QUEUEING MODELS OF PARALLEL SYSTEMS WITH SIMULTANEOUS RESOURCE POSSESSION
HENK JONKERS
Telematica Instituut, P.O. Box 589, 7500 AN Enschede, the Netherlands. E-mail: [email protected]
VICTOR F. NICOLA
Centre for Telematics and Information Technology, University of Twente, P.O. Box 217, 7500 AE Enschede, the Netherlands.
E-mail: [email protected]
Traditional queueing networks are still one of the most popular techniques for per-formance analysis of computer systems, because they combine efficient analysis with accurate performance predictions. However, they have some important lim-itations when applied to parallel and distributed systems. One of them is that solutions for simultaneous resource possession, which occurs in many parallel com-puting applications, are hard to find. In this paper we identify classes of scheduling disciplines for simultaneous resource possession, and derive an approximate analyt-ical solution for one of them. We compare the scheduling disciplines with respect to their performance, and validate the accuracy of the approximation.
1 Introduction
On account of their conceptual simplicity and efficient analytical solutions, (separable) queueing models remain among the most popular techniques for performance analysis of computer and communication systems. However, queueing models have their limitations: due to their limited expressiveness, some important properties of systems cannot be studied.
One of the areas in which the limitations of queueing models are particu-larly apparent is performance evaluation of parallel and distributed computing systems. One of the problems to solve is how to study the combination of con-dition synchronisations and mutual exclusion. Another important problem, that has turned out to be particularly hard to solve, issimultaneous resource possession (SRP). In parallel processing, there can be several sources of SRP: several hardware resources that are needed simultaneously, two critical pro-gram sections that are entered simultaneously, or a combination of both.
In order to make queueing analysis also available for these types of appli-cations, we are interested to find (approximate) solutions for queueing models with SRP. We propose practical solutions to extend the applicability of queue-ing analysis to some typical SRP patterns. For more complex situations, we
will have to resort to other, less efficient, modelling and analysis techniques (e.g. stochastic Petri nets) or to quantitative simulation.
2 Related work
Few publications exist of analytical solutions for queueing networks with si-multaneous resource possession. Although published already in 1982, Jacob-son and Lazowska’smethod of surrogates1 is still one of the most frequently cited works in this area. This method offers an iterative approximation for closed queueing networks with SRP. Theaggregate server method of Agrawal and Buzen2, specifically designed for the analysis of critical sections in pro-grams, is an iterative method as well. Some solutions have been published for specific classes of closed queueing networks with SRP, e.g. by Kaufman3, Courcoubetis4, or some solutions based on decomposition and aggregation5. For open queueing networks, related literature is even more scarce. Under some circumstances, the approach of Ghodsi and Kant6, based on the com-bination of task graphs and open queueing networks, can take into account the combination of mutual exclusion and hardware resource constraints. For a number of very specific types of open queueing networks, used to model production systems, (approximate) solutions are presented in7. We have not found solutions for a more general class of open queueing networks.
3 Example model
In this section we introduce a simple example that we use as an illustration throughout this paper. Consider a distributed-memory (DM) computer archi-tecture with three processing nodes, as shown in Figure 1. The central node,
P0, is interconnected to node P1 by a bidirectional interconnection link LA and to node P2 by linkLB.
We assume that all communications arecircuit-switched: before a message is sent between two nodes, a connection is established in which the commu-nication links on the path between the source and the destination node are claimed. The links in the circuit are not released until the message has been completely transmitted. Messages fromP1 toP2 or vice versa can be trans-mitted directly by establishing a connection using both of the links LA and
LB simultaneously; the central nodeP0 is not involved. In this example, we will only consider the communication links as shared resources. We distin-guish three classes of traffic: (1) messages from P0 to P1 or from P1 to P0 (needingLA); (2) messages fromP0toP2 or fromP2toP0(needingLB); (3) messages fromP1 to P2 or fromP2 toP1 (needingLA andLB). In the case
of class 3 messages simultaneous resource possession occurs, because the links
LA andLB must both be claimed before a message of this class can be sent. We assume that messages for the three traffic classes are generated at a rate ofλ1,λ2 andλ3, respectively. Messages vary in length and transmission time (the transmission time depends on the message length, but is independent of the distance between the nodes), with a mean transmission timeS = 1/µ. Figure 2 shows a queueing model of this system. For each link there is a server in the model, and there is one queue for each traffic class. The two servers connected to the middle queue are both needed simultaneously to serve class 3 customers.
