Mining Online Text Data for
Sentiment and News Impact
Analysis
Thesis for the degree of Philosophiae Doctor
Trondheim, September 2013
Norwegian University of Science and Technology
Faculty of Information Technology, Mathematics
and Electrical Engineering
Department of Computer and Information Science
NTNU
Norwegian University of Science and Technology
Thesis for the degree of Philosophiae Doctor
Faculty of Information Technology, Mathematics and Electrical Engineering Department of Computer and Information Science
© Wei Wei
ISBN 978-82-471-4636-1 (printed ver.) ISBN 978-82-471-4637-8 (electronic ver.) ISSN 1503-8181
Doctoral theses at NTNU, 2013:256
Abstract
As continuous growth of Internet, an ever increasing amount of information becomes available on the World Wide Web (WWW). Information on the WWW has never been so exploded that search engines using traditional keyword-based searching strategies hardly meet people’s needs to retrieve knowledge from online massive text data. The motivation of this thesis comes from the great demands on discovering implicit knowledge and rich semantics from online documents.
This thesis focuses on analyzing online business news, a representative of objective in-formation, and online customer reviews, a representative of subjective information. For online business news, a topic driven impact analysis model is proposed that quantifies the impact of topic of a news article. With the proposed topic driven impact analysis model, an explorative visual analysis system called ImpactWheel is developed to help users better navigate and understand topic-specific companies’ impact relationships through mining rich information source of online business news.
For online customer reviews, both document overall sentiment classification and attributed-based sentiment analysis are performed. In the regard of document overall sentiment clas-sification, taking advantages of high frequency of Co-occurring Term (CoT) patterns in customer reviews, a frequency-based algorithm is proposed to generate complex features which benefits sentiment classifiers. In order to search for effective features and ignore useless ones produced by the frequency-based complex feature generation algorithm, an Effective Feature Search (EFS) framework is proposed, which makes a novel connec-tion between feature candidate generaconnec-tion and a Stochastic Local Search process. In the regard of attributed-based sentiment analysis, the concept of Sentiment Ontology Tree is proposed, which organizes a product’s domain specific knowledge as well as sentiments in a tree-like ontology structure. With the concept of SOT, a Hierarchial Learning via Senti-ment Ontology Tree (HL-SOT) approach is proposed to solve the sentiSenti-ment analysis tasks in a hierarchical classification process. To enhance the classification performance and computational efficiency of the HL-SOT approach which encodes texts using a globally unified index term space, a Localized Feature Selection (LFS) framework is developed which generates the customized index term space for each node of SOT. Since that the HL-SOT approach was estimated by a RLS estimator which is not competent enough to find max class separation and that the statistical linear classifier has been evidently proven its fallibility on classifying sentiment, a more pragmatic Hybrid Hierarchical Classifica-tion Process (HHCP) is proposed. The HHCP approach employs a linear classifier that is capable of maximizing the class separation while minimizing the within-class variance for attribute detection and turns to a rule-based solution for sentiment orientation.
Preface
This thesis is submitted to the Norwegian University of Science and Technology (NTNU) for partial fulfilment of the requirements for the degree of philosophiae doctor.
This doctoral work has been performed at the Department of Computer and Information Science (IDI), NTNU, Trondheim, with Professor Jon Atle Gulla as main supervisor and with Professor Kjetil Nørvåg and Dr. Terje Brasethvik as co-supervisors.
The thesis has been part of the research project Cooperative Mining of Independent Doc-ument Repositories (COMIDOR), funded by the Norwegian Research Council under the VERDIKT research programme, grant No. 183337.
Acknowledgements
Foremost, I would like to express my sincere gratitude to my supervisor Professor Jon Atle Gulla for his fruitful discussions, guidance and help throughout my PhD work. I would also like to thank Professor Kjetil Nøvåg and Dr. Terje Brasethvik for being my co-supervisors.
I would like to thank Associate Professor Ole J. Mengshoel for his mentoring and valuable research discussions during my research stay at Silicon Valley campus of Carnegie Mellon University.
In addition, I would like to thank Geir Solskinnsbakk and Stein L. Tomassen. We have interesting discussions on research and good cooperation on teaching. I would also like to thank Rune Sætre for his patience on teaching me Norwegian and interesting discussions we had on various topics. Thanks to the administrative and technical staff at IDI for providing me kindly assistance. I would also like to thank all my colleagues at IDI for their help and support for providing a pleasant working environment.
I am immensely grateful to my father Nanxiang Wei and my mother Yuqi Zhou who made a bad boy turn to a right track with their great love and patience. Thanks to my grandma Xianming Zhu who lead the hyperactive boy to be quiet and to get used to reading and thinking so that he can find his way to research for a PhD. I would also like to thank my parents-in-law Dapeng Ge and Xiaoli Wang for bringing up my wife and their understanding, encouragement and help when we are in Norway. Finally, I would like to give a special thank to my loving wife Wei Ge and our wonderful daughter Zhihan Wei for the love, support and happiness I have from them.
Contents
Abstract i Preface iii Acknowledgements v Contents ixI
Introduction
1
1 Introduction 31.1 Background and Motivation . . . 3
1.2 Problem Outline . . . 4
1.3 Research Context . . . 6
1.4 Research Goal and Questions . . . 6
1.4.1 Business News Analysis . . . 7
1.4.2 Customer Reviews Analysis . . . 7
1.5 Research Approach . . . 9
1.6 Research Contributions . . . 10
1.7 Papers . . . 12
1.8 Thesis Structure . . . 13
2 Technological Background 15 2.1 Feature Selection Approaches . . . 15
2.1.1 Document Frequency Feature Selection . . . 15
2.1.2 Mutual Information Feature Selection . . . 16
2.1.3 χ2-statistic Feature Selection . . . 16
2.1.4 Term Strength Feature Selection . . . 16
2.1.5 Information Gain Feature Selection . . . 17
2.2 Machine Learning Classifiers . . . 17
2.2.1 Naive Bayes Classifier . . . 17
2.2.2 Support Vector Machine . . . 18
2.2.3 K-Nearest Neighbor . . . 19 vii
2.2.4 Decision Tree Classification . . . 20
2.2.5 Linear Fisher Classifier . . . 21
2.3 Association Rule Mining . . . 22
2.4 Statistical Topic Models . . . 23
3 State of the Art 25 3.1 Impact Modeling on News . . . 25
3.1.1 News Impact Tracking and Modeling . . . 25
3.1.2 News Relatedness Calculation . . . 26
3.1.3 Model Parameter Estimation . . . 27
3.2 Sentiment Analysis on Reviews . . . 27
3.2.1 Document Overall Sentiment Analysis . . . 27
3.2.2 Attributed-based Sentiment Analysis . . . 29
3.3 Summary . . . 30
4 Research Results and Evaluation 31 4.1 An Explorative Visual Analysis System . . . 31
4.1.1 Topic Driven Impact Analysis . . . 33
4.1.2 Visual Analysis . . . 36
4.1.3 Evaluation . . . 38
4.1.4 Summary . . . 41
4.2 An Automatic Complex Feature Generation Approach . . . 42
4.2.1 Preprocessing for Unigram Feature Generation . . . 42
4.2.2 Multi-Unigram Feature Generation Algorithm . . . 42
4.2.3 Evaluation . . . 44
4.2.4 Summary . . . 45
4.3 An Effective Feature Search Framework . . . 45
4.3.1 Stochastic Local Search Model . . . 46
4.3.2 Stochastic Local Search Algorithm . . . 48
4.3.3 Evaluation . . . 49
4.3.4 Summary . . . 49
4.4 A Hierarchical Learning Approach on Sentiment Ontology Tree . . . 51
4.4.1 Sentiment Ontology Tree . . . 51
4.4.2 Sentiment Analysis with SOT . . . 52
4.4.3 Evaluation . . . 55
4.4.4 Summary . . . 57
4.5 A Localized Feature Selection Framework . . . 57
4.5.1 Why Localized Feature Selection for the HL-SOT . . . 58
4.5.2 Local Feature Selection Scope for a Node . . . 58
4.5.3 Local Hierarchy Based Feature Selection . . . 59
4.5.4 Evaluation . . . 60
4.5.5 Summary . . . 62
4.6 A Hybrid Hierarchical Classification Process . . . 62
4.6.1 Attribute Detection Task . . . 63 viii
4.6.2 Sentiment Orientation Task . . . 66
4.6.3 Evaluation . . . 69
4.6.4 Summary . . . 70
4.7 Contributions in Relation to Related Work . . . 71
4.7.1 News impact analysis . . . 71
4.7.2 Document overall sentiment classification . . . 71
4.7.3 Attributed-based Sentiment Analysis . . . 72
5 Conclusions 75 5.1 Summary of Contributions . . . 75 5.2 Future Work . . . 77 References 77
II
Selected Papers
87
6 Paper One 89 7 Paper Two 99 8 Paper Three 113 9 Paper Four 145 10 Paper Five 157 11 Paper Six 165 12 Paper Seven 175 ixPart I
Introduction
Chapter 1
Introduction
In this chapter, an overview of research work conducted during my PhD study is pre-sented. In Section 1.1, the background and motivation of the work is discussed. The problem outline for the thesis is described in Section 1.2. A brief description of research context is presented in Section 1.3, followed by research goal and questions discussed in Section 1.4. Research approach and our research contributions are respectively pre-sented in Section 1.5 and Section 1.6. Our papers that are included in this thesis are listed in Section 1.7. Finally, an overview of the structure of the rest of the thesis is given in Section 1.8.
