1329
Exemplar Encoder-Decoder for Neural Conversation Generation
Gaurav Pandey, Danish Contractor, Vineet Kumar and Sachindra Joshi IBM Research AI
New Delhi, India
{gpandey1, dcontrac, vineeku6, jsachind}@in.ibm.com
Abstract
In this paper we present the Exemplar Encoder-Decoder network (EED), a novel conversation model that learns to uti-lize similar examples from training data to generate responses. Similar conver-sation examples (context-response pairs) from training data are retrieved using a traditional TF-IDF based retrieval model. The retrieved responses are used to cre-ate exemplar vectors that are used by the decoder to generate the response. The contribution of each retrieved response is weighed by the similarity of correspond-ing context with the input context. We present detailed experiments on two large data sets and find that our method out-performs state of the art sequence to se-quence generative models on several re-cently proposed evaluation metrics. We also observe that the responses generated by the proposed EED model are more in-formative and diverse compared to exist-ing state-of-the-art method.
1 Introduction
With the availability of large datasets and the recent progress made by neural meth-ods, variants of sequence to sequence learning (seq2seq) (Sutskever et al., 2014) architectures have been successfully applied for building con-versational systems (Serban et al.,2016, 2017b). However, despite these methods being the state-of-the art frameworks for conversation generation, they suffer from problems such as lack of diver-sity in responses and generation of short, repetitive and uninteresting responses (Liu et al.,2016; Ser-ban et al., 2016, 2017b). A large body of recent
literature has focused on overcoming such chal-lenges (Li et al.,2016a;Lowe et al.,2017).
In part, such problems arise as all information required to generate responses needs to be cap-tured as part of the model parameters learnt from the training data. These model parameters alone may not be sufficient for generating natural con-versations. Therefore, despite providing enormous amount of data, neural generative systems have been found to be ineffective for use in real world applications (Liu et al.,2016).
In this paper, we focus our attention on closed domain conversations. A characteristic feature of such conversations is that over a period of time, some conversation contexts1are likely to have oc-curred previously (Lu et al.,2017b). For instance, Table1shows some contexts from the Ubuntu dia-log corpus. Each row presents an input diadia-log con-text with its corresponding gold response followed by a similar context and response seen in train-ing data – as can be seen, contexts for “installing dms”, “sharing files”, “blocking ufw ports” have all occurred in training data. We hypothesize that being able to refer to training responses for pre-viously seen similar contexts could be a helpful signal to use while generating responses.
In order to exploit this aspect of closed do-main conversations we build our neural encoder-decoder architecture called theExemplar Encoder Decoder (EED), that learns to generate a response for a given context by exploitingsimilarcontexts from training conversations. Thus, instead of hav-ing the seq2seq model learn patterns of language only from aligned parallel corpora, we assist the model by providing it closely related (similar) samples from the training data that it canrefer to while generating text.
Specifically, given a contextc, we retrieve a set
Input Context Gold Response Similar Context in training data Associated Response
U1 if you want autologin install a dm of some sort
lightdm,gdm,kdm, xdm, slim, etc. U1
if you’re running a dm, it will probably
restart x e.g.gdm,kdm,xdm
U2 what is a dm U2 whats a dm?
U1 is it possible to share a file in one user’s home directory with another user?
so chmod 777 should do it, right? U1
howto set right permission for my home directory?
chmodand chown? u mean that sintax
U2 if you set permissions (to ’group’,’other’or with an acl) U2 but which is the syntax to set permissionfor my user in my home user directory ?
U1
is there a way to block all ports in ufw and only allow the ports that have been allowed?
do i need to use ipt-ables in order to use ufw?
U1 is ufw blocking connections to all ports by default?
how do i block all ports with ufw?
U2 try to get familiar with configuring
ip-tables U2 no, all ports are open by default.
U1
how do i upgrade on php beyond 5.3.2 on ubuntu using apt-get ? ? ? this version is a bit old
lucid,10.04 ubuntu 10.04.4 lts U1
hello!, how can i upgrade apt-get?(i have version 0.7.9 installed but i need to up-date to latest)
I’m usingubuntuserver10.04 64
U2 which version of ubuntu are you using? U2 sudo apt-get upgrade apt-get U1 what version of ubuntu do you have?
