© 2017, IRJET | Impact Factor value: 5.181 | ISO 9001:2008 Certified Journal | Page 1925
THE BIG DATA IMPORTANCE – TOOLS AND THEIR USAGE
Pooja Singh, Assistant Professor, Vadodara Institute of Engineering, Gujarat, India
---***---
Abstract:- In this modern time, colossal measures of information is accessible close by to leaders. Huge information alludes to a great degree vast datasets that might be broke down to uncover examples, patterns, and affiliations, particularly identifying with human conduct and cooperation. They are enormous, as well as high in assortment and speed, which makes them hard to handle utilizing customary devices and strategies. According to the development rate of such information, arrangements should be given to handle and concentrate esteem and learning which permits leaders to
have the capacity to increase profitable thoughts from such different and quickly changing information which comes, going from every day exchanges to client cooperation and interpersonal organization information. This paper plans to look at a portion of the distinctive techniques and apparatuses which can be pertinent on huge information, and in addition the open doors gave by the utilization of huge information examination in different choice spaces.
Keywords—big data, analytics, decision making.
INTRODUCTION
A world without information stockpiling is past creative energy; a place where everything about a man or association, each exchange performed, or each perspective which can be kept up is lost straightforwardly after utilize. Along these lines, Organizations lose the capacity to concentrate significant data and information, perform nitty gritty examinations, and also give new shots and focal points. Anything from client points of interest, to items accessible, to buys made, to representatives enlisted, and so forth has turned out to be basic for everyday exercises. Information is not only a back-office, accounts-settling apparatus any more. It is progressively utilized as a continuous basic leadership instrument. Information is the constituent component whereupon any association flourishes. With the expansion away capacities and techniques for information accumulation, a lot of information have turned out to be effortlessly accessible. Consistently, more information is being made which are to be put away and broke down keeping in mind the end goal to concentrate esteem. Moreover, information has turned out to be less expensive to store, so associations need to get however much esteem as could be expected from the gigantic measures of put away information. The size, assortment, and sudden change of such information require another sort of huge information examination, and diverse stockpiling and investigation strategies. Computing has become ubiquitous, creating countless new digital puddles, lakes, tributaries and
oceans of information. The motto of this paper is to provide an analysis of the available sources on big data analytics. Accordingly, some of the various big data tools, methods, and technologies which can be applied are discussed, and their applications and opportunities provided in several decision domains are portrayed. This is due to big data being a recently focused upon topic.
BIG DATA ANALYTICS
© 2017, IRJET | Impact Factor value: 5.181 | ISO 9001:2008 Certified Journal | Page 1926 Figure 1: Layered Architecture of Big Data System
Characteristics of Big Data
Big data is term for data sets that are so large or complex that old methods of data processing applications are insufficient to cope up with them. Challenges include analysis, capturing data, its accuracy, search, sharing, storage of data whose scale, distribution, diversity, and/or timeliness require the use of new technical architectures, analytics, and tools in order to enable new ideas that unlock new sources of business value. Three main features characterize big data: volume, variety, and velocity, or the three V’s. The volume of the data is its size, and how large it is. Velocity refers to the rate with which data is changing, or how often it is created. Variety includes the different formats and types of data, as well as the different kinds of uses and ways of analyzing the data. The Big data is streaming data which is collected at real-time, some researcher have defined it in fourth V- Veracity. Veracity focuses on the quality of the data. This feature is used to identify big data quality as good, bad, or undefined due to data inconsistency, incompleteness, ambiguity, latency, and approximations.
Big Data Analytics Tools and Methods
To have lots of data on hand is no longer enough to make
correct decisions at the right time. Such data sets can no longer be easily analyzed with traditional data management & analysis techniques and infrastructures. Thus a need for new tools and methods specialized for big data analytics, as well as the required architectures for storing and managing such data. Accordingly, the emergence of big data has an effect on everything from the data itself and its collection, to the processing, to the final extracted decisions.