P1 P0 P2
LA LB
Figure 1. 3-Node DM architecture
LA
LB λ1
λ3
λ2
Figure 2. Queueing model of the architecture
4 Scheduling disciplines
In SRP situations, resource scheduling is more complex than in the single-resource case. Pure first-come first-serve (FCFS) scheduling is generally no longer possible, because the first job in line for one resource might also need other resources that are not yet available. Therefore, before we consider solu-tions for the SRP problem, we need to identify possible scheduling disciplines, and choose one discipline for further study.
First, we distinguish non-priority and priority disciplines. As a third class, we consider processor sharing. For each scheduling discipline, we give performance simulation results, with arrival rateλ for each of the three job classes in the example. We assume a service time ofS= 1 time unit.
4.1 Non-priority scheduling
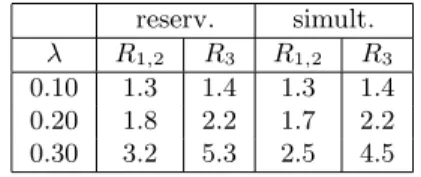
Non-priority scheduling disciplines for SRP provide the most straightforward generalisation of scheduling disciplines for single resource possession. The two main possibilities are by reservation, where a customer claims each of the needed resources as soon as they become available, and simultaneously, where the needed resources are claimed only when they are all available, as one atomic operation. The latter discipline is more efficient because, contrary to the former discipline,blocking is not possible here. Table 1 shows simulation results for these two scheduling disciplines using our example model from
Figure 2. R1,2 denotes the mean response time for class 1 and class 2 jobs, andR3 the mean response time for class 3 jobs.
4.2 Priority scheduling
As the simulation results show, the scheduling disciplines described in the previous subsection favour customers needing only one resource, especially for high workloads. In this section, we consider the possibility to give some sort of priority to customers needing more resources, in order to obtain more balanced response times. We can distinguishnon-preemptive andpreemptive priority. In the latter case, when a class 3 customer arrives, it claims both re-sources immediately (unless other class 3 customers are receiving service), and possibly interrupts the service of the low-priority (class 1 and 2) customers. Table 2 presents simulation results for the priority disciplines.
Table 1. Simulation of non-prio. disciplines reserv. simult.
λ R1,2 R3 R1,2 R3
0.10 1.3 1.4 1.3 1.4 0.20 1.8 2.2 1.7 2.2 0.30 3.2 5.3 2.5 4.5
Table 2. Simulation of priority disciplines non-preempt. preempt. λ R1,2 R3 R1,2 R3 0.10 1.3 1.4 1.39 1.11 0.20 1.8 1.9 2.08 1.25 0.30 2.8 3.3 3.57 1.43 4.3 Processor sharing
In the single-resource possession case, processor sharing (PS) is a good ap-proximation for a number of other scheduling disciplines. E.g., for a regular M/M/1 queue, the performance measures of PS scheduling are identical to those of FCFS. Although this will not be the case in the presence of SRP, PS might still offer a good approximation for other scheduling disciplines.
First we generalise the PS discipline to a SRP situation. The principle of PS is that the server capacity is equally shared between jobs in the queue. In the single resource possession case this means that, for a queue withn jobs, the effective service rate for a job is µ/n Considering our example model, with a total ofn1jobs in queue 1,n2 jobs in queue 2 andn3 jobs in queue 3, server 1 is shared byn1+n3 customers and server 2 by n2+n3 customers. We make the additional assumption thatclass 3 customers always require an equal capacity from both servers. As a consequence, the capacity that remains for the other two classes is also equal, because of our assumption of equal server capacities. We identify two ways to achieve this.
In the first method, which we will call “maximum processor sharing”, the maximum of the number of jobs in the class 1 and 2 queues determines the
departure rateµ3 for class 3 jobs, which (with a service time ofS) results in:
µ3= S(n n3
3+ max{n1, n2}) (1)
The remaining capacity is available for the class 1 and class 2 jobs:
µ1=µ2= max{n1, n2}
S(n3+ max{n1, n2}) (2) In this method, class 1 and 2 jobs always get at least their share of the capacity, sometimes more (when there are more customers at the other resource): it can be considered as a kind of (weak) priority for these classes.
