2018 International Conference on Communication, Network and Artificial Intelligence (CNAI 2018) ISBN: 978-1-60595-065-5
Study on the Specified Target Traceability in Multi-camera
Cheng-feng ZHU
1,2, Dong YIN
1,2,*, Jin-wen DING
1,3,*, An Wang
1,
Yu-hao LUO
1,2, Zhi-peng ZHOU
1,2and Ming-yue YUAN
1,21School of Information Science Technology, USTC, Hefei, Anhui 230027, China
2Key Laboratory of Electromagnetic Space Information of CAS, Hefei, Anhui 230027, China
3Department of Materials Science and Engineering, USTC, Hefei, Anhui 230026, China
*Corresponding author
Keywords: Surveillance video, Target tracking, Neural network, Mean-shift.
Abstract. In view of the tracing of the pedestrian history trajectory, a counter-tracking method based on multi-camera is proposed. Firstly, a basic database including many attributes such as video frame rate and perspective relationship is established. Secondly, all of the cameras in the environment are calibrated and the relationships among them are constructed. Various features obtained by ResNet neural network are used to improve the accuracy of recalibration for the processed camera data. Finally, using the mean-shift algorithm realizes target tracking and traceability in reverse-time. Compared with ASMS, ColorKCF and Staple algorithm, experiments in the paper show that the proposed method has some advantages in accuracy and loss rate of target tracking, which is effective in practical application.
Introduction
Recently, as non-traditional security method becoming a topic which people pay more attention to, researches about this spring up. When something terrible like terrorism happens, not only tracking the terrorists should we do, but also tracking what they do before the incident. With the development of the computer visual technology, solving such problem becomes more possible than before.
Tracking means to detect the object in the first frame and then with the help of computer visual we could find the object correctly in next frames. The difficulties that will be met in the task are move-then-stop [1], occlusion, illumination variation, deformation, moving background, background clutter, fast motion and so on. At the beginning, the research is based on tracking single object, but nowadays multi-object tracking is becoming a new topic [2]. Tracking can be divided into two main parts by the technology they use: Correlation Filter (CF) and Deep ConveNet (DC) based. CF can solve the task faster [2], while DC based can get higher score in accuracy and robustness [3]. Recently, increasing numbers of tracking methods using DC are developed and gotten great effects on tracking [4].
When a moving object exits a camera and enters another, how to find it continuously is an important question that many people pay much attention to. The question has some similarities with image retrieval. Although the object is a person, the technology of face recognition can do nothing to solve the problem, because the features of the person are difficult to extract when occlusion happened. Color is a feature which can play an important role, but illumination variation or background clutter may cause a worse result. In this way, extracting more effective features [5] and finding a suitable space [6] become the two effective ways to solve the problem.
Related Technologies
Object Detection
DPM (Deformable Parts Model) [7] algorithm is seem as an algorithm which uses HOG feature. It retains cell array and abandon block array after extracting HOG features, then normalizes them. When calculating gradient for an 8 × 8 cell array, it can get 4 × (9+18) = 108-dimensional features. They are so high that it will cost too much time. For the 4 × 9 = 36-dimensional features which can be seen as a 4 × 9 matrix, we should accumulate the sum of each rows and columns so that only 13-dimensional features will be retained. Then for the 4 × 18 matrix we could accumulate the sum of each column. To deal with the 31-dimensional features, we could get similar result without wasting too much time.
These features will be put into a root filter and some part filters. The root filter is used to describe the outline of the object and the part filters which using symmetrical structure to reduce complexity can tell the details of special parts.
0 0 0
0,0
0 0
,0
0 0
1
, , l , n i l 2 , i
i
score x y l R x y D x y b
(1)The score of each object can be gotten according formula (1). (x0,y0,l0) is used to describe the
location and size of the aim point. R0,l0
x y0, 0
is the score gotten from the root filter and
0
, 0 0
1
2 ,
n
i l i
i
D x y
is from the part filter i. b is the offset coefficient.
, , max , , , ,
i l dx dy i l i
D x y R xdx ydy d dx dy
(2)
According formula (2), we could get the score of part filter. (x, y) means the perfect location of
each model, Ri l,
xdx y, dy
is the original score, di is loss factor and
dx dy,
shows thedistance between fact and predict. So, di
dx dy,
means the loss score of each object.Object Match
[image:2.612.257.363.505.621.2]Object matching is an important part of target tracking. In this part, we try to use Convolution neural network (CNN) to extract enough features.
Figure 1. The structure of ResNet.
The structure of ResNet [8] is show in Figure 1. ResNet can create a deep net with low complexity, and has more features and less time.
Object Track
to the object but also to the background. With the help of the features which are extracted from background, the accuracy of this type will higher than the first one. But they will cost much time [12].
Our Algorithm
There are large numbers of cameras in public place, so when we want to review the accident, the challenge that we may meet is how to deal with the large information effectively. In this paper, an application framework is proposed. It will be divided into 5 parts as Figure 2 shown, they are Input, Pre-treatment, Re-identification, Tracking and Output. Input and Output are simple, so we will introduce the main three parts in the following.
