Research Article
a
May
2018
Computer Science and Software Engineering
ISSN: 2277-128X (Volume-8, Issue-5)
An Improvement on Deep Time Growing Neural Network
on Biological Signals: Review
Manpreet Kaur
Research Scholar, Guru Kashi University, Talwandi Sabo, Punjab, India
Er. Jashanpreet Kaur
Assistant Professor, Guru Kashi University, Talwandi Sabo, Punjab, India
Abstract: A novel method for learning the cyclic contents of stochastic time series: the deep time-growing neural network (DTGNN). The DTGNN combines supervised and unsupervised methods in different levels of learning for an enhanced performance. It was employed by a multiscale learning structure to classify cyclic time series (CTS), in which the dynamic contents of the time series are preserved in an efficient manner. This paper suggests a systematic procedure for finding the design parameter of the classification method for a one versus-multiple class application. In this paper different authors research papers are reviewed and different problems are stored and now these problems are resolved.
Keywords: DNN, HMM, CTS, MLP, TDNN etc.
I. INTRODUCTION
Time series classification has been a topic of study over decades. Several supervised and unsupervised methods have been suggested with which to learn the dynamic contents of time series. Dynamic time warping, hidden Markov model (HMM), and artificial neural network are three well known methods extensively employed in many contexts, e.g., automatic speech recognition [1]–[3]. Nevertheless, the development of a classification method sophisticated for the cyclic time series (CTS) had been overlooked in the model level, even though a number of methods were subjectively applied to the CTS [4]–[6]. A CTS is described as a no stationary time series exhibiting repetitive characteristics. Unlike periodic time series, the cyclic duration of a CTS can be inconsistent, but repetitive patterns are observed. This cyclic behavior attributes special features to the time series that can be exploited by a classifier to enhance its classification performance. The importance of developing a sophisticated method for the CTS classification is realized when considering that a recording of many natural phenomena and biological activities resembles a CTS. As an example, phonocardiogram (PCG) is a recording of the sounds emanating from the mechanical activity of a heart. This is considered as a typical CTS where the cycle duration is affected by a number of physiological activities, e.g., respiration. Several studies reported the importance of having a reliable decision support system for screening pediatric cardiac disease in primary healthcare centers, as the screening accuracy is still considerably low [7], [8]. The main challenge for developing a decision support system for screening cardiac disease is a reliable method for processing and classifying the PCG signal. Such a need is seen in different medical applications, in which the biological signal is cyclic, and the classification of the signal can be important, and sometimes critical to patient monitoring, as is the case, for instance, with the classification of the patterns associated with electroencephalograms (EEGs). Biological signals with cyclic characteristics often show no stationary behavior not
only within the cycles, but over them in the cycle-to-cycle variation. This associates a high level of complexity with the signal that makes the development of the classifier, a big challenge. Unlike many industrial applications, the origin of the complexities in the majority of the biological signals has yet to be fully understood. As a result, the stochastic models can provide a better learning than deterministic ones, especially when it comes with a general model for diverse medical applications. Such a model needs to be capable of coping with the complexities of the signals.
ISSN(E): 2277-128X, ISSN(P): 2277-6451, pp. 21-26 discriminative features. The proposed classifier is statistically validated using four different data sets, comprised of EEG, electromyogram (EMG), PCG, and phonorespirogram (PRG) signals. Three baselines are introduced to investigate the effect of the proposed multiple mapping structure.
II. DEEP NEURAL NETWORKS
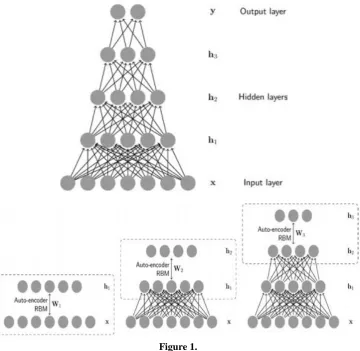
The basic structure of DNNs consists of an input layer, multiple hidden layers, and an output layer. Once input data are given to the DNNs, output values are computed sequentially along the layers of the network. At each layer, the input vector comprising the output values of each unit in the layer below is multiplied by the weight vector for each unit in the current layer to produce the weighted sum. Then, a nonlinear function, such as a sigmoid, hyperbolic tangent, or rectified linear unit (ReLU) [3], is applied to the weighted sum to compute the output values of the layer. The computation in each layer transforms the representations in the layer below into slightly more abstract representations [4]. Based on the types of layers used in DNNs and the corresponding learning method, DNNs can be classified as MLP, SAE, or DBN.
