ABSTRACT
LOFTIN, ROBERT TYLER. Extracting Latent Knowledge to Reduce Teacher Effort in Interactive Machine Learning. (Under the direction of David L. Roberts).
A key goal of research in interactive machine learning is to allow human users to teach artificial agents to perform useful tasks, such as filtering emails or delivering medication, without requiring
these users to have any experience with programming languages or artificial intelligence. To enable
this, agents must be able to learn through forms of communication that are natural for most users, forms that a user might employ when teaching another human or training an animal, such as
demonstration and evaluative feedback. There is a limit to the amount of these types of data that a
single user can provide in a reasonable amount of time; and for agents to learn complex, real world tasks, they must take maximum advantage of available user data. We argue, however, that existing
interactive learning approaches ignore a significant amount of useful information contained in
these forms of communication, and so require more work on the part of the user than is necessary. This work seeks to reduce the effort required to teach artificial agents by developing algorithms that
are able to extract this previously unexploited information.
In the case of learning from evaluative feedback, this work demonstrates that it is beneficial for an agent to treat human feedback as a complex, discrete mode of communication, rather than
simply as a numeric utility function to be optimized. Specifically, we look at how the teacher’s
approach to providing positive and negative feedback can influence the agent’s interpretation of situations where no feedback is provided, that is, if the agent expects to be rewarded for acting
correctly, then the lack of reward could be indicative of incorrect behavior. This work develops
a novel model of evaluative feedback as a discrete communication, with an interpretation that depends on the teacher’s training strategy. Based on this model, we develop two novel algorithms,
SABL and I-SABL. The SABL algorithm treats the problem of learning a behavior from feedback as
one of Bayesian inference. The I-SABL algorithm extends SABL, and infers a user’s teaching style in real time. I-SABL uses that knowledge to learn even when no explicit feedback is provided. We will
demonstrate empirically that SABL and I-SABL can learn more efficiently than previous approaches.
We also consider the case of learning from demonstrations and feedback simultaneously, and specifically what an agent can learn about its environment (independent of any specific task)
from such communication. In addition to knowing the task or tasks that they want an agent to perform, the teacher’s knowledge of the dynamics of the agent’s environment will often be greater
than the agent’s initial understanding. By modeling how the teacher’s communication depends
on their understanding of these dynamics, we will show that it is possible for an agent infer the unknown aspects of the dynamics based on this data, without having to observe the dynamics
teacher’s communication, as well as their own observations. The first, the BAM algorithm, learns an
explicit model of the transition dynamics based on both demonstrations and feedback, as well as direct observations of state transitions. The second algorithm, HAL, learns an implicit representation
of dynamics instead, and so can be applied to domains where learning and planning against an
explicit dynamics model would be difficult. We will show that the BAM and HAL algorithms can learn about the dynamics of their environments based on demonstrations and feedback, and more
importantly, that they can transfer this knowledge between different tasks in the same environment,
using this information to reduce the amount of teacher effort required for an agent to learn to perform a collection of tasks.
As the goal of this work is to develop algorithms that learn more efficiently from non-expert
human users, we validate our algorithms by conducting a series of large-scale, web-based user studies in which real human users teach learning agents to perform various tasks. Specifically,
we present the results of multiple user studies evaluating the SABL, I-SABL, and BAM algorithms,
and comparing them against existing approaches to learning from feedback and learning from demonstration. In addition to the technical contributions of this work, we also present a number
of empirical results regarding the different ways in which humans teach via demonstrations and
feedback. In particular, we presents an empirical analysis of the different teaching styles preferred by real users, and the factors that affect their choice of teaching style. Ultimately, we hope that by
