R E S E A R C H
Open Access
A novel sequence space related to
L
p
defined by Orlicz function with application in
pattern recognition
Mohd Shoaib Khan and QM Danish Lohani
**Correspondence:
[email protected] Department of Mathematics, South Asian University, New Delhi, 110021, India
Abstract
In the field of pattern recognition, clustering groups the data into different clusters on the basis of similarity among them. Many a time, the similarity level between data points is derived through a distance measure; so, a number of clustering techniques reliant on such a measure are developed. Clustering algorithms are modified by employing an appropriate distance measure due to the high versatility of a data set. The distance measure becomes appropriate in clustering algorithm if weights assigned at the components of the distance measure are in concurrence to the problem. In this paper, we propose a new sequence spaceM(φ,p,F) related toLp using an Orlicz function. Many interesting properties of the sequence space
M(φ,p,F) are established by the help of a distance measure, which is also used to modify thek-means clustering algorithm. To show the efficacy of the modified
k-means clustering algorithm over the standardk-means clustering algorithm, we have implemented them for two real-world data set, viz. a two-moon data set and a path-based data set (borrowed from the UCI repository). The clustering accuracy obtained by our proposed clustering algoritm outperformes the standardk-means clustering algorithm.
MSC: 40H05; 46A45
Keywords: clustering; double sequence;k-means clustering; Orlicz function
1 Introduction
Clustering is the process of separating a data set into different groups (clusters) such that objects in the same cluster should be similar to one another but dissimilar in another cluster [–]. It is a procedure to handle unsupervised learning problems appearing in pattern recognition. The major contribution in the field of clustering came due to the pioneering work of MacQueen [] and Bazdek []. Thek-means clustering algorithm was introduced by MacQueen [], which is based on the minimum distance of the points from the center. The variants ofk-means clustering algorithms were proposed to solve different types of pattern recognitions problems (see [–]). The clustering results ofk-means or its variant can be further enhanced by choosing an appropriate distance measure. Therefore, the distance measure has a vital role in the clustering.
Clustering process is usually carried out through theldistance measure [], but, due to
its trajectory, sometimes it fails to offer good results. Suppose that two pointsxandyare
Figure 1 Geometry oflpnorm.
selected on the boundary of the square (casep= ) and letzbe the center (Figure ). Then
lwill fail to distinguishxandy, but these points may be distinguished byl. If the pointsx
andyare on the circumference of the circle, thenlwill fail to distinguish them. Moreover,
thelp(p≥) distance measures are not flexible, so they cannot be modified as per the need of the clustering problem. Hence, clustering results derived through distance-dependent algorithms basically depend upon two properties of a distance measure: () trajectory and () flexibility. Till now, we have not come across to any distance measure that offers a guaranteed good result for every clustering problems. Clustering is carried out by using other variants of thelpdistance measure. The distance measure of the sequence spacelp,q,
≤p,q≤ ∞, introduced by Kellogg [] and further studied by Jovanovic and Rakocevic [], Oscar and Carme [], and Ivana et al. [] offers more flexibility in comparison tolp
due to involvement of additional parameterq. Sargent [] introduced another interest-ing sequence spacesm(ϕ) andn(ϕ) closely related tolp. Some useful extensions ofm(ϕ)
andn(ϕ) sequence spaces were proposed by Tripathy and Sen [], Mursaleen [, ], and Vakeel []. Malkowsky et al. [] defined a matrix mapping into the strong Cesàro sequence space [] and studied the modulus function. Recently, for first time, Khan et al. [] defined a distance measure of the double sequence ofM(φ) andN(φ) to cluster the objects. Moreover, Khan et al. in [, ] defined some more similarity measures by using distance measures of the double sequences in the uncertain environment. Mohi-uddine and Alotaibi applied measures of noncompactness to solve an infinite system of second-order differential equations inp spaces [, ]. The double sequence space is
further studied by Mursaleen and Mohiuddine [], Altay and Başar [, ], Başar and Şever [], and Esi and Hazarika []. Moreover, an Orlicz function and a fuzzy set are also used to define other types of double sequence spaces [, –]. The convergence of difference sequence spaces is discussed in [, , ].
