2019 International Conference on Computational Modeling, Simulation and Optimization (CMSO 2019) ISBN: 978-1-60595-659-6
The Application of Improved FP-Growth Algorithm in
Disease Complications
Xia GAO
1,*, Fang-qin XU
1and Zhi-min ZHU
21College of Information Technology, Shanghai Jian Qiao University, Shanghai, 201306, China
2School of Computer Science and Technology, Donghua University, 201620, Shanghai, China
*Corresponding author
Keywords: FP-Growth, Data mining, Association rules, Wisdom medical.
Abstract. With the rapid development of computer technology, data mining using association rules has been widely used in all walks of life. FP-Growth algorithm is an association rule algorithm. It does not need to generate candidates, so it has practical value for the study of disease complications. However, it is inefficient and prone to spillover due to its large scale medical data. This paper proposes an improved algorithm based on the FP-Growth algorithm, which sets the minimum support threshold and deletes infrequent item sets to improve the operation efficiency. Experimental results show that this algorithm accelerates the speed of data mining and improves the processing efficiency in the medical data environment.
Introduction
In recent years, traditional medical models such as lack of medical resources and uneven distribution of medical resources have greatly affected the development of medical services in China. These problems have led to the urgent need for the transformation and reform of the traditional medical mode in China. The arrival of the information age has promoted the development of the medical industry and brought the traditional medical industry into a new era[1].
The emergence and application of the concept of "smart medicine" has greatly changed the traditional Chinese medical model[2], and alleviated the situation of many patients with fewer medical resources. However, with the rapid increase on the amount of medical data, the problems of data redundancy and inefficient operation efficiency are urgently needed to solve. How to improve the retrieval and processing efficiency of medical data through information technology, how to provide medical staff with effective, accurate and reliable disease data, how to get the probability data of the occurrence of disease complications, these have become the core issues in the process of the development of wisdom medical .
Association Rule
Data mining is a type of decision support process, a process of searching for available information hidden in a large amount of data.[3]. Specifically, it is to mining information and data hidden from a large number of random data, but the information and data through mining must be useful[4]. Analyze the information and data after mining and provide intuitive information demonstrations by using visual methods or other friendly ways for decision makers to help decision makers grasp the internal rules and patterns, reduce the probability of error appearance and provide the correct decision support.
potential complications, find out the frequent relationship between different complications of the disease, and provide a more comprehensive decision support for wisdom medical.
Rules in association rules: I={i1,i2.…,in} is all sets of D database. Implication X=>Y can be used to express the relationship between things[6], in this implication X ⊂ I, Y ⊂ I and X ∩ Y = ∅.
The support of the implication X=>Y is the ratio of the number of transactions of X and Y to all transactions, it can be expressed as:
Sopport(X => Y) =P(X∪Y)D (1) The confidence of the implication X=>Y is the ratio of the number of transactions of X and Y to the number of transactions of X, it can be expressed as:
Confidence(X => Y) =P(X∪Y)P(X) (2)
FP-Growth Algorithm
With the growth of data scale and the increasing demand for computing volume, the environment of independent computers cannot meet the actual application requirements in terms of storage capacity and computing speed. The FP-Growth algorithm is a parallel computing method that can solve storage capacity and computing speed. A frequent pattern mining algorithm was proposed by Han et al.[7], which is an algorithm for mining association rules without generating candidates.
The Idea of the FP-Growth Algorithm. The basic idea of the FP-Growth algorithm is to use a tree structure to compress transactions and preserve the relationship between attributes in transactions [8]. To create the FP-Tree, the FP-growth algorithm only needs to complete two scans of the transaction set. This greatly reduces the number of scans and improves operational efficiency.
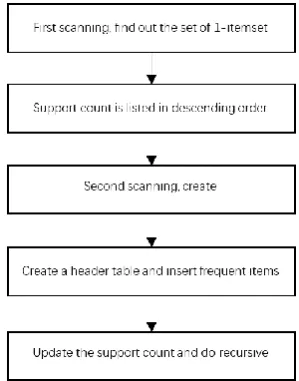
The first scan obtains the frequency of the current item, removes the items that do not meet the support requirements, and sorts the remaining items. [9].