1.1
Background and Motivation
As the internet reaches almost every corner of the world, more and more people get used to accessing information on the World Wide Web (WWW). Information on the WWW has never been so exploded. Search engine, e.g., Google1, has become an important tool for users to look for information they need. Traditional searching technologies have been studied in a relatively mature research area. However, documents retrieved by tra-ditional searching technologies only capture the explicit information and knowledge of documents. Document collections usually contain implicit knowledge and rich seman-tics, e.g., topic trends hidden behind large scales of news and sentiment expressed within customer reviews, where technologies with traditional keyword-based searching strategy do not work very well.
There are basically two kinds of information on the WWW, i.e., objective information and subjective information. The representative of objective information is online news. As the continuous growth of the online medias such as New York Times(NYT)2, an ever increas-ing amount of information is becomincreas-ing available through collections of news articles.
1http://www.google.com 2http://www.nytimes.com
4 CHAPTER 1. INTRODUCTION These news collections contain rich context information and complex inter connections. There is a great need and challenging to help people to understand and navigate through the online news with rich context in nature. With the rapid expansion of Web 2.0 technolo-gies that facilitates people to write reviews and share opinions online, a large amount of review texts are generated and available on the WWW. The online user-generated reviews are the representative of subjective information and are deemed to be rich in opinions and can be very useful information for potential customers, online advertisers as well as product manufacturers. As the amount of opinion information grows rapidly, it becomes impossible for humans to manually collect and digest these opinion-rich texts exhaus-tively. However, ranked lists of web contents retrieved by traditional search engines are insufficient for more complex data exploration and analytical tasks discussed above. The motivation for this thesis comes from the demands on discovering knowledge and semantics from online text data. The thesis focuses on analyzing both objective informa-tion, e.g., online business news, and subjective informainforma-tion, e.g., online customer reviews, of online text data. For online business news, we analyze the impact of news of compa-nies so as to better understand the affection of a specified event and its epidemic through mining news collections. For online customer reviews, we perform sentiment analysis on them so that we can recommend products to new customers using opinions from previous customers.
1.2
Problem Outline
The problems that are investigated in this thesis belong to the field of web intelligence3, which is the area of study and research of the application of artificial intelligence and information technology on the web in order to create the next generation of products, services and frameworks based on the internet. Technologies such as machine learning, data mining, and semantic web, etc. are usually involved in solving web intelligence tasks.
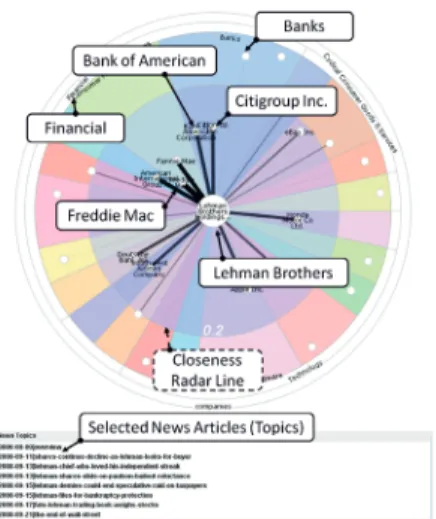
The first main problem studied in this thesis is analyzing the impact of news of companies and extracting the affection of a specified event and its epidemic through mining news collections. As we know, online business news collections may cover various topics of companies, their products, events and related people. Intuitively, each news of a company represents one topic the company is involved. With its development, a topic once it comes forth will usually impact more other companies. Information retrieval technologies help to find related news pages on a certain topic. However it is still difficult when we are trying to find innate relations of the content of multiple topic contexts. When considering underlying contexts, there are no clear answers to the questions such as “Are company A and company B are related? how are they related? and why are they related?".
To answer these questions, users usually have to examine fine-grained local-level relations
CHAPTER 1. INTRODUCTION 5 over multiple topics. For instance, the news of the bankruptcy of “Lehman Brother" had a great impact on a number of financial institutions. In order to better understand this event, the users need to check a series of news articles to find which companies are most related with Lehman and most affected by Lehman. Although some existing techniques provide valuable insights into solving the similar challenges, none of them offers a complete solution to address the following two challenges: 1). given a news topic or article of a company, how to detect its impact to other companies? 2). how to make the complex analysis approaches in a simple explorative manner that can be used by common users? To bridge this gap, in this thesis we present an approach that enables users to navigate and analyze large news corpora with rich topic contexts.
The other main problem studied in this thesis is performing sentiment analysis on cus-tomer reviews. The research of sentiment analysis was proposed to concern not only what topics are talking about in the documents but also what opinions and sentiments are ex-pressed on the related topics. Existing works on sentiment analysis can be divided into two categories. One category of work focuses on analyzing document overall sentiment, i.e. overall sentiment classification (e.g. [1, 2, 3]). The other category of work focuses on analyzing which aspect of the product the sentiment is expressed on, which is usually referred to as attribute-based sentiment analysis (e.g. [4, 5, 6]). This thesis studies both categories of the problems.
As suggested by its name, document overall sentiment classification is concerned with analyzing a document’s overall sentiment, which can be solved by two main approaches. Lexicon-based methods [7] conduct sentiment analysis by inferring a document’s overall sentiment from sentiments of words (e.g. [8]) or phrases (e.g., [9]). Machine learning approaches build classifiers to classify a document’s overall sentiment through a super-vised [10] or unsupersuper-vised [11] learning process.