In this paper, we define a new double sequence spaceM(φ,p,F) related toLpusing the following Orlicz function:
M(φ,p,F)
=
x={xmn} ∈:sup
s,t≥
sup
ζ∈Ust
φst
m,n∈ζ
F
|
xmn|
ρ
p
<∞, for someρ>
.
Obviously,M(φ,p,F) is a norm space, and hence the induced distance measure is repre-sented as
dM(φ,p,F)(x,y) =
sup
s,t≥
sup
ζ∈Ust
φst
m,n∈ζ
F
|xmn–ymn|
ρ
pp
.
clustering problem. Besides, defining the distance measure ofM(φ,p,F), we have also studied some of its mathematically established properties. Finally, the distance measure ofM(φ,p,F) is used in thek-means clustering algorithm, which clusters real-world data sets such as two-moon data set and path-based data set. The clustering results obtained by the modified clustering algorithm is compared with thek-means clustering algorithm to show its efficacy.
2 Preliminaries
Throughout the paper,l∞,c, and cdenote the Banach spaces of bounded, convergent,
and null sequences; ω,N, andRdenote the sets of real (ordinary or single) sequences, natural numbers, and real numbers, respectively.
2.1 Orlicz function [34]
A functionF: [,∞)→[,∞) is called an Orlicz function if (i) F() = ,F(x) > forx> , andF(x)→ ∞asx→ ∞; (ii) Fis convex;
(iii) Fis nondecreasing; and
(iv) Fis continuous from the right of .
An Orlicz functionF is said to satisfy -condition for all values ofxif there exists a
constantK> such thatF(x)≤KF(x) for allx≥. The -condition is equivalent to
F(Lx)≤KF(x) for all values ofx> and forL> . An Orlicz functionF can always be represented in the following integral form:
F(x) =
x
η(t)dt,
whereη, known as the kernel ofF, is right-differentiable fort≥,η() = ,η(t) > for
t> ,ηis nondecreasing, andη(t)→ ∞ast→ ∞.
LetCbe the space of finite sets of distinct positive integers. Given any elementσofC. Let
c(σ) be the sequence{cn(σ)}such thatcn(σ) = ifn∈σandcn(σ) = otherwise. Further, let
Cs=
σ∈C: ∞
n=
cn(σ)≤s (cf. [])
be the set of thoseσ whose support has cardinality at mosts, and
=
φ={φn} ∈ω:φ> , φn≥ and
φn n
≤ (n= , , . . .)
,
where ϕn=ϕn–ϕn–.
Forϕ∈, the sequence space, introduced by Sargent [] and known as Sargent’s se-quence space, is defined as follows:
m(φ) =
x={xn} ∈ω:sup
s≥
sup
σ∈Cs
φs
n∈σ
|xn|
<∞
.
is said to beboundedifx∞=supm,n|xmn|<∞. We denote the space of all bounded dou-ble sequences byL∞. Consider a sequencex={xmn} ∈. If for everyε> , there exist n◦=n◦(ε)∈Nand∈Rsuch that
|xmn–|<ε
for allm,n>n◦then we say that the double sequencexisconvergentin thePringheim sense
to the limitand writeP-limxmn=. ByCpwe denote the space of all convergent double sequences in the Pringsheim sense. It is well known that there are such sequences in the spaceCpbut not in the spaceL∞. So, we can consider the spaceCbpof double sequences that are both convergent in the Pringsheim sense and bounded, that is,Cbp=Cp∩L∞. A double sequencex={xmn}is said toconverge regularly to(shortly,r-convergentto) ifxisP-convergent toand the limitsxm:=limnxm,n(m∈N) andxn:=limmxm,n(n∈N)
exist. Note that, in this case, the limitslimmlimnxm,nandlimnlimmxm,nexist and are equal
to theP-limit ofx. Therefore,is called ther-limit ofx.