The framework maps the different big data storage, management, and processing tools, analytics tools and methods. Thus, the changes associated with big data analytics are reflected in three main areas: big data storage and architecture, data and analytics processing, and, finally, the big data analyses which can be applied for knowledge discovery and informed decision making.
Big Data Storage and Management
The traditional methods of structured data storage and retrieval consist of relational databases, data marts, and data Warehouses. The data is uploaded to the storage from operational data stores using Extract, Transform, Load (ETL), or Extract, Load, Transform (ELT), tools which extract the data from outside sources, transform the data to fit operational needs, and finally load the data into the database or data warehouse. Thus, the data is cleaned, transformed, and catalogued before being made available for data mining and online analytical functions.
© 2017, IRJET | Impact Factor value: 5.181 | ISO 9001:2008 Certified Journal | Page 1927 databases which helps in eliminating I/O disk space and
also enables the real-time response from the databases.
Big Data Analytic Processing
After the enormous information stockpiling, systematic preparing comes into concern. In this way, there are fundamental four necessities for preparing. Quick information stacking is the essential necessities. Along these lines, it is important to decrease the stacking time of information as the network activity meddles amid load time with question execution. According to the diagnostic based prerequisite, the second is quick question handling. The third prerequisite for huge information preparing is to proficiently use the capacity territory in light of the fact that the quick development in view of client movement can request gigantic storage room which can be overseen well amid handling. What's more, the last prerequisite is solid versatility to workload designs and startling elements that will be happened amid handling.
BIG DATA TOOLS Hadoop
Hadoop is a framework used for the processing of large data sets in a distributed computing environment.Hadoop was introduced by Google’s MapReduce that is software framework which divides the tasks of application into various parts.The important aspect of big data processing isparallelism which is provided by MapReduce.
[image:3.595.308.562.102.250.2]Map Reduce is defined as parallel programming model, which is a combination of “Map” and “Reduce” function, which is suitable for big data processing. The idea behind MapReduce is breaking a task down into steps and executing the steps in parallel in order to reduce the time needed to complete the task. The Current Apache Hadoop ecosystem consists of the Hadoop Kernel, MapReduce, HDFS and numbers of various components like Apache Hive, Base, Sqoop, Pig and Flume.
Fig. 2:- Apache Hadoop Ecosystem
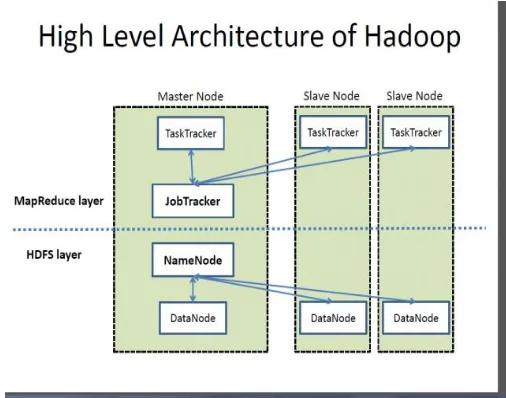
Fig.3:-Hadoop Architecture
The Current Apache Hadoop biological community comprises of the Hadoop Kernel, MapReduce, HDFS and quantities of different parts like Apache Hive, Base, Sqoop, Pig and Flume. It gives unwavering quality, versatility, and sensibility by giving an execution to the MapReduce worldview. Hadoop comprises of two fundamental parts: the HDFS for the enormous information stockpiling, and MapReduce for huge information examination. The HDFS gives an excess and dependable dispersed record framework, where a solitary document is part into parts and disseminated crosswise over various hubs.
[image:3.595.304.557.293.492.2]© 2017, IRJET | Impact Factor value: 5.181 | ISO 9001:2008 Certified Journal | Page 1928 between the customer and the Data Node, guiding the
customer to the specific Data Node which contains the asked for information. The first phase of the MapReduce job is to map input values to a set of key/value pairs as output. The “Map” function partitions large computational tasks into smaller tasks, and assigns them to the appropriate key/value pairs.