For the second scanning, FP-tree is built, marking its root node as "NULL" and creating a header table. The frequent items are sequentially inserted into the FP-tree, and the support count of each tree node is updated. Figure 1 shows the flowchart of the classic FP-Growth algorithm.
Figure 1. The flow chart for classical FP-Growth algorithm.
[image:2.595.223.373.498.689.2]Giving an example of using an improved FP-growth algorithm is better to illustrate the mining process. Setting the minimum support threshold is three.
First, scan database D in Table 1 and find out the set of 1-itemset and get their support count A={a:4,b:4,c:1,d:3,e:3,f:3,g:3}. The item C that does not meet the minimum support degree is deleted. In addition, the transaction order is reordered to generate Table 2 database D1 according to the descending order of support counts.
Table 1. Database D.
Tid Items Bought T1 a b c d e f g h
T2 a f g
T3 b d e f
T4 a b d
[image:3.595.233.363.173.459.2]T5 a b e g
Table 2. Database D1.
Tid Items Bought T1 a b d e f g h
T2 a f g
T3 b d e f
T4 a bd
T5 a b e g
Table 3. Header Table.
Item Support Count
a 4
b 4
d 3
e 3
f 3
g 3
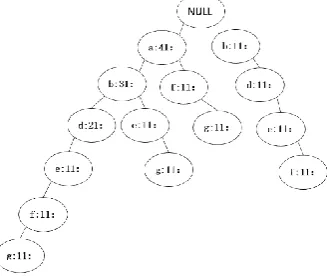
[image:3.595.217.381.547.685.2]Second, scan database D1 in Table 2. FP-Tree can be built after header table has been created. For the first transaction T1, the first branch is created with 7 nodes, in which a is the child node of the root, and the rest of the node is the chain node[10]. For the later transactions, if there is a shared prefix node, the prefix node is used directly and the number of nodes is increased by 1. If there is no shared node, a new node will be built directly [11]. Finally the FP-Tree diagram is created as shown in Figure 2.
Figure 2. Creation of FP-Tree.
Simulation Experiment
One is to analyze the support count extracted by FP-Growth algorithm and get the final support and confidence, the other is to compare the difference in operational efficiency between the classic FP-Growth algorithm and the improved FP-Growth algorithm.
[image:4.595.90.505.182.245.2]Sample Analysis. According to the new algorithm, processing data of disease complications, and deleting data items less than the minimum support threshold, and obtaining support and confidence according to association rules, as shown in Table 4.
Table 4. Values of support and confidence.
Implication Support Confidence
hypertension=>dizzy 31.39% 71.23%
hypertension=>coronary disease 23.27% 62.45%
dizzy=> hypoglycemia 24.45% 65.92%
diabetes mellitus=>coronary disease 20.27% 60.10%
Table 4 shows that implication hypertension=>dizzy has a higher degree of support and confidence, at the same time, patients with hypertension has higher support in patients with hypertension and dizzy symptoms, it will give doctors more information on complications in the process of diagnosis and treatment for reference.
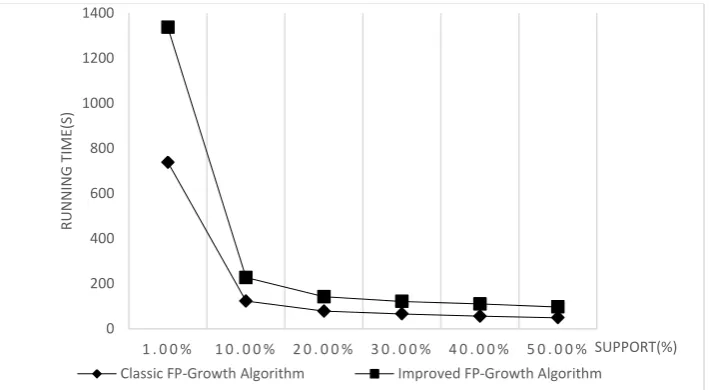
Performance Analysis. In order to make the experimental data more intuitionistic, the comparison results are represented by a line chart, as shown in Figure 3.
