2017 International Conference on Electronic and Information Technology (ICEIT 2017) ISBN: 978-1-60595-526-1
Distributed Representations of Mongolian Words and Its
Efficient Estimation
Wuyuntana
1and Siriguleng
WANG
1,*
1
School of Computer Science and Technology, Inner Mongolia Normal University, Hohhot, China
*Corresponding author
Keywords: Word vectors, Continuous Bag-of-Words model, Skip-gram model, semantic syntactic evaluation.
Abstract. The word vectors has good semantic properties that can be used to improve and simplify many natural language processing applications. In this paper, we use the two model architectures Continuous Bag-of-Words (CBOW) and skip-gram to compute the Mongolian word vectors. On this basis, we design a comprehensive test set based on the Mongolia language features to measure the similarity of Mongolian syntactic and semantic. And then on this test set estimate the quality of the Mongolian word vectors. Experiments show that the Skip-gram architecture works better than the CBOW on the Mongolian syntactic semantic tasks, and the word vectors computed by this model are have good quality. Take Mongolian verb vectors as an example, also find that there are multiple similarities between the computed Mongolian word vectors.
Introduction
Processing the natural language with machine learning algorithm, It is necessary to digitize the language first. The word vectors is a way to digitize the words in the language. One of the simplest word vectors representations is one-hot representation, which expresses words as indexes in vocabularies, so there is no notion of similarity between words. The introduction of Distributed Representation can overcome the shortcomings of one-hot representation. By training, each word in a language is mapped to a fixed length of a short vector, putting all of these vectors together to form a word vector space, and each vector is a point in the space, if introduce the "distance" in this space, we can according to the distance between the words to determine their syntactic , semantic similarity.
Present Situation of Word Vectors Research
Representation of words as continuous vectors has a long history. A model architecture for estimating neural network language model (NNLM) was proposed in [1], which uses a feed forward neural network with a linear projection layer and a nonlinear hidden layer to co-learn word vector representation and language model. This work has been followed by many others. In order to reduce the number of parameters, [2] was proposed to use recurrent neural network learn word vectors representation (RNNLM). The biggest advantage of the recurrent neural network is that it can make full use of all the above information to predict the next word. The disadvantage is that the recurrent neural network is difficult to optimize, if the optimization is not good, long distance information will be lost, and even can’t reach the effect of opening window to see a number of words in front. Another architecture of NNLM was presented in [3, 4], where the word vectors are first learned using a neural network with a single hidden layer, and then the word vectors are used to train NNLM. Thus, we can learn word vectors even without constructing the full NNLM. In the NNLM model, the training efficiency depends on the calculation of the hidden layer to the output layer. In terms of this issue, two new model architectures CBOW and Skip-gram are proposed in [5] to calculate the continuous vector, removed the hidden layer in NNLM. The CBOW model takes the word vectors of the context as input, the mapping layer is shared among all the words, The output layer is a classifier with the goal of maximizing the probability of the current word. In contrast to CBOW, the input layer of the Skip-gram model is the current word vectors, and the output layer maximizes the prediction probability of the contexts. In [6] they present several extensions of the Skip-gram model that improve both the quality of the vectors and the training speed by sub sampling of the frequent words and negative sampling. The introduction of sub sampling is to reduce the effect of frequent words on accuracy and training speed. For morphologically rich languages with large vocabularies and many rare words, In [7] they proposed a new approach based on the skip-gram model, where each word is represented as a bag of character n-grams. A vector representation is associated to each character n-gram, words being represented as the sum of these representations.
Establishment of Mongolian Syntactic Semantic Test Set
Word vectors can also be manipulated by addition and subtraction to correspond to a semantic and syntactic relationship. We estimate quality of the word vectors through syntactic and semantic word similarities. For example, see the closest vector to C (AJILCIN)-C (AJILCIN) +C(AJILTAN) is whether or not C(AJILTAD). Different from the English, Mongolian word vectors estimation does not have its own syntactic and semantic test set. Therefore, we designed a syntactic semantic comprehensive test set based on the Mongolian language features.
Establishment of Mongolian Semantic Test Set
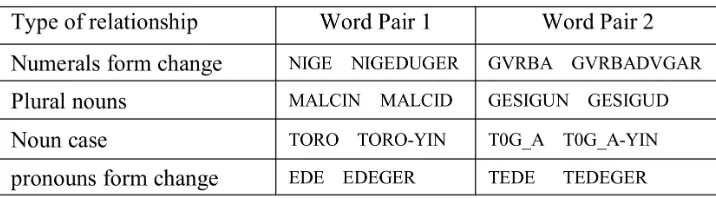
According to previous research found that when we train high dimensional word vectors on a large amount of data, the resulting vectors can be used to answer very subtle semantic relationships between words, such as a city and the country it belongs to, e.g. France is to Paris as Germany is to Berlin. For this phenomenon, we have established two Mongolian semantic relationship sets: capital city relationship and male-female relationship (see Table 1). A large list of Semantic question is formed by connecting each category of two word pairs, total has 100 semantic questions. We have included in our test set only single token words, thus multi-word entities are not present (such as NIU’ Y0RK).