Table 1: Sample input contexts and corresponding gold responses from Ubuntuvalidationdataset along with similar contexts seen in training data and their corresponding responses. We refer to training data as training data for the Ubuntu corpus. The highlighted words are common between the gold response and the exemplar response.
of context-response pairs(c(k), r(k)),1 ≤k ≤K using an inverted index of training data. We create anexemplar vectore(k)by encoding the response r(k)(also referred to as exemplar response) along with an encoded representation of the current con-text c. We then learn theimportanceof each ex-emplar vectore(k)based on the likelihood of it be-ing able to generate the ground truth response. We believe that e(k) may contain information that is helpful in generating the response. Table 1 high-lights the words in exemplar responses that appear in the ground truth response as well.
Contributions: We present a novel Exemplar Encoder-Decoder (EED) architecture that makes use of similar conversations, fetched from an index of training data. The retrieved context-response pairs are used to create exemplar vec-tors which are used by the decoder in the EED model, to learn the importance of train-ing context-response pairs, while generattrain-ing re-sponses. We present detailed experiments on the publicly benchmarked Ubuntu dialog corpus data set (Lowe et al., 2015) as well a large collection of more than 127,000 technical support conversa-tions. We compare the performance of the EED model with the existing state of the art generative models such as HRED (Serban et al., 2016) and VHRED (Serban et al.,2017b). We find that our model out-performs these models on a wide vari-ety of metrics such as the recently proposed Activ-ity EntActiv-itymetrics (Serban et al.,2017a) as well as Embedding-based metrics (Lowe et al.,2015). In addition, we present qualitative insights into our results and we find that exemplar based responses
are more informative and diverse.
The rest of the paper is organized as follows. Section2briefly describes the recent works in neu-ral dialogue generation The details of the proposed EED model for dialogue generation are described in detail in Section 3. In Section 4, we describe the datasets as well as the details of the models used during training. We present quantitative and qualitative results of EED model in Section5.
2 Related Work
In this section, we compare our work against other data-driven end-to-end conversation models. End-to-end conversation models can be further classi-fied into two broad categories —generationbased models andretrievalbased models.
in-formative responses and adds diversity to response generation. Models that explicitly incorporate di-versity in response generation have also been stud-ied in literature (Li et al., 2016b; Vijayakumar et al., 2016; Cao and Clark, 2017; Zhao et al.,
2017).
Our work differs from the above as none of these above approaches utilize similar conversa-tion contexts observed in the training data explic-itly.
Retrieval based models on the other hand treat the conversation context as a query and obtain a set of responses using information retrieval (IR) techniques from the conversation logs (Ji et al.,
2014). There has been further work where the responses are further ranked using a deep learn-ing based model (Yan et al., 2016a,b;Qiu et al.,
2017). On the other hand of the spectrum, end-to-end deep learning based rankers have also been employed to generate responses (Wu et al.,2017;
Henderson et al.,2017). Recently a framework has also been proposed that uses a discriminative di-alog network that ranks the candidate responses received from a response generator network and trains both the networks in an end to end manner (Lu et al.,2017a).
In contrast to the above models, we use the in-put contexts as well as the retrieved responses for generating the final responses. Contemporaneous to our work, a generative model for machine trans-lation that employs retrieved transtrans-lation pairs has also been proposed (Gu et al.,2017). We note that while the underlying premise of both the papers remains the same, the difference lies in the mech-anism of incorporating the retrieved data.
3 Exemplar Encoder Decoder
3.1 Overview
A conversation consists of a sequence of utter-ances. At a given point in the conversation, the ut-terances expressed prior to it are jointly referred to as the context. The utterance that immediately fol-lows the context is referred to as the response. As discussed in Section1, given a conversational con-text, we wish to to generate a response by utiliz-ing similar context-response pairs from the train-ing data. We retrieve a set ofKexemplar context-response pairs from an inverted index created us-ing the trainus-ing data in an off-line manner. The input and the retrieved context-response pairs are then fed to the Exemplar Encoder Decoder (EED)
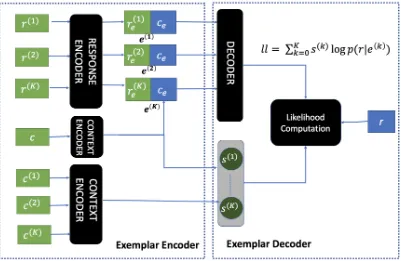
network. A schematic illustration of the EED net-work is presented in Figure1. The EED encoder combines the input context and the retrieved re-sponses to create a set ofexemplar vectors. The EED decoder then uses the exemplar vectors based on the similarity between the input context and re-trieved contexts to generate a response. We now provide details of each of these modules.
