2017 2nd International Conference on Computational Modeling, Simulation and Applied Mathematics (CMSAM 2017) ISBN: 978-1-60595-499-8
Optimization of GPU-Based Main-Memory Hash Join
Guo-hua LI
1, Yu-qi REN
2, Can LUO
3,
Jin HUANG
3,*and Yang-dong DENG
31School of Transportation and Logistics, Southwest Jiaotong University, Chengdu, 610031, China
2CRRC Dalian Research Institute Co. Ltd., Dalian, Liaoning, 116021, China
3School of Software/KLISS/TNList, Tsinghua University, Beijing, 100084, China
*Corresponding author
Keywords: Hash join, Query optimization, GPU.
Abstract. With the advent of the big data era, highly efficient and scalable join algorithms are becoming increasingly essential for database operations. As a result, recent years witnessed a strong momentum in accelerating join algorithms with multi- and many-core processors. Among various acceleration platforms, GPUs have the advantage in terms of raw computing power and scalability. The hash join problem, however, poses unique challenges for effective GPU implementations. Especially, a complete treatment of the problem by systematically considering various GPU architectural details and input characteristics is still missing. In this work, we built a GPU-based testbed to systematically study the performance tradeoffs of developing highly efficient GPU implementations for hash join. On such a basis, we investigated a set of essential building blocks including data transfer mechanisms between host (CPU) and device (GPU) to take advantage of the PCI-E bandwidth, a streaming scheme to effectively overlap data transfer and kernel execution, and an atomic-free transformation to minimize costly synchronization overhead. By integrating these blocks, we are able to improve the hash join performance to a new level. The experimental results show that our GPU implementation of hash join outperforms the state-of-the-art results by up to 111%. We also proposed a framework to guide the selection of optimization strategies.
Introduction
The join operation is a fundamental part of modern database systems. Due to its performance advantages over other join algorithms such as nested-loops join and sort-merge join, hash join [1] has become one of the most popular join algorithms. Today the hash join operation is even more critical due to its wide deployment in main-memory databases [2]. As a result, significant effort has been dedicated to improving the performance of hash join. The existing work can be categorized into two orthogonal directions, algorithmic improvements and parallel executions. The former family of techniques, such as grace hash join [3] and the hybrid hash join [4], overcomes the insufficiency of the original hash join, while the latter category of approaches resorts to the computing power made possible by multi-core CPUs [5], many-core platforms exemplified by graphics processing units (GPUs) [6],[7], and heterogeneous platforms like FPGAs [8] and accelerated processing units (APUs) [9]. In this work, we focus on the parallel computing approach on GPUs.
algorithmic components and different points of improve have to be evaluated in a systematic framework.
To address the above problem, we revisit the GPU accelerated main-memory hash join problem in this paper by constructing a systematic testbed so that different algorithmic enhancements can be analyzed in an integrated manner. We analyze major components of GPU-based main-memory hash join algorithm in multiple dimensions and devise the state-of-the-art optimization solutions. The strategies are integrated into a GPU based testbed for performance evaluation. The experimental results show that our GPU implementation of hash join outperforms the state-of-the-art GPU results by at least 65% and up to 111%.
A Testbed for GPU Accelerated Hash Join
Architecture
[image:2.595.183.412.323.468.2]In this work, we use the simple hash join (SHJ) listed in Algorithm 1 as it is the fundamental form of the hash join algorithms. In practice, the GPU implementation of SHJ outperforms the counterparts of other variants [7]. As shown in the algorithm form in Algorithm 1, SHJ operates on two input tables, R and S. The symbols used in this paper is listed in Table 1.
Table 1. Symbols used in this paper.
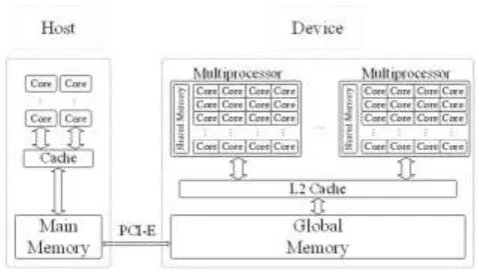
Figure 1. CPU-GPU heterogeneous architecture. Table 2. Hardware and software configuration of the testbed.