MLP has a similar structure to the usual neural networks but includes more stacked layers. It is trained in a purely supervised manner that uses only labeled data. Since the training method is a process of optimization in high-dimensional parameter space, MLP is typically used when a large number of labeled data are available.
Figure 1.
SAE and DBN use AEs and RBMs as building blocks of the architectures, respectively. The main difference between these and MLP is that training is executed in two phases: unsupervised pre-training and supervised fine-tuning. First, in unsupervised pre-training (Figure 1.2), the layers are stacked sequentially and trained in a layer-wise manner as an AE or RBM using unlabeled data. Afterwards, in supervised fine-tuning, an output classifier layer is stacked, and the whole neural network is optimized by retraining with labeled data. Since both SAE and DBN exploit unlabeled data and can help avoid over fitting, researchers are able to obtain fairly regularized results, even when labeled data are insufficient as is common in the real world [5].
III. RELATED STUDIES
Early studies on dynamic classifiers suggested dynamic time warping for speech recognition. However, many
ISSN(E): 2277-128X, ISSN(P): 2277-6451, pp. 21-26 their inefficiencies with the multidimensional time series. The HMM has been proposed as a statistical method for time series classification where the dynamic behavior of a time series is modeled by a set of the states in conjunction with their interconnection, and the probability features are often employed for the classification purpose. The application of HMM has been of interest for speech recognition, in which state and symbol probabilities along with state transition probability play important roles in the recognition task. The MLP neural network was considered to be another alternative to HMM within this context, but its strong link to HMM was later understood by the researchers. An MLP by itself could not include the dynamic contents of time series in its architecture, and therefore, the TDNN was introduced as the transition invariant Backpropagation for the noisy speech recognition tasks. The conventional TDNN includes the dynamic contents of time series over a set of the temporal windows. This makes the dimension of the feature vectors become large, which will, in turn, increase the structural risk of the classifier. The recurrent neural network was suggested as another dynamic classifier to provide probabilistic modeling. One of the interesting aspects of neural networks in comparison with HMM is their capability of quick learning with limited size of the training data, whereas the presence of local minimum is considered to be disadvantage along with the high structural risk. The SVM was later introduced to perform binary classification in a convex way, and therefore to overcome the problem of local minima associated with MLP. It provides rather immunity against the outliers than MLP as the outliers are not contributed in the training, and also provides flexibilities in terms of the nonlinear mapping thanks to the kernel-based performance. Recent progress proposed the use of the kernels, which include the dynamic contents of time series, i.e., the autoregressive kernel. Other kernel based studies highlight different aspects of such an approach in classification. The hybrid models have also been introduced for the classification purposes as a combination of two different models, e.g., HMM and MLP, where some of the parameters of one model are obtained from the other one. The hybrid models have been employed in data intensive domains, such as biomedical signal processing and natural language processing. The dynamic SVM is a hybrid model inspired by the concepts from nonlinear dynamics systems where an appropriate nonlinear model, i.e., the Russler system, serves as a tool for a classifier composed of the SVM method. Our recent study proposed a combination of HMM and SVM in conjunction with a preprocessing phase for binary classification of time series. The application of the artificial intelligence methods has been extended to a heart sound analysis to screen patients with cardiac abnormalities from the healthy ones. The nonstationary characteristics of heart murmurs along with between-class similarities act as a hamper to the development of an appropriate method. Artificial intelligence methods, e.g., MLP, HMM, hybrid methods, and the combination of MLP and statistical methods, have been reported in a number of studies for the purpose of the PCG analysis. In many medical applications, where signal processing is an objective, including neuroelectrical studies, my electric analysis, and lung sound classification, such artificial intelligence based methods are essentially needed to overcome the signal complexities. Recent studies suggested the use of the growing window associated with the MLP classifier. In this case, the growing scheme was tentatively selected according to the prior insight about the signal characteristics. These studies commonly proposed growing schemes tailored for a specific classification problem, and failed to address a deep learning process for finding the characteristics of the growing scheme.