In the second method, “minimum processor sharing”, theminimum num-ber of jobs in the class 1 and 2 queues determines the departure rateµ3. Again, the remaining capacity is available for class 1 and class 2 jobs:
µ3= S(n n3
3+ min{n1, n2}) and µ1=µ2=
min{n1, n2}
S(n3+ min{n1, n2}) (3) Whenn3= 0, all the capacity goes to the other jobs, i.e.,µ1=µ2= 1/S. In this discipline, class 3 jobs have some sort of (weak) priority. Table 3 shows the simulation results for the two types of processor sharing scheduling. 5 Analytical solutions
For the preemptive priority discipline, an exact closed-form solution can be derived for the example model, using an approach similar to8. However, this solution cannot easily be generalised to allow for the analysis of more complex systems with SRP. In the remainder of this section, we derive an approximate solution for the maximum processor sharing case.
5.1 Approximate solution for maximum processor sharing
The approximate solution that we present in this section assumesmaximum processor sharing, and is applicable to any open queueing network in which each job class needs at most two resources. We first consider the solution for the example model of Figure 2. The first approximation is that we assume that for the jobs that require only one resource (the class 1 and class 2 jobs in our example), the regular multiple-class M/M/1 expressions apply:
Ni≈ ρi
1−ρi−ρ3 and Ri≈
S
1−ρi−ρ3 (fori= 1,2) (4) Next, we observe that the service rate of class 3 jobs depends on the number of class 3 jobs, and the maximum of the number of class 1 jobs and the
number of class 2 jobs in the queue. Let us denote this maximum by N1,2. We now assume that R3 ≈ (1 +N1,2+N3)S. Combining this with Little’s law,N3=λ3R3, we can solveR3:
R3≈1 +N1,2
1−ρ3 S (5)
Now the only thing we still need is an estimate forN1,2. A lowerbound ofN1,2 can be derived when assuming that the number of jobs in queue 1 and queue 2 are independent, resulting following expression (we omit the derivation):
N1,2 ≥E(max{N1, N2}) = ρ1 1−(ρ1+ρ3)+ ρ2 1−(ρ2+ρ3)− ρ1ρ2 (1−ρ3)2−ρ1ρ2 (6)
We get a better approximation forN1,2 when compensating for the depen-dency. Experiments show that the following approximation gives good results:
N1,2≈1−(ρρ1 1+ρ3)+ ρ2 1−(ρ2+ρ3)− ρ1ρ2 (1−ρ3)−ρ1ρ2 (7) Table 3. Simulation of PS disciplines
maximum minimum
λ R1,2 R3 R1,2 R3
0.10 1.25 1.39 1.37 1.13 0.20 1.69 2.02 1.95 1.38 0.30 2.63 3.36 3.14 1.92
Table 4. Analytical results of maximum PS Simulation Analytical λ R1,2 R3 R1,2 R3 0.10 1.25 1.39 1.25 1.38 0.20 1.69 2.02 1.67 2.02 0.30 2.63 3.36 2.50 3.36 5.2 Generalised solution
The above result can be generalised to any model in which every job requires at most 2 resources. Consider a job of class arequiring resourcesQ and R, denoting the utilisation of class a jobs on the resources by ρa. The total utilisation of other jobs using resourceQis denoted byρb, and of other jobs using resourceRbyρc; these can be jobs using only one resource, but they can also belong to other classes needing two resources. ρQ is the total utilisation of resourceQ, i.e.,ρQ=ρa+ρb; likewise,ρR=ρa+ρc. In a similar way as for our original example model, we use an approximation forNbc, the expected value of the maximum of the number of non-class-a-customers:
Nbc≈ ρb 1−ρQ + ρc 1−ρR− ρbρc 1−ρa−ρbρc (8) This finally results in the following expression for the response time:
Ra= 1 +Nbc
1−ρa S (9)
Also in the general case, we use the regular M/M/1 solution as an approxi-mation for job classes that need only one resource.
5.3 Validation
Table 4 compares our approximate solution to the simulation results from section 4.3. For this particular example, with a balanced workload, the ap-proximation appears to be very accurate.
To validate the generalised solution, we consider an extension of the DM architecture from our original example with an extra node P3, as shown in Figure 3. We assume that, unlike in the first example, the central node P0 does not send or receive messages, so that all the communications require two links simultaneously. We again distinguish three traffic classes, with arrival ratesλ1,λ2 andλ3: (1) messages betweenP1andP2(usingLAandLB); (2) messages betweenP2andP3(usingLBandLC); (3) messages betweenP1and
P3(usingLAandLC). Figure 4 shows the queueing model for this situation.
