leads to the major failing of many such systems, that is, the problem of a high false positive or false alert rate [8].
1)NSL KDD Data Set: For IDS we have used NSL-KDD [7] is a data set that was produced as a result of KDD CUP dataset [6] refinement. In NSL KDD data set the researchers solved some of the problems of the KDD’99 data set. The NSL KDD data set still suffers from some of the problems like redundancy and too much amount of records to be tested in a network evaluation and may not be a noble representative of existing real networks. But however it still can be applied as an effective benchmark data set to help researchers compare and build different intrusion detection methods. The total number of records in the NSL KDD train and test sets are reasonable and easy to work with.
2)Spark: Spark is capable of processing large petabytes of data at a time, distributed across a cluster of thousands of co-operating physical or virtual servers. Spark can run programs up to 100x faster than hadoop map reduce in memory. MLlibs integration with Spark has following benefits:
i. Spark is designed with iterative computation in mind,
it enables the development of efficient
implementations of large-scale machine learning algorithms since they are typically iterative in nature. Improvements in low-level components of Spark often translate into performance gains in MLlib, without any direct changes to the library itself.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 8, Issue 2, February 2018)
49
iii. MLlib is one of several high-level libraries built on top of Spark. As part of Sparks rich ecosystem, and in part due to MLlibs spark.ml API for pipeline development, MLlib provides developers with a wide range of tools to simplify the development of machine learning pipelines in practice[9].
II.LITERATURE REVIEW
1. According to Tan et. al. (2014) the Conventional standalone IDSs are susceptible to cooperative attacks, so theyre unsuitable for collaborative environments (such as a cloud computing environment). To defend against this type of attack, collaborative intrusion detection systems (CIDSs) correlate suspicious evidence between different IDSs to improve the intrusion detection efficiency. Unlike conventional standalone IDSs, a CIDS shares traffic information with the IDSs located at a local networks entry points.
2. Zamani et. al.(2013) reviewed several influential algorithms for intrusion detection based on various machine learning techniques. Characteristics of ML techniques makes it possible to design IDS that have high detection rates and low false positive rates while the system quickly adapts itself to changing malicious behaviors. They divided these algorithms into two types of ML-based schemes: Artificial Intelligence (AI) and Computational Intelligence (CI). Although these two categories of algorithms share many similarities, several features of CI-based techniques, such as adaptation, fault tolerance, high computational speed and error resilience in the face of noisy information, conform the requirement of building efficient intrusion detection systems.
3. In this paper authors presents a study for enhancing the training time of SVM of data sets, using hierarchical clustering analysis. They used the Dynamically Growing Self-Organizing Tree (DGSOT) algorithm for clustering to overcome the drawbacks of traditional hierarchical clustering algorithms. Authors presented a new approach of combination of SVM and DGSOT, which starts with an initial training set and expands it gradually using the clustering structure produced by the DGSOT algorithm.
4. In this paper authors focused on a more systematic and automated IDS development process rather that the pure knowledge encoding and engineering approaches. They proposed a novel framework, MADAM ID, for Mining Audit Data for Automated Models for Intrusion Detection.
5.Authors presented a hybrid data mining approach en-compassing feature selection, filtering, clustering, divide and merge and clustering ensemble. They work on a method for calculating the number of the cluster centroid and choosing the appropriate initial cluster centroid
III. PROPOSED WORK
[image:2.612.326.559.238.418.2]
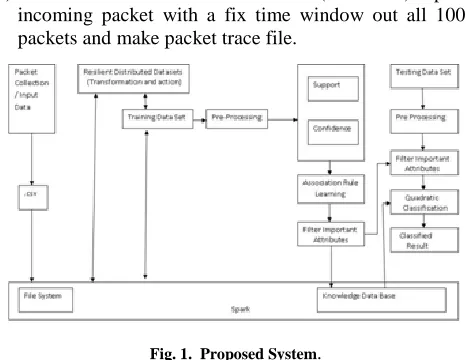
1)Packet collector : a. Packet collector (wireshark) capture incoming packet with a fix time window out all 1000 packets and make packet trace file.
Fig. 1. Proposed System.
Then information is extracted from six fields of IP header that accommodate source IP address, destination IP address, time interval and length of the packet trace file that would be stored to RDD. b. NSL KDD data are stored in RDD for static intrusion detection.
2) Format converter : The common format of spark is a test file. But the packet trace file (.pcap) is a binary format. So there is a need to convert the packet to trace file to text file, and split by each line to Data processor.