IV. LITERATURE SURVEY
Arash Gharehbaghi et.al.[2017] have studied a novel method for learning the cyclic contents of stochastic time series: the deep time-growing neural network (DTGNN). The DTGNN combines supervised and unsupervised methods in different levels of learning for an enhanced performance. It was employed by a multiscale learning structure to classify cyclic time series (CTS), in which the dynamic contents of the time series are preserved in an efficient manner. This paper suggests a systematic procedure for finding the design parameter of the classification method for a one versus-multiple class application. A novel validation method is also suggested for evaluating the structural risk, both in a quantitative and a qualitative manner. The effect of the DTGNN on the performance of the classifier is statistically validated through the repeated random sub sampling using different sets of CTS, from different medical applications. The validation involves four medical databases, comprised of 108 recordings of the electroencephalogram signal, 90 recordings of the electromyogram signal, 130 recordings of the heart sound signal, and 50 recordings of the respiratory sound signal. Results of the statistical validations show that the DTGNN significantly improves the performance of the classification and also exhibits an optimal structural risk.[1]
ISSN(E): 2277-128X, ISSN(P): 2277-6451, pp. 21-26 comparable results to its fully-supervised equivalent. Our semi-supervised method has the significant advantage of reduced annotation cost. Furthermore, it reduces the opportunity for human error in the labeling process normally required for training of segmentation algorithms. It also lowers the annotation cost of training a model capable of continuous monitoring of cycle characteristics such as those employed to analyze the progress of movement disorders or analysis of running technique.[2]
Timothy J. O‟Shea et.al.[2016] have studied the adaptation of convolutional neural networks to the complex-valued temporal radio signal domain. We compare the efficacy of radio modulation classification using naively learned features against using expert feature based methods which are widely used today and e show significant performance improvements. We show that blind temporal learning on large and densely encoded time series using deep convolutional neural networks is viable and a strong candidate approach for this task especially at low signal to noise ratio.[3]
Alan Jovic et.al.[2014] have studied patient disorder classification and prediction from biological signals is addressed. We approach the problem from the perspective of nonlinear dynamical systems. Explored signals are ECG and EEG. We propose a combination of linear and nonlinear features for classification of four different types of heart rhythms through heart rate variability analysis. Classification accuracy is evaluated by three well known machine learning algorithms: C4.5, support vector machines and random forest. The algorithms‟ success rates are compared. The method of combining linear and nonlinear measures shows promising results in heart rate variability modeling. Random forest method has exhibited 99.6% classification accuracy.[4]
Jurgen Schmidhuber et.al. [2014] have studied deep artificial neural networks (including recurrent ones) have won numerous contests in pattern recognition and machine learning. This historical survey compactly summarises relevant work, much of it from the previous millennium. Shallow and deep learners are distinguished by the depth of their credit assignment paths, which are chains of possibly learnable, causal links between actions and effects. I review deep supervised learning (also recapitulating the history of back propagation), unsupervised learning, reinforcement learning & evolutionary computation, and indirect search for short programs encoding deep and large networks.[5]
V. PROBLEM FORMULATION
In this research topic the different problems are studied these problems are given below:
1. There is specific classification problem, and failed to address a deep learning process for finding the characteristics of the growing scheme.