Our testbed is a high performance workstation equipped with an Intel(R) Core(TM) i7-5960X CPU and 64GB of DDR3 main memory. An Nvidia GTX 980Ti GPU is added to the motherboard as co-processor and accessed via 16-lane PCI-E 3.0 bus with the theoretic peak bandwidth of 15.75GB/s [11]. We run the experiments on Ubuntu 16.04 with Nsight Eclipse and CUDA 8. The configuration of the hardware and software platform is outlined in Table 2.
Implementation
We developed a GPU accelerated SHJ algorithm by following the techniques proposed by Kaldewey et al. [7] as the baseline implementation. The processing flow follows the typical host-device computing pattern as follows.
1) Initialize two input tables, R and S
2) Transfer R and S from host (CPU) to device (GPU)
3) Build hash table H from R in the device (Building phase)
4) Probe hash table H with S and generate result table T in the device. (Probing phase)
5) Transfer T from device to host
In our implementation, all input tables (i.e. R and S) are created in the main memory. Entries in the tables have the form <id, key>, among which both the id and the key are 32-bit unsigned integers. So the size of each entry is 8 Bytes. We use the open addressing hash table H and denote the size of H as |H| = 2 * |R| initially which means the loading factor is 0.5. We choose the least significant bits (LSB) of the input key of tables R and S as the hash function and a linear probing strategy to handle hash conflicts.
we set |R|<=|S| because we always build hash table from smaller table in general. In the beginning. After the join algorithms, we get a result table T in the main memory. With the setup of the match rate, it can be estimated that |T|≈0.03×|S|. We than use NVIDIA’s Nsight tool to derive a detailed profiling of the GPU based SHJ algorithm.
Algorithmic Engineering
The above profiling results suggest potential directions of optimizations. Among the four components having an impact on the overall performance, the construction of the hash table can be fully parallelized and thus has a limited optimization space.
GPU Memory Management
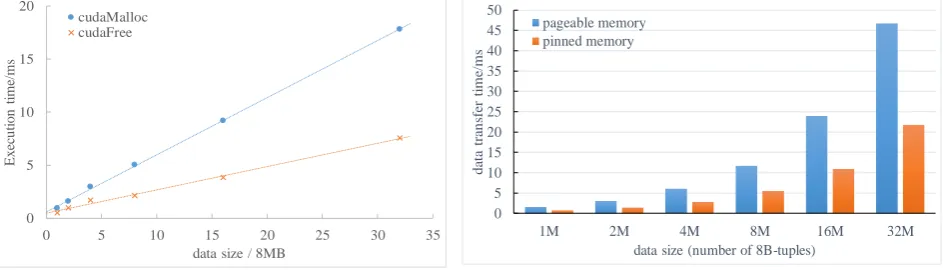
[image:4.595.65.537.308.443.2]The memory for storing the input, output and hash tables has to be allocated and deleted during the join process with standard functions, respectively. Figure 2 shows that such memory management can be expensive in terms of execution time. Figure 3 reports the execution time of the two GPU memory functions with regard to data size. It can be seen that the respective time is approximately proportional to the size of the data.
Figure 3. Execution time of the two GPU memory
functions with regard to data size. Figure 4. Comparison of data transfer times between pageable memory and pinned memory.
Although the memory management can be rather expensive, the respective overhead can be amortized by allocating enough device memory at the start of running the database system and reusing the space for multiple join operations. For each reuse, only a memory clean operation is required and the respective execution time is around 6% of the memory allocation.
Data Transfer
An unavoidable problem of GPU computing is that the datasets have to be transferred between CPU and GPU. For large datasets, the respective overhead can be significant. The optimization space of data transfer is elaborated in this subsection.