Since Pang et al. [10] studied sentiment classification using machine learning techniques, a lot of work has addressed the document overall sentiment classification problem in a supervised text classification process. Within exiting publications there exist various tech-niques to improve performance of traditional topic-based classifiers on sentiment classi-fications. These techniques include feature selection approaches, identifying more im-portant subjective portions of texts [12], learning from human-annotator rationale [13] or human interaction [14]. The problem of document overall sentiment classification we dealt in this thesis aims at improving performance of sentiment classifiers from the per-spective of feature selection.
Attributes-based sentiment analysis is to analyze sentiment based on each attribute of a product. When we look into the details of each example of product reviews, we find that online product reviews usually constitute domain specific knowledge. The product’s at-tributes mentioned in reviews might have some relationships between each other. For ex-ample, for a digital camera, comments on image quality are usually mentioned. However, a sentence like “40D handles noise very well up to ISO 800", also refers to image qual-ity of the camera 40D. Here we say “noise" is a sub-attribute factor of “image qualqual-ity". As we know, in computer science and information science, an ontology formally
repre-6 CHAPTER 1. INTRODUCTION sents knowledge as a set of concepts within a domain, and the relationships among those concepts4. Therefore, in this thesis we aims at studying the problem of ontology-based sentiment analysis, where ontology structure serves as external knowledge to organize a product’s attributes.
1.3
Research Context
The research in this PhD thesis has been conducted at the Department of Computer and Information Science (IDI) at Norwegian University of Science and Technology (NTNU) within the project Cooperative Mining of Independent Document Repositories (COMI-DOR). The COMIDOR project is funded by the Norwegian Research Council under the VERDIKT research programme with project number 183337. The COMIDOR project started in 2008 and ended in 2012.
The main objective of the COMIDOR project is to understand the form and contents from cooperatively mining independent document collections. Traditional search technologies have been studied in a relatively mature research area. However, documents retrieved by traditional search technologies only capture the explicit information and knowledge of documents. Document collections usually contain implicit rich semantics, where tech-nologies with traditional keyword-based searching strategy do not work very well. In this research context, the focus of this thesis is on mining implicit rich semantics and knowl-edge from document collections. The targeted document collections used in our research are respectively 1) online business news which represents objective information on the WWW and 2) online customer reviews which represents subjective information on the WWW.
1.4
Research Goal and Questions
The research in this thesis aims at developing approaches to extracting implicit knowledge from mining online text data. Specifically, the knowledge to be extracted depends on which online text data are analyzed. Focus on the online business news (one representative of online objective information) and online customer reviews (one representative of online subjective information), the main research objectives of this thesis are two-fold:
RO1: How can we detect companies’ relations through analyzing online business news collections?
RO2: How can we extract peoples’ opinions and sentiments through analyzing on-line customer reviews?
CHAPTER 1. INTRODUCTION 7
1.4.1
Business News Analysis
As the continuous growth of the online medias such as New York Times(NYT)5, an ever increasing amount of information is becoming available through collections of news arti-cles. Traditionally, people use search tools to retrieve a ranked list of documents whose content is highly related to a set of user-supplied keywords. This model has proven re-markably powerful for information retrieval tasks, such as locating the address of a restau-rant. However, ranked lists of news contents are insufficient for more complex data explo-ration and analytical tasks where users try to understand the relations between complex concepts that span across multiple documents. One main research objective of this the-sis aims at discovering relations among companies according to their impact that can be detected within their news. A company has an impact on another company if news about the impacted company in some systematic way reflect what is going on with the other company. Our first research question is:
RQ1: How can we model and quantify the impact of a company’s news?
1.4.2
Customer Reviews Analysis
On the WWW there is a mass of information with multifarious opinions on a given topic may be generated from all over the world in a very short time. As the number of prod-uct reviews grows, it becomes difficult for a user to manually learn the panorama of an interesting topic from existing online information. Faced with this problem, research on opinion mining and sentiment analysis, e.g., [4, 5, 15], were proposed and have become a popular research topic at the crossroads of information retrieval and computational lin-guistics. Research on sentiment analysis can be classified into two different categories according to granularity of sentiments being analyzed against texts. One category is doc-ument overall sentiment analysis. The other category is aspect-based sentiment analysis. In this thesis, we study problems of sentiment analysis on customer reviews in both cate-gories.
Carrying out sentiment analysis on customer reviews is not a trivial task. When we look into the details of each example of product reviews, we find that there are two intrinsic properties that might help us to solve the problem:
IP1: Customer reviews constitute domain-specific knowledge.
The product’s attributes mentioned in reviews might have some relationships between each other. For example, for a digital camera, comments on image quality are usually mentioned. However, a sentence like “40D handles noise very well up to ISO 800", also refers to image quality of the camera 40D. Here we say “noise" is a sub-attribute factor of “image quality".
IP2: Vocabularies used in product reviews tend to be highly overlapping.
8 CHAPTER 1. INTRODUCTION In online customer reviews, for one product there only exist a finite number of aspects (product’s attributes) that can be commented on. For example, for a digital camera, at-tributes that are usually mentioned in reviews are “price", “LCD", “picture quality" and “battery life", etc. For each reviewed attribute, there are a finite number of vocabularies that are usually involved in sentiment expressing.
Document Overall Sentiment Analysis
Document overall sentiment classification is concerned with analyzing a document’s over-all sentiment. As indicated in the statement of Intrinsic Property 2 (IP2), vocabularies used in product reviews tend to be highly overlapping. Words referred to attributes of a product as well as words for describing sentiment on the attributes will co-occur in the customer reviews with high frequency. Furthermore, high frequent co-occur terms to-gether indicate more clear sentiments than each only single term. For example, single term like “high" does not necessarily means positive sentiment. However, in a corpus of customer reviews on digital cameras terms “high" and “price" might co-occur together frequently and means definitely negative. Therefore, we have a research question:
RQ2: How can we capture high frequent co-occur terms as complex features to im-prove the accuracy of sentiment classification on product reviews?
As high frequent co-occur terms are generated as complex features for sentiment classi-fier, classification performance is expected to be improved. However, all the captured high frequent co-occur term patterns are not necessarily effective features for a sentiment clas-sifier. For example, in customer reviews on hotels, the terms “staff", “nice", and “service" usually co-occur together. However, the generated complex feature like “staff service" is a noise or useless feature to classifiers. Therefore, we know the generated complex features by high frequent co-occur term pattern may generate noise as well and we have the following research question to deal with this problem:
RQ3: How can we identify and remove unwanted complex features from the gener-ated co-occur terms without losing effective features for sentiment classifica-tion?
Attributed-based Sentiment Analysis
Attributes-based sentiment analysis is to analyze sentiment based on each attribute of a product. As indicated in the statement of Intrinsic Property 1 (IP1), customer reviews con-stitute domain-specific knowledge. There are relationship between attributes of a product in that domain. In computer science, one natural way to represent the structure and rela-tionship of concepts of a domain knowledge is to use ontology. It is intuitive to investigate whether we can use the knowledge of an ontology structure to help us perform attributed-based sentiment analysis. Therefore we have the following research questions:
CHAPTER 1. INTRODUCTION 9
RQ4: How can we design an ontology-supported framework so that knowledge of the product ontology enhances the sentiment analysis process?
The above research question aims at developing an ontology-supported framework that can use the knowledge of ontology structure of a product domain to facilitate sentiment analysis process. If an ontology-supported sentiment analysis framework can be devel-oped, it entails opportunities of improvement from several angles. Therefore, a further research question following RQ5 is:
RQ5: What are the important factors affecting the performance of the above ontology-supported sentiment analysis framework?
