Schemaless Representation of Semistructured
Data and Schema Construction
Dong-Yal Seo1, Dong-Ha Lee1, Kang-Sik Moon1, Jisook Chang1,
Jeon-Young Lee1, and Chang-Yong Han2 1 Dept. of Computer Science and Engineering
Pohang University of Science and Technology Pohang, Kyungbuk, 790-784, KOREA
2 Data Warehouse Advanced Technology
Oracle Systems Korea, Ltd. Youngdeungpo-Gu, Seoul, 150-010, KOREA
Abstract. We should consider semistructured data of which have a
weak schema information in networked information world. To manage such semistructured data eciently, this paper introduces a data model for semistructured data and operations for schema construction. We transform semistructured data into structured one by introducing schema construction methodology, compared to the former studies which are fully dependent on schemaless manipulations. For schema construction, we dened operations for buildingIS-A/IS-PART-OFrelationships, col-lecting data objects to build a primitive class, and merging two data instances or classes.
1 Introduction
1.1 Motivation
In early stages of data processing such as inventory/account management sys-tems, a centralized large database system was used as an information server. Through the database design (or real-world modeling) phase, DBA(Database Administrator) denes a well-structured schema. We perform data acquisition and creation after schema denition. For end-users, their role is to manipulate data via predened schema. The schema is rm and end-users are not responsible for schema management.
As data sources and computing environment are distributed, abundant of information is provided by individual users and updated very quickly. Each end-user creates and updates his/her own information, like DBA. The WWW(World-Wide Web) is a typical domain of the examples. Every user creates his/her own documents and submitts in the WWW. How to manage those plenty of HTML documents and other web resources? We should always navigate through hyper-links or search by keywords because there is no absolute schema in the stored information. If we could dene a schema on the set of web resources, not only we have a better structure of gathered information but also we can use a structured query language. Schema provides the well-structured view of
stored data. It expresses data location, relationships among data objects, data categories, summarized concepts, and so on.
The data sets, where there is no absolute schema xed in advance and whose structure may be irregular or incomplete, are known as semistructured data. Even though a data is created as a well-structured, i.e., schema-based, set of data, it becomes semistructured when the data comes out from its original structure. For example, a single record from a relational table is semistructured if we have no idea about the overall structure of the table and the relationships with other tables.
1.2 Problems and Approaches
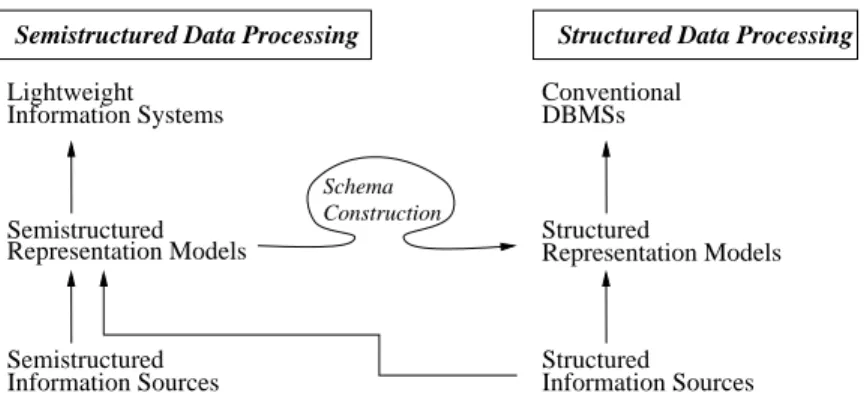
Figure 1 shows the approaches of information processing based on the struc-tural nature of data sources. Right side of the gure presents conventional data processing. Information itself has a rigid structure and is represented with a well-structured model, like relational or object-oriented. Users manipulate data with a schema which mainly provides an structural abstraction of stored data.
Construction
Semistructured
Representation Models StructuredRepresentation Models
Semistructured
Information Sources StructuredInformation Sources Lightweight
Information Systems
Schema
Conventional
Structured Data Processing
DBMSs
Semistructured Data Processing
Fig.1.Information Structures and Processings
Left side shows the processing of information with poor schema, i.e. semistruc-tured information[12] (or even unstructured [3]). Semistructured information is represented with a lightweight model, which permits schemaless creation of data instances, and is stored in a lightweight storage. Stored information is manip-ulated with a lightweight query language, which can be used with incomplete schema information.