reducing the effort required to teach artificial agents, the approaches developed in this work will allow interactive learning to be applied to more complex, real-world domains, and for interactive
© Copyright 2019 by Robert Tyler Loftin
Extracting Latent Knowledge to Reduce Teacher Effort in Interactive Machine Learning
by
Robert Tyler Loftin
A dissertation submitted to the Graduate Faculty of North Carolina State University
in partial fulfillment of the requirements for the Degree of
Doctor of Philosophy
Computer Science
Raleigh, North Carolina
2019
APPROVED BY:
Eric Laber Dennis Bahler
Min Chi Michael L. Littman
External Member
DEDICATION
BIOGRAPHY
Robert Loftin was born in Durham, North Carolina, in 1989, and was raised in Greensboro, NC. He attended the Georgia Institute of Technology in Atlanta from 2008 to 2011, receiving a Bachelor of
Science in Computer Science in the spring of 2011. He pursued his PhD in Computer Science at
ACKNOWLEDGEMENTS
I would like to thank my advisor Dave Roberts for his support throughout my exceedingly long career as a PhD student. I would also like to thank Matt Taylor and Michael Littman for their advice
and mentorship over the years. Finally, I would like to thank my colleagues Matthew Adams, James
TABLE OF CONTENTS
LIST OF TABLES . . . vii
LIST OF FIGURES. . . .viii
Chapter 1 Introduction. . . 1
1.1 Interactive Learning Setting . . . 3
1.2 Understanding Training Strategies . . . 3
1.3 Learning About the Agent’s Environment . . . 5
1.4 Summary of Thesis . . . 7
Chapter 2 Related Work . . . 9
2.1 Reinforcement Learning . . . 10
2.1.1 Markov Decision Processes . . . 10
2.1.2 Model-Free Reinforcement Learning . . . 11
2.1.3 Model-Based Reinforcement Learning . . . 11
2.2 Learning from Feedback . . . 12
2.3 Imitation Learning . . . 13
2.3.1 Apprenticeship Learning . . . 14
2.3.2 Inverse Reinforcement Learning . . . 16
2.4 Discussion . . . 18
Chapter 3 SABL: Strategy Aware Learning from Feedback . . . 19
3.1 Behaviorism . . . 20
3.2 Training Strategies . . . 20
3.3 Probabilistic Model of Training Strategies . . . 21
3.4 Numeric Reward vs. Discrete Feedback . . . 23
3.5 Strategy-Aware Bayesian Learning . . . 24
3.5.1 The SABL Algorithm . . . 24
3.5.2 SABL for Unknown Strategies: Inferring-SABL . . . 25
3.6 SABL with Advantage Functions . . . 29
3.6.1 Advantage Functions . . . 29
3.6.2 The A-SABL Model . . . 30
3.7 Discussion . . . 32
Chapter 4 Empirical Evaluation of SABL . . . 33
4.1 User Studies . . . 33
4.1.1 Volunteer Studies . . . 35
4.1.2 Amazon Mechanical Turk Studies . . . 35
4.2 Analysis of Training Strategies Used in Practice . . . 37
4.2.1 Effects of Dog-Training Experience . . . 40
4.2.2 Effect of Agent Appearance . . . 41
4.2.3 Effect of Feedback from the Agent . . . 42
4.3 Performance of SABL and I-SABL . . . 44
4.3.1 Reward Based Algorithms, M−0and M+0 . . . 45
4.3.2 User Studies . . . 46
4.3.3 Experiments with Simulated Trainers . . . 48
4.4 SABL in Sequential Domains . . . 49
4.5 Conclusions . . . 51
Chapter 5 BAM: Learning Dynamics from Human Teachers . . . 53
5.1 Learning a Teacher’s Dynamics Model . . . 55
5.1.1 Learning from Demonstrations and Feedback . . . 56
5.1.2 The Behavior Aware Modeling Algorithm . . . 57
5.2 BAM vs. SERD . . . 59
5.3 Off-task Demonstrations . . . 60
5.3.1 Recognizing Off-Task Demonstrations . . . 60
5.3.2 Learning Reusable Skills . . . 60
5.4 Concluding Thoughts on BAM . . . 61
Chapter 6 Empirical Evaluation of the BAM Algorithm . . . 62
6.1 Experimental Domains . . . 63
6.2 Alternative Algorithms . . . 65
6.3 Simulated Teacher Experiments . . . 66
6.3.1 Global Cost Functions . . . 67
6.3.2 Demonstrations and Feedback . . . 69
6.4 Human Subjects Experiment . . . 69
6.4.1 Learning Sessions . . . 71
6.4.2 Results . . . 72
6.5 Conclusions . . . 73
Chapter 7 HAL: Modeling a Teacher’s Reasoning Process. . . 75
7.1 Human Abstraction Learning . . . 77
7.1.1 Planning Representations . . . 77
7.1.2 Residual Inverse Reinforcement Learning . . . 79
7.1.3 The HAL Algorithm . . . 81
7.2 Simulation Experiments . . . 83
7.3 Concluding Remarks on HAL . . . 86
Chapter 8 Conclusions and Future Directions. . . 88
8.1 Future Directions . . . 89
8.2 Concluding Remarks . . . 90
LIST OF TABLES
Table 3.1 Breakdown of the training strategies observed in our web-based user studies.. . . 21
Table 4.1 Summary of Amazon Mechanical Turk studies, results of which are discussed in Sections 4.2.2, 4.2.3 and 4.2.4. . . 36 Table 4.2 Breakdown of strategies used in AMT 1, 2 and 3 when training an agent
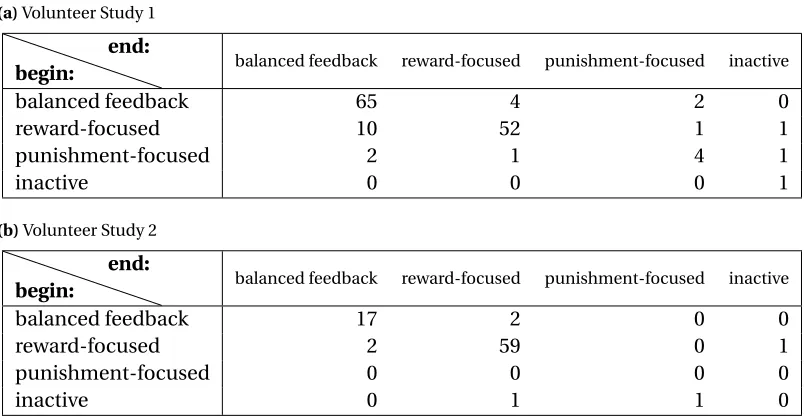
ap-pearing as a dog, robot, snake or arrow. . . 38 Table 4.3 The number of participants beginning a training session using one strategy