3) Pre Processing: This phase is used to resilient dis-tributed dataset (RDD) to compute some necessary features of packets. Assemblage of the packet and estimate of the features which have the same source IP address and destination IP address have to be done.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 8, Issue 2, February 2018)
50
Then testing dataset is given as input to the system. Preprocessing is also done for the testing data. Then filter the attributes from the testing data. Filtered testing data and knowledge database are given as input to quadratic classification. Classification gives result as intrusion.
IV. EXPERIMENTAL WORK
1) Association rule generation and quadratic classification:
Input: Network Traffic dataset (say for instance, NSLKDD+ dataset Output: Attack categories: DoS, U2R, R2L and probe Attacks No of features: 42
2) Equations: to calculate support and confidence:
3) Spark Enviorment:
A. Spark DAG Visualization
B. Spark Event Timeline
V. RESULT
1) Overview of computational time:
As we can see from result testing time in intrusion detection is 33.6 seconds for NSL KDD data. We can see that time taken is less in compare to other IDS methods because we are processing our data using spark environment. In proposed method limitation is the building time is high in compare to other IDS methods.
2) Justification using confusion matrix:
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 8, Issue 2, February 2018)
51
4) False Positive Rate:False positive rate for class one is highest.FPR of each will be responsible for false alarm rate. The highest FPR is 2.44922 percentage. We can say FPR rate is low so system is more accurate.
5) True Positive Rate:
From the graph we can observe that TPR is high in most the class. The TPR is low in 2nd , 15th and19th class .From confusion matrix we can see that data are very less in all three classes , so it will not affect performance of system.
6) Precision: Precision (also called positive predictive value) is the fraction of relevant instances among the retrieved instances .he precision is at good level in all classes other than class number 8, 15 and 19.
7) Recall: Recall (also known as sensitivity) is the fraction of relevant instances that have been retrieved over the total amount of relevant instances. Recall value is also high in most of the classes other than class number 2 , 15 and 19.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 8, Issue 2, February 2018)
52
9) Weighted precision, Weighted recall and weighted F1 Score:10) Performance: Performance of proposed system is calculated based on different parameters
VI. COMPARISON
For comparison we have taken various IDS methods which are mentioned in above graph. Comparison has been done on following parameters:
1. Detection Rate (DR): Detection rate of proposed algorithm is 99.8509 which is highest rate in comparison to all IDS methods.
2. False Positive Rate/False Alarm (FPR): FPR rate is less in compare to all IDS methods which also our second objective.
3. Accuracy: Accuracy of our proposed algorithm is high in compare to all IDS methods except LSSVM-IDS+FMIFS.
VII. CONCLUSION
Our proposed works is based on association rule generation, quadratic classification and spark Mllib environment Using java and spark environment we were able to model the system and observe the performance of the system. The results shows that this is very significant contribution into the field of intrusion detection systems as the observed intrusion detection rate of 99.85 percentage and a false alarm rate of 0.15percentage shows that the system have very good performance and through further tuning of the system this performance can be improved. Our results show that this IDS performs well as other systems proposed in this field. In the future work of our research we can improve the detection accuracy of various network attacks. Some network attacks are out of the scope. These attacks can be known through improving network protocols and deploying additional security mechanisms.
REFERENCES
[1] Z. Tan et al., ”Enhancing Big Data Security with Collaborative Intrusion Detection,” in IEEE Cloud Computing, vol. 1, no. 3, pp. 27-33, Sept. 2014.
[2] Z. Tan et al., ”Enhancing Big Data Security with Collaborative Intrusion Detection,” in IEEE Cloud Computing, vol. 1, no. 3, pp. 27-33, Sept. 2014.
[3] Khan, L., Awad, M.,Thuraisingham, B. (2007). A new intrusion detection system using support vector machines and hierarchical clustering. The VLDB JournalThe International Journal on Very Large Data Bases, 16(4), 507521.
[4] Lee, W., Stolfo, S.J.: A framework for constructing features and models for intrusion detection systems. ACM Trans. Inform. Syst. Security 3(4), 227261 (2000).
[5] K. Wankhade, S. Patka and R. Thool, ”An efficient approach for Intrusion Detection using data mining methods,” 2013 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Mysore, 2013, pp. 1615-1618.
[6] KDD Cup 1999, Available Online: http://kdd.ics.edu/databases/kddcup99/kddcup99.html, October 2007.
[7] Tavallaee, Mahbod, et al. ”A detailed analysis of the KDD CUP 99 data set.”Proceedings of the Second IEEE Symposium on Computational Intelligence for Security and Defence Applications 2009.
[8] Mohay, George M.Computer and intrusion forensics. Artech House, 2003.