1.5
Research Approach
In this section, we discuss the research approaches used in this work.
The goal of the research process is to produce new knowledge or deepen understanding of a topic or issue6. Generally, there are three main forms of taking a research process, i.e., exploratory research, constructive research, and empirical research. Although it is difficult to define clear boundaries between them, each of them highlights different aspects of activities in the research process. Exploratory research is a type of research conducted for a problem that has not been clearly defined7. Constructive research is perhaps the most common computer science research method. This type of approach demands a form of validation that doesn’t need to be quite as empirically based as in other types of research like exploratory research8. Empirical research is a way of gaining knowledge by means of direct and indirect observation or experience. Empirical evidence (the record of one’s direct observations or experiences) can be analyzed quantitatively or qualitatively9. The research taken in this thesis involves activities of the above research approaches. Specifically, the research process includes following typical activities:
• Research Problem Survey.The important approach to starting a research process is to survey the research problems. The survey is mainly conducted by broad litera-ture reviewing. The literalitera-tures are mainly from prestigious international conference proceedings, e.g., ACL, WWW, SIGIR, etc, and good international journals, e.g., TKDE, TOIS, etc. Through this broad reading process, we can find out the chal-lenges of our research problems and understand the state-of-the-art techniques pro-posed in existing publications. In the research problem survey process, we learn all the preliminary knowledge of our research and make good preparation for further exploitation.
6http://en.wikipedia.org/wiki/Research#Research_methods 7http://en.wikipedia.org/wiki/Exploratory_research 8http://en.wikipedia.org/wiki/Constructive_research 9http://en.wikipedia.org/wiki/Empirical_research
10 CHAPTER 1. INTRODUCTION
• Knowledge Learning and Approach Development.The model and approach de-velopment process is to propose our own methods to tackle the research problems. In this process, we first analyze the challenges within the problems. Then we learn and study the knowledge that can be applied to the problems. The knowledge we need to learn in this stage involves several areas including natural language pro-cessing, linear algebra, probability theory, neural information propro-cessing, etc. After deep learning on the required knowledge, we can propose our own approaches to the research problems.
• Data Preparation.One important activity for research is to prepare data on which the proposed approaches can be evaluated. In our research, we use both public standard data sets and manually labeled self-created data sets. For task of sentiment classification, we use public standard data sets. e.g., the movie review data set10 so that our approach can be easily compared with related work. For some tasks, such as product attribute detection and news impact analysis, we have to crawl data from online websites and manually label the data set for the specific experimental purposes.
• Metrics for Result Analysis. In empirical research, experiments can be analyzed quantitatively and qualitatively. The metrics used in the research of this thesis mainly use quantitatively empirical analysis. For each research problem, metrics are designed with each research questions raised in the research process so that ad-vantages and disadad-vantages of proposed approaches can be revealed in an objective manner.
1.6
Research Contributions
This thesis has 6 research contributions listed as follows:
C1: ImpactWheel, an explorative visual analysis system that can reveal the impact of news articles.
In paper P1, we propose ImpactWheel, a new visual analysis technique that enables users to navigate and analyze large news corpora with rich topic contexts. Topic driven impact analysis provides a ranking mechanism that finds a set of companies that are deemed as most impacted by topics of news of a user-interested company. The idea of a probabilis-tic topic model is that documents are mixtures of topics, where a topic is semanprobabilis-tically coherent and is formally treated as a probability distribution of words. In the paper P1 we discuss how we use a probabilistic topic model to naturally quantify impact of a com-pany’s news to the topic proportion in other companies’ news collections, and propose a semi-supervised model estimation process to estimate the model’s parameters which serves as quantity of impact of a company’s news. In the paper P1, we also provide a new visualization design that helps us portray the relation ranking results and facilities data
CHAPTER 1. INTRODUCTION 11 understanding. Rich interactions are also provided that enable us to explore the analy-sis results in a dynamic and efficient way and also help to detect data patterns from rich context.
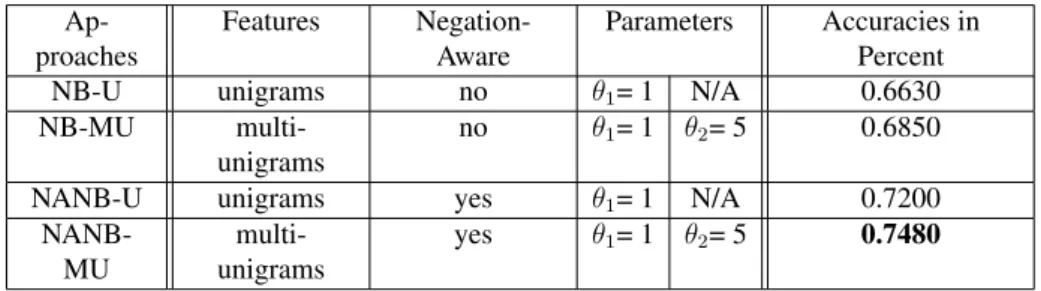
C2: An automatic approach for generating complex features for sentiment classi-fiers.
In paper P2, we propose an approach to generating complex features, called multi-unigram features, to enhance a negation-aware Naive Bayes classifier. The term “multi-unigram feature" is coined to represent the process that the generated features are produced by our algorithm that takes an initial set of unigram feature candidates as input. We further make the Naive Bayes classifier aware of negation expressions in the training and classification process to eliminate the confusions of the classifier that is caused by negation expressions within sentences. Experiments in the paper P2 not only qualitatively show the good qual-ity of the generated features but also quantitatively demonstrate a significant effectiveness of ideas of both the multi-unigram features generation and the negation-aware classifier on improving the performance of the original Naive Bayes classifier.
C3: An Effective Feature Search (EFS) framework for enhancing the performance of sentiment classifiers.
As discussed in RQ3, the complex feature generation algorithm proposed in the paper P2 not only produce effective features but also bring useless noise for sentiment classi-fiers. In paper P3, we propose an Effective Feature Search (EFS) framework that makes a novel connection between feature candidate generation and a Stochastic Local Search (SLS) process to enhance performance of machine learning classifiers for sentiment clas-sification. The EFS framework contains two steps. In the feature generation step, we uti-lize filter-based methods [16] to generate feature candidates including both complex fea-ture and unigram feafea-ture taking advantage of high frequency Co-occurring Term (CoT) patterns. In the feature pruning step, we map the feature set optimization process to a Stochastic Local Search (SLS) process. In the proposed SLS model, a wrapper-based selection is adopted to score each selected feature subset with an objective function tai-lored to the classifier. A hill-climbing SLS algorithm is developed in the model to ensure quickly finding a local optima.
C4: A Hierarchical Learning via Sentiment Ontology Tree (HL-SOT) approach for sentiment analysis.
In paper p4 and P5, we study the problem of sentiment analysis on product reviews through a novel method, called the HL-SOT approach, namely Hierarchical Learning (HL) with Sentiment Ontology Tree (SOT).By sentiment analysis on product reviews we aim to fulfill two tasks, i.e., labeling a target text with: 1) the product’s attributes (at-tributes detection task), and 2) their corresponding sentiments mentioned therein (senti-ment orientation task). The proposed HL-SOT approach is the first work to formulate the tasks of sentiment analysis to be a hierarchical classification problem. In the paper P4, we first propose a formal definition on SOT. A specific hierarchical learning algorithm is further proposed to achieve tasks of sentiment analysis in one hierarchical classification
12 CHAPTER 1. INTRODUCTION process.
C5: A Localized Feature Selection (LFS) framework tailored to the HL-SOT ap-proach.