In general, for any notion of convergenceν, the space of allν-convergent double se-quences will be denoted by Cν, and the limit of a ν-convergent double sequence xby
ν-limm,nxmn, whereν∈ {P,bp,r}.
Başar and Sever [] have introduced the spaceLp ofp-summable double sequences corresponding to the spacelp(p≥) of single sequences as
Lp:=
{xmn} ∈:
m,n
|xmn|p<∞
(≤p<∞)
and examined some properties of the space. Altay and Başar [] have generalized the set of double sequences L∞, Cp, and Cbp etc. by defining L∞(t) = ({xmn} ∈ : supm,n∈N|xmn|tmn <∞), Cp(t) = ({xmn} ∈:P-lim
m,n→∞|xmn–|tmn<∞), and Cbp(t) =
Cp∩L∞, respectively, wheret={tmn}is a sequence of strictly positive realstmn. In the
casetmn= for allm,n∈N,L∞(t),Cp(t), andCbp(t) reduce to the setsL∞,Cp andCbp, respectively.
Now just to have a better idea about other convergences, especially the linear conver-gence, we first consider the isomorphism defined by Zelster [] as
T:→ω,
x→z= (zi) := (xχ–(i)),
()
whereχ:N×N→Nis the bijection defined by
χ(, )= , χ(, )= , χ(, )= , χ(, )=
.. .
χ(,n)= (n– )+ , χ(,n)= (n– )+ , . . . ,
χ(n,n)= (n– )+n, χ(n,n– )=n–n+ , . . . , χ(n, )=n, ..
Let us consider a double sequencex={xmn}and define the sequences={smn}viaxby
smn:=
m,n
i,j
xij (m,n∈N).
For brevity, here and in what follows, we abbreviate the summations ∞k=∞l= and
m k=
n l=by
∞,∞
i,j= and
m,n
i,j=, respectively. Then the pair (x,s) and the sequences={smn}
are called a double series and the sequence of partial sums of a double series, respectively. Letλbe the space of double sequences, converging with respect to some linear conver-gence ruleμ-lim:λ→R. The sum of a double seriesi∞,j=,∞xijwith respect to this rule is defined byμ-i∞,j=,∞xij:=μ-limsmn.
In this paper, we define an analogoue of Sargent’s sequence in the double sequence space. For this, we first suppose thatU is the space whose elements are finite sets of distinct elements ofN×Nobtained byσ×ς, whereσ∈Csandς∈Ctfor eachs,t≥. Therefore any elementζofUmeans (j,k);j∈σ&k∈ςhaving cardinality atmostst, where
sis the cardinality with respect tom, andtis the cardinality with respect ton. Here, the product saycofstmay be same for differnt sets of positive integersk,l, but in that case,Ukl is different fromUst. Given any elementζ ofU, we denote byc(ζ) the sequence{cmn(ζ)} such that
cmn(ζ) =
⎧ ⎨ ⎩
if (m,n)∈ζ,
otherwise.
Further, let
Ust=
ζ∈U: ∞,∞
m,n=
cmn(ζ)≤st
be the set of thoseζ whose support has cardinality at mostst, and let
=
φ={φmn} ∈:φ> , φmn, φmn, φmn≥ and
φmn mn
,
φmn mn
,
φmn mn
≤ (m,n= , , . . .)
,
where ϕmn=ϕmn–ϕm–n, ϕmn=ϕmn–ϕmn–, ϕmn=ϕmn–ϕm–n–.
Forϕ∈, we define the sequence space
M(φ,F) =
x={xmn} ∈:sup
s,t≥
sup
ζ∈Ust
φst
m,n∈ζ F
|
xmn|
ρ
<∞, for someρ>
.
