2016 International Conference on Computer, Mechatronics and Electronic Engineering (CMEE 2016) ISBN: 978-1-60595-406-6
Bayesian Reinforcement Learning for
Multiscale Combinatorial Grouping
Ya-fei LIU
*, Wan-zeng CAI and Xiao-long LIU
College of Computer, National University of Defense Technology, Changsha, China
*Corresponding author
Keywords: Object detection, Bayesian statistical model, Multiscale combinatorial grouping, Region proposal, Geometrical features.
Abstract. Currently, most of the top performing object detectors apply proposal methods to guide the
search for objects, in order to avoiding exhaustive sliding window search. As a classical proposal method, Multiscale Combinatorial Grouping (MCG) [1, 2] performs well on the PASCAL VOC dataset, especially for low proposal number. But when it comes to the autonomous driving object scenarios, the result is poor. In our paper, we applied Bayesian model to the proposals generated by MCG [1, 2] to re-rank the candidate bounding boxes using several geometrical features. We evaluated our method on the challenging KITTI dataset, the results shows that the Bayesian model can greatly improve the performance of MCG [1, 2] for better object detection.
Introduction
In recent years, object detection has become a major research area. Although there exists a variety of approaches, most traditional methods follow the sliding window paradigm [3], in which the search is performed in every candidate image window. Generally speaking, single-scale detection requires
classifying around 104105windows per image, and the number grows by an order of magnitude with the scale of image for multi-scale detection. In some Modern detection datasets [4-6], the search space
increases to 106107 windows per image. As the core classifiers are more and more complex, the object detection performance has increased, meanwhile the cost of the computation time per window is more and more expensive, which heavily limits the speed of calculation.
One way for solve the contradiction is region proposal method. Region proposal method creates a set of candidate bounding boxes of the object location, which can greatly reduce the space we search. There exists a lot of classical proposal methods such as CPMC[7,8], Edgebox[9], SelectiveSearch[10,11], Bing[12] etc. MCG is a common and efficient method, which is proposed by P. Arbelaez in [1, 2]. MCG introduces a fast normalized cuts algorithm for computing multi-scale hierarchical segmentations building on [13].
Despite the widespread use and popularity of detection proposals, there are also some problems we should handle. In this paper, we extract some geometrical features of the bounding boxes generated by MCG, after that a Bayesian probability model is trained using these features, we use the Bayesian probability model to re-rank the candidate bounding boxes, which can be seen as an process of Reinforcement Learning. We test our model on the challenging KITTI benchmark [14]. Extensive experiments prove that the Bayesian model can greatly improve the performance of MCG across all categories under various occlusion and truncation levels.
Related Work
Currently, for the purpose of high quality of the detection, the classifiers always extract complex and expensive cues to recognize specific objects, since what counts for a smaller computation is to use a fewer proposal number and achieve a higher proposal recall. In the recent years, diverse efforts have been made to enhance the performance. Hosang et al. [17] conclude that the current proposal methods can be divided into two categories: grouping methods and window scoring methods, grouping methods obtain the segments of the images, then merge these segments into multiple regions that may correspond to objects.
Van et al. [10] propose the well-known SelectiveSearch, which greedily merges superpixels into larger areas to generate proposals. There are no parameters to learn, but we should manually choose the features and similarity functions. Currently many state-of-the-art object detection algorithms use the SelectiveSearch to generate the proposals, including R-CNN [18] and Fast R-CNN [19]. S. Manén et al. [20] use similar features as SelectiveSearch, the difference is that the superpixels merging process where the probabilities are learned. Chang[21] applies saliency and Objectness [22] to a graphical model to merge superpixels. CPMC [7, 8] directly computes graph cuts with some seeds instead of using initial segmentations, then the order of the segments is ranked using a large pool of features. Geodesic [23] divides an over-segmentation [13] into superpixels and uses classifiers to place seeds for a geodesic distance transform, which is applied to define whether the proposals contain the interested objects.
An alternate strategy of generating proposals is window scoring, which scores every candidate window based on the similarity between the extracted proposals and the ground truth. The more likely the proposal contains the object, the higher its score is. B. Alexe et al. [22] select some salient locations as the initial proposals, furthermore score the proposals based on several features, which include color, location, edges, size, and saliency features. A fast proposal detection method is proposed by M.-M. Cheng et al. [13]. In this method a simple linear classifier is trained on edge cue, which is used in a sliding window manner. Another common window scoring region proposal method is Edge Boxes [9], which builds on the object boundary estimates obtained by structured decision forests using the edges. There are No parameters are learned, so the speed is fast.
