2019 International Conference on Information Technology, Electrical and Electronic Engineering (ITEEE 2019) ISBN: 978-1-60595-606-0
Deformable Convolutional Networks Tracker
Wen-ming CAO* and Xue-jun CHEN
Shenzhen Key Laboratory of Media Security Shenzhen University Shenzhen, China
*Corresponding author
Keywords: Object tracking, Deformable convolution.
Abstract. Object tracking is a fundamental topic in computer vision. It is an interdisciplinary scientific filed involving machine learning, pattern recognition etc, and has a wide applicability. Although, convolutional neural networks (CNNs) have achieved significant success for visual recognition tasks. Deformation and scale variation of targets are huge challenges in object tracking. They cannot address these challenges for relying on massive amounts of data to build deep models. They are inherently limited to model geometric transformations due to the fixed geometry in the building blocks. In short, CNNs are inherently limited to model large and unknown transformation. In this paper, we introduced a deformable convolution module to construct a novel deformable convolutional networks tracker(DCT).The tracker illustrates outstanding performance in the Visual Tracker Benchmark (OTB)100[7] benchmark with scale variation and deformation attributes.
Introduction
Computer vision is an interdisciplinary field that deals with how computers can obtain high-level understanding information from images or videos. It can be seen as an extension of human vision and perception. In the past two decades, computer vision technology are widely used in intelligent control, decision systems, information retrieval, human-computer interaction, etc.
In computer vision, object tracking (also known as visual tracking) has always been an important topic. Visual tracking determines the motion information, direction and trajectory of the target by estimating the position, shape or occupied area of the tracking target in a sequence of continuous video images, and realizes the analysis and understanding of the behavior of the moving target in order to complete a higher level task. Visual tracking has important research significance and broad application prospects in both military defense and civil security.
Specific research and applications include: intelligent video surveillance, modern military, video-based human-computer interaction, smart transportation system, intelligent visual navigation, 3D reconstruction and so on. The visual tracking framework includes four parts[4]: motion model, feature extractor, observation model, model updater.
unknown transforms. This limitation stems from the fixed geometry of the CNN module: the convolution unit samples the input feature map at a fixed location.
In this work, we introduced a new module deformable convolution that greatly enhances CNN's ability to model geometric transformations. It adds the 2D offsets to the regular grid sampling position in the standard convolution.
Related Work
Deformable Convolutional Networks Theory
The feature maps and convolution in CNNs are 3D.The deformable convolution operates on the 2D spatial domain. The modules here are used to describe clearly in 2D without loss of generality, and naturally expand to 3D. The 2D convolution[5] mainly consists of two steps:1) The input feature map x is sampled by the regular R square; 2) summing the sampled values weighted by w. Grid R determines the size and expansion of the receptive field.
Defines 1, a 33standard kernel operation. For each positionp0of the output feature map y,we
obtain:
p x w y np
p
p
p
) ( n) ( n)(
0 0
(2)
Where pn enumerates the positions in R. R determines the relationship between the output feature
map and the previous feature map. In the contrast, the deformation convolution, Deformable convolutional neural network adds offsets pn|n1,...N, N=|R|to each position of the sample point.
When applying a 33standard convolution kernel, the N is equal to 18, where there is 2 dimensions and 9 sampling points. Eq.(2) becomes
p p x w y n n nn
p
p
p
p
) ( ) ( )(
0 0
(3) Now, the sample is now in an irregular and offset position pnpn.Since the offset pnis usually a
fractional. Eq. (3) is realized by bilinear interpolation as:
q q x p q Gp) ( , ) ( )
( x
(4) Where pp0pnpndenotes an arbitrary position, possibly a fraction, for Eq (3). q traverses the
integer positions of all feature maps andG q,pis a bilinear interpolation kernel. Note that G is two-dimensional, dividing the two-dimensional kernel into two one-dimensional kernels as:
q p gqx px g
qy py
G , , ,
(5)
Whereg a,bmax(0,1ab).Equation (5) is computationally fast becauseG q,pis non-zero for only a few qs.
Multi-Domain Network
The image resolution in image classification is high. The image resolution in visual tracking is generally low. The purpose is to locate the target in the image, you may encounter background clutter and the target object is too small. Although the network trained in large-scale image classification matches has achieved good performance in visual tracking tasks, it is still not fully applicable to visual tracking tasks. In the visual tracking, the types of objects not included in the image classification task may appear. As the networks become deeper, the weakening of the target location information is not conducive to the target location.
MDNet uses the model VGG-M pre-trained in the image classification task as the network initialization model, followed by multiple fully connected layers for the classifier.
Deformble Convolution Network Tracker
The Architecture of Network Tracker
To deal with the problem for object scale variation, deformation, we introduce deformable convolutions module to the tracker. This section describes deformable convolution network module to obtain scale invariant features for visual tracking.
DCT has N branches corresponding to N domains. During training, each tracking video corresponds to a fully connected layer for learning general feature representation tracking. During tracking, the fully connected layer during training is removed, and a fully connected layer is initialized using the first frame sample. The new fully connected layer continues to fine tune during the tracking process to accommodate new target changes. This method makes the feature more suitable for target tracking, and the performance is greatly improved.
[image:3.595.72.519.293.390.2]Shared layers conv1 FC6-1 FC6-2 FC6-N-1 FC6-N FC4 FC5 xy y y z o p q r t k xy y y z o p q r t k conv2 conv3 input images
Figure 1. Deformation convolutional networks tracker.
