International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, UGC Approved List of Recommended Journal, Volume 8, Issue 4, April 2018)87
Sentiment Analysis of Twitter Streaming Data
Binita Kumari
1, Rakesh Ranjan Kumar
21
Assistant Professor,GGSESTC, Bokaro, India
2CSE Department, IIT(ISM) Dhanbad Abstract: - As the number of internet users increases
rapidly, many new users are joining the social networking websites, e.g. twitter, Facebook etc. Twitter offers the ideal environment for everyone to speak about their opinions and talk about their ideas and share immediately what they are thinking about. With the help of Twitter people communicate with each other. Since this data stream is constantly growing, it is hard to extract useful information for users. Every kind of people wants to benefit from these data and get a personalized ser-vice from Twitter. The huge amount of data from product reviews, blogging posts, tweets and customer feedbacks, etc., makes it necessary to automatically identify and classify sentiments from these sources. This can be benefit not only businesses and organizations who need market intelligence but also individuals who are interested in purchasing/com-paring products online. In this paper, we expound a new approach using both corpus based and dictionary based methods to determine the semantic orientation of the opinion words in tweets.
Keywords: —Micro blogging, Twitter, Sentiment Analysis, opinion mining
I. INTRODUCTION
Ongoing increase in wide-area network connectivity promise vastly augmented opportunities for collaboration and resource sharing. Now-a-days, various social networking sites like Twitter, Facebook, MySpace, and YouTube have gained so much popularity and we cannot ignore them. They have become one of the most important applications of Web 2.0 [1]. They allow people to build connection networks with other people in an easy and timely way and allow them to share various kinds of information and to use a set of services like picture sharing, blogs, wikis etc
.
Two-thirds of the world‟s internet population visits a social network or blogging site [2]. The fast and exponential growth of social networking sites which provide facility of information exchange between users and social media have become an ideal platform for research and data mining. The valuable information retrieved from social networking sites can be utilized in many ways one of which can be to study, understand and predict the market for specific products which is very essential to improve qualities of the respective product.
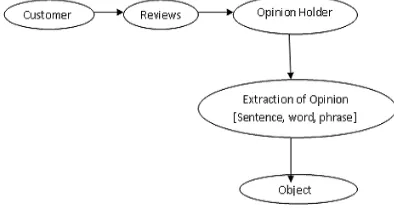
[image:1.612.338.535.415.527.2]After collecting the desired information the most important part would be to under-stand the contents of this information. Here natural language processing comes into play. NLP is field of computer science and linguistics concerned with the interactions between computers and human (natural) languages [3]. One specific application in NLP that can be used for this purpose is sentiment analysis. Sentiment analysis has been widely researched area on document, sentence, phrase and feature level analyses in different domains. Automated sentiment analysis could not only benefit businesses and organizations who need market intelligence but also individuals who are interested in purchasing/comparing products. With all these processes and methods, it is possible to build a system which can extract application dependent information, process it and produce data which can be used for studying and deductions based on the information retrieved.
Figure 1: Opinion Mining Model
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, UGC Approved List of Recommended Journal, Volume 8, Issue 4, April 2018) [image:2.612.49.286.133.218.2]88
Figure 2: Concept of sentiment AnalysisThis research paper presents a technique for text mining of Twitter feeds in real time and sentiment analysis using three-way classification by investigating the sentiment intensity. The main focus is on improving the accuracy and solving the data sparsity issue in tweet classification, effectively reducing the number of tweets classified as neutral.
II. LITERATURE REVIEW
A lot of research has been done by researchers in
the sentiment analysis domain. A few of the many
approaches used approaches used for sentiment
classification are discussed.
Go et al. (2009) [14] were among the first to does sentiment analysis exclusively on Twit-ter data. In this paper they take care of the problem as one of binary classification, they categorized tweets as either positive or negative. Due to the shortage of hand-labeled training data Go et al. (2009) use distant supervision to train a supervised approach. They have downloaded huge amount of tweets via the Twitter API and mark emoticons in the tweets with label noise. In this paper they haven‟t consider those Tweets containing emoticons expressing both positive and negative sentiment. They also remove those messages which containing re-tweets and message duplicates.
Pak and Paroubek (2010) [15] also use positive and negative emoticons as noisy labels to create their training data of 250,000 tweets. However, they exercises the tweets associated with the Twitter related with newspapers as samples, and classify these tweets with three classes. They have removed URLs, hash tags, usernames, re-tweets, emoticons and stop words (a, an, the) from all tweets and use token on whitespace and punctuation.