(rows) and ending it using another (columns). Entries on the diagonal indicate that no change occurred. . . 38 Table 4.4 Breakdown of strategies used when training a dog with policy-accuracy
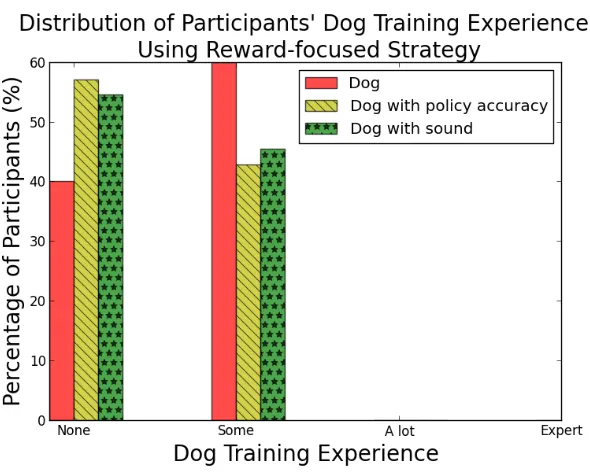
dis-played and a dog with sound, as well as when training a dog with the $0.25 performance bonus and with the $0.75 bonus. . . 42 Table 4.5 For all algorithm and simulated trainer pairs tested, the average number of steps
before the agent correctly identified the intended policy as the most likely, and the average number of explicit feedbacks that were provided before the intended task was identified as the most likely. “N/A” indicates that the algorithm was unable to learn the correct policy in the majority of training runs. . . 50
Table 6.1 The mean duration, in seconds, of learning sessions for each environment and algo-rithm. Standard deviations are given in parentheses.. . . 70
LIST OF FIGURES
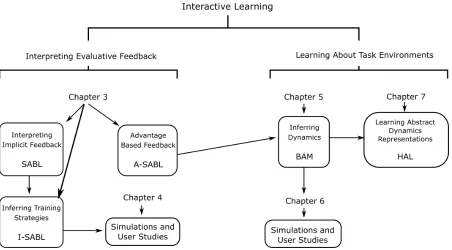
Figure 1.1 The connections between different aspects of this work, and how these ele-ments relate to the chapters of this thesis. . . 7
Figure 4.1 A screenshot of the study interface. Additional buttons that begin and end training have been cropped out. . . 34 Figure 4.2 Alternative sprite combinations used in the Mechanical Turk Studies. In
addi-tion to being represented as a dog, the agent could also have been a robot, a snake, or an arrow. . . 36 Figure 4.3 Mosaic plots (generated with the R language) with Pearson residuals for
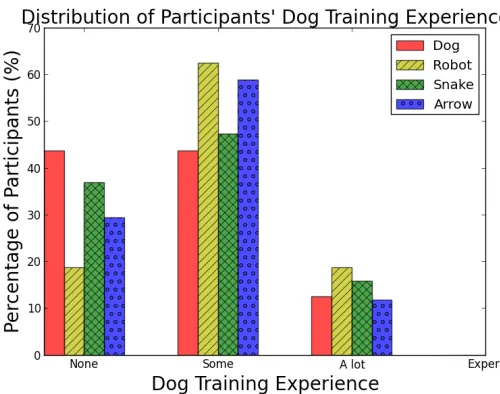
strate-gies in the volunteer studies, grouped by dog-training experience (Note that boxes with solid borders indicate a deviationabovethe expected value, while boxes with dotted borders indicate a deviationbelowthe expected value). Users with no experience were more likely to use balanced-feedback strategy, users with some experience were more likely to use a reward-focused strategy. For volunteer study 1, differences were 2–4 standard deviations from their expected values (significant withp<0.05). . . 40 Figure 4.4 The distribution of participants in AMT 1, 2 and 3 who used a reward-focused
strategy, based on their experience with dog training, grouped by the sprite they were training. . . 42 Figure 4.5 The distribution of participants in AMT 6-8 who used a reward-focused
strat-egy based on their experience with dog training, grouped by different training conditions. . . 43 Figure 4.6 The average number of episodes required to learn a policy that was correct for at
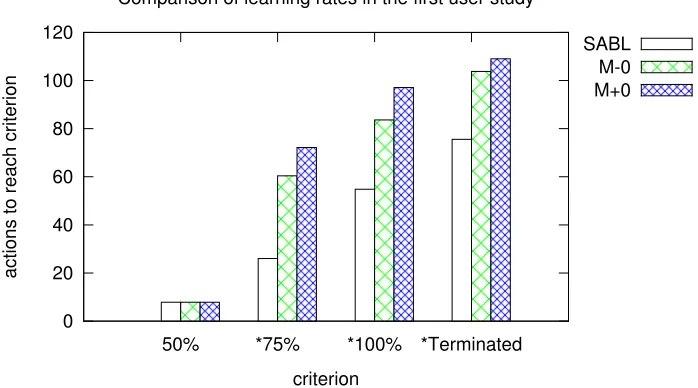
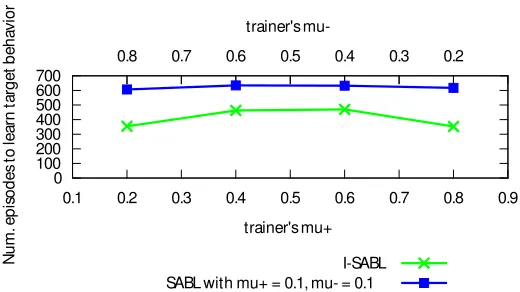
least 50%, 75%, or 100% of observations, and until the participants terminated the session. (* indicates that differences were statistically significant for that column).. . 47 Figure 4.7 Performance of I-SABL and SABL (µ__=µ+=0.1) with simulated trainers. The bottom
x-axis is the trainer’sµ+, the top x-axis isµ__, and the y-axis is the number of episodes
to find the target policy. As the difference betweenµ+andµ__grows, so too does the
performance difference between SABL and I-SABL.. . . 48 Figure 4.8 The sequential domain. Blue squares represent possible goal states, circles represent
obstacles of type one and stars represent obstacles of type two.. . . 49
Figure 5.2 An illustration of the assumed dependence of a teacher’s feedback and demon-strated actions on the cost functionsC(zi)for each individual task, and on
their global dynamics modelTθ. Note that the state transitions observed by the agent,DE, also depend onTθ, which is to say thatTθ is an exact model of the true dynamics. Note also that teacher data depends on the costs and dynamics through a state-action value functionQifor each taski. . . 57
Figure 6.1 The four navigation environments used in the simulated teacher experiments, in-cluding the Doorway and Two Rooms environments used in the human subjects experiments. Orange circles indicate goal locations, with each goal defining a differ-ent task. White squares indicate states blocked by obstacles.. . . 63 Figure 6.2 The two gravity environments used in the simulated teacher experiments. Orange
circles indicate goal locations, with each goal defining a different task. Arrows indicate states that change the direction of the gravity, but the agent can only see the color of these arrows, not their direction. The unknown dynamics consist of the mapping from colors to gravity directions. . . 64 Figure 6.3 The two farming environments used in both the simulated teacher and human