Pageable Memory vs. Pinned Memory. Here we compare the data transfer performance in terms of transfer time between pageable memory and pinned memory. From Figure 4, it can be seen that pinned memory offers considerably shorter transfer time. Experimental results prove that the effective bandwidth of pinned memory can be as high as 10.1~11.5GB/s (4.9~5.3GB/s for pageable memory). In fact, the pinned memory enables up to 98% utilization of the effective bandwidth.
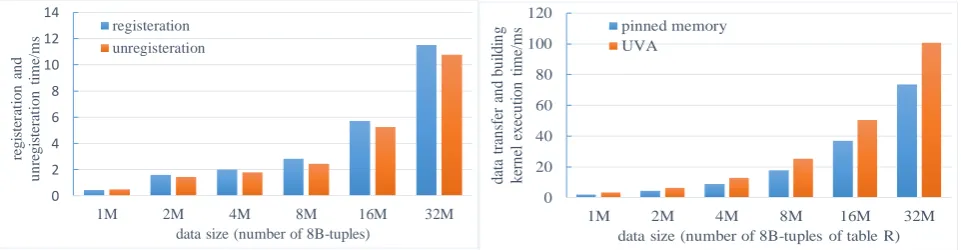
The efficiency of pinned memory actually comes with a cost because the access to them has a fixed overhead, i.e., the registration and unregistration processes. Figure 5 shows the measured cost for these two operations. In fact, frequent registration and unregistration operations may easily neutralize the performance advantage of pinned memory. Such overhead, fortunately, can be amortized in the hash join operation by reserving a large space of pinned memory for main-memory databases during initialization and then reusing the memory space in succeeding operations.
0 5 10 15 20
0 5 10 15 20 25 30 35
E
x
ec
u
ti
o
n
t
im
e/
m
s
data size / 8MB cudaMalloc
cudaFree
0 5 10 15 20 25 30 35 40 45 50
1M 2M 4M 8M 16M 32M
d
at
a
tr
an
sf
er
t
im
e/
m
s
data size (number of 8B-tuples) pageable memory
Figure 5. Comparison of registration and unregistration
times of pinned memory. Figure 6. Comparison of execution times of data transfer and building kernel execution time.
Pinned Memory vs. UVA. UVA is based on the pinned memory and doesn’t need explicit data transfer requests. A shared virtual memory space is provided by CUDA UVA model and mapped the host memory to the device memory. Data transfer only occurs implicitly only when kernel execution need to read or write the data. Therefore, UVA can reduce the data transfer management and accelerate the application development.
Since the UVA mechanism allows in-kernel access to the CPU main memory, we measured the total time of the table R transfer and building kernel to evaluate the performance of pinned memory and UVA. The results are listed in Figure 6. The results suggest that the pinned memory is about 37% faster than UVA. Our results indicated that it does not enable better performance than pinned memory when executing the building kernel partly due to the random patterns of memory accesses. In fact, Negrut et al. [12] suggest that the UVA is preferable when the memory accesses have a high degree of spatial and temporal coherence.
Figure 7. Guidance chart for selecting optimization
strategies for GPU accelerated hash joins. Figure 8. Performance comparison between the baseline and our optimized implementations.
Overall Evaluation
In the previous section, we studied the major tradeoffs involved in the design of efficient GPU implementations of hash joins. Based on the analysis, we propose a design guidance for selecting optimization strategies for GPU accelerated hash joins. Figure 7 illustrates the optimization selection process. It allows developers to choose a series of optimized design decision according to the characteristics of input data. The baseline GPU implementation has the same parameters and algorithmic flow as those proposed by Kaldewey et al. [7]. The results shown in Figure 8 prove that out implementation outperforms the baseline GPU implementation by at least 65% and up to 111% on data size from 2MB to 64MB.