Bifet and Frank, 2010 [17] briefly discuss the challenges that Twitter data streams pose, focusing on classification problems, and then consider these streams for opinion mining and sentiment analysis.
To deal with streaming unbalanced classes, authors propose sliding window Kappa statistic for evaluation in time-changing data streams. Using this statistic they perform study on Twitter data using learning algorithms for data streams.
Cui, A. et al. [18] showed that sentiment analysis of tweets is a challenging task due to multilingual and informal messages. This paper is tackling this problem by analysis of emotion tokens. Emotion is the mood of a person depicted from the words in the tweet. Emotion can be sad, happy, angry, etc. The proposed approach has two steps. First, emotion tokens are extracted from the message. Second, graph propagation algorithm plots the tokens at different polarities.
Ye, S. and Wu, S.F. [19] discovered message propagation pattern using Twitter. The evaluation is based on examining different social influences and their effects such as stabilities, correlations and assessments. An important feature of this research is the identification of popular tweets.
Montejo-Raez, A. et al.[20] proposed an unsupervised approach for sentiment polarity detection from twitter tweets. The polarity scores are calculated from Senti Word Net and random walk algorithm is used to calculate the weights from the tweet. The proposed algorithm has comparable performance with SVM algorithm. The benefit of the proposed technique is that no need of training corpus as required in supervised learning techniques and no dependency on the model domain. The limitations include handling of negation, manual labeling process for certain tweets and facing flaws in calculation of final polarity score.
Argamon, S. et al. [21] used a supervised learning algorithm for determining complex sentiment-related attributes. These attributes are classified as attitude type and force. The WordNet glosses are used for the implementation of supervised learning algorithm which classifies them into four force levels and eleven of attitude levels.
III. EXISTING TECHNIQUES AND APPROACHES
A. Machine Learning Techniques
Machine learning techniques are most useful techniques for the sentiment analysis for categorized document or sentences into positive, negative or neutral categories.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, UGC Approved List of Recommended Journal, Volume 8, Issue 4, April 2018)89
1)Supervised Techniques
[image:3.612.45.286.293.374.2]The supervised approach assumes that there are finite set of classes into which the document should be classified and training data available for each class. In case when there are two classes: positive and negative. For supervised document-level classification, three classifiers are commonly used: Naive Bayes (NB) [10], Maximum Entropy (ME) [10], and Support Vector Machines (SVM) [10]. Steps involved in supervised approaches are data processing, feature extraction, learning/parameter estimation, and decoding as shown in Figure 3 below:
Figure 3: Supervised Techniques
2)Unsupervised Techniques
Unsupervised machine learning techniques don‟t use training data set for classification. Unsupervised approach is the lexicon-based method, which uses dictionary of sentiment words and phrases with their associated orientations and strength, and incorporates intensification and negation to compute sentiment score for each document. In unsupervised technique, classification is done by function which compares the features of given text against discriminatory-word lexicons whose polarity is determined prior to their use. For example, starting with positive and negative word lexicons, one can look for them in the text whose sentiment is being sought and register their count. If the document has more positive lexicons, it is positive, otherwise it is negative.
B. Natural Language Processing
Natural language processing techniques play important role to get accurate sentiment analysis. NLP techniques like Beg of words, Hidden markov model, part of speech (POS), N-gram algorithms, large sentiment lexicon acquisition and parsing techniques are used to express opinion for document level, sentences level and aspect level. Large sentiment lexicon acquisition is used sentiment word dictionary which contains lot of sentiment words with their numeric threshold value for particular domain. Now-a-days Senti WordNet dictionary is used for subjective sentiment analysis.
Noun phrase (NP), verb oriented, adjective oriented sentimental analysis concentrate on NP, verb and adjective respectively to classify the sentence or entity into positive, negative or neutral. Word based techniques, Emotional based techniques are part of the NLP domain for sentiment analysis classification particularly for twitter message analysis.
C. Text Mining Techniques
[image:3.612.327.562.312.399.2]Text mining techniques are also useful for efficient automatic sentiment analysis for twitter messages. Text mining process divides into four stages. In this approach supervised machine learning algorithms are used for classification purpose. Text Mining Process is shown in the figure 4.