In paper p6, we propose a Localized Feature Selection (LFS) framework tailored to the HL-SOT approach to sentiment analysis. In the proposed LFS framework, significant feature terms of each node can be selected to construct the locally customized index term space for the node so that the classification performance and computational efficiency of the existing HL-SOT approach are improved.
C6: A Hybrid Hierarchical Classification Process for Sentiment Analysis.
In paper P7, a Hybrid Hierarchical Classification Process (HHCP) is proposed to solve the two tasks, i.e., attributes detection task and sentiment orientation task, of sentiment anal-ysis. The HHCP approach is proposed based on the paper P4 of the HL-SOT approach. Compared with the HL-SOT approach, the HHCP approach has the following contribu-tions. First, the HHCP approach employs a linear Fisher classifier for attribute detection task, since Fisher classifier is developed by requiring maximum class separation in the output space, which is deemed as more competent than the Regularized Least Squares (RLS) employed by the HL-SOT approach. Second, the HHCP approach only performs the sentiment orientation task on the identified attributes that are leaf nodes of the hierar-chical structure. Third, since the statistical linear classifiers that are designed for semantic classifications are evidently prone to errors when applied to classifying sentiment infor-mation, unlike the HL-SOT approach, the HHCP approach turns to a rule-based heuristic solution for the sentiment orientation task.
1.7
Papers
There are seven papers that are included in this thesis. These papers have all been pub-lished in international peer reviewed workshops, conferences, and journals. In this sec-tion, we present an overview of the papers. Details of the papers are included in the thesis in Part II.
P1: Wei Wei, Nan Cao, Jon Atle Gulla and Huamin Qu: “ImpactWheel : Visual Anal-ysis of the Impact of Online News", in Proceedings of the 2011 IEEE/WIC/ACM International Conference on Web Intelligence.
P2: Wei Wei, Jon Atle Gulla and and Zhang Fu: “Enhancing Negation-Aware Senti-ment Classification on Product Reviews via Multi-Unigram Feature Generation", in Proceedings of the Sixth International Conference on Intelligent Computing.
P3: Wei Wei, Ole J. Mengshoel and Jon Atle Gulla: “Stochastic Search for Effective Features for Sentiment Classification" Under submission to Data and Knowledge Engineering.
CHAPTER 1. INTRODUCTION 13
P4: Wei Weiand Jon Atle Gulla: “Sentiment Learning on Product Reviews via Sentiment Ontology Tree", in Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics.
P5: Wei Wei: “Analyzing Text Data for Opinion Mining", in Proceedings of 16th Inter-national Conference on Applications of Natural Language to Information Systems.
P6: Wei Weiand Jon Atle Gulla: “Enhancing the HL-SOT Approach to Sentiment Anal-ysis via a Localized Feature Selection Framework", in Proceedings of the 2011 International Joint Conference on Natural Language Processing.
P7: Wei Weiand Jon Atle Gulla: “Sentiment Analysis in a Hybrid Hierarchical Clas-sification Process", in Proceedings of the 7th International Conference on Digital Information Management.
1.8
Thesis Structure
This thesis contains two parts. Part I introduces background and motivation of research in this thesis and also presents an overview of technology context, related work, results and evaluations, etc. Part II contains a list of papers that are related to research in this thesis. The remainder of this thesis is organized as follows:
Part I
Chapter 2: Technology Context.In this chapter, an overview of background knowledge and technologies that are related to this thesis are reviewed.
Chapter 3: State of the Art.In this chapter, we discuss our research problems in terms of the state of the art approaches.
Chapter 4: Research Results. In this chapter, we summarize the contributions of this thesis. Each contribution is correspondent to a research question raised in the Sec-tion 1.4. For each contribuSec-tion, a research quesSec-tion is revisited. Then we briefly describe each proposed approach, its evaluation, and roles of authors in the paper.
Chapter 5: Conclusion and Future Work.In this chapter, we conclude the work in this thesis and discuss potential research directions for future work.
Part II: Publication List.This part contains a list of the papers (P1-P7) that are used in this thesis and produced in the period of my PhD study.
Chapter 2
Technological Background
In this chapter, we briefly introduce fundamental techniques that are background knowl-edge for understanding the research papers that are included in this thesis. The chapter is organized as follows. Section 2.1 discusses five classic feature selection algorithms that are utilized in the papers P2, P3, and P6. Section 2.2 describes a list of machine learning classifiers that are used in the papers P2-P7. Section 2.3 presents a classic association rule learning algorithm that inspires complex feature generation algorithm proposed in the papers P2 and P3. Section 2.4 introduces statistical topic models that are background technique for developing the topic driven impact analysis model in the paper P1.
2.1
Feature Selection Approaches
Feature selection1also known as feature reduction, variable selection or data dimension reduction is a process of selecting a subset of most important and relevant features for building robust learning models. Research on feature selection techniques has become the focus of people working on statistical machine learning areas with the following ob-jectives: improving the prediction performance of the models, providing faster and more cost-effective learning and classification process, and providing a better understanding of the underlying process that generated the data [17]. In this section, we review five classic feature selection algorithms, i.e., Document Frequency (DF) [18], Mutual Information (MI) [18, 19],χ2-statistic (CHI) [18], Term Strength (TS) [20], and Information Gain (IG) [21], that are used in our research process.
2.1.1
Document Frequency Feature Selection
Document Frequency (DF) feature selection algorithm is a frequency-based feature selec-tion process. The DF algorithm is the simplest and effective feature selecselec-tion algorithm
1http://en.wikipedia.org/wiki/Feature_selection
16 CHAPTER 2. TECHNOLOGICAL BACKGROUND that quantifies importance of a term as the number of documents in which the term occurs. Based on the intuition that rare terms are less important for category prediction, the DF algorithm counts the document frequency of each unique terms in the training data set and select a sub set of terms whose document frequency fulfills the threshold.
2.1.2
Mutual Information Feature Selection
Mutual Information (MI) is usually used to measure dependence of two random vari-ables2. In text classification, MI can be used to indicate how much a termtis related to a classc. Therefore MI might serve as a criteria to select feature terms for some specific class and is calculated as [18]:
I(t, c) = et∈{1,0} ec∈{1,0} P(et, ec) log2 P(et, ec) P(et)P(ec) , (2.1)
whereet= 1means a training document containstandet= 0means a training document
does not containt, andec = 1means a training document is in classcandec= 0means
a training document is not in classc.
2.1.3
χ
2-statistic Feature Selection
χ2feature selection is a popular algorithm for selecting features in text classification. The criteria used in theχ2feature selection algorithm is based onχ2test which is applied to test the independence of two events. Lettdenote a term andcdenote a class. Theχ2
score oftwithcis calculated as [18]:
χ2(t, c) = et∈{1,0} ec∈{1,0} (Netec−Eetec) 2 Eetec , (2.2)
whereetandechave the same definition as in the Formula 2.1, andN andE are
respec-tively the observed frequency and the expected frequency in the training data.