Throughout the paper,m,n∈ζ means
m∈σ
The spacesM(φ,F),Lp, andL∞can be extended toM(φ,p,F),Lp(F), andL∞(F) as follows:
M(φ,p,F)
=
x={xmn} ∈:sup
s,t≥
sup
ζ∈Ust
φst
m,n∈ζ
F | xmn| ρ p
<∞, for someρ>
,
Lp(F) =
{xmn} ∈:
m,n
F
|xmn|
ρ
p
<∞, for someρ>
(≤p<∞),
L∞(F) =
{xmn} ∈:sup
m,nF
|
xmn|
ρ
<∞, for someρ>
.
Now, if we take the cardinalitytwith respect tonas , thenM(φ,F) reduce tom(φ,F), andM(φ,p,F) tom(φ,p,F). Here, without further discussingM(ϕ,F), we immediately defineM(φ,p,F) so as not to deviate from our main goal to show thatM(φ,p,F) is a class of new double sequences lying betweenLp(F) andL∞(F). We then further prove certain conditions under whichM(φ,p,F) is same as that ofLp(F) andL∞(F). We can easily see that all results in Section hold forM(φ,F), which is a particular case ofM(φ,p,F) withp= .
3 Some interesting results related toM(
φ
,p,F)Theorem . The sequence spaceM(φ,p,F)is a linear space overR.
Proof Letx,y∈M(φ,p,F) andλ,μ∈R. Then there exists positive numbersρ andρ
such that
sup
s,t≥
sup
ζ∈Ust
φst
m,n∈ζ
F | xmn| ρ p <∞ and sup
s,t≥
sup
ζ∈Ust
φst
m,n∈ζ
F | xmn| ρ p
<∞.
Letρ=max(|λ|ρ, |μ|ρ).
() <p< . Using the well-known inequality|a+b|p≤ |a|p+|b|pfor <p< and the
convexity of Orlicz functions, we have
sup
s,t≥
sup
ζ∈Ust
φst
m,n∈ζ
F
|
λxmn+μymn|
ρ
p
≤sup
s,t≥
sup
ζ∈Ust
φst
m,n∈ζ
F
|
λxmn|
ρ
p
+sup
s,t≥
sup
ζ∈Ust
φst
m,n∈ζ
F
|
μymn|
ρ
p
≤sup
s,t≥
sup
ζ∈Ust
φst
m,n∈ζ
F
|
λxmn|
ρ
p
+sup
s,t≥
sup
ζ∈Ust
Ust
m,n∈ζ
F
|
μymn|
ρ
p
<∞,
() ≤p< +∞. It is easy to see that for alla,b∈R,|a+b|p≤p(|a|p+|b|p) andFis
convex, so that, for alls,t≥,ζ∈Ust,
sup
s,t≥
sup
ζ∈Ust
φst
m,n∈ζ
F
|λxmn+μymn|
ρ
p
≤sup
s,t≥
sup
ζ∈Ust
φst
m,n∈ζ
p
F
|
λxmn|
ρ
p
+sup
s,t≥
sup
ζ∈Ust
φst
m,n∈ζ
p
F
|
μymn|
ρ
p
≤sup
s,t≥
sup
ζ∈Ust
φst
m,n∈ζ
p+ F
|xmn|
ρ
p
+sup
s,t≥
sup
ζ∈Ust
φst
m,n∈ζ
p+ F
|
ymn|
ρ
p
<∞.
This shows thatx,y∈M(φ,p,F)⇒λx+μy∈M(φ,p,F).
Remark . The distance measure between two sequencesxnandyninduced byCesqp(F)
can be represented as
dCesqp(F)(x,y) =
∞ n= Qn n i=
qifi|xi–yi|
pp
.
Theorem . M(φ,p,F)⊆M(ψ,p,F)if and only ifsups,t≥(φst
ψst) <∞.
Proof Letx∈M(φ,p,F). Then
sup
s,t≥
sup
ζ∈Ust
φst
m,n∈ζ
F | xmn| ρ p
<∞ for someρ> .