[image:4.595.122.477.392.587.2]From the performance comparison results shown in Figure 3, it can be clearly seen that, in terms of performance, the improved FP-Growth algorithm is better than the traditional FP-Growth algorithm. When the support is reduced, the classic one has a more significant reduction in runtime, while the improved one has a more stable growth.
Figure 3. Contrast diagram of algorithm performance.
Summary
This paper analyzes the current problems in the wisdom medical, expounds the essence of association rules, and proposes an improved FP-Growth algorithm, so as to serve the growing volume of medical data. Devoted to its application of disease complications, experiment results compare the performance difference between the classical FP-Growth algorithm and the improved FP-Growth algorithm, and get the support and confidence of disease complications with the improved FP-Growth algorithm. This will provide a new decision support for medical diagnosis.
Acknowledgement
This thesis is one of the achievements of the construction of the innovation base for the employment of college graduates funded by the Shanghai Municipal Education Commission, the extra-curricular
0 200 400 600 800 1000 1200 1400
1 . 0 0 % 1 0 . 0 0 % 2 0 . 0 0 % 3 0 . 0 0 % 4 0 . 0 0 % 5 0 . 0 0 %
R
UN
N
ING
T
IME(S)
SUPPORT(%)
practice base project of the Internet of Things Engineering. I would like to express my sincere gratitude. I also thank Shanghai Jianqiao College and colleagues who provide help and support at work.
References
[1] Fangqin Xu, Haifeng Lu. "The Application of FP-Growth Algorithm Based on Distributed Intelligence in Wisdom Medical Treatment", International Journal of Pattern Recognition and Artificial Intelligence, 2017.
[2]Yang Yong, Wang Wei. A parallel FP-growth algorithm based on Mapreduce [J]. Journal of Chongqing University of Posts and Telecommunications (Natural Science Edition), 2013, 25 (5):652-657.
[3] Shi Liang, Qian Xuezhong. Research and Implementation of Parallel FP-Growth Algorithm Based on Hadoop[J]. Microelectronics & Computer, 2015, (04):150-154.
[4] Wei X, Ma Y, Zhang F, et al. Incremental FP-Growth mining strategy for dynamic threshold value and database based on MapReduce[C]//IEEE International Conference on Computer Supported Cooperative Work in Design. 2014:271-276.
[5] Chen Yin. Study on association rule mining algorithm based on FP-GROWTH algorithm [J]. Wireless Internet Technology. 2017, (19):118-121.
[6] Zhang Zhenyou, Sun Yan, Ding Tiefan, Liu Pengfei. A novel distributed parallel FP-Growth algorithm based on Hadoop framework [J]. Hebei Journal of Industrial Science and Technology. 2016, (02):169-177.
[7] Cho Y, Ahn Y, Yoon S, et al. Analysis of anti-cancer cytokines by Apriori algorithm, decision tree, and SVM[C]//International Conference on Big Data and Smart Computing. IEEE, 2015:232-237.
[8] Li Jun, Li Lingjuan. Design and parallel implementation of minimum spanning tree based K-means algorithm [J]. Journal of Nanjing University of Posts and Telecommunications (Natural Science Edition), 2017, (05):81-86.
[9] Feng Yuan, Dai Xiaoxia, Tang Xiaobin, Gong Xiaoyan. FDTD parallel algorithm based on distributed platform [J]. Journal of Beijing University of Aeronautics and Astronautics, 2016, [09]:1874-1883.
[10] Kuikui Jia, Haibin Liu. An Improved FP-Growth Algorithm Based on SOM Partition[C]. Abstracts of the Third International Conference of Pioneering Computer Scientists. 2017: 62-64.