Research Article
a
August
2017
Computer Science and Software Engineering
ISSN: 2277-128X (Volume-7, Issue-8)
English-Marathi Cross Language Information Retrieval
System
Kalyani Lokhande
Research Scholar, Department of Computer Engineering, SSBT’s COET, Jalgaon, Maharashtra, India
Dhanashree Tayade
Assistant Professor, Department of Computer Engineering, SSBT’s COET, Jalgaon, Maharashtra, India
DOI: 10.23956/ijarcsse/V7I8/0127
Abstract— Nowadays, different types of content in different languages are available on World Wide Web and their usage is increasing rapidly. Cross Language Information Retrieval (CLIR) deals with retrieval of documents in another language than the language of the requested query. Various researchers worked on Cross Language Information Retrieval systems for Indian languages using different translation approaches. There is still CLIR system to be developed which allow user to retrieve Marathi documents when English query is given. In the proposed English to Marathi Cross Language Information Retrieval system, translation is based on query translation approach. The proposed system retrieves Marathi documents depending on matching terms in query. The performance of the proposed system is improved by query pre-processing and query expansion using WordNet.
Keywords— Cross Language Information Retrieval; WordNet; FIRE 2010 Dataset; Query Pre-processing; Query Expansion.
I. INTRODUCTION
Information Retrieval (IR) systems since developed has opened doors of information across the world. Initially IR systems were mostly developed for English language. Language has been barrier for users. Introduction of Cross
Language Information Retrieval systems has opened new paradigm for efficient and easy retrieval of information. The
evaluation of Cross Language Information Retrieval for Indian languages started recently. After the highly successful CLEF and NTCIR campaigns, since 2008, the Forum for Information Retrieval Evaluation [FIRE], modeled focused specifically on Indian languages and English. Document collections have been developed for some Indian Languages namely, Hindi, Bangla, Marathi and English.
The number of Internet users increasing day to day accessing any kind of required information at any time. Information Retrieval (IR) mainly refers to a process that the finding required information. With 100 million internet users, India is at third place globally in usage of internet. Though the internet has shrunken the geographical boundaries, the language diversification is a big barrier to get full benefit of the internet. Hence there is a need to develop a technique like Cross Language Information Retrieval which is used to retrieve documents in a language other than the user used to specify the query. Therefore, Internet is no longer monolingual and non-English contents are accessed rapidly. In this aspect, Information retrieved is mainly considered in text form [1].
A. Cross Language Information Retrieval System for Indian Languages
The number of Web users accessing the Internet become increasing day to day because people can access any kind of required information at any time. Information Retrieval (IR) mainly refers to a process that the user can find required information should be easily accessible and digestible. Though the network shrank the globe, the language diversification is a great barrier to attain full benefit of the digital life. Hence there is a need to develop a technique like Cross Language Text Retrieval which is used to retrieve text documents in a language other than the user used to specify the query. Therefore Internet is now becoming multilingual and non-English contents are accessed rapidly [1].
CLIR is an area of IR which is interesting and having much scope of development. The aim o f CLIR is to allow users to input queries in one language and retrieve documents in one or more other languages. The resulting documents can then be translated into the language used for the query to allow the user to get the sense about the information
retrieved For example, user wants information about Marathi Abhangas if the query fired in English (like Abhang) the
retrieved documents shows poor result compared when query fired in Marathi language itself. Cross Lingual Information Retrieval provides the solution for language barrier, by allowing the user to ask the query in the local language and then to get the documents in another language (English) and vice versa [2].
In India plenty of people are speaking diversified local languages. In world population, very few people know English language and can right the queries in English in a right way. The language diversification is a great barrier to get the benefits of the web. Cross Lingual Information Retrieval provides the solution for that barrier, by allowing the user to ask the query in the local language and then to get the documents in another language [3].
II. RELATED WORK
ISSN(E): 2277-128X, ISSN(P): 2277-6451, DOI: 10.23956/ijarcsse/V7I8/0127, pp. 112-116 and Machine Translation approach is used. Other language-specific resources included a Hindi stemmer, a Bengali morphological analyser, and a set of 200 Hindi and 273 Bengali stop words. Lucene framework was used for retrieval, indexing, stemming and scoring of the documents. The experiment pointed out the necessity of good linguistic resources,
mainly a rich bilingual lexicon.
Saurabh Varshney and Jyoti Bajpai, in [5], proposed an algorithm for improving the performance of the English-Hindi CLIR system. Use of all possible combination of English-Hindi translated query using transliteration of English query terms and choosing the best query among them for retrieval of documents is done. The experimental results show that the proposed approach helps to resolve ambiguity in English-Hindi CLIR system and gives more relevant information as compared English monolingual. The pre and post query expansion helps to improving the performance of the English-Hindi CLIR system and based upon past experiences the proposed approach retrieves more relevant information.
