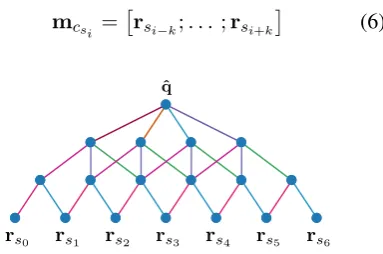
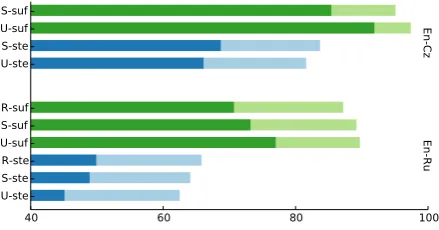
Word Translation Prediction for Morphologically Rich Languages with Bilingual Neural Networks
13
0
0
Full text
Figure


+3


Related documents