subjects experiments. Target Fields are highlighted with green squares, with each target field defining a different task. Also visible are the agent itself (the blue drone), and the three farm implements (only the plow and sprinkler are available in (b)).. . . 64 Figure 6.4 The total return of the policies learned by BAM, model-based IRL, and behavioral
cloning, as a percentage of the total return for the optimal policies. Curves are aver-ages over 50 separate agents learning from scratch.. . . 66 Figure 6.5 The total return of the policies learned by BAM, model-based IRL, and model-based
IRL with global costs, as a percentage of the total return for the optimal policies. Curves are averages over 50 separate agents learning from scratch. . . 68 Figure 6.6 The total return (averaged over 50 episodes) of the policies learned by BAM,
model-based IRL, and behavioral cloning, as a percentage of the total return for the optimal policies, learning from demonstrations and feedback combined. Curves are averages over 50 separate agents learning from scratch. . . 69 Figure 6.7 A screen shot of the user interface for the user study conducted through Amazon
Mechanical Turk. The interface is currently in the tutorial mode for the navigation domain.. . . 71
Figure 7.1 An illustration of the assumed dependence of a teacher’s feedback and demon-strated actions on their internal planning process described by the parame-tersθ, and the intent vectorzifor each individual task. Note that while the
teacher’s planning process depends on the true dynamics of the environ-ment, it does not directly predict the observed transitionsDE. The dashed arrow illustrates an assumed direct dependence ofθonDE, which is used to
approximate the more complex dependence ofθonDE throughT. . . 78
Figure 7.3 The two navigation environments we used to evaluate the effectiveness of learning abstract models with HAL, as opposed to low-level dynamics models. In this version of the navigation task, the agent observes the occupancy of all cells within a fixed radius. The area the agent has observed so far is brighter in these figures than the unexplored space. Each of the environments is represented by a 40x40 cell occupancy map. . . 83 Figure 7.4 The percentage of episodes in which the agent’s policy completed the target task,
where the task was chosen at random for each episode. Estimated by running 200 episodes from random initial states. Five expert demonstrations of each task were provided. A larger value indicates better performance.. . . 85 Figure 7.5 The expected number of steps required to complete all tasks, as a percentage of the
CHAPTER
1
INTRODUCTION
A key goal of research in interactive machine learning is to allow human users to teach robots and
other artificial agents to perform useful tasks, such as filtering emails and delivering medication, without requiring these users to possess experience with programming languages or artificial
intelli-gence. To enable this, we must design agents that can learn from modes of communication that are
natural for everyday users (whom we will refer to as theteachers), modes that a user might employ when teaching another human, or when training an animal. In this work we focus on learning from
two such forms of communication: a user demonstrating a behavior to an agent[Arg09], and a user providing evaluative feedback while an agent attempts to perform a behavior itself. While a number of existing approaches are able to learn from demonstrations and/or feedback[TB06; Jud14; KS09; Arg07], we argue that these methods ignore a significant amount of useful information contained in these forms of teacher communication. Specific examples of such information include:
1. The teacher’s strategy for training the agent.
2. Implicit communication through the withholding of feedback.
3. Task independent knowledge regarding the structure of the agent’s environment.
4. Information about the teacher’s own understanding of the task and environment.
This work seeks to reduce the effort required to teach artificial agents by developing algorithms that
As part of this work, we look closely at the problem of learning from evaluative feedback. We
demonstrate that it is beneficial for an agent to treat human feedback as a complex, discrete mode of communication, rather than simply a numeric utility function to be optimized, as has been done
with previous work. We pay special attention to cases where different teaching styles affect the
correct interpretation of a teacher’s feedback. Specifically, we look at how the teacher’s approach to providing positive and negative feedback can influence the agent’s interpretation of situations
where no feedback is provided. If the agent expects to be rewarded for acting correctly, then the lack
of reward could be indicative of incorrect behavior.