2.1.4
Term Strength Feature Selection
Term Strength (TS) [20] estimates term importance based on how commonly a term is likely to appear in a cluster of highly related documents [22]. In the TS feature selec-tion process, the algorithm first cluster documents in the training data according to their similarity. The number of clusters that can be generated from training data depends on the threshold on document similarity. Let documentsxiandxjrespectively represent any
two different documents from the same cluster of training data. Score of term strength of
CHAPTER 2. TECHNOLOGICAL BACKGROUND 17
tis calculated based on the estimated conditional probability thattoccur in the document
xigiven thattalso occur in the documentxj, i.e.,:
s(t) =P(t∈xi|t∈xj). (2.3)
2.1.5
Information Gain Feature Selection
Information Gain (IG) is another frequently used measurement on feature selection in the field of machine learning. The IG utilizes entropy to calculate information change given more conditions. In information theory, entropy is used to measure uncertainty of a random variable. LetXdenote a random variable with possible values{x1, x2, ..., xn}.
Then the entropy ofX:
I(X) =− n
i=1
P(xi)log2P(xi). (2.4)
The IG feature selection algorithm quantifies the importance of a termtto a classcas how much difference is between entropy ofcand conditional entropy ofcgivent:
IG(t, c) =P(c|t)log2P(c|t)−P(c)log2P(c). (2.5)
2.2
Machine Learning Classifiers
Machine learning is a discipline within Artificial Intelligence (AI) that deals with algo-rithms that enable computers to learn from empirical data and solves problems on new observed data. In machine learning and statistics, classification is a key problem that pre-dicts which categories new observed data belong to. In this section, we review a list of machine learning classifiers that are utilized in the research of this thesis.
2.2.1
Naive Bayes Classifier
The technique of a Naive Bayes (NB) classifier is based on the Bayesian theorem3with strong “naive" independence assumptions. The NB classifier is a simple but popular ef-fective probabilistic classifier on solving classification problems. It can often outperform more sophisticated classification methods. In a typical text categorization problem, letd
denote a document and letcdenote a class. With the Bayes’ rule, the probability of the documentdbeing in the classcis calculated as:
P(c|d) =P(c)P(d|c) P(d) .
18 CHAPTER 2. TECHNOLOGICAL BACKGROUND
Since for each classc, the probability of a documentd, i.e.,P(d), can be treated equally,
with conditional independent assumption on words of the documentd, the probability of
dbeing inccan be derived as:
P(c|d)∝P(c)
∀w∈d
P(w|c),
where P(w|c)is the conditional probability of a wordw occurring in a document that
belongs to classc.
2.2.2
Support Vector Machine
Support Vector Machine (SVM) is one of the best supervised machine learning tech-niques. It was proposed by Cortes and Vapnik [23]. The SVM classifier projects data to a high dimension which is typically much higher than the original feature space. The
non-linear function, sayϕ(·), can be polynomials, Gaussians, or other basis functions [24]. In
a sufficiently high dimension transformed byϕ(·), data from two categories can be
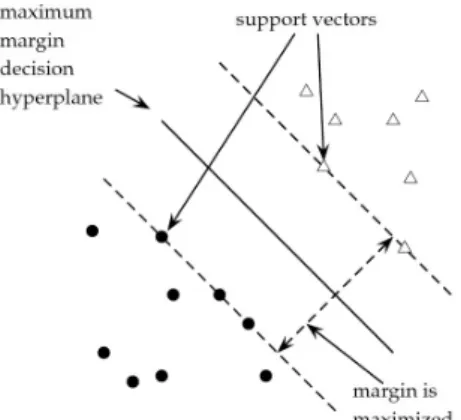
sepa-rated by a hyperplane which has the largest distance to the nearest training data point of any class (see Fig. 2.1 [25]). The distance between the hyperplane and the nearest point is called margin. The nearest point is called support vector.
Figure 2.1: An Example of Support Vector Machine Hyperplane
Let feature vector vi represent each data pattern in original space. Let xi denote the
vector that is transformed by an appropriate nonlinear functionϕ(·): xi =ϕ(vi). Then
the training data set in the transformed space is represented by{(xi, yi)}, wherexiis a
vector in the transformed space andyi =±1according to whether the data instanceiis
in or not in the category. Letwrepresent the gradient vector of the optimal hyperplane.
The hyperplane can be represented bywTx+b. Thus the margin between the hyperplane
andxiis:
yi(wTxi+b)
CHAPTER 2. TECHNOLOGICAL BACKGROUND 19 Assuming there is a positive marginδexists [23], that is
yi(wTxi+b)
w ≥δ.
The goal of the SVM is to find appropriate parameters, i.e.,wandb, of the hyperplane that maximizeδ. To ensure a unique solution ofwandb, we impose the constraintwδ = 1
and the objective function can be represented as:
max
w,b
1
w
s.t. yi(wTxi+b)≥1.
Since maximizingw1 is equal to minimizing 12w2, the objective function can be pre-sented as: min w,b 1 2w 2 s.t. yi(wTxi+b)≥1.
The above optimization problem is a typical quadratic programming problem and have been studied in a number of alternative schemes [26, 23, 27].
2.2.3
K-Nearest Neighbor
K-Nearest Neighbor (KNN) classification is one of the classic algorithm in machine learn-ing. It is a supervised learning algorithm and has been used in many applications in the field of data mining, statistical pattern recognition, and text processing. KNN is instance-based learning and assign objects to the class of its closestkneighbors, wherekindicates the number of closest neighbors that are considered in the training and classification pro-cess. Here is an example of KNN in Fig. 2.2, wherek= 7. From the example, we can see that within the seven closest neighbors around the object “X" there are five black circles and two white circles. Therefore, the “X" object will be assigned to the class of black circle.
The most popular metrics for calculating similarity between objects are Euclidean dis-tance and Cosine similarity. Let n-dimensional vectorsxi andxj respectively represent
two objects. The Euclidean distance4is the ordinary distance between two points that one would measure with a ruler and is calculated as:
distance(xi, xj) = n t=1 (xi,t−xj,t)2. 4http://en.wikipedia.org/wiki/Euclidean_distance
20 CHAPTER 2. TECHNOLOGICAL BACKGROUND
Figure 2.2: An Example of KNN Classifier (k= 7)
The Cosine similarity5is a measure of similarity between two vectors of an inner product
space that measures the cosine of the angle between them and is calculated as:
sim(xi, xj) = xi·xj xixj = n t=1xi,t×xj,t n t=1(xi,t)2 n t=1(xj,t)2 .
2.2.4
Decision Tree Classification
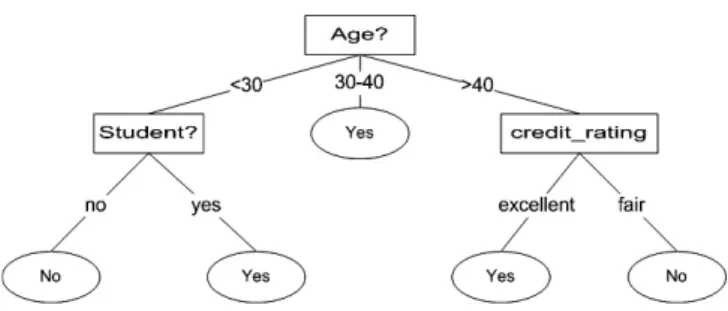
Figure 2.3: An Example of Decision Tree.
A decision tree6is a decision support tool that uses a tree-like graph or model of decisions
and their possible consequences, including chance event outcomes, resource costs, and utility. In machine learning and data mining, a decision tree classifier is a predictive model using decision tree to map objects to class labels which are represented as leaves in the classification tree structure. An example of a decision tree classification is presented in Fig. 2.3. In the example, we see that each interior node, e.g., age and credit rating, represent a feature to be considered in the decision tree. Leaf nodes in Fig. 2.3 represent two classes, i.e., yes or no, of decisions on whether issuing a credit card. A decision tree
5http://en.wikipedia.org/wiki/Cosine_similarity 6http://en.wikipedia.org/wiki/Decision_tree
CHAPTER 2. TECHNOLOGICAL BACKGROUND 21 can be learned from training data. There are several decision tree learning algorithms including Iterative Dichotomiser 3 (ID3) [28], C4.5 algorithm [29], and Classification And Regression Tree (CART) [30], etc.