3.2 Retrieval of Similar Context-Response Pairs
Given a large collection of conversations as (context, response) pairs, we index each re-sponse and its corresponding context intf −idf vector space. We further extract the lastturnof a conversation and index it as an additional attribute of the context-response document pairs so as to al-low directed queries based on it.
Given an input contextc, we construct a query that weighs the last utterance in the context twice as much as the rest of the context and use it to retrieve the top-k similar context-response pairs from the index based on a BM25 (Robertson et al., 2009) retrieval model. These retrieved pairs form our exemplar context-response pairs (c(k), r(k)), 1≤k≤K.
3.3 Exemplar Encoder Network
Given the exemplar pairs (c(k), r(k)), 1 ≤ k ≤ K and an input context-response pair (c, r), we feed the input contextcand the exemplar contexts c(1), . . . , c(K) through an encoder to generate the embeddings as given below:
ce=Encodec(c)
c(ek)=Encodec(c(k)),1≤k≤K
Note that we do not constrain our choice of en-coder and that any parametrized differentiable ar-chitecture can be used as the encoder to gener-ate the above embeddings. Similarly, we feed the exemplar responses r(1), . . . , r(K) through a re-sponse encoder to generate rere-sponse embeddings re(1), . . . , re(K), that is,
r(ek) =Encoder(r(k)),1≤k≤K (1)
in-Figure 1: A schematic illustration of the EED network. The input context-response pair is(c, r), while the exemplar context-response pairs are(c(k), r(k)),1≤k≤K.
formation about similar responses along with the encoded input context representation.
e(k)= [ce;re(k)],1≤k≤K (2)
The exemplar vectorse(k),1≤k≤Kare
fur-ther used by the decoder for generating the ground truth response as described in the next section.
3.4 Exemplar Decoder Network
Recall that we want the exemplar responses to help generate the responses based on how similar the corresponding contexts are with the input context. More similar an exemplar context is to the input context, higher should be its effect in generating the response. To this end, we compute the similar-ity scoress(k),1 ≤ k ≤ K using the encodings computed in Section3.3as shown below.
s(k) = exp(c
T
ec
(k)
e ) PK
l=1exp(cTec
(l)
e )
(3)
Next, each exemplar vector e(k) computed in Section3.3, is fed to a decoder, where the decoder is responsible for predicting the ground truth re-sponse from the exemplar vector. Letpdec(r|e(k))
be the distribution of generating the ground truth response given the exemplar embedding. The ob-jective function to be maximized, is expressed as a
function of the scoress(k), the decoding distribu-tion pdec and the exemplar vectorse(k) as shown below:
ll=
K X
k=1
s(k)logpdec(r|e(k)) (4)
Note that we weigh the contribution of each exem-plar vector to the final objective based on how sim-ilar the corresponding context is to the input con-text. Moreover, the similarities are differentiable function of the input and hence, trainable by back propagation. The model should learn to assign higher similarities to the exemplar contexts, whose responses are helpful for generating the correct re-sponse.
The model description uses encoder and de-coder networks that can be implemented using any differentiable parametrized architecture. We dis-cuss our choices for the encoders and decoder in the next section.
3.5 The Encoders and Decoder
[image:4.595.99.500.63.324.2]hierarchies—at the word level and then at the ut-terance (sentence) level. We use a hierarchical re-current encoder—popularly employed as part of the HRED framework for generating responses and query suggestions (Sordoni et al.,2015a; Ser-ban et al.,2016,2017b). The word-level encoder encodes the vector representations of words of an utterance to an utterance vector. Finally, the utterance-level encoder encodes the utterance vec-tors to a context vector.
Let (u1, . . . ,uN) be the utterances present in the context. Furthermore, let(wn1, . . . , wnMn)be
the words present in thenthutterance for1≤n≤ N. For each word in the utterance, we retrieve its corresponding embedding from an embedding matrix. The word embedding forwnmwill be de-noted aswenm. The encoding of thenthutterance can be computed iteratively as follows:
hnm=f1(hnm−1, wenm),1≤m≤Mn (5)
We use an LSTM (Hochreiter and Schmidhuber,
1997) to model the above equation. The last hid-den statehnMn is referred to as the utterance
en-coding and will be denoted ashn.