We also consider the case of learning from demonstrations and feedback simultaneously, and
specifically what an agent can learn about its environment from such communication. In addition
to knowing the task or tasks that they want an agent to perform, the teacher’s knowledge of the dynamics of the agent’s environment will often be greater than the agent’s initial understanding. By
modeling how the teacher’s communication depends on their understanding of these dynamics,
we will show that it is possible for an agent infer the unknown aspects of the dynamics based on this data, without having to observe the dynamics directly. We will also show that an agent can take
advantage of this knowledge to find solutions for the target task(s) more efficiently. We summarize
the purpose of this work in the following thesis statement:
By modeling the dependencies of a human teacher’s communication with an agent on that teacher’s own understanding of their environment, and on their choice of training strategy, we can design algorithms which learn to perform behaviors in less time and with less effort on the part of human teachers.
The core contributions of this work are a set of novel algorithms for learning from human teachers.
Specifically, we present four learning algorithms, each of which extracts information from a teacher
that existing methods have ignored:
1. Strategy-Aware Bayesian Learning (SABL), which learns behaviors from both explicit and implicit evaluative feedback.
2. Inferring SABL (I-SABL), which infers a teacher’s strategy online based on the feedback they
have provided.
3. Behavior Aware Modeling (BAM), which learns about the transition dynamics of unobserved states from a teacher.
4. Human Abstraction Learning (HAL), which captures a teacher’s abstract understanding of
their environment.
We present the results of a number of experiments evaluating these algorithms, both with synthetic
algo-rithms in reducing teacher effort relative to existing approaches. In addition to our main technical
contributions, this work also presents an empirical examination of the strategies human teachers employ when providing feedback.
1.1
Interactive Learning Setting
Interactive machine learning has been applied to a wide variety of settings, from long term inter-action with a single user in a smart home environment[Zul17], to online systems where a single agent learns from many users at once[Isb01]. This work focuses specifically on the case where a single user teaches an agent to perform one or more specific tasks, in a single training session that
might last from a few minutes to a few hours, depending on the complexity of the tasks. While
our experiments will only involve virtual agents, a key real world motivation for this set up is the application of interactive learning to robotics, that is, allowing an end user to expand the space
of behaviors a robot is capable of performing. While we believe that the techniques developed in
this work will be applicable to other interactive learning settings, the subtle differences in the way humans communicate in different contexts may require significant modifications to our algorithms,
and we would not expect them to work out of the box in settings beyond those we consider here.
While the empirical results that this work will produce will involve agents learning in a diverse set of task domains, the teaching process itself will be similar in each domain, and for each learning
algorithm. The ultimate goal of a teaching session is to have the agent learn apolicy, a mapping from the state of the environment to an action the agent can take, that performs the task being taught. An agent’s learning ability will be evaluated in terms of the time and effort required for it to learn
a satisfactory policy. There are two modes of teaching we will consider, the first being evaluative
feedback where the agent acts according to its current policy while the teacher observes, and has the option to provide positive and negative feedback at any time. The second mode involves the
teacher providing a demonstration of the target task, where the teacher has access to the same
observations and actions as the agent. When learning with demonstrations, we will allow teachers to switch between demonstrating a behavior themselves, and having the agent perform the behavior
while they provide feedback. We will also allow multiple tasks to be taught within a single session,
where the agent will know which of a fixed set of tasks is currently being taught.
1.2
Understanding Training Strategies
to maximize the expected value of the feedback it receives for its actions.
In this work, however, we argue that trainer feedback is a more complicated form of discrete communication between the teacher and the learning agent. Simply treating feedback as a numeric
reward signal (i.e., reward has a positive value, punishment has a negative value, and the goal is to maximize the average return), will in many cases lose information about the target behavior present in the teacher’s feedback. We will see that there are many possible approaches to teaching
via positive and negative feedback, which we will describe astraining strategiesthroughout this work. The teacher’s choice of strategy may depend on the nature of the task being taught, on the nature of the learning agent, and on the teacher’s own background. The teacher may even change
strategies in response to the agent’s behavior.
We are specifically interested in how the teacher’s strategy affects their use of thelackof feed-back as a form ofimplicitfeedback, and how this implicit feedback should be interpreted. As a motivational example of this phenomenon, we consider a common approach to dog training, where
trainers will provide a large amount of explicit reward in the form of treats and conditioned rewards (i.e.,clicker training), but very little explicit punishment. When such an approach is taken to provid-ing feedback, the lack of explicit reward (i.e., withholding a treat from a dog) can itself be interpreted as a form of punishment, indicating that the dog’s previous actions were incorrect. If, however, the reverse strategy was followed, and the trainer only provided explicit punishment, then the lack of
feedback would indicate that the dog’s actions were in fact correct. If the learning agent knows that the teacher is more likely to withhold feedback for either correct or incorrect actions, it can use
this knowledge to learn about actions for which no explicit feedback has been given. In Chapters 3
and 4, we will address the following questions regarding the interpretation of evaluative feedback as a discrete form of communication, and the interpretation of implicit feedback:
1. Will an agent which interprets feedback as a discrete communication learn more efficiently
than one which interprets it as a numeric reward signal?
2. Does the lack of feedback convey useful information when learning from human teachers,
and can we extract this information?