Suppose thatsups,t≥(φst
ψst) <∞. Thenϕst≤kψstfor some positive numberkand for all s,t∈N, so
ψst ≤ k
ϕst for alls,t∈N. Therefore we have
ψst
m,n∈ζ
F | xmn| ρ p ≤ k φst
m,n∈ζ
F
|xmn|
ρ
p
for eachs,t∈Nand for someρ> .
Now taking the supremum on both sides we get
sup
s,t≥
sup
ζ∈Ust
ψst
m,n∈ζ
F | xmn| ρ p
≤ksup
s,t≥
sup
ζ∈Ust
φst
m,n∈ζ
F | xmn| ρ p
Therefore we have
sup
s,t≥
sup
ζ∈Ust
ψst
m,n∈ζ
F
|xmn|
ρ
p
<∞ and for someρ> .
Hencex∈M(ψ,p,F).
Conversely, letM(φ,p,F)⊆M(ψ,p,F) and suppose thatsups,t≥(φst
ψst) <∞. Then there
exist increasing sequences (si) and (ti) of natural numbers such thatlim(φst
ψst) =∞. Now for
everyb∈R+, the set of positive real numbers, there existi
◦,j◦∈Nsuch that ψϕsitisiti >bfor
allsi≥i◦andti≥j◦. Henceψsiti > b
ϕsiti, so that, for someρ> ,
ψsiti
m,n∈ζ
F
|xmn|
ρ
p
> b φsiti
m,n∈ζ
F
|xmn|
ρ
p
for allsi≥i◦andti≥j◦. Now taking the supremum oversi≥i◦,ti≥j◦, andζ ∈Ust, we get
sup
si≥i◦,ti≥j◦
sup
ζ∈Ust
ψsiti
m,n∈ζ
F | xmn| ρ p
>b sup
si≥i◦,ti≥j◦
sup
ζ∈Ust
φsiti
m,n∈ζ
F | xmn| ρ p . ()
Since () holds for allb∈R+(we may takebsufficiently large), we have
sup
si≥i◦,ti≥j◦
sup
ζ∈Ust
ψsiti
m,n∈ζ
F
|xmn|
ρ
p
=∞
whenx∈M(ϕ,p,F) with <sups
i≥i◦,ti≥j◦supζ∈Ust
φsiti
m,n∈ζ(F(
|xmn|
ρ )) p<∞.
Therefore x ∈/ M(ψ,p,F). This contradicts to M(φ,p,F) ⊆ M(ψ,p,F). Hence sups,t≥(φst
ψst) <∞.
Corollary . M(φ,p,F) =M(ψ,p,F)if and only ifsups,t≥(ηst) <∞andsups,t≥(ηst–) <
∞,whereηst= (ψφstst)for all s,t∈N.
Corollary . M(φ)⊆M(φ,p,F).
Proof Ifp= andF(x) =x, thenM(φ) =M(φ,p,F). Also,M(φ)⊆M(φ,p,F).
Theorem . The inclusionsLp(F)⊆M(φ,p,F)⊆L∞(F)M(φ,p,F)hold.
Proof Letx∈Lp(F). Then, for someρ> , we have∞i,j=,,∞(F(|xmn|
ρ ))
p<∞. Since (ϕ st) is
nondecreasing with respect tos,t≥, for someρ> , we have
φst
m,n∈ζ
F | xmn| ρ p ≤ φ
m,n∈ζ
F | xmn| ρ p ≤ φ ∞,∞
i,j=,
F
|
xi,j|
ρ
p
<∞.
Hencesups,t≥supζ∈Ust φ
st
m,n∈ζ(F(| xmn|
ThusLp⊆M(φ,p,F). Now letx∈M(φ,p,F). Then for someρ> , we have
sup
s,t≥
sup
ζ∈Ust
φst
m,n∈ζ
F | xmn| ρ p
<∞,
sup
m,n≥
φ
m,n∈ζ
F
|xmn|
ρ
p
<∞.
⇒F(|xmn|
ρ )≤(Aφ)
p for someA> and allm,n∈N. Thusx∈L∞(F).