The utterance-level encoder takes the utterance encodings h1, . . . , hN as input and generates the encoding for the context as follows:
cen=f2(cen−1, hn),1≤n≤N (6)
Again, we use an LSTM to model the above equa-tion. The last hidden stateceN is referred to as the context embedding and is denoted asce.
A single level LSTM is used for embedding the response. In particular, let (w1, . . . , wM) be the sequence of words present in the response. For each wordw, we retrieve the corresponding word embedding we from a word embedding matrix. The response embedding is computed from the word embeddings iteratively as follows:
rem=g(rem−1, wem),1≤m≤M (7)
Again, we use an LSTM to model the above equa-tion. The last hidden stateremis referred to as the response embedding and is denoted asre.
4 Experimental Setup
4.1 Datasets
4.1.1 Ubuntu Dataset
We conduct experiments on Ubuntu Dialogue Cor-pus (Lowe et al., 2015)(v2.0)2. Ubuntu dialogue corpus has about 1M context response pairs along with a label. The label value1 indicates that the response associated with a context is the correct response and is incorrect otherwise. As we are only interested in positive labeled data we work withlabel= 1. Table2depicts some statistics for the dataset.
Size
Training Pairs 499,873 Validation Pairs 19,560 Test Pairs 18,920
[image:5.595.353.481.256.338.2]|V| 538,328
Table 2: Dataset statistics for Ubuntu Dialog Cor-pus v2.0 (Lowe et al.,2015), where|V|represents the size of vocabulary.
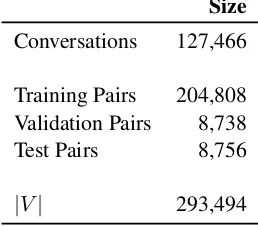
4.1.2 Tech Support Dataset
We also conduct our experiments on a large tech-nical support dataset with more than 127K con-versations. We will refer to this dataset as Tech Support dataset in the rest of the paper. Tech Support dataset contains conversations pertaining to an employee seeking assistance from an agent (technical support) — to resolve problems such as password reset, software installation/licensing, and wireless access. In contrast to Ubuntu dataset, this dataset has clearly two distinct users — em-ployee and agent. In our experiments we model theagentresponses only.
For each conversation in the tech support data, we sample context and response pairs to create a dataset similar to the Ubuntu dataset format. Note that multiple context-response pairs can be gen-erated from a single conversation. For each con-versation, we sample 25% of the possible context-response pairs. We create validation pairs by selecting 5000 conversations randomly and sam-pling context response pairs). Similarly, we create test pairs from a different subset of 5000 conver-sations. The remaining conversations are used to
2https://github.com/rkadlec/
create training context-response pairs. Table3 de-picts some statistics for this dataset:
Size
Conversations 127,466
Training Pairs 204,808 Validation Pairs 8,738
Test Pairs 8,756
[image:6.595.116.245.104.217.2]|V| 293,494
Table 3: Dataset statistics for Tech Support dataset.
4.2 Model and Training Details
The EED and HRED models were implemented using the PyTorch framework (Paszke et al.,
2017). We initialize the word embedding matrix as well as the weights of context and response en-coders from the standard normal distribution with mean 0and variance 0.01. The biases of the en-coders and decoder are initialized with 0. The word embedding matrix is shared by the context and response encoders. For Ubuntu dataset, we use a word embedding size of 600, whereas the size of the hidden layers of the LSTMs in context and response encoders and the decoder is fixed at 1200. For Tech support dataset, we use a word em-bedding size of128. Furthermore, the size of the hidden layers of the multiple LSTMs in context and response encoders and the decoder is fixed at 256. A smaller embedding size was chosen for the Tech Support dataset since we observed much less diversity in the responses of the Tech Support dataset as compared to Ubuntu dataset.
Two different encoders are used for encoding the input context (not shown in Figure1for sim-plicity). The output of the first context encoder is concatenated with the exemplar response vectors to generate exemplar vectors as detailed in Sec-tion3.3. The output of the second context encoder is used to compute the scoring function as detailed in Section 3.4. For each input context, we re-trieve5similar context-response pairs for Ubuntu dataset and3context-response pairs for Tech sup-port dataset using the tf-idf mechanism discussed in Section3.2.
