Bilingual LSA Based LM Adaptation for Spoken Language Translation
Full text
Figure
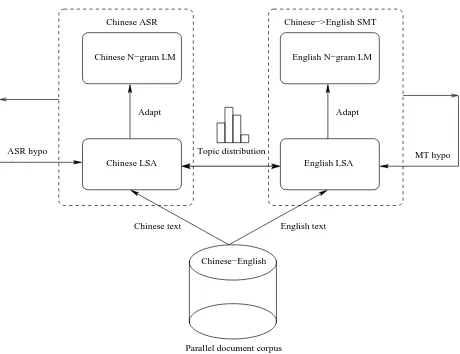
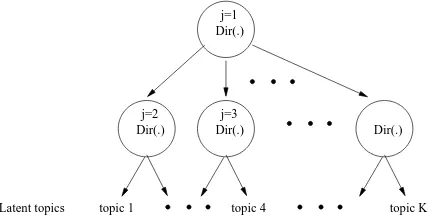
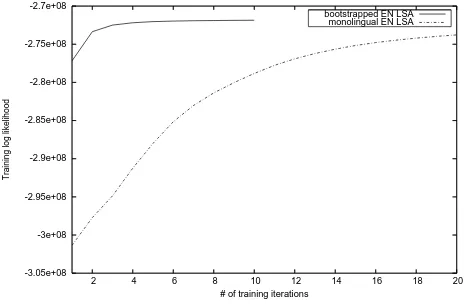
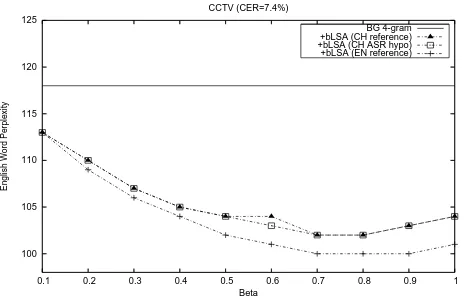
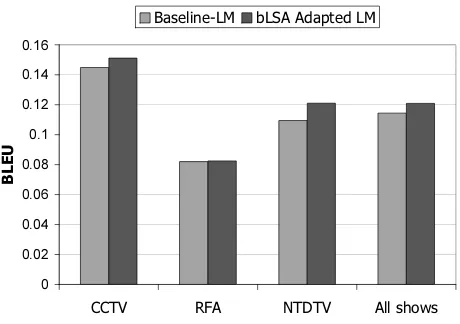
Related documents
3 shows the results of tests in which pulse rate, carrier frequency and playback level were systematically varied; pulse rates of alternatives had values (40 and 75 pulses s –1
Deze deelvraag luidt ‘welke factoren zijn volgens de literatuur en de data die worden gebruikt in dit onderzoek van invloed op de hoogte van de beloning van topfunctionarissen
Van de respondenten die op het moment van invullen van de vragenlijst benzodiazepinen gebruikten gaf in totaal 52,2% aan dat zij de intentie hadden om te stoppen; 31,8%
The project was divided to three key areas of inquiry, the office culture (exploring issues such as banter, social relationships at work, office conversations, dress code,
Results:- The following table and graph shows the depression among male and female adolescent students in Haryana govt.. Table shows a significant difference between male and
ABS: Australian Bureau of Statistics; AOA NJRR: Australian Orthopaedic Association National Joint Replacement Registry; CCD: Census Collection District; IRSAD: Index for
This paper seeks to help fill this gap by describing aspects of design, study site selection, technical chal- lenges encountered and solutions developed to maintain quality control