The studies on lightweight approaches much overlooked the importance of database schema. Although schemaless manipulation is convenient for users who want to retrieve data without deep knowledge of underlying structures, schema is indispensable for embedded SQL, API calls, or stored procedures. Schema gives rmness and conceptualized view.
In semistructured data processing, end-users represent data instances with-out complete knowledge of the predened schema. (Or even withwith-out any schema
information.) So data creation phase can be performed before schema denition phase. For semistructured data processing, we established the strategy, \schema-less creation, schema-based manipulation" which involves the following goals:
1. Provide a representation model for schemaless data instances. The model should be expressive enough to describe semistructured data instances from heterogeneous data sources.
2. Devise a mechanism for schema construction which can be applied to a schemaless pool of data instances. After applying schema construction pro-cedures, we will have a rigid schema and manipulate the stored data with SQL.
The remaining parts of this paper is composed as follows. Section 2 presents related work and corresponding contributions. Section 3 and 4 address a data model for schemaless creation of data objects and operations for schema con-struction, the main contribution of this work, respectively. And nally, conclusion and directions for future work are discussed in section 5.
2 Related Work
General problems of networked information processing are discussed in [4]. Three conceptual layers of networked information systems are introduced as information Interface, information dispersion, and information gathering. Our work deals with the problems in information gathering layer. More specically, we are interested in data mapping problem and we introduce schema construction operators for that problem. The importance and the motivation about schema-less data representations and manipulations are discussed in [1][3][11][12].
Schemaless data instances are usually described by their attributes and cor-responding values. Attribute-value pairs were used for data representation in OEM(Object Exchange Model)[11], Labeled-Tree[3], and Data Forest Model[1]. Although not developed as a semistructured data model, O2's complex value
model[8] shows a good way of semistructured representation with attribute-value pairs. All the earlier models for semistructured data are similar to each other and their expressive powers are almost same.
TSIMMIS3project[7] introduces OEM and other related work[12] about the
integration of heterogeneous information sources. OEM provides sets and nested substructures as well as atomic values like integers and strings by using attribute-value pairs4. Labeled-Tree model, has the same expressive power as the OEM,
represents semistructured data as trees, i.e., the trees with a labeling of edges. Data Forest Model supports list type which is unable to be described in the OEM and the labeled-tree.
The former studies are mainly focused on lightweight approaches and the importance of database schema is too overlooked. The schema construction ap-proach draws a distinction between our study and conventional methodologies in
3 The Stanford-IBM Manager of Multiple Information Sources
semistructured data processing. The problems on structuring[13] and typing[9] semistructured data are introduced recently.
The studies on subject-oriented programming[10] introduce a methodology for class compositions which deals with behaviors compared to our approach which deals with data.
3 Schemaless Creation of Data Objects
Objects are usually distinguished by their types, where type describes applicable operationsand properties. Properties dene either attributes of the object itself or relationships among objects. We mainly considered data objects from the viewpoint of properties.
3.1 Model Denition
Our data model describes schemaless data objects with a series of attribute-value pairs, called AVPL(Attribute-Value Pairs List). An attribute-attribute-value pair is composed of two tuples, attribute and value. When we denote a set of AVPL, a set of attributes, and a set of values asD, A, and V, respectively, AVPL is dened as follows:
1. Single attribute-value pair is an AVPL
(a2A)^(v2V)?!f(a;v)g2D
2. Union of two attribute-value pairs is an AVPL
D1;D2 2D?!D 1 [D 2 2D
Attributeis an ordered collection of one or more variables, where each variable itself is also an attribute. WhenSdenotes the set of strings, attribute is dened as follows:
1. Singleton attribute
s2S?!s2A
2. Composite attribute (Attribute with multiple variables)
a1;a2;:::;an
2A?!(a
1;a2;:::;an) 2A
where (a1;a2;:::;an) is an ordered sequence of attribute variables.
Value is an assignable instance, or a set of instances, to the corresponding attribute and its variables. Assignment of values to attributes are dened as follows:
1. Singleton attribute and value
a ?v
2. Composite attribute and value (a1;a2;:::;an) ?(v 1;v2;:::;vn) where (a1;a2;:::;an) 2A, (v 1;v2;:::;vn)
2V, and eachvi is assigned toai
(1in).