Figure 4: Text Mining Process
IV. DATA SOURCE
Launched in July of 2006, Twitter rapidly gained worldwide popularity, with over 300 million users as of 2011, and became one of the highest-ranking social networking sites in January 2009, according to the Alexa rank [8]. Twitter, which enables its users to send and read text-based posts of up to 140 characters, known as “tweets”, raises usage especially during prominent events. Twitter is a social networking and micro blogging service that allows its users post real time messages. Tweets have many unique characteristics, which create new challenges and shape up the means of carrying sentiment analysis on it as compared to other domains. Following are some key characteristics of tweets:
Message Length: The maximum length of single Twitter message is 140 characters. This is different from previous sentiment classification research that focused on classifying longer texts, such as product and movie reviews.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, UGC Approved List of Recommended Journal, Volume 8, Issue 4, April 2018)90
Topics: Twitter users can post messages about range oftopics unlike other sites which are designed for a specific topic. This differs from a large fraction of past research, which focused on specific domains such as movie reviews.
Emoticons: These are pictorial representations of facial expressions using punctuation and letters. The purpose of emoticons is to express the user‟s mood.
Target: Twitter users use of the “@” symbol to refer to other users on Twitter. Users are automatically alerted if they have been mentioned in this fashion.
Hash tags: People use the hash tag symbol “#” before a relevant keyword or phrase (no spaces) in their Tweet to categorize those Tweets and help them show more easily in Twitter Search.
Special symbols: “RT” is used to indicate repeation of someone else‟s earlier tweet.
V. THE PROPOSED FRAMEWORK
The new framework applies a variant of techniques for Twitter feed analysis and classification. The Proposed framework uses three phases data collection, preprocessing phase and scoring module. This is hybrid framework retrieve data streams from Twitter streaming API in real-time. The proposed system is uses new emoticon classifier for extraction of emoticons and pre-processing steps which pre-processing and transform the tweets in stream pattern. The proposed hybrid framework is shown in Figure 5 and
[image:4.612.321.551.126.402.2]the flowchart of the proposed framework is given in Figure 6
Figure 5: Proposed Framework for Sentiment Analysis of Twitter Data
The main tasks to accomplish in this thesis are:-
Collecting data from Twitter: The Twitter streaming API is allowing real time access to publicly available data on Twitter.
Pre-processing the Tweets: Removal of URLs, hash-tags, username and special characters, spelling correction using dictionary, substitution of abbreviations and stop words removal.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, UGC Approved List of Recommended Journal, Volume 8, Issue 4, April 2018)91
[image:5.612.52.283.274.539.2]To uncover the opinion direction, we will first extract the opinion words in the tweets and then find out their orientation, i.e., to decide whether each opinion word reflects positive sentiment, negative sentiment or neutral sentiment. In this thesis, we are considering the opinion words as the combination of the adjectives along with the verbs and adverbs. The corpus-based method is used to find the semantic orientation of adjectives and the dictionary-based method is employed to find the semantic orientation of verbs and adverbs. The overall tweet sentiment is then calculated using linear equation which incorporates emotion intensifiers too.
Figure 6: Flow Chart of Proposed Framework for Sentiment Analysis of Twitter Data
5.1 Pre-processing steps
We have prepared the transaction file that contains opinion indicators, namely the adjective, adverb and verb along with emoticons (we have taken a sample set of emoticons and manually assigned opinion strength to them). Also we have identified some emotion intensifiers, namely, the percentage of the tweet in Caps, the length of repeated sequences & the number of exclamation marks, amongst others. Thus, we are pre-processed all the tweets as follows:-
Extract all emoticons from the tweet and replace with appropriate word.
Remove all URLs (e.g. www.example.com), hash tags (e.g. #topic), targets (@username).
Remove all stopword. Remove all special character.
Replace all abbreviation with correct word.
5.2 Pseudo code for proposed framework
Input: Tweet
Output: Sentiment value
Find tweets from Twitter for particular keyword with the API
For each tweet, do
Procedure Pre-processing (tweet) Tweet=Apply Emoticon tagger Tweet= Remove URL (Tweet) Tweet= Remove Hashtags (Tweet) Tweet= Remove UserName (Tweet) Tweet= Remove StopWord (Tweet) Tweet= Remove Special Character (Tweet) End procedure
Sentiment value=0 Procedure scoring (Tweet) For each tweet
Sentiment Value=Sum (positive)-Sum (negative) End of each tweet
Overall polarity=use Bayes classifier (tweet) End procedure
End
5.3 Refine the Abbreviation Word
This filters all abbreviation words before starting the detection of abbreviation words to save the “running time” of the detection process. The word is considered as an “abbreviation” if found in an opinion lexicons or dictionary. If the word is “abbreviation” word then it is passed to the abbreviation identification module for further processing. In this module abbreviation dictionary is searched for finding abbreviation and its definition. If found it is passed to the sentiment scoring module otherwise Web is searched for its definition (meaning). If the Web returns positive response the abbreviation is scored. In case of negative result then it is treated as a misspelled word. This framework corrects the basic spelling errors such as word with repeated letters.