We use the Adam optimizer (Kingma and Ba,
2014) with a learning rate of1e−4 for training the model. A batch size of20 samples was used
during training. In order to prevent overfitting, we use early stopping with log-likelihood on valida-tion set as the stopping criteria. In order to gen-erate the samples using the proposed EED model, we identify the exemplar context that is most sim-ilar to the input context based on the learnt scor-ing function discussed in Section 3.4. The cor-responding exemplar vector is fed to the decoder to generate the response. The samples are gener-ated using a beam search with width5. The av-erage per-word log-likelihood is used to score the beams.
5 Results & Evaluation
5.1 Quantitative Evaluation
5.1.1 Activity and Entity Metrics
A traditional and popular metric used for compar-ing a generated sentence with a ground truth sen-tence is BLEU (Papineni et al., 2002) and is fre-quently used to evaluate machine translation. The metric has also been applied to compute scores for predicted responses in conversations, but it has been found to be less indicative of actual perfor-mance (Liu et al.,2016;Sordoni et al.,2015a; Ser-ban et al., 2017a), as it is extremely sensitive to the exact words in the ground truth response, and gives equal importance to stop words/phrases and informative words.
Serban et al. (2017a) recently proposed a new set of metrics for evaluating dialogue responses for the Ubuntu corpus. It is important to highlight that these metrics have been specifically designed for the Ubuntu corpus and evaluate a generated response with the ground truth response by com-paring the coarse level representation of an utter-ance (such as entities, activities, Ubuntu OS com-mands). Here is a brief description of each metric:
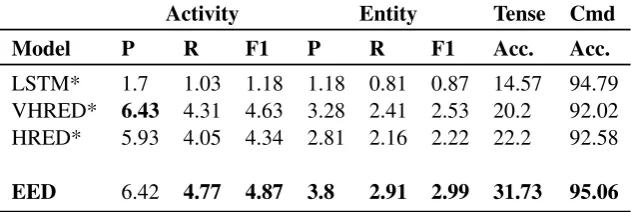
• Activity: Activity metric compares the ac-tivities present in a predicted response with the ground truth response. Activity can be thought of as a verb. Thus, all the verbs in a response are mapped to a set of manually identified list of 192 verbs.
Activity Entity Tense Cmd
Model P R F1 P R F1 Acc. Acc.
LSTM* 1.7 1.03 1.18 1.18 0.81 0.87 14.57 94.79 VHRED* 6.43 4.31 4.63 3.28 2.41 2.53 20.2 92.02 HRED* 5.93 4.05 4.34 2.81 2.16 2.22 22.2 92.58
[image:7.595.141.457.62.168.2]EED 6.42 4.77 4.87 3.8 2.91 2.99 31.73 95.06
Table 4: Activity & Entity metrics for the Ubuntu corpus. LSTM*, HRED* & VHRED* as reported by Serban et al. (2017a).
• Tense: This measure compares the time tense of ground truth with predicted response.
• Cmd: This metric computes accuracy by comparing commands identified in ground truth utterance with a predicted response.
Table 4 compares our model with other re-cent generative models (Serban et al., 2017a) — LSTM (Shang et al.,2015), HRED (Serban et al.,
2016) & VHRED (Serban et al.,2017b).We do not compare our model with Multi-Resolution RNN (MRNN) (Serban et al.,2017a), as MRNN explic-itly utilizes the activities and entities during the generation process. In contrast, the proposed EED model and the other models used for comparison are agnostic to the activity and entity information. We use the standard script3 to compute the met-rics.
The EED model scores better than generative models on almost all of the metrics, indicating that we generate moreinformativeresponses than other state-of-the-art generative based approaches for Ubuntu corpus. The results show that re-sponses associated with similar contexts may con-tain the activities and entities present in the ground truth response, and thus help in response genera-tion. This is discussed further in Section5.2. Ad-ditionally, we compared our proposed EED with a retrieval only baseline. The retrieval baseline achieves an activity F1 score of 4.23 and entity F1 score of 2.72 compared to 4.87 and 2.99 re-spectively achieved by our method on the Ubuntu corpus.
The Tech Support dataset is not evaluated using the above metrics, since activity and entity infor-mation is not available for this dataset.