2.2.5
Linear Fisher Classifier
A linear Fisher classifier also known as Fisher’s linear discriminant is a classification method that finds a linear combination of features and projects high-dimensional data onto a line and performs classification in this one-dimensional space. A linear Fisher classifier is developed by maximizing separation between classes while minimizing variance within each class. Letx∈ X(X =Rd)denote a vector representation for a text to be classified.
Let cand¯crespectively denote the two classes: related toc and not related toc. The function of a linear Fisher classifierf(.)is to project the d-dimensional input vectorx
down to one dimensiony∈Rby:
y=f(x) =wT·x,
wherew= (w1, w2, ..., wd)Tis a unit weight vector that defines the linear Fisher classifier.
Imagine that if the two classescand¯care divisible in thed-dimensional space, after being projected down to the one dimensionR, we still want to keep their divisibility. That is to say a projection needs to be selected so that the class separation can be maximized. Let the mean vectorsxcandx¯crespectively represent the two classes ofcandc¯, i.e.,:
xc= 1 Nc i∈c xi, x¯c= 1 N¯c j∈c¯ xj.
We need to find a weight vectorwthat can maximize the separation distance betweenxc
andx¯cwhen projected byw. However, the projection discovered in this way still suffers
from a problem that the two classes that could be separated in the original space are still overlapping in the one dimensional output space, because the covariances of the two class distributions are non-diagonal. To alleviate this problem, Fisher [31] proposed a balanced function that maximizes separation between classes while minimizing variance within each class: J(w) =w TS Bw wTS Iw , (2.6)
whereSBis the between-class covariance matrix given by:
SB= (x¯c−xc)(xc¯−xc)T, (2.7)
andSI is the inner-class covariance matrix given by: SI = i∈c (xi−xc)(xi−xc)T + j∈¯c (xj−x¯c)(xj−x¯c)T. (2.8)
22 CHAPTER 2. TECHNOLOGICAL BACKGROUND The weight vector w that makes the optimized projection is thew that maximizes the
J(w)function in Formula 4.14, i.e.,:
w= arg max w J(w) = arg maxw wTS Bw wTS Iw . (2.9)
To calculate the weight vector wand deal with the small sample size problem [32] in the training data set, following the similar idea in [33], we perform the singular value decomposition ofSI and have:
SI =UΣVT, (2.10)
whereU andV ared-by-dorthogonal matrices andΣis ad-by-ddiagonal matrix. Let
V = [v1, ..., vr, vr+1, ..., vd], whereris the rank ofSI. SinceSI is a singular matrix,ris
smaller than the dimensionality of the original space, i.e.,r < d. Therefore, there must be a kernelKofSI, whereKis the null space ofSIand is a linear span of a set of vectors {xk|SIxk = 0,1≤k≤(d−r)}. Let matrixQbe[vr+1, ..., vd]. Since the kernelKcan
be spanned by vectorsvr+1, ..., vd[34], the matrixQQT can be used when transforming
samples from the original space to kernel. LetS˜B denote the scatter matrix ofSB and
define:
˜
SB=QQTSB(QQT)T. (2.11)
The weight vector wcan be calculated as the eigenvector corresponding to the largest eigenvalues of scatter matrix ofS˜B.
2.3
Association Rule Mining
Association Rule Mining is a fundamental data mining method on identifying co-occurrence relationships, called associations, in large data sets. The problem of mining association rules can be presented as follows [35]. Let’s take market basket analysis as an exam-ple. In a supermarket, customers purchase items. Shopping details of each purchase are recorded as transactions at cashiers. LetI = {i1, i2, ..., im}denote a set of items. Let T = (t1, t2, ..., tn)be a set of transactions. An association rule is an implication of the
ruleX→Y, whereX⊂I, Y ⊂I, andX∩Y =∅.
Apriori [36] is one of classic algorithms for learning association rules. The Apriori al-gorithm which relies on the downward closure [35] has two steps. First, it generate a frequent item set that has frequency in transactions above minimum threshold, say θ. Second, associate item associations are generated with co-occurrence frequency above the thresholdθbased on the frequent item set generated in the first step. Details of the Apriori algorithm are presented in Algorithm 1.
CHAPTER 2. TECHNOLOGICAL BACKGROUND 23
Algorithm 1Apriori Algorithm
1: F ← ∅; initialized to be empty set
2: F1← {f|f =i∈Iandi.countθ}; generate a frequent item set
3: for(k= 2;Fk−1=∅;k++)do
4: Fcand← ∅; initialized to be empty set
5: Fk← ∅; initialized to be empty set
6: forallf, f∈Fk−1do
7: withf={i1, ..., ik−2, ik−1} 8: andf={i1, ..., ik−2, ik−1} 9: fcand← {i1, ..., ik−2, ik−1, ik−1}
10: iffcand.countθthen
11: Fk←Fk∪ {fcand}; 12: end if
13: end for 14: end for
15: returnF ← ∪kFk; return the generated feature setF as a union of all the
generatedFk
2.4
Statistical Topic Models
A topic model is a type of statistical model for discovering the abstract "topics" that occur
in a collection of documents7. The idea of a probabilistic topic model is that documents
are mixtures of topics, where a topic is semantically coherent and is formally treated as a
probability distribution of words. In a probabilistic topic model, a documentdis deemed
to be generated by a mixture of topics. To generate each wordw ind, a latent topicz
is chosen with a probability andw is considered to be generated from a topic-specific
multinomial distributionθzover words.
Probabilistic Latent Semantic Analysis (PLSA) is one of well known topic model devel-oped by Thomas Hofmann in 1999 [37]. In PLSA documents are considered being made
up of a mixture of latent topics from a topic setZ={z1, z2, ..., zK}and model the whole
document collectionDas:
P(D) = d∈D p(d, w) = d∈D w∈d P(d)P(w|d) = d∈D w∈d P(d) z∈Z P(w|z)P(z|d). (2.12)
Formula 2.12 models the process of generating each wordwinDin a natural way. When
“authors" are writing each documentd, they first chose some specific topic with
probabil-ityP(z|d)and then choose a word from the topiczwith probabilityP(w|z). The number
of parameters in the Formula 2.12 is K|D|+K|V|, whereK is the number of latent
topics, and|D|is the number of documents inD, and|V|is the number of words in the
vocabulary setV. These parameters can be learned using the EM algorithm [37, 38].
24 CHAPTER 2. TECHNOLOGICAL BACKGROUND
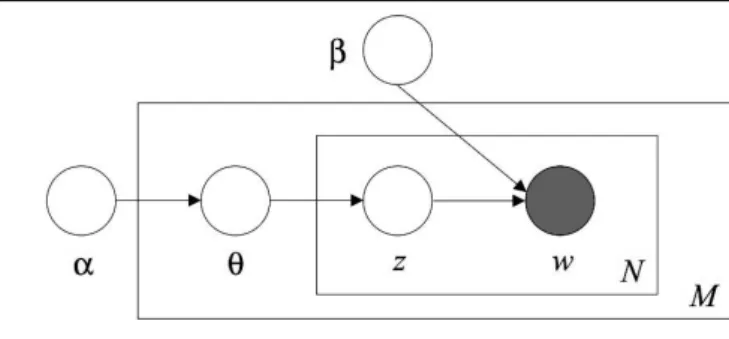
Figure 2.4: Graphical Model Representation of LDA.