5.4 Emoticons Extraction
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, UGC Approved List of Recommended Journal, Volume 8, Issue 4, April 2018)92
Example:-We went through everything very quickly and I feel like I‟m ready to make changes to my paper. :)
Love working with her. (:
An emoticon is identified using a regular expression. Approaches are use to convert the emoticon :) to “smile” to identify the patterns that characterize emoticons and replace them with the appropriate text.
5.5 Tweet Sentiment Score Calculation
After pre-processing the each tweet, we have split the sentence into words and calculate the sum of positive against negative word matches. We estimate tweet‟s sentiment by counting the number of occurrences of “positive” and “negative” words. To assign numeric score to each tweet, we shall simply subtract the number of occurrences of negative words from the number of positive. Larger negative scores will correspond to more negative expressions of sentiment, neutral (or balanced) tweets should to zero, and very positive tweets should score larger, positive numbers. So if a sentence contains 3 positives words and 1 negative word, its score is 2. For this we use the Bing Liu list which has 2006 positive words and 4784 negative words which makes 6790 in total.
Let T be a set of tweets t defined as: T= {t1, t2,...,tn}
Let W be a set of words w in each tweet t defined as: W= {w1, w2,...,wm}
If the word is found in the positive set then, it is declared as positive. It is declared negative if found in the negative set. If the word is not found in both sets, we declare as neutral. Total positive and negative words are counted and the sum is calculated. A score of 1 is assigned to the refined tweet, if the sum is greater than zero. A score of1 is assigned if the sum is less than zero. A score of zero indicates that the calculated sum is zero.
For calculating the final score of a Tweet is defined as:
Let PW be a set of positive words in tweet T. PW= Set of Positive Words
Let NW be a set of negative words in tweet T NW= Set of Negative Words
Score of tweet (T) = Number of positive word –Number of negative word
If Score >0, this means that the sentence has an overall „positive opinion‟
If Score <0, this means that the sentence has an overall „negative opinion‟
If Score = 0, then the sentence is considered to be a „neutral opinion‟.
The list of words score Sw is calculated as:
Figure 7: Score Calculation
Where wx, wy and wz are words belonging to set of words W and t is a tweet from the set of tweets T.
VI. EXPERIMENT AND RESULT ANALYSIS
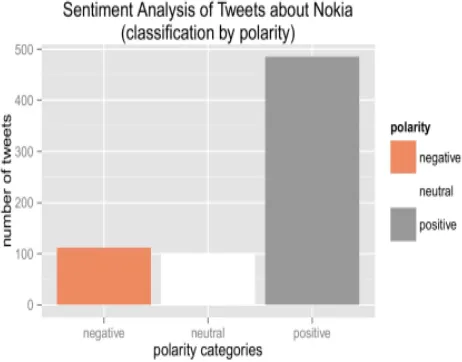
[image:6.612.332.563.442.623.2]Sentiment analysis on new framework are done using R software and we access the tweets on certain keyword using API. It is about analyzing the mood on Twitter about certain Keyword. We get number of tweets which contain keyword define by user, filter out the text of these tweets and then we analyze these tweets are positive or negative. We use tool doing the sentiment analysis is called R. It is free “software environment for statistical computing and graphics and is available for Unix platforms, Windows and MacOS. Its available here:http://www.r-project.org/ In sentiment analysis, I have used RStudio GUI and following packages TwitteR, ROAuth, plyr, stringr, gplot2, RColorBrewer, tm, wordcloud.
Figure 8: Relation between Tweets Polarity
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, UGC Approved List of Recommended Journal, Volume 8, Issue 4, April 2018)93
[image:7.612.58.284.181.363.2]Following Figure 9 classify every tweets respect to their emoticon. Here emoticon is categories in seven type i.e. unknown, joy, sadness, anger, surprise, fear and disgust.