P. Arbelaez et al.[1, 2] proposed the MCG algorithm, which in our paper we mainly do research and make improvements on. MCG is a grouping proposal detection method. It introduces a coarse-to-fine approach for computing bottom-up hierarchical image segmentations using gPb-ucm algorithm of [24], the edge of each pair of adjacent regions in the hierarchy is weighted. Then the authors merge the segmentations according to edge strength to form the candidate boxes and rank them with the trained random forest using features. We find that when we use these classical proposal methods on the actual outdoor scenario, the result is poor, probably because of the occlusion, scale and complicated background. Inspired by Bogdan Alexe et al. [25], we apply the Bayesian model to learn the cues of the bounding boxes generated by the MCG. Bayesian model is a statistical model in which we use some low level geometrical features to train the Bayesian classifier. Boxes containing the annotated object are considered as positive examples, the others as negative ones, then we statistic the features of the bounding boxes both positive and negative to get the probability model, in the test stage we re-rank the bounding boxes according the probability that they belong to the positive. The details will be described below.
Approach
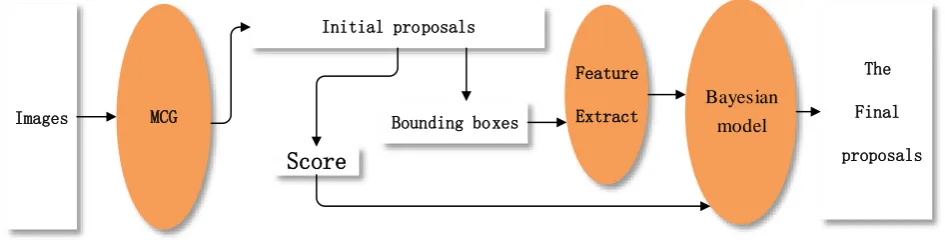
features are obtained so that we can decide the probability of the test proposal belonging to a positive example according to the value of the features.
Initial proposals
MCG
Images Bounding boxes
Score
Feature
Extract Bayesian
model
The
Final
[image:3.595.61.534.117.241.2]proposals
Figure 1. The Bayesian model for Re-ranking.
The Initial Proposals Made by MCG
Proposals generated by MCG for object candidate region is to create a set of hypotheses with a high achievable quality, and then learn to rank them using some low-level features. We put the images of the KITTI dataset into the MCG algorithm, using the Pareto front optimization to reduce the computation, then we get the large number of the candidate regions, then the MCG trains a Random Forest to regress the object overlap with the ground truth using some simple features, the score is obtained by ranking the remained proposals based on Maximum Marginal Relevance measures. We can get the initial proposals which have the coordinates of the bounding boxes and the initial scores, we do some deal with the form of the proposals. Then a vector
x y w h scorel, l, b, b,
is generated torepresent each of the proposal for all images, where the
x yl, l
is coordinate of the upper left corner,
w hb, b
respectively are the box width and box height.Proposal Features
After the initial proposals are generated, we should extract the simple geometrical features to train the Bayesian model. We will introduce four low level geometrical features we use in our paper, they are Aspect Ratio(AR), Distance To The Ground (D2R), Diagonal multiply distance (DMD), Area multiply square of the object distance (AMD).
Aspect Ratio (AR): in the KITTI benchmark, the bounding boxes which cover the objects perfectly always have a range of size, regardless of pedestrians, cars and cyclists. So we believe that the Aspect Ratio is a distinctive cue to classify the positive and negative. The equation is shown as follow:
b b
w AR
h
where the wb,hb has been introduced above.
Distance To The Ground (D2R): the ground is a plane, and the objects what we interest are close to the ground plane, so the bounding boxes far away from the ground is hardly possible to cover the targets, we use it to guide the search as a useful cue. Every pixel in the images has a distance to the ground calculated by:
0 0 0
2 2 2
Dist Ax By Cz D
A B C
(2)
where
x y z0, 0, 0
denotes the coordinate of the pixel, A,B,C are the coefficient of the ground plane
1 1
1 1
1
2 ,
9
c c
i c c
x y
i i x x y y
D R Dist x y
where
2
b c l
w x x and
2
b c l
h
y y express the coordinate of the proposal’s central point.