2. Another problem is temporal and spectral resolution problem.
3. There is class problem for multiple input data.
4. Another is N-class decision problem.
5. The problem of patient disorder classification and prediction from biological signals.
6. The quadratic programming optimization problem.
7. Another problem is regression problems.
VI. RESEARCH METHODOLOGY
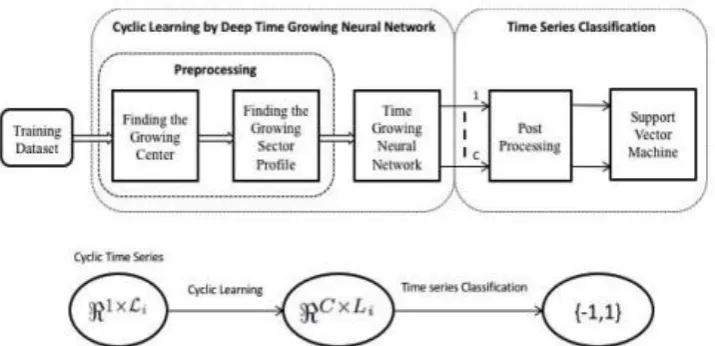
The proposed classifier is sophisticated to overcome the complexities that exist in CTS of biological signals. It introduces three levels of learning: within the cycles, over the cycles, and the time series classification. The first two levels cope with the nonstationary behaviors of the biological CTS, while the last one performs the one-versus-multiple class learning. The dynamic contents of the time series are explored by using the growing sectors in all three schema as introduced. The learning process is based on the spectrasectoral contents of the growing sectors. Fig. 2 demonstrates two cycles of a time series along with the growing schema with K = 4 sectors. The number of the growing sectors is considered as a design parameter is found in the optimization process. The method proposes an algorithm for finding an optimal growing center. For a certain sector of a cycle, the spectral contents are calculated over the corresponding sectors of the other cycles. The resulting spectra-sectoral contents are employed for the cyclic learning. The proposed classifier pays special attention to the cyclic learning by introducing a novel learning method, the DTGNN to improve the discrimination power.
ISSN(E): 2277-128X, ISSN(P): 2277-6451, pp. 21-26 characteristics and in the middle and output layers for the quantification. In the third level, the outcomes of the TGNN are employed by a binary classifier after the statistical processing. The supervised learning in both the second and third levels utilizes the binary label qi defined in (7) for the classification. The learning process is composed of a multiscale method for enhanced training, and a systematic procedure is proposed to determine the optimal set of design parameters.
Figure 2. Two cycles of a biological time series. The information is extracted from the growing sectors using all the three schema: forward, backward, and bilateral growing scheme. The number of the growing sectors is K = 4 and
the growing center is selected at the 75% of the cycle duration, for illustrational simplicity
Figure 3. Flowchart (top) of the classification process and the corresponding flow mapping (bottom).
VII. CONCLUSION
Early studies on dynamic classifiers suggested dynamic time warping for speech recognition. However, many researchers believe that the structures, which involve dynamic time warping, cannot provide a suitable baseline due to their inefficiencies with the multidimensional time series. In this paper different problems are specific classification problem, and failed to address a deep learning process for finding the characteristics of the growing scheme. Another problem is temporal and spectral resolution problem. The problem of patient disorder classification and prediction from biological signals. All these problems are resolved with modified Deep Machine Learning Method for Classifying Cyclic Time Series of Biological Signals Using Time-Growing Neural Network.
REFRENCES
[1] Arash Gharehbaghi et.al. “A Deep Machine Learning Method for Classifying Cyclic Time Series of Biological
Signals Using Time-Growing Neural Network” IEEE Transactions On Neural Networks And Learning Systems -2017.
[2] Christine F. Martindale et.al. “Smart Annotation of Cyclic Data Using Hierarchical Hidden Markov Models” ,
ISSN(E): 2277-128X, ISSN(P): 2277-6451, pp. 21-26
[3] Timothy J. O‟Shea et.al. “Convolutional Radio Modulation Recognition Networks” arXiv:1602.04105v3
[cs.LG] 10 Jun 2016.
[4] Alan Jovic et.al. “Classification of Biological Signals Based on Nonlinear Features” University of Zagreb, Unska 3, 10000 Zagreb, Croatia-2014.
[5] Jurgen Schmidhuber et.al. “Deep Learning in Neural Networks: An Overview” Galleria 2, 6928 Manno-Lugano
Switzerland 2 July 2014.
[6] A. Graves, A. Mohamed, and G. E. Hinton, “Speech recognition with deep recurrent neural networks,” CoRR,
vol. abs/1303.5778, 2013. [Online]. Available: http://arxiv.org/abs/1303.5778.
[7] T. O‟Shea, “Gnu radio channel simulation,” in GNU Radio Conference 2013, 2013.
[8] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” CoRR, vol. abs/1412.6980, 2014. [Online]. Available: http://arxiv.org/ abs/1412.6980.
[9] F. Chollet, Keras, https://github.com/fchollet/keras, 2015.
[10] M. Jaderberg, K. Simonyan, A. Zisserman, and K. Kavukcuoglu, “Spatial transformer networks,” CoRR, vol.
abs/1506.02025, 2015. [Online]. Available: http://arxiv.org/abs/1506.02025.
[11] T. N. Sainath et al., “Learning the speech front-end with raw waveform cldnns,” in Proc. Interspeech, 2015.