Se le ct v id eo Se le ct t im e Vi d eo s Se le ct t ar ge t Selected? Exit? Y N Video compression Camera number and time Camera number and time Y Result DMP algorithm ResNet Matching candidates ta rg et Mean‐shift tracking
Pre-treatment Re-identification Tracking
Input Output
[image:3.612.173.436.202.278.2]N
Figure 2. The framework of tracking in multi-camera.
Pre-treatment
Table 1. Structure of database.
Camera number
Start
time Duration
Frame per
second Perspective
Connect among cameras Camera
number
Connected
area Non-overlapping area
What we should do at first is to build a database as Table.1. When we localize the videos' time successfully at the first time, it may save a lot of time when the target enters another camera and reduces the risk of target loss a lot.
, j
f
i j
out in i j
t t
(3)j in
t is the time that the target exits the camera j, j is the target’s average speed in camera j,
,
fi j * is a function saved in the database to assume the least time that the target may use in the
non-overlapping area. Then we could try to re-identify the target in camera i at time i
out
t .
Secondly, when tracking the target in a video which we get from the camera, the size may change drastically which may lead to the tracking rectangle too large or too small. If we want to design a long-term tracking algorithm, it may increase the risk of target loss. For it, we need determine the relationship between the location and size in each camera. Then we can remark the target when the rectangle is too large or too small and track the target even longer.
Re-identification
The algorithm in this paper is a long time tracking algorithm in different cameras. In this case when the target enters another camera, we may remark the target automatically.
As what is shown above, there are two ways to find the target correctly. One is to extract as more features as possible, the other is to find an effective matching plan.
2048
2
1
( ) - D , S ,
0 S ,
k k i l l s s
k q
s s
p q d p q p q
score p q
[image:3.612.86.523.349.390.2]k
p is the feature which is extracted from the target by ResNet, while qk is that from a candidate.
i
d is the loss parameter in camera i, D
p ql, l
represents the distance between the place thecandidate is in and the place the target should be in. S
p qs, s
shows the difference between thecandidate's size and his predicted size which is assuming according to his place.
Tracking
The challenges for tracking are hard. It is impossible to track the target in long time just with the help of a low complexity algorithm. So what we do is trying to remark the target periodically in some special area where we can find many people or some irregular people frequently in the past. In this case we could find the target in near area instead of the whole area of the camera which may waste too much time. What’s more, when we find the target become a little large or a little small which means there is a risk to lose the target in next frame, so in this case we also should remark the target. This time as we are sure that the target is not loss, so the area even smaller than the first case. In addition,
i
d may change to avoid the effect from a similar person. Figure 3 is the flowchart of tracking
algorithm.
Special space?
t mod f=0?
Regular size?
Tracking Re‐identify Place in the frame Exit?
Y
Y
Y N
N
N Y
N
[image:4.612.184.428.283.340.2]Place in Last frame
Figure 3. The flow chart of tracking.
Experiments and Analysis
The experiment platform is CPU: i7, Graphics card: GTX960, RAM: 8G, OS: Windows 7, programming software: Visual Studio 2013. Environment parameters: 18 cameras in two layers. Tracking targets: 6 people. Images: 8000 frames.
Compared Method
In this paper we select ASMS, ColorKCF, Staple to compare, which are famous real-time tracking
algorithms. When we want to track the target through a video with N frames, we should know in
each frame where the target is if he exits. In this case we call this place as TP and the size of the
target as TParea. What’s more, we call the place what we can get from an algorithm as PP and the size
as PParea. In addition we support another two parameters SP and OP:
SPTPPP, OPTPPP (5)
Here, we call their size as SParea and OParea. The scale between OParea and SParea is range from 0
to 1, which means target may be loss or continued.
op op
N score
N
(6)
In the formula (6), Nop is the number of the frames where the scale between OTarea and STarea is
above 0.5. In some papers, they use Nnl which is the number of the frames when the target is not loss
instead of N. In that case, an algorithm which just can track for a short time may get a higher score
than a long-time algorithm. An algorithm will achieve a low score when PPis too large or too small.
accuracy a
N score
N
, completion
c
N score
N
(7)
where Na is the number of the frames where the scale between OParea and PParea is above 0.5 and
c
N is between OParea and TParea.
Simultaneously, we use ID Sw to count the times of target loss. We will remark the target only when the target exits one camera and enters another, and the times of marking will be shown in mt.
[image:5.612.74.539.201.562.2]Experiment Result
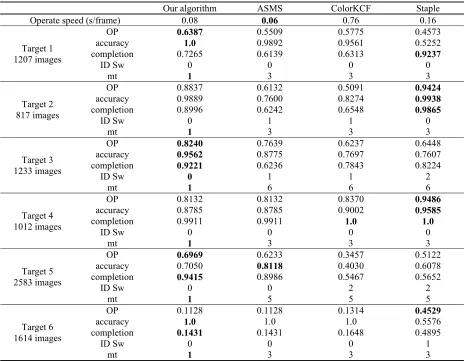
Table 2. Comparison of different algorithms.