3. Can an agent infer the teacher’s training strategy without knowing the task being taught, and use this knowledge to correctly interpret the lack of feedback?
In Chapter 3 we describe a probabilistic model which captures certain aspects of the teacher’s
training strategy, and use that model to derive two algorithms,Strategy-Aware Bayesian Learning (SABL) andInferring SABL(I-SABL), which explicitly consider training strategy, and can therefore learn about the target behavior even from cases where no explicit feedback is given. In Chapter 4
we present the results of experiments we have conducted both with real human teachers, and with
of web-based studies in which human teachers trained virtual agents to perform tasks by providing
evaluative feedback. Our experiments with human teachers show that SABL and I-SABL can learn more efficiently than existing approaches which interpret feedback as a numeric reward signal. Our
experiments with both real and simulated teachers also show that the I-SABL algorithm can infer
a teacher’s training strategy online, and use that knowledge to interpret the lack of feedback and learn more efficiently than SABL can without knowledge of this strategy. We also characterize the
types of strategies followed in practice by human teachers, and look at potential factors that could
affect those users’ choices of strategy.
1.3
Learning About the Agent’s Environment
In Chapters 3 and 4, we focus on learning individual tasks from a human teacher. Communication from a teacher, however, often contains useful information which is not specific to any single task,
and by extracting this knowledge an agent may be able to learn multiple tasks in less time than
would be needed to learn each task independently. The policy being communicated by a teacher depends not only on the particular task they wish the agent to perform, but also on thedynamicsof the environment in which the agent will operate, that is, on the way in which the agent’s actions can
affect the state of its environment. Existing approaches can learn about these dynamics through direct observations of the outcomes of the agent’s actions, and apply this knowledge to learn multiple
tasks from a teacher. In many real world applications however, we can assume that the teacher’s
knowledge of the current environment will be much greater than the agent’s initial knowledge. We will see that it is possible for a learning agent to extract this knowledge from the data provided by
the teacher, and use it to better understand the task (or the set of tasks) it is being asked to perform.
In Chapters 5 through 7, we will address several questions regarding the problem of learning about dynamics from human teachers, including:
1. Can an agent learn about unobserved aspects of its environment based on communication
from a human teacher?
2. Can dynamics knowledge acquired when learning one task be transferred such that an agent
can learn subsequent tasks more efficiently?
3. How can we capture and utilize the teacher’s high-level understanding of the environment
when modelling the low-level dynamics is impractical?
To illustrate the dynamics learning problem more clearly, we will consider as a running example the problem of a mobile delivery robot learning to navigate through a building for which it does
not initially know the layout. In this setting, the unknown dynamics are defined by this layout, that
any of a number of existing algorithms to explore and build a map of the building on its own, but
this process would be time consuming. A more efficient way to teach the robot the building’s layout would be to simply have a human, who is already familiar with the building, give the robot a tour,
showing the robot the different locations to which it will eventually need to navigate. During this
tour, the robot could learn apartialmap of areas that are visible to its sensors, but much of the layout, such as the interiors of rooms, would not be directly observed.
By reasoning about why the human teacher took the route they did, the robot may be able to
infer something about these areas of the building. Many approaches to interactive learning are based on the assumption that the teacher will act in an efficient, if not necessarily optimal manner.
We would imagine that the teacher giving the tour would take the shortest route between each
location, such that the decision to take one path implies that no shorter path exists. This knowledge can then be used to fill in regions of the map that couldn’t be sensed directly. For example, the robot
might observe a number of open doorways, but would not be able to determine which of these
doors lead to separate rooms, and which ones lead to the same room. If multiple doors lead to a single large room, then it may be possible to take a shortcut through this room to reach different
parts of the building. The fact that the teacher doesn’t take this shortcut, but instead takes a longer
route would therefore indicate that these doors lead to separate rooms.
In Chapter 5 we describe theBehavior-Aware Modeling(BAM) algorithm, which performs exactly this kind of inference, and builds a model of the transition dynamics based on demonstrations and feedback provided by a teacher. BAM extends the concept ofinverse reinforcement learning, where an agent infers the goals of a task from from its interaction with the teacher, to allow the
agent’s model of its environment to also depend of data coming from the teacher. To translate the goals of a task into an actual policy for completing that task, an agent using inverse reinforcement
learning must understand the dynamics of its environment as well, which requires additional data
when the dynamics are not initially known. BAM seeks to reduce the data required in these cases by taking advantage of the teacher’s own knowledge of the dynamics. Most importantly, when learning
multiple tasks in a single environment, BAM is able to transfer knowledge of the dynamics provided
by the teacher between tasks, thus allowing a collection of tasks to be learned more efficiently together than would be possible if they were taught independently. In Chapter 6, we present the
results of experiments evaluating the BAM algorithm, both with simulated teachers and with real
human subjects, which demonstrate the advantages of BAM over existing approaches.
Finally, we consider how a teacher’s understanding of the agent’s environment can be captured
and utilized in settings where building and planning against a low-level model of the one-step
tran-sition dynamics is not practical, as is the case in many domains with high-dimensional, continuous state spaces. In extracting dynamics from the teacher’s behavior, an agent is essentially learning
how the teacher understands and reasons about their environment. The agent may be able to take
Figure 1.1The connections between different aspects of this work, and how these elements relate to the chapters of this thesis.
efficiently. In Chapter 7, we describe theHuman Abstraction Learning(HAL) algorithm, which learns a mapping from a latent task description to a value function that can be used to select actions for
the specified task. This mapping implicitly encodes the teacher’s internal planning process, as well
as their high-level representation of the environment. We also present preliminary results regarding the effectiveness of HAL in learning from data from simulated teachers.