0 2 4 6 8 10 12 14
1M 2M 4M 8M 16M 32M
re g is te ra ti o n a n d u n re g is te ra ti o n t im e/ m s
data size (number of 8B-tuples) registeration unregisteration 0 20 40 60 80 100 120
1M 2M 4M 8M 16M 32M
d at a tr an sf er a n d b u il d in g k er n el e x ec u ti o n t im e/ m s
data size (number of 8B-tuples of table R) pinned memory
UVA
[image:5.595.57.538.71.196.2] [image:5.595.79.537.408.573.2]Start
|R| + |S| >= 1M
Stream num = 1 Stream num = 8
Transfer data and Building kernel
Stop
Allocate pinned memory in the host
Probing kernel and Generate result table
YES
NO
Atomic-write Atomic-free |S| >= 4M
YES
NO
Transfer result from device to host 0 0.5 1 1.5 2 2.5 3 3.5 4 4.5 5
2M 4M 8M 16M 32M 64M
G P U h a sh j o in r u n ti m e [G P U c y c le s/ tu p le ]
|R| + |S| (number of 8B-tuples joined) baseline implementation
Conclusion
In this work, we performed a systematic analysis on GPU accelerated hash join operations. By identifying performance-critical modules and potential spaces for optimization, we developed a set of optimization strategies including data transfer acceleration, streaming to overlap data transfer and kernel execution, and prefix-sum based atomic-free probing. These strategies are integrated into a GPU based testbed for performance evaluation. The experimental results show that our GPU implementation of hash join outperforms the baseline GPU implementation by up to 111% in regard to input data size from 2MB to 64MB.
Acknowledgements
This research is sponsored in part by NSFC Program (No. 61527812), National Science and Technology Major Project (No. 2016ZX01038101), MIIT IT funds (Research and application of TCN key technologies) of China, and The National Key Technology R&D Program (No. 2015BAG14B01-02).
References
[1] K. Bratbergsengen, “Hashing methods and relational algebra operations”, Proceedings of the 10th International Conference on Very Large Data Bases, pp. 323-333, Morgan Kaufmann Publishers Inc., 1984.
[2] C. Balkesen, J. Teubner, G. Alonso, and M. T. Özsu, “Main-memory hash joins on multi-core CPUs: Tuning to the underlying hardware”, In Data Engineering (ICDE), 2013 IEEE 29th International Conference on, pp. 362-373. IEEE, 2013.
[3] M. Kitsuregawa, H. Tanaka, and T. Moto-Oka, “Application of hash to data base machine and its architecture”, New Generation Computing 1, no. 1, pp. 63-74, 1983
[4] H. Zeller, and J. Gray, “An Adaptive Hash Join Algorithm for Multiuser Environments”, In VLDB, vol. 90, pp. 186-197. 1990.
[5] C. Balkesen, G. Alonso, J. Teubner, and M. T. Özsu, “Multi-core, main-memory joins: Sort vs. hash revisited”, Proceedings of the VLDB Endowment 7, no. 1, pp. 85-96. 2013.
[6] B. He, K. Yang, R. Fang, M. Lu, N. K. Govindaraju, Q. Luo, and P. Sander, “Relational joins on graphics processors”, In Proceedings of the 2008 ACM SIGMOD international conference on Management of data, pp. 511-524. ACM, 2008.
[7] T. Kaldewey, G. Lohman, R. Mueller, and P. Volk, “GPU join processing revisited”, In Proceedings of the Eighth International Workshop on Data Management on New Hardware, pp. 55-62. ACM, 2012.
[8] R. J. Halstead, I. Absalyamov, W. A. Najjar, and V. J. Tsotras, “FPGA-based Multithreading for In-Memory Hash Joins”, In CIDR. 2015.
[9] J. He, M. Lu, and B. He, “Revisiting co-processing for hash joins on the coupled cpu-gpu architecture”, Proceedings of the VLDB Endowment 6, no. 10, pp. 889-900. 2013.
[10] Y. Deng, and S. Mu, “Electronic Design Automation with Graphic Processors: A Survey”, Foundations and Trends® in Electronic Design Automation 7, no. 1–2, pp. 1-176. 2013.
[11] https://en.wikipedia.org/wiki/PCI_Express