BNU HKBU UIC NLP Team 2 at SemEval 2019 Task 6: Detecting Offensive Language Using BERT model
Full text
Figure
Related documents
In this paper we apply a range of approaches to language modeling — including word- level n -gram and neural language models, and character-level neural language models — to the
The SemEval-2019 Shared Task 6: Identifying and Categorizing Offensive Language in Social Media was divided into three sub-tasks, namely offensive language identification (Sub-task
We train multiple models using different ma- chine learning algorithms to evaluate the efficacy of each of the pre-trained sentence embeddings for the downstream sub-tasks as defined
The paper describes the insights obtained when tackling the shared task using an ensemble of traditional machine learn- ing classification models and a Long Short-Term Memory
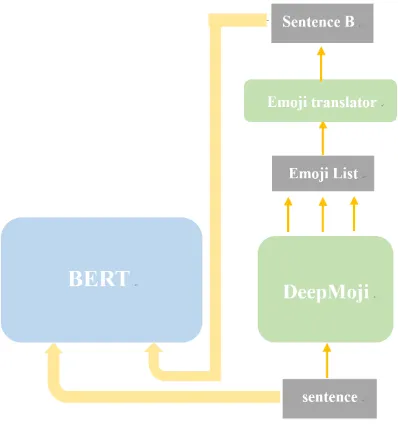
Our approach for the SemEval-2019 task 6 (identi- fying and categorizing offensive language in social media) comprises of deep learning models: Bidi- rectional LSTM, Bidirectional
Supervised pre-training of our neural network architecture is performed as multi- task learning of parallel training of five different NLP tasks with some overlap to offensive
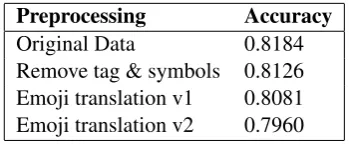
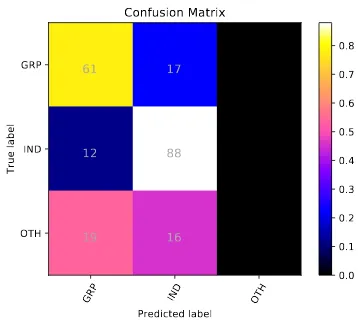
The main reason can be de- creasing amount of data for each of them, where Sub-task A has more data followed by Sub-task B categorizing offensive tweets identified by Sub- task A
a large pre-trained language model, (2) A CNN- based encoder that learns task-specific sentence representations, (3) an MLP classifier that predicts the label given the joint