1.4
Summary of Thesis
Chapter 2 will give a brief introduction to reinforcement learning, on which much of this work is based, and will discuss related work on the many existing approaches to interactive machine
learning, with a focus of methods for learning from evaluative feedback and task demonstrations. Chapter 3 will describe our model of the way in which teachers provide evaluative feedback, and
will describe the SABL and I-SABL algorithms which are based on this model. Chapter 4 discusses
empirical results on the effectiveness of SABL and I-SABL, from experiments with both real users and simulated teachers, as well as an analysis of the training strategies teacher’s employed during these
experiments. Chapter 5 describes the BAM algorithm for learning dynamics models from feedback
domains with large or continuous state spaces, and presents potential solutions, in particular the
HAL algorithm, which learns abstract representations of a teacher’s planning process, rather than low-level transition models. Finally, Chapter 8 summarizes the contributions of this thesis, and
CHAPTER
2
RELATED WORK
The field of interactive machine learning encompasses all scenarios where an artificial agent capable
of learning can or must interact with a human user. Work on interactive machine learning ranges from purely empirical studies of human behavior, how humans respond to and work with robots and
artificial agents, to purely algorithmic work addressing the unique computational challenges that
arise in interactive learning. A complete survey of the entire field of interactive machine learning is beyond the scope of this thesis, and so this chapter will focus on those aspects of interactive
learning that are most relevant to our work. In chapter 3, we will describe novel ways of interpreting
evaluative feedback provided by a teacher, and so in this chapter we will cover a number of works on the problem of learning from feedback, paying special attention to the particular interpretation
used by each approach. In chapters 5, 6 and 7 we will develop new algorithms for learning about
these dynamics of an environment from demonstrations provided by a teacher. We will therefore explore the various algorithms that have been developed for learning from such demonstrations,
with a focus on how each algorithm incorporates knowledge of the transition dynamics. As this
2.1
Reinforcement Learning
This work, similar to much of the literature on interactive machine learning, frames the problem
in terms ofReinforcement Learning(RL)[Gri13; Jud14]. Reinforcement learning is the problem of having an agent learn, through interaction with its environment, how to act so as to optimize some utility function. Reinforcement learning is one of the most general frameworks for artificial
intelligence, encompassing both machine learning and sequential decision making. An RL agent
lacks complete prior knowledge of either the utility function it is trying to optimize, or the nature of the environment in which it is operating. In the context of interactive learning, an agent typically has
access to information provided by a human teacher in place of, or in addition to the observations it
receives from its environment.
2.1.1 Markov Decision Processes
A reinforcement learning problem is typically described by aMarkov decision process(MPD), defined by the tuple{S,A,T,C}[SB98]. Here,Srepresents the set of states in which the MPD can be at any given time, whileArepresents the set of actions the agent may take in any state. In this work we generally assume thatSandAare discrete and finite, but we will also consider the case where states are real vectors, such thatSis a continuous vector space. The dynamics of the process are defined by the probability measureT :S×A×ΣS 7→[0, 1], whereΣS is aσ-algebra overS.T
represents the probability that, after taking and actiona∈Ain states∈S, the process will transition to states0∈S. For discrete state spaces we will writeT(s,a,s0) =P r{s
t+1=s0|at =a,st =s}. Finally,
C :S7→ ℜis the cost function to be minimized by the agent.1
The solution to an MDP is apolicyπ:S×ΣA7→[0, 1], which defines a distribution over actions
given the current state which minimizes the expected returnJ(π). This return may be defined as the expected total cost for an agent that selects actions according toπover a finite numberτof
steps,J(π) =EPτt=0C(st)|π, which we refer to as theepisodiccase.J(π)may also be defined as the infinite-timeγ-discounted total costJ(π) =limτ→∞EPτt=0γtC(st)|π
, or the infinite-time average
per-step costJ(π) =limτ→∞Eτ1Pτt=0C(st)|π
. We note that for the discounted and average cost
cases, there will exist a stationary, deterministic policyπwhich minimizesJ. For the episodic case however, the optimal policy may be non-stationary, and may depend on the time remaining until
the end of the episode. We will therefore denote byπ={π1. . .πτ}a sequence of policies, withπi
being the policy at timeτ−i, in the episodic case.