The MapReduce work inside Hadoop relies on upon two unique hubs: the Job Tracker and the Task Tracker hubs. The Job Tracker hubs are the ones which are in charge of appropriating the mapper and reducer capacities to the accessible Task Trackers.
APACHE PIG
Pig was at first created at Yahoo Research around 2006 however moved into the Apache Software Foundation in 2007. Pig comprises of a dialect and an execution situation. Pig's dialect, called as PigLatin, is an information stream dialect - this is the sort of dialect in which you program by associating things together. Pig can work on complex information structures, even those that can have levels of settling. Not at all like SQL, Pig does not require that the information must have a mapping, so it is appropriate to handle the unstructured information. However, Pig can in any case influence the estimation of a mapping in the event that you need to supply one. PigLatin is socially total like SQL, which implies it is at any rate as intense as a social variable based math. Turing culmination requires contingent builds, a vast memory model, and circling develops. PigLatin is not Turing complete on itself, but rather it can be Turing finished when reached out with User-Defined Functions.
Fig.4: Pig Architecture.
There are three different ways to run Pig. You can run your PigLatin code as a script, just by passing the name of your script file to the pig command. You can run it interactively through the grunt command line launched using Pig with no script argument. Finally, you can call into Pig from within Java using Pig’s embedded form.
APACHE HIVE
© 2017, IRJET | Impact Factor value: 5.181 | ISO 9001:2008 Certified Journal | Page 1929 Fig.5:- Hive Architecture
Hive additionally underpins propelling administrations from the hive order. You can dispatch an administration that gives you a chance to get to Hive through Thrift, ODBC, or JDBC by passing support of the hive order took after by the word hive server. There is likewise a web interface to hive whose administration is propelled by taking after the administration choice with hive. You can likewise utilize a Hive administration to run the hadoop summon with the jug alternative the same as you could do straightforwardly, however with Hive jolts on the classpath. In conclusion, there is an administration for an out of process metastore. The metastore stores the Hive metadata. There are three designs you can decide for your metastore. In the first place is inserted, which runs the metastore code in a similar procedure with your Hive program and the database that backs the metastore is in an indistinguishable procedure from well. The second choice is to run it as nearby, which keeps the metastore code running in process, yet moves the database into a different procedure that the metastore code speaks with. The third alternative is to move the metastore itself out of process too. This can be helpful on the off chance that you wish to impart a metastore to different clients. APACHE SQOOP
Sqoop is an effective hadoop tool for non-programmers which functions by looking at the databases that need to be imported and choosing a relevant import function for the source data. Once the input is recognized by Sqoop hadoop, the metadata for the table is read and a class definition is created for the input requirements. Hadoop Sqoop can be forced to function selectively by just getting the columns needed before input instead of importing the entire input and looking for the data in it. This saves considerable amount of time. In reality, the import from the database to HDFS is accomplished by a MapReduce job that is created in the background by Apache Sqoop.
Fig.6:- Sqoop Architecture
Sqoop has connectors for working with a scope of prominent social databases, including MySQL, PostgreSQL, Oracle, SQL Server, and DB2. Each of these connectors knows how to interface with its related DBMS. There is likewise a non specific JDBC connector for interfacing with any database that backings Java's JDBC convention. Furthermore, Sqoop gives upgraded MySQL and PostgreSQL connectors that utilization database-particular APIs to perform mass exchanges productively.
Elements of Apache Sqoop
Apache Sqoop underpins mass import i.e. it can import the total database or individual tables into HDFS. The documents will be put away in the HDFS record framework and the information in inherent indexes.
Sqoop parallelizes information exchange for ideal framework use and quick execution.
Apache Sqoop gives coordinate information i.e. it can outline databases and import straight forwardly into HBase and Hive.