Eva Katta and Anuj Arora, in [6], proposed an improved searching and ranking approach for English- Hindi based CLIR system. The approach focuses on proper searching and ranking of documents by using algorithms such as Particle Swarm Optimization and Nave Bayes. The n-gram matching of query terms to that of document is done. The proposed system retrieves more relevant documents as compared to other systems.
Chaware and Srikantha Rao, in [7], proposed Domain Specific Information Retrieval in Multilingual environment by considering a shopping mall as the domain. The user can pose the query in Hindi, Marathi or Guajarati and the back end data is stored in English. Using Character-by-Character mapping, the query is converted to English. When there was an exact matching exist, keywords were converted to local language by doing Character-to-ASCII mapping. The efficiency of the Information retrieval depends on the minimum number of keys to be mapped.
Rajendra et al., in [8], proposed a Cross Language Information Retrieval (CLIR) approach using corpus driven query suggestion. Use of corpus statistics to gather a clue on selecting the right query terms when the translation of a specific query is missing or incorrect is done. The top ranked queries are used to perform query formulation. Using the re-formulated weighted query, CLIR is performed. Comparison is done between the results of CLIR system with Google translation of user queries and CLIR system with the proposed query suggestion approach. English and Tamil corpus of FIRE 2012 dataset used for analysis. The experimental results show that the proposed approach performs well while dealing with incorrect translation of the queries.
As per study of previous work, it is found that for CLIR systems are developed for many of the Indian languages. English-Marathi CLIR will be new invention in CLIR field of Indian languages. Among translation approaches, Query translation approach has been adapted by most of the authors. For query translation, bilingual dictionary and machine translation systems are widely used being easier approach. However, new approaches like Corpus and Ontology proves promising if it used for specific domain. Experiment setup is mostly on standard dataset.
In this paper, propose English-Marathi CLIR system which makes use of basic techniques of query pre-processing. The performance will be improved by using query expansion technique using WordNet. The experiment will
be performed on FIRE 2010 dataset in Marathi. The performance of the system will be evaluated using precision and recall.
III. PROPOSED WORK
The framework of proposed approach is described in Fig.1.The proposed framework shows the working of English-Marathi CLIR system in which user gives their query in English language and the relevant documents are retrieved in Marathi language. The documents will be used from FIRE 2010 Dataset of Marathi news corpus. The steps involved in flow of the proposed system is given below:
ISSN(E): 2277-128X, ISSN(P): 2277-6451, DOI: 10.23956/ijarcsse/V7I8/0127, pp. 112-116 1. Firstly user enters the query in English language.
2. By using pre-query expansion, the English query by using various stools like English WordNet is expanded. 3. Query translation translate refined English query to Marathi query with query translation approach by using
Google translator.
4. This expanded Marathi query is fired to retrieve Marathi relevant documents based on similarity between query and documents.
1) Query Pre-processing:
In the process of pre-processing, tokenization is applied to query to separate each term in a query. It usually involves separation and segmentation of words as well as isolating them from punctuation marks or other related formatting and mark-up symbols. Query pre-processing is first and basic step which is done whenever query is given. The input query is English. When inputted the query each word in query is separated and keywords are identified by process of tokenization.
2) Query Expansion:
Query Expansion (QE) is a widely used technique that attempts to increase the likelihood of a match between
the query and relevant documents by adding semantically related terms (called expansion terms) to a user’s query [4].
Here, in this work, WordNet is used as source of query expansion. First English WordNet is used to expand user query. Here, WordNet not only used to get the synonyms for each keyword but also to make combinations of these synonyms to get similar queries.
3) Query Translation:
In proposed system, for query translation among different types of translation approaches Google translator is
used. From these set of queries, each query is submitted for translation one by one. The query translation is done via Google Translator. The original query along with expanded query words which stored in array of strings are translated using Google Translator.
4) Information retrieval system :
The information retrieval process involves searching and ranking of documents. Documents are searched for matching terms. The documents retrieved which satisfy matching condition. The translated Marathi query is fired to database to get the desired documents. The documents are retrieved based matching terms using Boolean logic.
IV. RESULT AND DISCUSSION
Building a successful and sustainable CLIR requires suitable methodologies and metrics for assessing its
effectiveness. Among the major evaluation measures that are mostly used for determining the effectiveness CLIR system
include precision and recall. The Equation 4.1 and Equation 4.2 are used to calculate precision and recall of the system respectively.