The domain of attributes includes primitive strings, references of values, set (or list) of values, and AVPL objects. Therefore, an AVPL object itself (or a set of AVPL objects) is also a component of other AVPL objects and allows nested structure.
When we denote a set (or type system) of values as V, types of values are dened as follows:
1. Primitive character strings
s2S?!s2V
whereS denotes a set of strings. 2. References to any type of values
v2V ?!&v2V
where &v is the reference, i.e., identier, ofvand. 3. Set of any types of values (unordered)
v1;v2;:::;vn
2V ?!fv
1;v2;:::;vn g2V
4. List of any types of values (ordered)
v1;v2;:::;vn 2V ?!< v 1;v2;:::;vn> 2V 5. AVPL objects d2D?!d2V
whereD denotes a set of AVPL objects. 6. Null (empty value)
Any attribute can be nullvalued, i.e., no value is assigned. 7. Identier
A self contained label, a string, which begins with `#'. Identier is optional and used by other AVPL objects as a reference.
3.2 Expressive Power
All the atomic values are strings in AVPL. Other kinds of atomic types like integer, oat, and boolean are not provided. Those types can be easily derived from a data source and users are free from atomic types.
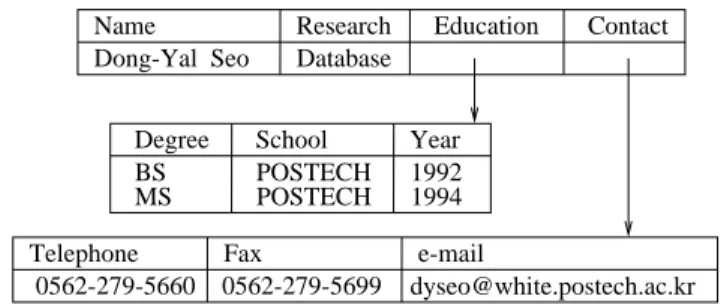
We can represent table-structured values as well as references(identiers), sets, lists,and nested structures. It provides table structures with a composite attribute (as table headers) and a corresponding list of composite values (as record tuples). Advanced semantics of object-oriented model, like IS-A relation-ship cannot be represented. Figure 2 is an example of AVPL object in tabular representation.
Name Research Education Contact Dong-Yal Seo Database
Degree School Year
BS POSTECH 1992
MS POSTECH 1994
Telephone Fax e-mail
0562-279-5660 0562-279-5699 [email protected]
Fig.2.Tabular Representation of an Example AVPL Object
4 Schema Construction
4.1 Schema and Objects
Schema, in an OODB, denes classes and their relationships. And the relation-ships among classes imply the relationrelation-ships among objects. Schema denes both structural and behavioral part of a class. In this work, we mainly focused on structural part.
To construct a schema from a pool of schemaless objects, we should build 1)a class from a set of instances, and 2)various relationships among those classes. At rst, we will remind possible relationships among classes to dene operations for constructing classes and their relationships. There are two relationships be-tween obejcts, IS-A and IS-PART-OF. The former is the basis of the inheritance hierarchy and the latter is is the basis of the composition hierarchy.
A type is a collection of objects with the same structural and behavioral information in an object-oriented model. Type is implemented as a class and the class denes a collection relationship. Not only objects are created as instances of a class, a class could be created as a collection of instances.
One object can be described in more than two ways. In this case, those two descriptions must be merged into a single description because an object is unique in object-oriented world. So two descriptions can have an equivalence relationship.
4.2 Schema Construction Operations
1. Creation of a class by Instance Collection
For the AVPL objectsS1;:::;Smand their attribute-setsA1;:::;Am, a class
of AVPL objectsU is constructed with Object Collect(S
1;:::;Sm)if U =fS
1;S2;:::;Sm g
where the attribute-setU Aof
U isU A=A1
[A 2
[[AmFor all attributes a 2U
A, if there is any AVPL object Si(1
m) where a is not in Ai, the
value ofais NULL. 2. Merging
(a) Object Merging
For two AVPL objectsS and T, a new AVPL object U is constructed with Object Merge(S,T)if
U =fwj(w2S[T)^9^a(^a2S^^a2T)g
where the attribute-set of U is the same as S [T and ^a is a
com-mon(shared) attribute-value pair of S and T. w is an attribute-value pair.