Sqoop makes information examination productive. Sqoop helps in alleviating the exorbitant burdens to
outside frameworks. APACHE FLUME
Apache Flume is a framework utilized for moving huge amounts of spilling information into HDFS. Gathering log information introduce in log documents from web servers and amassing it in HDFS for investigation, is one normal illustration utilize instance of Flume.
Flume bolsters numerous sources like –
© 2017, IRJET | Impact Factor value: 5.181 | ISO 9001:2008 Certified Journal | Page 1930 Framework logs
Apache logs (empower Java applications to compose occasions to records in HDFS by means of Flume).
Fig.7:- Flume Architecture
Logs are normally a wellspring of stress and contention in the vast majority of the enormous information organizations. Logs are a standout amongst the most difficult assets to oversee for the operations group as they take up colossal measure of space. Logs are seldom present at spots on the circle where somebody in the organization can make viable utilization of them or hadoop designers can get to them. Numerous enormous information organizations end up building instruments and procedures to gather logs from application servers, exchange them to some storehouse so they can control the lifecycle without expending pointless circle space.
CONCLUSION
From this review, it is reasoned that in PigLatin, the information stream is indicated. In any case, in Hive, the outcomes are portrayed and it makes sense of how to fabricate an information stream to accomplish the coveted outcomes under disseminated environment. In Sqoop, JDBC Connectivity is required. In flume, log documents from different servers are required. Not at all like Pig, in Hive an outline is required, yet you are not restricted to just a single construction. Like PigLatin and the SQL, HiveQL itself is a socially entire dialect however it is not a Turing complete dialect. It can likewise be stretched out through UDFs simply like Piglatin to be a Turing complete. Hive is an innovation for transforming the Hadoop into an information stockroom, finish with SQL tongue for questioning it. Sqoop is utilized for parallel information exchange though Flume is for gathering
and amassing data.In this paper, at first a mapreduce work utilizing Apache Pig is effectively made and after that it is utilized to break down a major database to get required outcomes. At long last a mapreduce employment is made utilizing Hive and after that practiced it to break down a major database to get comes about. The last outcomes demonstrate that the examination performed by both of the mapreduce machines is effective. The execution of the considerable number of apparatuses talked about was almost same.
REFERENCES
1) S.Vikram Phaneendra & E.Madhusudhan Reddy “Big Data- solutions for RDBMS problems- A survey” In 12th IEEE/IFIP Network Operations & Management Symposium (NOMS 2010) (Osaka, Japan, Apr 19{23 2013).
2) Alexandros Biliris,“An Efficient Database Storage Structure for Large Dynamic Objects”, IIEEE Data Engineering Conference, Phoenix, Arizona, pp. 301-308, February 1992.
3) An Oracle White Paper, “Hadoop and NoSQL Technologies and the Oracle Database”, February 2011.
4) Cattell, “Scalable sql and nosql data stores”, ACM SIGMOD Record, 39(4), pp. 12–27, 2010.
5) Russom, “Big Data Analytics”, TDWI Research, 2011. 6) Sanjay Ghemawat, Howard Gobioff, and Shun-Tak
Leung, “Google file system”, 2003.
7) http://www.guru99.com/introduction-to-flume
and-sqoop.html.
8) https://www.dezyre.com/article/sqoop-vs-flume-battle-of-the-hadoop-etl-tools-/176
9) http://wikibon.org/wiki/v/HBase,_Sqoop,_Flume_an d_More:_Apache_Hadoop_Defined
10) Adams, M.N.: Perspectives on Data Mining. International Journal of Market Research 52(1), 11– 19 (2010).
11) Asur, S., Huberman, B.A.: Predicting the Future with Social Media. In: ACM International Conference on Web Intelligence and Intelligent Agent Technology, vol. 1, pp. 492–499(2010)
© 2017, IRJET | Impact Factor value: 5.181 | ISO 9001:2008 Certified Journal | Page 1931 BIOGRAPHIES
Pooja Singh
Assistant Professor, Vadodara Institute of Engg. Kotambi, Vadodara.