Theorem . LetF,F,Fbe Orlicz functions satisfying -condition.Then
() M(φ,p,F)⊆M(φ,p,F◦F),
() M(φ,p,F)∩M(φ,p,F) =M(φ,p,F+F).
Proof () Letx∈M(φ,p,F). Then there existsρ> such that
sup
s,t≥
sup
ζ∈Ust
φst
m,n∈ζ
F
|xmn|
ρ
p
<∞.
Let <ε< andδwith <δ< be such thatF(t) <ε, <t≤δ. Puttmn=F(|xmnρ |) and
for anyζ ∈Us, consider
m,n∈ζ
F(tmn)
p
=
F(tmn)
p
+
F(tmn)
p
,
where the first sum is overtmn≤δ, and the second is overtmn>δ. From the remark we
have
F(tmn)
p
≤F()p
tpmn≤F()p
tmnp , ()
and fortmn>δ, we use the fact that
tmn<tmn δ < +
tmn
δ .
SinceFis nondecreasing and convex, we have
F(tmn)≤F
+tmn δ
< F() +
F
tmn
δ
.
SinceFsatisfies -condition, we have
F(tmn) < k
tmn
δ F() + k
tmn
δ F() =k
tmn
δ F().
Hence
F(tmn)
p
<
ktmn
δ F()
p
Therefore
F(tmn)
≤max
,
kF
() δ
pp
m,n∈ζ
tmnp . ()
By () and () we haveM(φ,p,F)⊆M(φ,p,F◦F).
() The proof follows from the inequality
sup
s,t≥
sup
ζ∈Ust
φst m,n∈ζ
(F+F)
|xmn|
ρ
pp
≤sup
s,t≥
sup
ζ∈Ust
φst m,n∈ζ
F
|
xmn|
ρ
pp
+sup
s,t≥
sup
ζ∈Ust
φst m,n∈ζ
F
|
xmn|
ρ
pp
<∞.
Theorem . TheM(φ,p,F)satisfy the following relations: () M(φ,p,F) =Lp(F)if and only ifsups,t≥(ϕst) <∞,
() M(φ,p,F) =L∞(F)if and only ifsups,t≥(φstst) <∞.
Proof () If we takeϕst= for alls,t∈N, then we haveM(φ,p,F) =Lp(F).
() By Theorem . we easily get that M(φ,p,F) = L∞(F) if and only if sups,t≥(φst
st) <∞.
3.1 k-means algorithm forM(
φ
,p,F) distance measureLetX={x,x, . . . ,xn}be a given data set. Then the proposed clustering algoritm works as
follows.
Step-: Select firstkdata points as the cluster centerxk={x,x, . . . ,xk}(wherekis the
number of clusters).
Step-: Compute the distance between each data point and cluster center through
M(φ,p,F)distance measure.
Step-: Put the data point into that cluster whoseM(φ,p,F)distance with its center is minimal.
Step-: Redefine cluster centers for newly evolved clusters due to the above steps; the new cluster centers are computed asci=ki
ki
j=xi, wherekiis the number of
points in theith cluster.
Step-: Repeat Step to Step until the difference between two consecutive cluster centers becomes less than a desired small number.
3.2 Clustering by using the inducedM(
φ
,p,F) distance measureFigure 2 Two-moon data set.
(a) Clustering byl
(b) Clustering byM(φ,p,F)
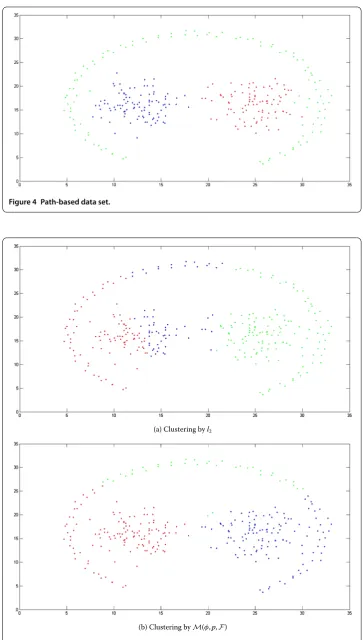
Figure 4 Path-based data set.