Precision:
It refers to the ratio of the relevant retrieved documents and the set of retrieved documents. It is defined by the amount of relevant documents retrieved compared to all documents retrieved.
Precision = (4.1)
Where α= relevant documents, β= retrieved documents
Recall:
It refers to the ratio of the relevant retrieved documents and the set of relevant documents. It is defined by the amount of relevant documents retrieved compared to all documents relevant.
Recall = (4.2)
Where α= relevant documents, β= retrieved documents
The proposed system performed experiments on FIRE 2010 datasets. The system uses WordNet to generate similar
multiple queries. For analysing the performance of the system the queries from different TEN topics are chosen. Here
ISSN(E): 2277-128X, ISSN(P): 2277-6451, DOI: 10.23956/ijarcsse/V7I8/0127, pp. 112-116
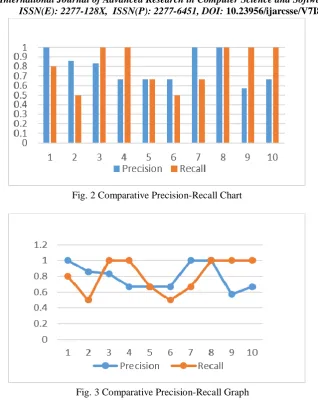
Fig. 2 Comparative Precision-Recall Chart
Fig. 3 Comparative Precision-Recall Graph
From the analysis of results of experiment, it is depicted as the precision and recall values lies between 0.5 to 1. Hence the objective the proposed system is achieved which is to maintain good precision recall. When compared to most of the CLIR system in Indian language, the precision and recall values are better one.
V. CONCLUSION
Cross-language IR made new prototypes in searching documents through various languages across the world. CLIR for Indian languages has gained importance in last decade and there is scope to explore much in this field. Cross-lingual IR provides new paradigms in searching documents through varieties of languages across the world. CLIR for Indian languages has gained importance in last decade and there is scope to explore much in this field. The proposed English-Marathi CLIR uses WordNet to improve results of retrieval. The proposed system uses WordNet not just to expand queries but to create similar multiple queries. The results show that the performance of the system is good with maintaining promising precision and recall. The performance of any CLIR depends mainly on linguistic resources used for the development of the system. In future, the linguistic resources such as standard translation dictionaries and other tools can be developed. The research work can be extended by adding these linguistic resources in Marathi to proposed architecture for better performance.
ACKNOWLEDGMENT
It is a great pleasure and moment of immense satisfaction for me to express my profound gratitude to Head of
Department of Computer engineering, Dr. Prof. G. K. Patnaik for his valuable advice and guidance. I acknowledge all
the staff members of the department of Computer Engineering, SSBT's College of Engineering & Technology for their help and suggestions during various phases of this project work. I would also like to extent my gratitude towards my
family members and friendswho always encouraged me in every deed.
REFERENCES
[1] P. Iswarya, Dr. V. Radha, International Journal Of Engineering Research And Applications, "Cross Language
Text Retrieval: A Review" (IJERA) ISSN: 2248-9622 Vol.2, Issue 5, September- October 2012, pp.1036-1043.
[2] L. Kalyani and T. Dhanashree, “English-marathi cross language information retrieval system based on query
ISSN(E): 2277-128X, ISSN(P): 2277-6451, DOI: 10.23956/ijarcsse/V7I8/0127, pp. 112-116
[3] A. Nagarathinam and S. Saraswathi, “State of art: Cross lingual information retrieval system for Indian
languages," International Journal of Computer Applications, vol. 35, no. 13, 2011.
[4] D. Mandal, S. Dandapat, M. Gupta, P. Banerjee, and S. Sarkar, “Bengali and hindi to English cross-language
text retrieval under limited resources." in CLEF (Working Notes), 2007.
[5] S. Varshney, J. Bajpai, “Improving performance of English-Hindi Cross Language Information Retrieval using
Transliteration of query terms” 2013 IEEE International Conference in MOOC, Innovation and Technology in Education (MITE), 978-1-4799-1626-9/13/2013 IEEE.
[6] E. Katta and A. Arora, \An improved approach to english-hindi based cross language information retrieval
system," in Eighth International Conference on Contemporary Computing (IC3), IEEE, 2015, pp. 354-359.
[7] S. Chaware and S. Rao, \Ontology approach for cross-language information retrieval," Published in
International Journal of Computer Technology and Application, vol. 2, pp. 379{384, 2011.
[8] P. Rajendra and S. Sudeshna, \Cross-language information retrieval with incorrect query translations," Polibits,.