Latent Dirichlet Allocation (LDA) is a generative probabilistic topic model and is pro-posed by Blei et al. in 2002 [39]. As described by Fig. 2.4 [39], the LDA is a three-level hierarchical Bayesian model, in which each document is modeled as a finite mixture over a set of latent topics. Each topic is modeled as infinite mixture over an underlying set of topic probabilities. The main contribution of LDA compared with the PLSA is that
the authors introduce the Dirichlet distribution Dir(α)to model the parameters of topic
distribution of documents. Different from the generation process of PLSA, the LDA
as-sumes the following generative process for each documentwinD. First, the parameter
θis chosen according to the Dirichlet distribution Dir(α). Then a topiczis chose from
a multinomial distribution parameterized byθ. Finally, within the topicza wordwis
chosen from a multinomial probability defined by a Dirichlet distribution Dir(β). The
LDA model of the above generative process for describing a training document collection
Dis presented as: P(D|α, β) = d∈D P(θd|α)( Nd i=1 zdi P(zdi|θd)P(wdi|zdi, β))dθd, (2.13)
where αandβ are super parameters. θd is the multinomial distribution that describes
topic distributions for the documentd. Ndis the total number of words in a document
d. wdirepresents theithword of the documentd. zdirepresents the topic that generate
the wordwdi. The LDA model is a complete Bayesian model since it introduces Dirichlet
distributions Dir(α)and Dir(β)to respectively model the parametersP(z|d)andP(w|z)
of PLSA as random variables. In this way, the number of parameters to be estimated for a
LDA model isK+K|V|. These parameters can be estimated by an efficient approximate
Chapter 3
State of the Art
In this chapter, we give an overview of the state-of-the-art work that is related to research of this thesis. The related work is categorized into two sections that are respectively related to the two main problems studied in this thesis. Section 3.1 reviews the related work to modeling impact of online news. Section 3.2 discusses previous work on opinion mining and sentiment analysis.
3.1
Impact Modeling on News
With continuous growth of internet, huge amounts of news data becomes available on online medias. Research on online news analysis has been widely studied in the research communities of information retrieval and text mining. Unlike traditional search technolo-gies that returns a ranked list of documents whose content is highly related to a set of user-supplied keywords, recent research relies on Topic Detection and Tracking (TDT) technologies to model and analyze news topic trend and impact [40].
3.1.1
News Impact Tracking and Modeling
Mori et al. [41] proposed a technique for topic-tracking from Web pages obtained by search engines. The technique relies on a KeyGraph to form concepts and topics with a collection of frequent words clustered together. Yang et al. [42] applied hierarchical and non-hierarchical document clustering algorithms to a corpus of 15,836 stories, focusing on the exploitation of both content and temporal information to automatically detect novel events from a temporally-ordered stream of news stories. Kumaran and Allan [43] use named entities as well as text classification techniques to improve performance of the new event detection task. Leskovec et al. [44] developed a framework for tracking short, distinctive phrases that travel relatively intact through online text and presented scalable algorithms for identifying and clustering textual variants of such phrases that scale to
26 CHAPTER 3. STATE OF THE ART a collection of 90 million articles, which offers quantitative analysis of the global news cycle and the dynamics of information propagation between mainstream and social media. Wang et al. [45] proposed an automatic online news topic ranking algorithm based on inconsistency analysis between media focus and user attention. Although existing work investigated on the topic detection and tracking problem in various way, none of them formulates a model that quantifies the impact of topics of news articles.
The first challenge in our research on news impact modeling is to develop a model that quantifies the impact of topics of news articles. Therefore different with existing TDT works [41, 42, 43, 44, 45] which focus on detecting and tracking topics of news articles, our work focus on the challenge of modeling impact of user-interested news topics and enables users to navigate among selected news topics to analyze and reveal news impact in an explorative manner.
3.1.2
News Relatedness Calculation
The second challenge in our research on news impact analysis is that in our proposed topic driven model we need to develop an approach to calculate impact relation between news articles based on proportion of one article’s contents occupying the other article. A straightforward approach is to approximate the impact relation between news articles using document similarity measurement. Document similarity measurements calculate similarities between documents to indicate their relatedness and are usually employed in text classification [46] and text clustering [47] tasks. A simple but effective approach to measuring similarity between documents uses the vector space model, e.g., Cosine Simi-larity1. However, vector space model measures similarity between documents by treating each whole document as a vector. Without focusing on any semantic aspect, documents that are highly ranked as similar according to the vector space model might not necessar-ily relate to each other on the required semantic topic. Wang and Taylor [48] proposed to measure semantic similarities of documents based on concept forests that are generated with the assistance of a natural language ontology. In that work, document similarities are measured based on semantic concepts. However, the generation of concepts depends on the availability of an external ontology, while the semi-supervised topic model proposed in our work does not require knowledge from external resources. The proposed concept-tree-distance based document similarity [49] is a semantic concept based measurement without external knowledge. However, the approach proposed in [49] can neither be guided to focus on semantic topics nor work for the documents that might relate to more than one concerned topics.
CHAPTER 3. STATE OF THE ART 27
3.1.3
Model Parameter Estimation
The proposed semi-supervised topic model in the paper P1 is based on probabilistic topic models, e.g., PLSA [37, 50], LDA [39], which have been proven effective for discovering latent semantic topics through modeling large collections of texts and have already been reported with promising performances on information retrieval [51], summarization [52, 15], clustering [53], classification [54], as well as various web intelligence tasks [6, 55, 56, 57, 58]. In our research, we adopt a topic model to model the news impact. The Maximum Likelihood (ML) estimator with the Expectation Maximization (EM) algorithm [59] is usually used for estimation of this kind of topic models. However, since this parameter estimation process is conducted in an unsupervised setting without any prior knowledge on the trained topics, the generated topic models will probably not be well agreed with required topics. Therefore, there is a challenge on how we can guide the news impact model training process to enforce the generated topic models to seemly represent the required topics.
3.2
Sentiment Analysis on Reviews
Sentiment analysis is a key problem studied under the research field of opinion mining which is at the crossroads of information retrieval and computational linguistics. There have already been a lot of research works that are dedicated to solving this problem. The task of sentiment analysis on reviews was originally performed to extract overall sentiment from the target texts, i.e., document overall sentiment classification. However, in [2], as the difficulty shown in the experiments, the whole sentiment of a document is not necessarily the sum of its parts. Then there came up with research works shifting focus from overall document sentiment to sentiment analysis based on product attributes [4, 60, 61, 5], i.e., attributed-based sentiment analysis. In our research on sentiment analysis on reviews, we investigate both on document overall sentiment classification and attribute-based sentiment analysis.
3.2.1
Document Overall Sentiment Analysis
Document overall sentiment analysis is to summarize the overall sentiment in the docu-ment. There have already been a lot of research works that are dedicated to solving this problem. With different grouping criterion existing research works can be grouped into different categories.
According to different granularity levels on which sentiment classification is to be ana-lyzed, existing papers will mainly fall into two categories: word-level sentiment classifi-cationandphrase-level sentiment classification. Theword-level sentiment classification
is to utilize the polarity annotation of words in each sentence and summarize the over-all sentiment of each sentiment-bearing word to infer the overover-all sentiment within the