Map Reduce a Programming Model for Cloud Computing Based On Hadoop Ecosystem
Full text
Figure
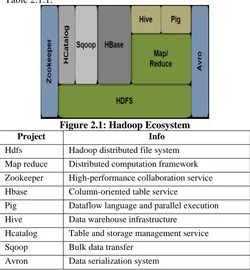
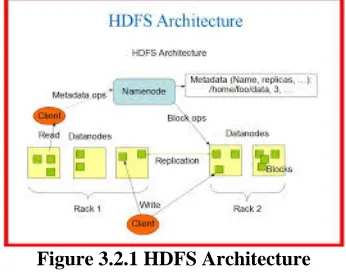
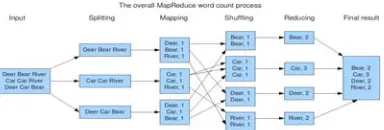
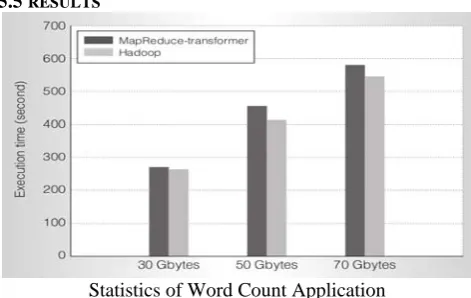
Related documents
Results: There are striking differences in the number of single cigarette violations found by state, with 38 states producing no warning letters for selling single cigarettes even
The information you provide will help me and others gain a better understanding how drug testing affects students’ attitudes toward this type of drug prevention program, and assist
Measurement, Constrained Estimation, Nonlinear Filtering, Distributed Fusion, Packet... List
Taking into account (i) the trend of gradually even revenue contribution from our existing Medical Practitioners over the Track Record Period; (ii) our expansion and plan of
The goal of this study was stability analysis of the upstream slope of earthen dams using the finite element method against sudden change in the water surface of the reservoir in
For example, if you elected a Medical Reimbursement FSA (Health Care FSA) benefit of $1,000 for the plan year and have received only $200 in reimbursement, you may continue
Yeast Surface Two-hybrid for Quantitative in Vivo Detection of Protein- Protein Interactions via the Secretory Pathway[J]. Cell Surface Assembly of HIV gp41 Six-Helix Bundles
Abstract: The US housing market exhibits seasonal boom and bust cycles where prices and the speed of trade (turnover rate) rise in summers and fall in winters.. We present a