3 https://github.com/julianser/Ubuntu-Multiresolution-Tools/blob/master/ActEntRepresentation/eval file.sh
5.1.2 Embedding Metrics
Embedding metrics (Lowe et al.,2017) were pro-posed as an alternative to word by word compar-ison metrics such as BLEU. We use pre-trained Google news word embeddings4 similar to Ser-ban et al. (2017b), for easy reproducibility as these metrics are sensitive to the word embeddings used. The three metrics of interest utilize the word vec-tors in ground truth response and a predicted re-sponse and are discussed below:
• Average: Average word embedding vec-tors are computed for the candidate response and ground truth. The cosine similarity is computed between these averaged embed-dings. High similarity gives as indication that ground truth and predicted response have similar words.
• Greedy: Greedy matching score finds the most similar word in predicted response to ground truth response using cosine similarity.
• Extrema: Vector extrema score computes the maximum or minimum value of each dimen-sion of word vectors in candidate response and ground truth.
Of these, the embedding average metric is the most reflective of performance for our setup. The extrema representation, for instance, is very sensi-tive to text length and becomes ineffecsensi-tive beyond single length sentences(Forgues et al.,2014). We use the publicly available script5 for all our com-putations. As the test outputs for HRED are not available for Technical Support dataset, we use our
4GoogleNews-vectors-negative300.bin fromhttps://
code.google.com/archive/p/word2vec/ 5https://github.com/julianser/
Ubuntu Tech Support
Model Average Greedy Extrema Average Greedy Extrema
HRED 0.5131 0.4103 0.3263 0.6372 0.5100 0.4355
[image:8.595.122.478.63.127.2]EED 0.5528 0.4172 0.3134 0.6420 0.5125 0.4356
Table 5: Embedding Metrics (Lowe et al.,2015) for Ubuntu and Technical Support Corpus.
Ubuntu Tech Support
Model distinct-1 distinct-2 distinct-3 distinct-1 distinct-2 distinct-3
HRED 1154 8668 22417 645 3510 6365
[image:8.595.72.552.274.635.2]EED 1173 9572 29447 732 4149 7877
Table 6: The number of unique tokens, token-pairs and token-triplets for Ubuntu and Technical Support Corpus.
Input Context (C) and exemplar response (R) Generated/Ground Truth Responses
1
C:i want to check ntfs file systems. is fsck ok with ntfs.
→no , you ’d need to use chkdsk from windows.→
R:i already symlinked ntfsfix to fsck.ntfsand am scanning the unmounted devices
HRED:i know , but i dont know how to do that VHRED:how can i do that ?
EED:i am trying to usentfs3g i have a windows partition. GT:i dont have windows installed
2
C:anyone help me ?→seems that its detecting grub , have you tried checking continue without installing grub ?
R:try the livecd... you ca n’t boot into linux unlessgrub install
HRED:yes i did , but i have no idea how to fix it VHRED:yes i did. i dont know how to do it EED:nope not yet.grub install cdis not working GT:no i did not.
3
C:any ideas on my mplayer problem ?→reinstall. apt-get purge mplayer then reinstall
R:but half my system depends on thispackage...
HRED:I did that , but it didn’t work VHRED:I dont know how to do that EED:does n t work.packagedoes n t work GT:that does n’t seem as a solution
4
C:any of you guys in here know how to take a package on launchpad and recompile it and submit to your own ppa ? https : //launchpad.net/ mojocode/+archive /ppa ¡ ¡ i ’m trying to take the nginx package and install the rtmp module→could n’t you download the source and just commit it to your own ?
R:ineedprop . drivers
HRED:I don’t know how to do that , I just want to know if there is a way to do it VHRED:no , I just want to make it so I can use it EED:ineedto get the source package. package manager is not available
GT:so i figured how how to copy into my private ppa . any idea how to download those source files maybe and make modifications to resubmit and recompile ? https :
//launchpad.net / blendedbyus/+archive/master/+packages
5
C:hi people , can you help me uninstall a package ? i did dpkg -i virtualbox-4.2 4.2.2-81494 ubuntu precise
amd64.deb. how do i uninstall it , i ca n’t find the package from apt-get→sudo apt-get purge virtualbox should work fine→package virtualbox is not installed , so not removed→does n’t work : (
R: sudo dpkg– remove – force<package>
HRED:what version of ubuntu ?
VHRED:did you try sudo apt-get install virtualbox-ose EED: sudo dpkgreconfigure package package manager
[image:8.595.71.541.278.636.2]GT:if you ca n’t find the package ; sudo aptitude search virtualbox
Table 7: Contexts, exemplar responses and responses generated by HRED, VHRED and the proposed EED model. We use the published responses for HRED and VHRED. GT indicates the ground truth response. The change of turn is indicated by→. The highlighted words inboldare common between the exemplar response and the response predicted by EED.
own implementation of HRED. Table5compares our model with HRED, and depicts that our model scores better on all metrics for Technical Support
dataset, and on majority of the metrics for Ubuntu dataset.