Our algorithm ASMS ColorKCF Staple Operate speed (s/frame) 0.08 0.06 0.76 0.16
Target 1 1207 images
OP 0.6387 0.5509 0.5775 0.4573 accuracy 1.0 0.9892 0.9561 0.5252 completion 0.7265 0.6139 0.6313 0.9237
ID Sw 0 0 0 0
mt 1 3 3 3
Target 2 817 images
OP 0.8837 0.6132 0.5091 0.9424 accuracy 0.9889 0.7600 0.8274 0.9938 completion 0.8996 0.6242 0.6548 0.9865
ID Sw 0 1 1 0
mt 1 3 3 3
Target 3 1233 images
OP 0.8240 0.7639 0.6237 0.6448 accuracy 0.9562 0.8775 0.7697 0.7607 completion 0.9221 0.6236 0.7843 0.8224
ID Sw 0 1 1 2
mt 1 6 6 6
Target 4 1012 images
OP 0.8132 0.8132 0.8370 0.9486 accuracy 0.8785 0.8785 0.9002 0.9585 completion 0.9911 0.9911 1.0 1.0
ID Sw 0 0 0 0
mt 1 3 3 3
Target 5 2583 images
OP 0.6969 0.6233 0.3457 0.5122 accuracy 0.7050 0.8118 0.4030 0.6078 completion 0.9415 0.8986 0.5467 0.5652
ID Sw 0 0 2 2
mt 1 5 5 5
Target 6 1614 images
OP 0.1128 0.1128 0.1314 0.4529
accuracy 1.0 1.0 1.0 0.5576
completion 0.1431 0.1431 0.1648 0.4895
ID Sw 0 0 0 1
mt 1 3 3 3
Demonstration in Application Scene
[image:6.612.88.524.83.146.2](a) (b) (c) (d) (e)
Figure 4. Application demonstration of our algorithm.
When we select the target at 2017-06-22 16:01:52 from camera 17, we would be told that she entered camera17 at 16:01:51 (Figure 4 (a)). Then camera 16 would tell us what she did for 21s since 16:01:30 (Figure 4 (b)). We would found a record lasting 33s in camera 3 since 16:00:57 (Figure 4 (c)).Then we found camera 16 also recorded her activity from 16:00:54 to 16:00:27 (Figure 4 (d)). Finally, camera 4 would tell us what she did from 15:59:54 to 15:59:30 (Figure 4 (e)).
Conclusions
With a large number of cameras installed, video image processing is widely used. In this paper, in view of the requirement of automatic viewing of pedestrian history, a method of tracing the pedestrian path in multiple cameras is proposed, which effectively improves the ability of automatic video retrieval. Compared with the current main tracking algorithms, the experimental results show that our proposed method has some advantages in pedestrian tracking and can be used in multi-camera monitoring environment. Further improving the reverse tracking rate is the next work of this paper.
Acknowledgement
This work is supported by the National Natural Science Foundation of China (NSFC) under Grant No.61671423 and Grant No.61271403.
References
[1]Y.F. Jiang, H. Shin, J. Ju, et al. "Online pedestrian tracking with multi-stage re-identification,"
2017 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 2017, pp. 1-6
[2]Y.C. Lim and M. Kang, "Multi-Pedestrian detection and tracking using unified multi-channel
features," 2017 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 2017, pp. 1-5.
[3]Danelljan, M., Robinson, A., Shahbaz Khan, F., et al..: Beyond correlation filters: Learning
continuous convolution operators for visual tracking. In: ECCV. (2016)
[4]Kristan M. et al. (2016) The Visual Object Tracking VOT2016 Challenge Results. In: Hua G.,
Jégou H. (eds) Computer Vision – ECCV 2016 Workshops. ECCV 2016. Lecture Notes in Computer Science, vol 9914. Springer, Cham.
[5]S. Huang, Y. Gu, J. Yang, et al., "Reranking of person re-identification by manifold-based
approach," 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, 2015, pp. 4253-4257.
[6]N. Martinel and C. Micheloni, "Re-identify people in wide area camera network," 2012 IEEE
[7]P.F. Felzenszwalb, R.B. Girshick and D. McAllester, "Cascade object detection with deformable part models," 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, 2010, pp. 2241-2248.
[8]K. He, X. Zhang, S. Ren, et al. "Deep Residual Learning for Image Recognition," 2016 IEEE
Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, 2016, pp. 770-778.
[9]Bertinetto, L., Valmadre, J., Golodetz, S., et al. Staple: Complementary learners for real-time
tracking. In: CVPR. (2016)
[10]Vojir T., Noskova J., Matas J. Robust scale-adaptive mean-shift for tracking [J]. Pattern
Recognition Letters, 2014.
[11]Felsberg, M., Berg, A., H¨ager, G., et al.: The thermal infrared visual object tracking
VOT-TIR2015 challenge results. In: ICCV2015 workshop proceedings, VOT2015 Workshop.