(a) Clustering byl
(b) Clustering byM(φ,p,F)
clustering is %(Figure (b)). Moreover, in the case of a path-based data set, we take ϕ=n,∀m,n,p= , andF(x) =|x|. The clustering accuracy of the path-based data set by using thek-mean clustering algorithm is %, whereas by using the proposed modefied
k-means clustering algorithm it is %as shown in Figures (a) and (b), respectively.
4 Conclusions
The parametersφ,p,F involved in the sequence spaceM(φ,p,F) give additional three degrees of freedom to its induced distance measure. Therefore, it is more flexible in com-parison to thelpor weightedlpdistance measure. The flexibility in the distance measure can be judiciously used in the clustering of the real-world data sets. We have proposed only a modifiedk-means clustering algorithm; in the similar fashion, other distance-based clus-tering algorithms can also be modified. So, improvement in many clusclus-tering algorithms is possible due to a distance measure ofM(φ,p,F). We have shown the efficacy of an
M(φ,p,F)-basedk-means clustering algorithm over thel-basedk-means clustering
al-gorithm on the basis of better clustering accuracy obtained for a two-moon data set and path-based data set.
Competing interests
The authors declare that they have no competing interests.
Authors’ contributions
Both authors of the manuscript have read and agreed to its content and are accountable for all aspects of the accuracy and integrity of the manuscript.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Received: 25 May 2017 Accepted: 11 October 2017 References
1. MacQueen, J: Some methods for classification and analysis of multivariate observations. In: Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, vol. 1, pp. 281-297 (1967)
2. Bezdek, JC: A review of probabilistic, fuzzy, and neural models for pattern recognition. J. Intell. Fuzzy Syst.1(1), 1-25 (1993)
3. Khan, VA, Lohani, QM: New lacunary strong convergence difference sequence spaces defined by sequence of moduli. Kyungpook Math. J.46(4), 591-595 (2006)
4. Jain, AK: Data clustering: 50 years beyondk-means. Pattern Recognit. Lett.31(8), 651-666 (2010)
5. Cheng, MY, Huang, KY, Chen, HM: K-means particle swarm optimization with embedded chaotic search for solving multidimensional problems. Appl. Math. Comput.219(6), 3091-3099 (2012)
6. Yao, H, Duan, Q, Li, D, Wang, J: An improvedk-means clustering algorithm for fish image segmentation. Math. Comput. Model.58(3), 790-798 (2013)
7. Cap, M, Prez, A, Lozano, JA: An efficient approximation to thek-means clustering for massive data. Knowl.-Based Syst. 117, 56-69 (2017)
8. Güngör, Z, Ünler, A: K-harmonic means data clustering with simulated annealing heuristic. Appl. Math. Comput. 184(2), 199-209 (2007)
9. Kellogg, CN: An extension of the Hausdorff-Young theorem. Mich. Math. J.18(2), 121-127 (1971)
10. Jovanovi´c, I, Rakoˇcevi´c, V: Multipliers of mixed-norm sequence spaces and measures of noncompactness. Publ. Inst. Math.56, 61-68 (1994)
11. Blasco, O, Zaragoza-Berzosa, C: Multipliers on generalized mixed norm sequence spaces. Abstr. Appl. Anal.2014, Article ID 983273 (2014)
12. Dolovi´c, I, Malkowsky, E, Petkovi´c, K: New approach to some results related to mixed norm sequence spaces. Filomat 30(1), 83-88 (2016)
13. Sargent, W: Some sequence spaces related to thelpspaces. J. Lond. Math. Soc.1(2), 161-171 (1960)