EED model on activity and entity metrics are much more significant than those on embedding metrics. This suggests that the EED model is bet-ter able to capture the specific information (objects and actions) present in the conversations.
Finally, we evaluate the diversity of the gener-ated responses for EED against HRED by count-ing the number of unique tokens, token-pairs and token-triplets present in the generated responses on Ubuntu and Tech Support dataset. The results are shown in Table6. As can be observed, the re-sponses in EED have a larger number of distinct tokens, token-pairs and token-triplets than HRED, and hence, are arguably more diverse.
5.2 Qualitative Evaluation
Table 7 presents the responses generated by HRED, VHRED and the proposed EED for a few selected contexts along with the corresponding similar exemplar responses. As can be observed from the table, the responses generated by EED tend to be more specific to the input context as compared to the responses of HRED and VHRED. For example, in conversations1and2we find that both HRED and VHRED generate simple generic responses whereas EED generates responses with additional information such as the type of disk par-tition used or a command not working. This is also confirmed by the quantitative results obtained using activity and entity metrics in the previous section. We further observe that the exemplar re-sponses contain informative words that are utilized by the EED model for generating the responses as highlighted in Table7.
6 Conclusions
In this work, we propose a deep learning method, Exemplar Encoder Decoder (EED), that given a conversation context uses similar contexts and cor-responding responses from training data for gen-erating a response. We show that by utilizing this information the system is able to outperform state of the art generative models on publicly available Ubuntu dataset. We further show improvements achieved by the proposed method on a large col-lection of technical support conversations.
While in this work, we apply the exemplar en-coder deen-coder network on conversational task, the method is generic and could be used with other tasks such as question answering and machine translation. In our future work we plan to extend
the proposed method to these other applications.
Acknowledgements
We are grateful to the anonymous reviewers for their comments that helped in improving the pa-per.
References
Kris Cao and Stephen Clark. 2017. Latent variable di-alogue models and their diversity. InProceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics, vol-ume 2, pages 182–187.
Gabriel Forgues, Joelle Pineau, Jean-Marie Larchevˆeque, and R´eal Tremblay. 2014. Boot-strapping dialog systems with word embeddings. In Nips, modern machine learning and natural language processing workshop, volume 2.
Jiatao Gu, Yong Wang, Kyunghyun Cho, and Vic-tor OK Li. 2017. Search engine guided non-parametric neural machine translation. arXiv preprint arXiv:1705.07267.
Matthew Henderson, Rami Al-Rfou’, Brian Strope, Yun-Hsuan Sung, L´aszl´o Luk´acs, Ruiqi Guo, San-jiv Kumar, Balint Miklos, and Ray Kurzweil. 2017. Efficient natural language response suggestion for smart reply. CoRR, abs/1705.00652.
Sepp Hochreiter and Jurgen Schmidhuber. 1997. Long short-term memory. Neural computation, 9(8):1735–1780.
Zongcheng Ji, Zhengdong Lu, and Hang Li. 2014. An information retrieval approach to short text conver-sation. CoRR, abs/1408.6988.
Diederik Kingma and Jimmy Ba. 2014. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980.
Jiwei Li, Michel Galley, Chris Brockett, Jianfeng Gao, and Bill Dolan. 2016a. A diversity-promoting ob-jective function for neural conversation models. In NAACL HLT 2016, The 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Tech-nologies, San Diego California, USA, June 12-17, 2016, pages 110–119.
Chia-Wei Liu, Ryan Lowe, Iulian V Serban, Michael Noseworthy, Laurent Charlin, and Joelle Pineau. 2016. How not to evaluate your dialogue system: An empirical study of unsupervised evaluation met-rics for dialogue response generation. arXiv preprint arXiv:1603.08023.
Ryan Lowe, Nissan Pow, Iulian Serban, and Joelle Pineau. 2015. The ubuntu dialogue corpus: A large dataset for research in unstructured multi-turn dia-logue systems. arXiv preprint arXiv:1506.08909.
Ryan Thomas Lowe, Nissan Pow, Iulian Vlad Serban, Laurent Charlin, Chia-Wei Liu, and Joelle Pineau. 2017. Training end-to-end dialogue systems with the ubuntu dialogue corpus. Dialogue & Discourse, 8(1):31–65.