Table 1. Examples of two types of semantic questions in Semantic test set.
Establishment of Mongolian Syntactic Test Set
Mongolian is morphologically rich language, as exists a lot of inflectional forms of the noun and verb which have same base words and conveying similar notions. Such as the verbs "YABVH, YABVY_A, YABVL_A, YABVJV", have the base word "YABV" means "go" in different forms.
Mongolian nouns have morphological changes of case, number, possession and other areas. Mongolian case is expressed by connecting case additional ingredients behind the noun, such as "GER-UN", which ”GER” is a noun, "UN" is a additional ingredients of case, totally have seven types of case additional ingredients. The plurality of the Mongolian language is represented by connecting a variety of plural additional ingredients behind singular form of noun. For example, the noun singular form "BAGSI" (teacher) connect a plural additional ingredients "NAR" means "teachers". The changes of Mongolian numerals expressed by cardinal numerals connecting a variety of additional ingredients. For example, there is a cardinal numerals "NIGE", connect a additional ingredients"dUGER" to form "NIGEDUGER" that means “first”
Table 2. Examples of four types of syntactic questions in Syntactic test set.
Estimation of Mongolian Word Vectors
Word vectors can be manipulated by addition and subtraction to correspond to a semantic and syntactic relationship. use the analogy method to estimate the Mongolian word vectors on the established syntactic semantic test set. Four words of each question in syntactic semantic test set in turn correspond to a, b, c, d. It is known that the relationship between a and b is like c and d. First give a, b, c, and then see result of the C (a) -C (b) + C (c) is whether or not d. If the calculated vector is identical to the word d in the test set, we think it is the correct answer. We evaluate the overall accuracy for all question types, and for each question type separately (semantic, syntactic).
Mongolian Word Vectors Model Architecture
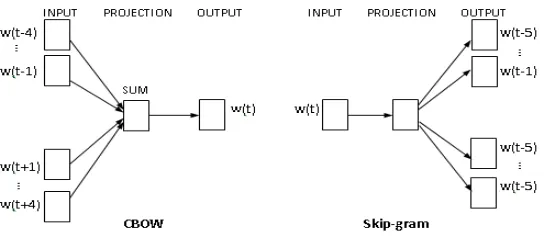
You can use different model architectures to learn word vectors, such as NNLM, RNNLM, LSA, and so on. According to previous studies, it is found that these architectures were significantly more computationally expensive for training than CBOW and Skip-gram models. Therefore, this paper uses CBOW and Skip-gram models to learn Mongolian word vectors.
In the CBOW/Skip-gram model, the target word is a word in the middle of a word string not the last word, and contexts are the m words before and after this word, m is the size of the model window.
The CBOW model optimizes the word vectors by predicting the current word based on the contexts. It is found that the 4-gram model in the Mongolian n-gram language model works best. Based on this feature, we train the Mongolian word vectors in the case of window 3-6, and use the established syntactic semantic test set estimate the word vectors. Finally found that when the window size is 4, the word vector’s quality is best. So the window size of the CBOW model used to train the Mongolian word vectors is set to 4, and the contexts of the target word are 4 words before and after target word. The model architecture is shown in Fig.1. For example, given the contexts of a word "DVMDADV VLVS-VN EB HAMTV" and "TOB H0RIYAN-V JOBLEGCID-UN H0RIY_A", we can predict that the word is probably "NAM-VN". It can be seen that when the window size is set to 4 in Mongolian, words can express good semantics.
Figure 1. Mongolian word vectors model architecture.
Experiment and Results
Use the CBOW and Skip-gram models mentioned in Section 4 to train Mongolian word vectors and adopts Hierarchical Softmax acceleration strategies. The training corpus uses the Mongolian language training corpus of CWMT2015 and the 1 million-word "modern Mongolian database" of Inner Mongolia University. The two corpus are Mongolian Latin form, the word and punctuation are divided before training.
After training the word vectors, use the analogy method to estimate the Mongolian word vectors on the established syntactic semantic test set.
We use the Skip-gram architecture with different choice of word vectors dimensionality and increasing amount of the training data to learn the Mongolian word vectors. The results shown in Table 3 .It can be seen that in some ways, adding a dimensionality or adding training data can improve quality of the word vectors.
Table 3. Accuracy on Semantic-Syntactic test set, using word vectors from the Skip-gram.