P3
LC
P1 P0 P2
LA LB
Figure 3. 4-Node DM architecture
LA LC λ1 λ3 λ2 LB
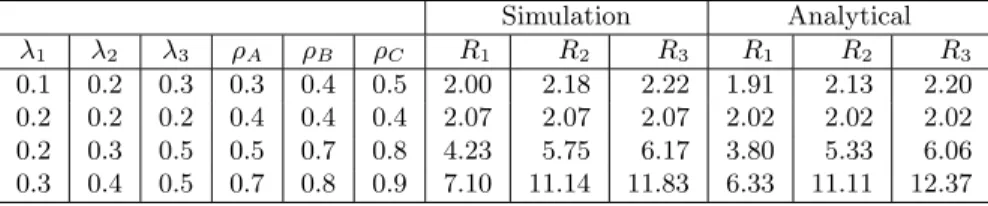
Figure 4. Queueing model of the architecture Table 5 compares the analytical approximations to simulation results for this model, for several combinations of arrival rates. Although the errors are slightly higher for this model than for our standard example, the analytical predictions still remain within approximately 10% of the simulation results.
Table 5. Analytical results vs. simulation for a more general model Simulation Analytical λ1 λ2 λ3 ρA ρB ρC R1 R2 R3 R1 R2 R3 0.1 0.2 0.3 0.3 0.4 0.5 2.00 2.18 2.22 1.91 2.13 2.20 0.2 0.2 0.2 0.4 0.4 0.4 2.07 2.07 2.07 2.02 2.02 2.02 0.2 0.3 0.5 0.5 0.7 0.8 4.23 5.75 6.17 3.80 5.33 6.06 0.3 0.4 0.5 0.7 0.8 0.9 7.10 11.14 11.83 6.33 11.11 12.37
6 Conclusions and future work
In this paper we considered simultaneous resource possession in the context of open queueing models for parallel processing systems. We identified three classes of scheduling disciplines for SRP and presented simulation results of their performance. For the maximum processor sharing discipline, we de-rived an analytical approximation, applicable to any open queueing network
in which each job requires at most two resources simultaneously. Comparison with simulation results shows that the approximation errors are small.
Many practical and challenging SRP problems remain to be investigated. Some research issues directly related to the problem considered in this pa-per are to find (approximate) solutions for other disciplines, in particular minimum processor sharing, and a generalisation of the maximum processor sharing solution to allow for jobs requiring more than two resources.
Acknowledgement
This paper is based on research from the Testbed project9, a collaboration of ABP, the Dutch Tax Department, ING Group, IBM and the Telematica Instituut, finan-cially supported by the Dutch Ministry of Economic Affairs. The project develops a language, methods and tools for business process modelling and (re)design in the financial sector, and the results have been applied in several real-life business cases. We thank Piet Boekhoudt for his useful suggestions to improve this paper. References
1. P.A. Jacobson and E.D. Lazowska. Analyzing queueing networks with simul-taneous resource possession. Comm. of the ACM, 25:142–151, February 1982. 2. S.C. Agrawal and J.P. Buzen. The aggregate server method for analyzing
serialization delays. ACM Trans. on Computer Systems, 1:116–143, May 1983. 3. J.S. Kaufman and W.S. Wong. Approximate analysis of a cyclic queueing network with applications to a simultaneous resource possession problem. Per-formance Evaluation, 11(3):187–200, 1990.
4. C.A. Courcoubetis and M.I. Reiman. Optimal control of queueing systems with simultaneous service requirements. IEEE Trans. on Automatic Control, 32(8):717–727, 1987.
5. D.J. Freund and J.N. Bexfield. A new aggregation approximation procedure for solving closed queueing networks with simultaneous resource possession. InProc. 1983 ACM SIGMETRICS Conference on Measuring and Modeling of Computer Systems, pages 214–223, 1983.
6. M. Ghodsi and K. Kant. Performance modeling of concurrent systems under resource constraints. In D.J. Evans et al., editors, Proc. Parallel Computing ’89, pages 589–594, Leiden, the Netherlands, August 1989.
7. J. Visschers, I. Adan, and J. Wessels. Product form solutions to production systems with simulaneous resource possession. Tech. rep. 99–15, Eindhoven University of Technology, Dept. of Mathematics and Computing Science, 1999. 8. V.F. Nicola. A single server queue with mixed types of interruptions. Acta
Informatica, 23:465–486, 1986.
9. H. Franken and W. Janssen. Get a grip on changing business processes: Results from the Testbed project. Knowledge & Process Management, winter 1998.