The following two cues refer to Depth information, which is key difference between RGB images with the actual world. There are plenty of stereo matching algorithms to capture the depth information, in our paper, we use MeshStereo [26] to get the disparity maps from stereo pairs of the KITTI benchmark and the result of every image is saved. Similar to method calculate the D2R, we get the average depth of a 3 3 region to represent the center.
1 1
1 1
1
, 9
c c
i c c
x y
obj i i
x x y y
d depth x y
wheredepth x
i,yi
is the depth value of point
x yi, i
Diagonal multiply distance (DMD): the Diagonal multiply distance can represent the object size in 3D approximately.
2 2
DMD wb hb dobj
where wb2+hb2 is the bounding box diagonal.
Area multiply square of the object distance (AMD): it is also an approximate representation of the real object size.
2
AMDwb hb dobj Where wbhb is the bounding box area.
Bayesian Statistic Model
After extracting the features, we train a Bayesian classifier to combine the cues, and get the distribution histogram of the images for each feature, in the test stage, we make a hypothesis that the test images follow the distribution, the probabilities belonging to the positive for each image are obtained. The probabilities are the new scores to Re-rank the bounding boxes. Giving a proposal, we can use the following equation to get the posterior probability:
0
0
,
( | ) |
obj|F
( | )
f F
c obj bg f F
p obj p f obj
p F obj p obj p
p F p c p f c
(7)Experiments
Evaluation Criterion
To evaluate our proposals, we draw the Bounding box Recall vs number of proposals curves and Bounding box Recall vs IoU curves. An object is regarded recalled when at least one proposal overlaps with the ground truth with IoU above a certain threshold. IoU represents the result of Intersection over Union between the extracted proposals and the ground truth. In our paper, the IoU threshold is set to 0.5, which is commonly used as the criterion to decide whether the proposal is reasonable or not.
Implementation Details
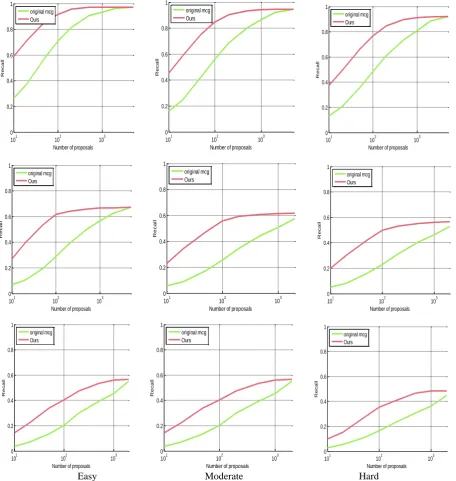
As is shown in Figure 2, the first, second and third rows respectively represent the categories of Car, Pedestrian, Cyclist. The vertical axis indicates the average recall, the horizontal axis indicates the number of the proposals, which is set to the range between 10 and 2000. Our method has enhanced the performance of MCG greatly. The recall increases by more than 20% when the proposal number is 100, regardless of the car, pedestrian, and cyclist.
101 102 103
0 0.2 0.4 0.6 0.8 1
Number of proposals
R e ca ll original mcg Ours
101 102 103
0 0.2 0.4 0.6 0.8 1
Number of proposals
R e ca ll original mcg Ours
101 102 103
0 0.2 0.4 0.6 0.8 1
Number of proposals
R e ca ll original mcg Ours
101 102 103
0 0.2 0.4 0.6 0.8 1
Number of proposals
R e ca ll original mcg Ours
101 102 103
0 0.2 0.4 0.6 0.8 1
Number of proposals
R e ca ll original mcg Ours
101 102 103
0 0.2 0.4 0.6 0.8 1
Number of proposals
R e ca ll original mcg Ours
101 102 103
0 0.2 0.4 0.6 0.8 1
Number of proposals
R e ca ll original mcg Ours
101 102 103
0 0.2 0.4 0.6 0.8 1
Number of proposals
R e ca ll original mcg Ours
101 102 103
0 0.2 0.4 0.6 0.8 1
Number of proposals
R e ca ll original mcg Ours
[image:5.595.69.526.283.765.2]Easy Moderate Hard
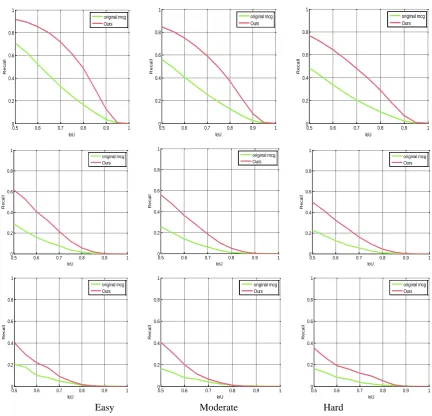
The Figure 3 demonstrates the curves of bounding box recall vs IoU for all categories in easy, moderate and hard levels. In this experiment, we set the number of the proposals to 100.