Tracking control and network updater: we introduce long-term and short-term updates to deal with two aspects of object tracking, robustness and adaptiveness. Long-term update executes periodically to update the model when tracking to positive samples, while short-term updates refer to when tracking failures detected, when the positive score of the estimated target is less than 0.5. In both cases, we use negative samples observed in the short term because the old negative examples are usually redundant or independent of the current frame. Please note that we update a single network during the tracking period. Both updates are performed based on the how fast the target appearance changes. To get the state of the target in each frame: first sampling N x1,...,xN
candidates sampled around the target in the previous frame and evaluating the candidate using the network. Give the best target state x* by finding the example with the largest positive score.
i x x f max arg i * x .Target candidate generation: To generate candidate frames in each frame, we sample 256
candidate targets according to a certain distribution and scale transformation, ti i t i t y s x
xt , , ,i1,...,N,
obeyed Gaussian distribution who’s means is the previous target object x*t-1and variance is a
diagonal matrix0.09r2,0.09 2,0.25
r , Where r is the width and height of the previous frame target. The
scale ratio of each candidate bounding box is calculated by multiplying 1.05si
by the initial target ratio.
Training Data: For offline training, we sample 50 positive samples and 200 negative samples per
frame. Where the positive examples have 0.7IoU overlap ratios with ground-truth bounding boxes, while the negative examples have0.3. Similarly, for online training, positive and negative samples are sampled in the same way, but S1500and - 5000
1
S .For bounding box regression, we use
1000 training examples with the same parameters[13].
Network learning: offline learning, we train the network for 100K iterations with learning rates
connected layers. At the first frame, we performed 30 iterations of the full connection layers with learning rate 0.0001 for fc4-5 and 0.001 for fc6.For online updates, we train 10 iterations of the fully connected layer and set the learning rate to three times of offline training. Each mini-batch contains 128 samples, of which 32 are positive samples and 96 are negative samples selected out of 1024 negative examples.
Experiment
We evaluated DCT in the sequences with challenge of scale variation on on Object Tracking Benchmark (OTB) [7] . Our algorithm is implemented in Pytorch using VGG pretrained models, and runs at around 2 fps with eight cores of 3.40GHz Intel i7-6700 and NVIDIA Geforce GTX 1080 GPU.
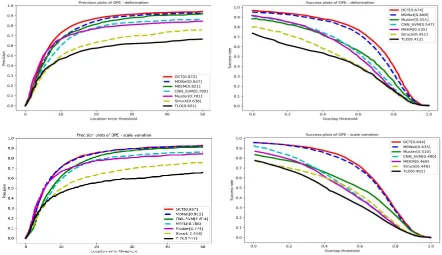
Evaluation on OTB with Challenge of Scale Variation and Deformation
OTB is a popular tracking benchmark that includes 100 fully annotated videos with eight challenge attributes: fast motion, background clutter, illumination variation, in-plane rotation, low resolution, occlusion, out of view, and scale variation. Our algorithm evaluated on the OTB with challenges of scale variation and deformation. The evaluation based on two indicators: center location error and bounding box overlap ratio. One-pass evaluation (OPE) is employed to compare our algorithms to the five state-of-the-art trackers: MUSTer[8], MEEM[9],TGPR[10], DSST[11] and KCF[12] and MDnet[6].
[image:4.595.73.516.485.740.2]In this paper, we propose a novel deformable convolutional networks tracker by introducing deformable convolutional modules to deal with the problem that the existing trackers easily fails when the target has large deformation and scale variation. For offline learning, we use a multi-domain pre-trained of a classifier to enable the network to obtain the deformation feature maps. For online learning, we get the parameters obtained by offline training and randomly initialize the last layer of the networks. For online learning, we only update the fully connected layer. The experiments show that our tracker has improved in the video sequences of deformation and scale transformation. For future work, since the tracker still can’t satisfy real-time running, we will accelerate the tracker.
Acknowledgement
This work was supported by National Science Foundation of China, No.61771322, 61375015, 61871186.
References
[1]Wang N, Shi J, Yeung D Y, et al. Understanding and Diagnosing Visual Tracking Systems[J]. 2015.
[2]Lowe D G. Object recognition from local scale-invariant features[C]// Iccv. 1999.
[3]Lecun Y, Bengio Y. Convolutional networks for images, speech, and time series[M]//The handbook of brain theory and neural networks. MIT Press, 1998.
[4]Wang N, Shi J, Yeung D Y, et al. Understanding and Diagnosing Visual Tracking Systems[J]. 2015.
[5]Dai J, Qi H, Xiong Y, et al. Deformable Convolutional Networks[J]. 2017.
[6]Nam H, Han B. Learning Multi-Domain Convolutional Neural Networks for Visual Tracking[J]. 2015.
[7]Wu Y, Lim J, Yang M H. Online Object Tracking: A Benchmark[C]//2013 IEEE Conference on Computer Vision and Pattern Recognition. IEEE Computer Society, 2013.
[8]Zhibin H, Chen Z, Wang C, et al. Multi-Store Tracker (MUSTer): a Cognitive Psychology Inspired Approach to Object Tracking[C]//IEEE Conference on Computer Vision & Pattern Recognition. IEEE, 2015.
[9]Zhang J, Ma S, Sclaroff S. MEEM: Robust tracking via multiple experts using entropy minimization.[J]. 2014.
[10]Gao J, Ling H, Hu W, et al. Transfer Learning Based Visual Tracking with Gaussian Processes Regression[C]//European Conference on Computer Vision. Springer, Cham, 2014.
[11]M. Danelljan, G. Häger, F. Khan, and M. Felsberg. Accurate scale estimation for robust visual tracking. In BMVC, 2014.1, 2, 5, 8