(b) Class Merging
For two classes of AVPL objectsSandT, a new class of AVPL objectsU
is constructed with Class Merge(S,T)ifU2U is constructed with
Ob-ject Merge(S,T)andU is constructed with Object Collect(U
1;U2;:::;Um)
whereS2S,T 2T, and Ui2U for 1im.
3. Composition (IS-PART-OF Relationship) (a) Object Composition
For two AVPL objectsS,T, a new AVPL objectU is constructed with Object Compose(S,T)if
U = (S?t)[T^
wheret2Sandt2T. ^T isT itself or a reference toT. The attribute-set
ofU is the same asS. (b) Class Composition
For two classes of AVPL objects S and T, a new class of AVPL
ob-jects U is constructed with Class Compose(S, T) if U 2 U is
con-structed with Object Compose(S, T) and U is constructed with
Ob-ject Collect(U1;U2;:::;Um) where S
2 S, T 2 T, and Ui 2 U for
1im.
4. Inclusion(IS-A Relationship)
For two sets of AVPL objectsU andV, a new relationship,U is a subset of V, can be constructed with Class Include(U,V)if
U V
where attribute-setsU Aand
V Aof
U andV, respectively, has relationship of VAUA.
5. Trivially we can dene additional operations, such as destruction, splitting, and exclusion, from the inverse of the above dened operations.
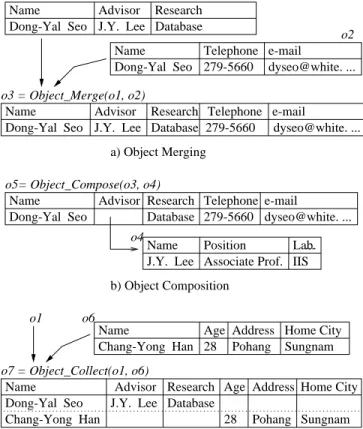
Figure 3 explains the operations Object Merge(), Object Compose(), and Ob-ject Collect(). Other operations like Class Merge() or Class Compose() can be implemented by using Object Merge() or Object Compose() with Object Collect(), respectively. Object Compose() in Figure 3 means composition by reference value.
Name Telephone e-mail
Dong-Yal Seo 279-5660 dyseo@white. ...
Name Advisor Research
Dong-Yal Seo J.Y. Lee Database
Name Advisor Research Telephone e-mail
Dong-Yal Seo J.Y. Lee Database 279-5660 dyseo@white. ...
Research Telephone Advisor
Name e-mail
Dong-Yal Seo Database 279-5660 dyseo@white. ...
Name ...
c) Object Collection to Build a Class Position Lab. J.Y. Lee Associate Prof. IIS
Age Address Home City Name
Chang-Yong Han 28 Pohang Sungnam
Advisor Age
Name Research Address Home City
Dong-Yal Seo J.Y. Lee Database
Chang-Yong Han 28 Pohang Sungnam
o2 o1
o3 = Object_Merge(o1, o2)
a) Object Merging o5= Object_Compose(o3, o4)
o4
b) Object Composition
o7 = Object_Collect(o1, o6)
o1 o6
Fig.3.Example of Schema Construction Operations
4.3 Schema Consistency
When the user runs a schema construction procedure using above mentioned operations, schema evolution takes place in the pre-existing schema. In database world, it is very important to keep schema consistency. We introduce several eects of schema construction operations on the existing schema hierarchy and map the consequences of the eects on the taxonomy of the schema-modication operations listed in [2]. In fact, the schema construction operations might heavily aect static structure of classes.
For example, merge operation could be considered as attribute adding oper-ation in schema evolution taxonomy if the class to be merged has reloper-ationships with other classes. Thus, if the invariants properties of the inheritance hierarchy cannot be preserved, the operation that breaks schema consistency rules should be rejected5.
We chose schema evolution taxonomy of ORION data model based on the
comparisons in [6]. Table 1 shows the taxonomy of schema modications in an object-oriented database and their corresponding schema construction op-erations. It means that we can map the consistency problems by our schema construction operations into schema modication problems.