0.5 0.6 0.7 0.8 0.9 1
0 0.2 0.4 0.6 0.8 1 IoU R e ca ll original mcg Ours
0.5 0.6 0.7 0.8 0.9 1
0 0.2 0.4 0.6 0.8 1 IoU R e ca ll original mcg Ours
0.5 0.6 0.7 0.8 0.9 1
0 0.2 0.4 0.6 0.8 1 IoU R e ca ll original mcg Ours
0.5 0.6 0.7 0.8 0.9 1
0 0.2 0.4 0.6 0.8 1 IoU R e ca ll original mcg Ours
0.5 0.6 0.7 0.8 0.9 1
0 0.2 0.4 0.6 0.8 1 IoU R e ca ll original mcg Ours
0.5 0.6 0.7 0.8 0.9 1
0 0.2 0.4 0.6 0.8 1 IoU R e ca ll original mcg Ours
0.5 0.6 0.7 0.8 0.9 1
0 0.2 0.4 0.6 0.8 1 IoU R e ca ll original mcg Ours
0.5 0.6 0.7 0.8 0.9 1
0 0.2 0.4 0.6 0.8 1 IoU R e ca ll original mcg Ours
0.5 0.6 0.7 0.8 0.9 1
0 0.2 0.4 0.6 0.8 1 IoU R e ca ll original mcg Ours
[image:6.595.78.511.102.518.2]Easy Moderate Hard
Figure 3. Bounding box Recall vs IoU for 100 proposals.
More experiments
0.5 0.55 0.6 0.65 0.7 0.75 0.8 0.85 0.9 0.95 1 0
0.2 0.4 0.6 0.8 1
IoU
R
e
ca
ll
[image:7.595.175.427.79.220.2]20 50 100 500 1000 1500 2000
Figure 4. Bounding box recall vs IoU for different numbers of proposals.
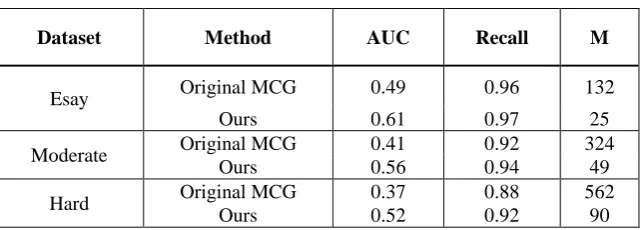
In the end, we also summarize the statistics performance measures for the car of three levels. A comparison analysis is made between the original MCG and our method. The measures are Area Under the Curve (AUC), the best recall and the number of object candidates at recall=0.75 (M), the result is shown below.
Table 1. Comparison the original MCG and our method.
Dataset Method AUC Recall M
Esay Original MCG 0.49 0.96 132 Ours 0.61 0.97 25 Moderate Original MCG 0.41 0.92 324
Ours 0.56 0.94 49 Hard Original MCG 0.37 0.88 562
Ours 0.52 0.92 90
Summary
MCG is a classical proposal method, but it behaves poor in the actual outdoor scenario. Based on this problem, we try our best to improve the performance. In this paper, we use the Bayesian Probability Model to Re-rank the proposal, we extract some simple but powerful features to train our Bayesian model, and obtain the probability distribution based on the features. Finally we use the Bayesian theory to get posterior probability as the new scores. We evaluate the performance of our model on the challenging KITTI benchmark [21]. The Re-ranking bounding boxes we get can achieve a good recall and precision for autonomous driving circumstances. Furthermore, we discover that the original proposals produced by MCG tend to ignore some small objects in the KITTI images, which probably results in the low recall for pedestrian and cyclist, In the future work, more work will be done to overcome the problem, and we will test the performance of the final proposals for detection task with a classifier such as R-CNN, Fast R-CNN etc.