Jiasen Lu, Anitha Kannan, Jianwei Yang, Devi Parikh, and Dhruv Batra. 2017a. Best of both worlds: Transferring knowledge from discriminative learn-ing to a generative visual dialog model. In I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors,Advances in Neural Information Processing Systems 30, pages 314–324.
Yichao Lu, Phillip Keung, Shaonan Zhang, Jason Sun, and Vikas Bhardwaj. 2017b. A practical approach to dialogue response generation in closed domains. arXiv preprint arXiv:1703.09439.
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: a method for automatic eval-uation of machine translation. In Proceedings of the 40th annual meeting on association for compu-tational linguistics, pages 311–318. Association for Computational Linguistics.
Adam Paszke, Sam Gross, Soumith Chintala, Gre-gory Chanan, Edward Yang, Zachary DeVito, Zem-ing Lin, Alban Desmaison, Luca Antiga, and Adam Lerer. 2017. Automatic differentiation in pytorch.
Minghui Qiu, Feng-Lin Li, Siyu Wang, Xing Gao, Yan Chen, Weipeng Zhao, Haiqing Chen, Jun Huang, and Wei Chu. 2017. Alime chat: A sequence to se-quence and rerank based chatbot engine. InACL.
Stephen Robertson, Hugo Zaragoza, et al. 2009. The probabilistic relevance framework: Bm25 and be-yond.Foundations and TrendsR in Information Re-trieval, 3(4):333–389.
Iulian Serban, Alessandro Sordoni, Yoshua Bengio, Aaron C. Courville, and Joelle Pineau. 2016. Build-ing end-to-end dialogue systems usBuild-ing generative hi-erarchical neural network models. InAAAI.
Iulian Vlad Serban, Tim Klinger, Gerald Tesauro, Kar-tik Talamadupula, Bowen Zhou, Yoshua Bengio, and Aaron C Courville. 2017a. Multiresolution re-current neural networks: An application to dialogue response generation. InAAAI, pages 3288–3294.
Iulian Vlad Serban, Alessandro Sordoni, Ryan Lowe, Laurent Charlin, Joelle Pineau, Aaron C Courville, and Yoshua Bengio. 2017b. A hierarchical latent variable encoder-decoder model for generating di-alogues. InAAAI, pages 3295–3301.
Lifeng Shang, Zhengdong Lu, and Hang Li. 2015. Neural responding machine for short-text conversa-tion. InACL.
Alessandro Sordoni, Yoshua Bengio, Hossein Vahabi, Christina Lioma, Jakob Grue Simonsen, and Jian-Yun Nie. 2015a. A hierarchical recurrent encoder-decoder for generative context-aware query sugges-tion. InProceedings of the 24th ACM International on Conference on Information and Knowledge Man-agement, pages 553–562. ACM.
Alessandro Sordoni, Michel Galley, Michael Auli, Chris Brockett, Yangfeng Ji, Margaret Mitchell, Jian-Yun Nie, Jianfeng Gao, and William B. Dolan. 2015b. A neural network approach to context-sensitive generation of conversational responses. In HLT-NAACL.
Ilya Sutskever, Oriol Vinyals, and Quoc V Le. 2014. Sequence to sequence learning with neural net-works. InAdvances in neural information process-ing systems, pages 3104–3112.
Ashwin K Vijayakumar, Michael Cogswell, Ram-prasath R Selvaraju, Qing Sun, Stefan Lee, David Crandall, and Dhruv Batra. 2016. Diverse beam search: Decoding diverse solutions from neural se-quence models. arXiv preprint arXiv:1610.02424.
Oriol Vinyals and Quoc V. Le. 2015. A neural conver-sational model. CoRR, abs/1506.05869.
Yu Wu, Wei Wu, Chen Xing, Can Xu, Zhoujun Li, and Ming Zhou. 2017. A sequential matching frame-work for multi-turn response selection in retrieval-based chatbots. CoRR, abs/1710.11344.
Rui Yan, Yiping Song, and Hua Wu. 2016a. Learning to respond with deep neural networks for retrieval-based human-computer conversation system. In SI-GIR.
Rui Yan, Yiping Song, Xiangyang Zhou, and Hua Wu. 2016b. ”shall i be your chat companion?”: Towards an online human-computer conversation system. In CIKM.