Because we did not consider the behavioral part of objects, the reader will not nd any taxonomy for methods. We neither address the category of default value attributes or shared attributes dened in [2], since these functions only have valuable meaning in classical object-oriented model where class denition always precedes object instantiation.
Table 1.Schema Construction Operations and Evolutions
Schema Construction Corresponding Schema Evolution
Merge Add attributes
Split Delete attributes and build a new class Compose Modify the domain's attributes
Decompose Modify composite attributes into noncomposite attributes Include Make a classS the superclass of classC
Exclude Remove a classS from the list of superclasses of classC
Collect Create a new class
5 Conclusion and Future Work
We introduced a new model of database processing where objects are created before schema denition. We dened a type system for semistructured data in-stances, and the operations for the construction of structural schema from a set of schemaless data instances.
In our data model, a schemaless data instance is created as a description which contains a list of user-dened attributes and their corresponding values. For schema construction, we dened operations for building IS-A and IS-PART-OFrelationships, collecting objects to build a class, and merging two objects or classes to make a larger one. Operations can be applied in both object-level and class-level.
Our approach is suitable for the applications where we collect and manage semistructured data instances, which are not created as instances of predened schema. Database system for collected HTML documents is a good application of our work. HTML documents have signicantly less structure than the examples in this paper and it is more dicult to extract the attribute-value pairs needed to construct the schema.
References
1. Abiteboul, S., Cluet, S., Milo, T.: Correspondence and Translation for Heteroge-neous Data.Proceedings of the '97 ICDT, Delphi, Greece (1997) 352{363
2. Banerjee, J., Kim, W., Kim, H., Korth, H.: Semantics and Implementation of Schema Evolution in Object-Oriented Databases.Proceedings of the '87 ACM SIG-MOD, San Francisco, CA (1987) 311{322
3. Buneman, P., Davidson, S., Hillerbrand, G., Suciu, D.: A Query Language and Optimization Techniques for Unstructured Data.Proceedings of the '96 ACM SIG-MOD, Montreal, Canada (1996) 505{516
4. Bowman, C., Danzig, P., Manber, U., Schwartz, M.: Scalable Internet Resource Dis-covery: Research Problems and Approaches.Communications of the ACM.37(8)
(1994) 98{107
5. Bowman, C., Danzig, P., Hardy, D., Manber, U., Schwartz, M.: The Harvest In-formation Discovery and Access System.Proceedings of the Second International World Wide Web Conference, Chicago, Illinois (1994) 763{771
6. Tsichritzis, D., ed.:Object Management. Centre Universitaire d'Informatique, Uni-versity of Geneva (1990)
7. Chawathe, S., Garcia-Molina, H., Hammer, J., Ireland, K.: The TSIMMIS Project: Integration of Heterogeneous Information Sources.Proceedings of IPSJ Conference, Tokyo, Japan (1994)
8. Bancilhon, F., Delobel, C., Kanellakis, P. eds.:Building an Object-Orient System: The Story of O2. Morgan Kaufmann, San Mateo, CA (1992)
9. Nestorov, S., Abiteboul, S., Motwani, R.: Inferring Structure in Semistructured Data. Proceedings of the Workshop for the Management of Semistructured Data (in Conjunction with '97 ACM PODS/SIGMOD), Tucson, Arizona (1997) 42{48 10. Ossher, H., Kaplan, M., Harrison, W., Katz, A., Kruskal, V.: Subject-Oriented
Composition Rules. Proceedings of the OOPSLA '95, Austin, Texas (1995) 235{ 250
11. Papakonstantinou, Y., Garcia-Molina, H., Widom, J.: Object Exchange Across Heterogeneous Information Sources. Proceedings of the 11th IEEE International Conference on Data Engineering, Taipei, Taiwan (1995) 251{260
12. Quass, D., Rajaraman, A., Ullman, J., Widom, J.: Querying Semistructured Het-erogeneous Information.Proceedings of 4th International Conference on Deductive and Object-Oriented Databases, Singapore (1995) 319{344
13. Seo, D., Lee, D., Lee, K., Lee, J.: Discovery of Schema Information from a Forest of Selectively Labeled Ordered Trees.Proceedings of the Workshop for the Manage-ment of Semistructured Data (in Conjunction with '97 ACM PODS/SIGMOD), Tucson, Arizona (1997) 54{59