Figure 9: Different Class of emoticon express in Tweet by Chart
VII. CONCLUSIONS AND FUTURE WORK
The expression of opinions of users in social networking platforms has become one of the main ways of communication, due to spectacular development of web environment in recent years. The large amount of information on these platforms makes them viable for use as data sources for applications based on opinion mining and sentiment analysis. In this paper we have discusses an approach where stream of tweets from the Twitter micro blogging site are preprocessed and classified based on their feature content as positive, negative and neutral and analyzed with machine learning algorithms i.e., Naïve Bayes can achieve high accuracy for classifying sentiment. To uncover the sentiment, we extracted the opinion words and emoticons from the tweets and get the final score based. The work presented in this paper specifies a novel approach for sentiment analysis on Twitter data. This work is exploratory in nature and the prototype evaluated is a preliminary prototype. The initial results show that it is a motivating technique. In future we will apply this approach for the other close domain. We need a global sentiment word dictionary which we can use for either for open or close domain and contain proper threshold values. In future we can use the pure semantic, ontology and description logic approach to classify subjective sentences and objective sentences and then after classify into positive, negative or neutral category.
REFERENCES
[1] L. Colazzo, A. Molinari and N. Villa, “Collaboration vs Participation: the Role of Virtual Communities in a Web 2.0 world” International Conferences on Education technology and Computer (ICETC), pages 321-325, 2009,.
[2] Global Faces and Networked Places, A Neilsen report on Social Networking‟s New Global Footprint, March 2009.
[3] Christopher D. Hinrich Schtze Weston, “Foundations of statistical natural language processing” ACM-Transaction, 1999.
[4] Haewoon Kwak, Changhyun Lee, Hosung Park, and Sue Moon “What is Twitter, a Social Network or a News Media”, Communications of the ACM, 2010.
[5] Meeyoung Cha, Hamed Haddadi and Krishna P. Gummadi “Measuring User Influence in Twitter: The Million Follower Fallacy”, Association for the Advancement of Artificial Intelligence (www.aaai.org), 2010.
[6] B.Liu, “Sentiment Analysis and Subjectivity: Handbook of Natural Language processing, Second Edition”, To appear in Handbook of
Natural Language Processing,
2010.
[7] W. N. Venables, D. M. Smith and The R Core Team, “ An Introduction to R”, A Programming Environment for Data Analysis and Graphics, 2010.
[8] Amy Mollett, Danielle Moran and Patrick Dunleavy “Using Twitter in university research, teaching and impact activities”, the LSE Public Policy Group (PPG), UK.,2011.
[9] B.Pang and L.Lee,“Opinion Mining and Sentiment Analysis.”, Foundations andTrends in Information Retrival, pages 1-135, 2008. [10] Bo Pang and Lillian Lee,“Thumbs up ? Sentiment Classification
using Machine Learning Techniques”, Appears in Proc. 2002 Conf. on Empirical Methods in Natural Language Processing (EMNLP), pages 118-134, 2012
[11] D. Klein and C. D. Manning. “Fast exact inference with a factored model for natural language parsing”, In NIPS, MIT Press, pages 3-10, 2002.
[12] K. Toutanova, D. Klein, C. D. Manning, and Y. Singer. “Feature-rich part-of-speech tagging with a cyclic dependency network”, In HLT-NAACL, 2003.
[13] Stefano Baccianella, Andrea Esuli, and Fabrizio Sebastiani “SENTIWORDNET 3.0: An Enhanced Lexical Resource for Sentiment Analysis and Opinion Mining”, 2010.
[14] Alec Go and Lei Huang. “Twitter Sentiment Classification using
Distant Supervision”,
publication/12dc1e21bf5b3ebf7259154d92ec31146/coca.alina, 2009. [15] Alexander Pak, Patrick Paroubek. “Twitter as a Corpus for Sentiment Analysis and Opinion Mining” emph LSM 11 Proceedings of the Workshop on Languages in Social Media, pages 30-42, 2010.
[16] Luciano Barbosa, Junlan Feng. “Emotion Tokens: Bridging the Gap among Multilingual Twitter Sentiment Analysis”, Springer-Verlag, Berlin, Heidelberg, pages 238-249, 2011.
[17] A. Bifet, E. Frank,, “Sentiment Knowledge Discovery in Twitter Streaming Data”,Springer-Verlag, Berlin, Heidelberg‟, pages 1-15, 2010
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, UGC Approved List of Recommended Journal, Volume 8, Issue 4, April 2018)94
[19] S. Ye, S.F. Wu, “Measuring message propagation and socialinfluence on Twitter.com”, LNCS 6430, Springer-Verlag, Berlin Heidelberg, pages 216-231, 2011.
[20] A. Montejo-Raez, E. Martnez-Camara, M.T. Martn-Valdivia, L.A. Urena-Lopez. “RandomWalk weighting over SentiWordNet for sentiment polarity detection on Twitter” Proceedings of the 3rd Workshop on Computational Approaches to Subjectivity and Sentiment Analysis, pages 3-10, 2012.