References
[1]Rbelaez P, Ponttuset J, Barron J, et al. Multiscale Combinatorial Grouping[C] IEEE Conference on Computer Vision and Pattern Recognition. 2014:328-335.
[2]Ponttuset J, Arbelaez P, Barron J, et al. Multiscale Combinatorial Grouping for Image Segmentation and Object Proposal Generation[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2016:1-1.
[image:7.595.139.460.330.445.2][4]Deng J, Dong W, Socher R, et al. Imagenet: A large-scale hierarchical image database. Computer Vision and Pattern Recognition, 2009. IEEE Conference on. IEEE, 2009: 248-255.
[5]Everingham M, Eslami S A, Van Gool L, et al. The pascal visual object classes challenge: A retrospective. International Journal of Computer Vision, 2015, 111(1): 98-136.
[6]Lin T-Y, Maire M, Belongie S, et al. Microsoft coco: Common objects in context, in Computer Vision–ECCV 2014. 2014, Springer. p. 740-755.
[7]Carreira J, Sminchisescu C. Constrained parametric min-cuts for automatic object segmentation[J]. IEEE Transactions on Software Engineering, 2010, 23(3):3241-3248.
[8]Carreira J, Sminchisescu C. CPMC: Automatic Object Segmentation Using Constrained Parametric Min-Cuts[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2012, 34(7):1312-28.
[9]Zitnick C L, Dollár P. Edge Boxes: Locating Object Proposals from Edges[M]// Computer Vision – ECCV 2014. 2014:391-405.
[10]Van d S K E A, Uijlings J R R, Gevers T, et al. Segmentation as selective search for object recognition.[C]// IEEE International Conference on Computer Vision, ICCV 2011, Barcelona, Spain, November. 2011:1879-1886.
[11]Uijlings J R R, Sande K E A V D, Gevers T, et al. Selective Search for Object Recognition[J]. International Journal of Computer Vision, 2013, 104(2):154-171.
[12]Cheng M M, Zhang Z, Lin W Y, et al. BING: Binarized Normed Gradients for Objectness Estimation at 300fps[J]. 2014:3286-3293.
[13]Dollár P, Zitnick C L. Fast Edge Detection Using Structured Forests.[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2015, 37(8):1558-70.
[14]A. Geiger, P. Lenz, and R. Urtasun. Are we ready for autonomous driving? the kitti vision benchmark suite. In CVPR, 2012.
[15]Lampert C H, Blaschko M B, Hofmann T. Beyond sliding windows: Object localization by efficient subwindow search[J]. 2008:1-8.
[16]Marchesotti L, Cifarelli C, Csurka G. A framework for visual saliency detection with applications to image thumbnailing[C]// International Conference on Computer Vision IEEE International Conference on Computer Vision. 2009:2232-2239.
[17]Hosang J, Benenson R, Dollar P, et al. What makes for effective detection proposals?[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2015, 38(4):814-830.
[18]Girshick R, Donahue J, Darrell T, et al. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation[J]. Computer Science, 2014:580-587.
[19]Girshick R. Fast R-CNN[J]. Computer Science, 2015.
[20]Manen S, Guillaumin M, Gool L V. Prime Object Proposals with Randomized Prim's Algorithm[C]// IEEE International Conference on Computer Vision. 2013:2536-2543.
[21]Chang K Y, Liu T L, Chen H T, et al. Fusing generic objectness and visual saliency for salient object detection[C]// IEEE International Conference on Computer Vision. 2011:914-921.
[23]Krähenbühl P, Koltun V. Geodesic Object Proposals[C]// European Conference on Computer Vision. 2014:725-739.
[24]Arbelaez P, Maire M, Fowlkes C, et al. Contour detection and hierarchical image segmentation.[J] IEEE Transactions on Pattern Analysis & Machine Intelligence, 2011, 33(5):898-916.
[25]Alexe B, Deselaers T, Ferrari V. What is an object?[C]// Computer Vision and Pattern Recognition (CVPR), 2010 IEEE Conference on. IEEE, 2010:73-80.
[26]Zhang C, Li Z, Cheng Y, et al. Meshstereo: A global stereo model with mesh alignment regularization for view interpolation. Proceedings of the IEEE International Conference on Computer Vision. 2015: 2057-2065.