Training words
Dimensionality 12M 17M 23M 10 17.91 22.88 25.36 200 20.57 25.54 28.11 300 22.35 26.53 29.03 600 21.22 27.54 28.26
[image:5.612.169.441.68.187.2]In order to compare the two model architectures, we trained the word vectors with CBOW and Skip-gram on 23M training corpus, and the word vectors dimensionality is 300. Experiments show that the Skip-gram architecture works better than the CBOW on the Mongolian syntactic semantic tasks. The comparison is given in Table 4.
Table 4. Comparison of architectures, accuracy on Semantic-Syntactic test set.
negative sample. Therefore, under this strategy, the optimization goal becomes the probability of maximizing the positive sample while minimizing the probability of the negative sample.
In order to compare the two accelerating methods, we trained the word vectors on the Skip-gram architecture with Negative Sampling and Hierarchical Softmax. The training corpus is 23M training corpus and the vector dimensionality is 300. Negative Sampling uses negative examples of 5 and 15. Experiments show that the Negative Sampling works better than the Hierarchical Softmax on the semantic tasks. The comparison is given in Table 5.
Table 5. Comparison of two accelerating methods in Skip-gram architecture.
Accelerating methods
Semantic Accuracy Syntactic Accuracy
[%] [%]
total Accuracy [%] NEG-5 18.69 35.71 27.2 NEG-15 18.69 27.01 22.85 HS-huffman 15.12 42.95 29.03
The total experimental results show that the semantic accuracy is relatively low, the first reason is that we ignore the concept of synonyms in the test, such as "EREGTEI EMEGTEI HUU UHIN" in the test set, "UHIN" has a synonym"HEUHEN", if the calculated vector and test set word "UHIN" is exactly the same, we think it is the correct answer, so the synonym "HEUHEN" is ignored. The second reason is the lack of place name in the training corpus, so the quality of the word vectors about place name is relatively bad.
Mongolian is a morphologically rich languages, some suffix can be added to some verb or noun to simply mean one specific thing about that particular word that the suffix commonly represents. This means that there exists a lot of inflectional forms of the same noun and verb base words, conveying similar notions. Mongolian verbs have rich morphological change, but verb base words are rarely found in training corpus, so it is difficult to use analogical relations to inference the relationship between verbs .So we use the cosine distance of two vectors to calculate the similarity of the verbs. Table 6(see Table 6) shown similar six words to the verb "YABVHV", similar words 2 and 3 are semantic similar words to "YABVHV", the others word have similar endings with "YABVHV". So we can see that the Mongolian verb vectors has multiple similarities.
Table 6. Similar six words to the verb "YABVHV".
Conclusions
In this paper, we use the CBOW/Skip-gram model to learn the Mongolian word vectors and test the quality of the word vectors on our syntactic semantic test set.
morphologically rich language representations. Furthermore, Word2vec itself is a shallow neural network model. After computing the good word vectors, the word vectors is usually used as the initial value of the various neural network structures, use the results of pre-training as initial value can improve the effect of the task in general. So we will use the trained word vectors as the initial value of Mongolian-Chinese machine translation task to enhance its effect.
Acknowledgement
This research was financially supported by the National Science Foundationof China: "Research on Mongolian Chinese Machine Translation Based on Neural Network" (61762072) and Inner Mongolia Autonomous Region Natural Science Foundation: "Mongolian Named Entity Recognition research based on conditional random field (2016MS0623)".
References
[1] Y. Bengio, R. Ducharme, P. Vincent. A neural probabilistic language model. Journal of Machine Learning Research, 2003, 3:1137-1155.
[2] Mikolov Tomáš. Statistical Language Models based on Neural Networks. PhD thesis, Brno University of Technology. 2012. [PDF]
[3] T. Mikolov. Language Modeling for Speech Recognition in Czech. Masters thesis, Brno University of Technology.2007.
[4] T. Mikolov, L. Burget and O. Glembek. Neural network based language models for highly inflective languages, In: Proc. ICASSP2009.
[5] Mikolov Tomáš, Wen-tau Yih, and Geoffrey Zweig. Linguistic regularities in continuous space word representations.Proceedings of NAACL-HLT. 2013. [PDF]
[6] Mikolov Tomáš, Ilya Sutskever and Jeffrey Dean. Distributed Representations of Words and Phrases and their Compositionality. NIPS2013
[7] P. Bojanowski, E. Grave and T. Mikolov. Enriching Word Vectors with Subword Information. Facebook AI Research. 2016.
[8] J. Turian, L. Ratinov, Y. Bengio. Word Representations: A Simple and General Method for Semi-Supervised Learning. In: Proc. In ACL, 2010.
[9] T. Mikolov, W.T. Yih, G. Zweig. Linguistic Regularities in Continuous Space Word Representations. NAACL HLT. 2013.
[10] J. Turian, L. Ratinov, Y. Bengio. Word Representations: A Simple and General Method for Semi-Supervised Learning. In: Proc. Association for Computational Linguistics, 2010.
[11] R. Collobert, J. Weston and P. Kuksa. Natural language processing from scratch. JMLR, 12, 2011.