14. Tripathy, BC, Sen, M: On a new class of sequences related to the spacelp. Tamkang J. Math.33(2), 167-171 (2002)
15. Mursaleen, M: Some geometric properties of a sequence space related top. Bull. Aust. Math. Soc.67(2), 343-347
(2003)
16. Mursaleen, M: Application of measure of noncompactness to infinite system of differential equations. Can. Math. Bull. 56, 388-394 (2013)
17. Khan, VA: A new type of difference sequence spaces. Appl. Sci.12, 102-108 (2010)
19. Djolovi´c, I, Malkowsky, E: On matrix mappings into some strong Cesaro sequence spaces. Appl. Math. Comput. 218(10), 6155-6163 (2012)
20. Khan, MS, Alamri, BAS, Mursaleen, M, Lohani, QMD: Sequence spacesM(ϕ) andN(ϕ) with application in clustering. J. Inequal. Appl.2017(1), 63 (2017)
21. Mohiuddine, SA, Srivastava, HM, Alotaibi, A: Application of measures of noncompactness to the infinite system of second-order differential equations inpspaces. Adv. Differ. Equ.2016(1), 317 (2016)
22. Alotaibi, A, Mursaleen, M, Mohiuddine, SA: Application of measures of noncompactness to infinite system of linear equations in sequence spaces. Bull. Iran. Math. Soc.41(2), 519-527 (2015)
23. Mursaleen, M, Mohiuddine, SA: Convergence Methods for Double Sequences and Applications. Springer, Berlin (2014)
24. Altay, B: On some double Cesàro sequence spaces. Filomat28(7), 1417-1424 (2015)
25. Altay, B, Ba¸sar, F: Some new spaces of double sequences. J. Math. Anal. Appl.309(1), 70-90 (2005) 26. Basar, F, Sever, Y: The spaceLqof double sequences. Math. J. Okayama Univ.51, 149-157 (2009)
27. Esi, A, Hazarika, B: Some double sequence spaces of interval numbers defined by Orlicz function. J. Egypt. Math. Soc. 22(3), 424-427 (2014)
28. Savas, E, Patterson, RF: On some double almost lacunary sequence spaces defined by Orlicz functions. Filomat19, 35-44 (2005)
29. Mohiuddine, SA, Raj, K, Alotaibi, A: Some paranormed double difference sequence spaces for Orlicz functions and bounded-regular matrices. Abstr. Appl. Anal.2014, Article ID 419064 (2014)
30. Hazarika, B, Kumar, V, Lafuerza-Guillén, B: Generalized ideal convergence in intuitionistic fuzzy normed linear spaces. Filomat27(5), 811-820 (2013)
31. Talo, O, Basar, F: Certain spaces of sequences of fuzzy numbers defined by a modulus function. Demonstr. Math. 43(1), 139-149 (2010)
32. Mohiuddine, SA, Hazarika, B: Some classes of ideal convergent sequences and generalized difference matrix operator. Filomat31(6), 1827-1834 (2017)
33. Mursaleen, M, Sharma, SK, Mohiuddine, SA, Kılıçman, A: New difference sequence spaces defined by Musielak-Orlicz function. Abstr. Appl. Anal.2014, Article ID 691632 (2014)
34. Nakano, H: Concave modulars. J. Math. Soc. Jpn.5, 29-49 (1953)
35. Zeltser, M: Investigation of Double Sequence Spaces by Soft and Hard Analitical Methods. Dissertationes Mathematicae Universitatis Tartuensis, vol. 25, Tartu University Press, Univ. of Tartu, Faculty of Mathematics and Computer Science, Tartu (2001)
36. Jain, AK, Law, MHC: Data clustering: a users dilemma. In: Proceedings of the First International Conference on Pattern Recognition and Machine Intelligence (2005)
37. Chang, H, Yeung, D-Y: Robust path-based spectral clustering. Pattern Recognit.41(1), 191-203 (2008)
38. Khan, MS, Lohani, QMD: A similarity measure for atanassov intuitionistic fuzzy sets and its application to clustering. In: Computational Intelligence (IWCI), International Workshop on. IEEE, Dhaka (2016)