For a given MDP, we defineπ?=arg minπJ(π)as the optimal policy for the MDP for our chosen definition ofJ(π). In the case of finite state and action spaces, where bothT andC are known exactly, it is possible to findπ?through the straightforwardvalue iterationalgorithm. Value iteration
1Here we refer to minimizing expectedcost, as opposed to maximizing expectedreward, to avoid confusion with the
computes functionsV?:S7→ ℜandQ?:S×A7→ ℜthat define the expected return under the optimal policy, given that the agent starts in a given state, or starts in a state and takes a given action. In the episodic case considered in this work, the values of these functions depend on the time until the
episode ends, such that, for a discrete state and action space:
Qi?(s,a) =−C(s) +X
s0∈S
T(s,a,S0)Vi?−1(s0), (2.1)
Vi?(s) =max
a∈AQ
?
i(s,a), (2.2)
withQ0?(s,a) =V0?=0. From the optimalQ-function, we then have thatπ?i(s) =arg maxa∈AQi?. 2.1.2 Model-Free Reinforcement Learning
Reinforcement learning considers the problem of learning the optimal policy when the cost
func-tion and transifunc-tion dynamics are initially unknown to the agent. Much of the RL literature focuses onmodel-freealgorithms, which compute an optimal policy without ever learning an explicit representation of the dynamics of the environment. Temporal difference algorithms for reinforce-ment learning find an approximation of the optimalQ-function online via interaction with the environment[SB98]. The simplest such algorithm,Q-learning, is essentially an online version of value iteration. In theγ-discounted case, at timet, aQ-learning agent updates its estimate of the state-action value function as:
Q(st−1,at−1) = (1−δ)Q(st−1,at−1) +δ
h
−C(st−1) +γmax
a∈AQ(st,a)−Q(st−1,at−1)
i
. (2.3)
Q-learning therefore substitutes averaging over samples from the transition distribution for inte-grating over all possible transitions. Another popular class of model-free algorithms are those that
perform a search directly in the space of policies. Of particular interest arepolicy gradientmethods, which perform gradient descent on the expected returnJ(πθ), estimating the gradient∇θJ(πθ)with respect to the parameters of the policy itself based on trajectories sampled underπθ [Sut00].
2.1.3 Model-Based Reinforcement Learning
This work considers the problem of learning a model of the transition dynamics of an agent’s environment based on a teacher’s behavior. As such, it is closely related to work onmodel-based reinforcement learning. In model-based RL, the agent builds an explicit representation of the
transition dynamics and the cost function, and then computes an optimal policy based on these models. In discrete state spaces, model-based RL algorithms can employ value iteration to compute
optimal policies, and can be used to more efficiently explore an environment than is possible
continuous-state problems as well[DR11; Kim04], model-based methods can struggle in these settings when compared to model-free algorithms. Importantly, representing the dynamics of an environment can often be more complex than simply representing the optimal policy or value
function for a single task. In addition, small errors in the learned model can compound over time,
such that the long-term accuracy of predicted state distributions can be limited.
2.2
Learning from Feedback
Chapters 3 and 4 address the problem of learning from feedback provided by a human teacher. This work is part of a growing literature on the problem of designing algorithms which can learn from
such feedback. This work is also motivated by work in psychology on how animals and humans
learn from positive and negative feedback, specifically, the concept of behaviorism[Ski38]. Based on the insights gained from that work, we develop an approach to learning from feedback which
does not interpret feedback as numeric reward as most existing work does, but instead as a form of
discrete communication from the trainer. Here we discuss existing work in machine learning from feedback, and provide some background on the psychological underpinnings of our work.
There exists a large body of work on the problem of learning from human trainers, and specifically
on learning from trainer feedback. Some approaches[TB06]have treated human feedback as a form of guidance for an agent trying to solve a reinforcement learning problem. In that work, human
feedback did not change the numeric reward from the underlying RL problem, or the optimal policy,
but improved exploration and accelerated learning. Their results suggest that humans give reward in anticipation of good actions, instead of rewarding or punishing the agent’s recent actions.
COBOT[Isb01]was an online chat agent with the ability to learn from its human users with RL techniques. It learned how to promote and make useful discussion in a chat room, combining explicit and implicit feedback from multiple human users. The TAMER algorithm[KS09]has been shown to be effective for learning from human feedback in a number of task domains common in
the RL research community. This algorithm is modeled after standard RL methods which learn a value function from human-delivered numeric rewards. At each time step the algorithm updates its
estimate of the reward function for a state-action pair using thecumulativereward for that action. Similar to our work, other studies[Kno12]have examined how users want to provide feedback, finding that: 1) there is little difference in a trainer’s feedback whether they think that the agent
can learn or that they are critiquing a fixed performance; and 2) humans can reduce the amount
of feedback they give over time, and having the learner make mistakes can increase the rate of feedback. Our work differs because we focus on leveraging how humans naturally provide feedback
when teaching, not how to manipulate that feedback.
that depended probabilistically on the trainer’s target policy, rather than the traditional approach of
treating feedback as numeric reward. Both our work and Policy Shaping use a model of the feedback distribution to estimate a posterior distribution over the trainer’s policy. In contrast to that work,
ours focuses on handling different training strategies, whereas Policy Shaping assumes actions
which do not receive explicit trainer feedback are uninformative as to the trainer’s policy (though still informative about the underlying MDP). The algorithms presented in our work use knowledge
of the trainer’s strategy to extract policy information from actions that receive no explicit feedback.
Further, our algorithms can infer this strategy from experience, and so can adapt to a particular trainer’s strategy.
Other forms of feedback besides simple punishment and reward have also been explored,
including feedback employed by film directors, golf instructors, and 911 operators[Hee04]. These experts gave rich feedback and direction in the form of explaining consequences, querying learner
understanding, using assistive aids,etc. Recent work has shown that a teacher’s feedback may depend on the agent’s current policy, that is, positive feedback is given when the agent’s current actions are an improvement relative to its previous behavior[Mac17]. In addition, other work has considered ways in which an agent can actively solicit feedback from a teacher, for example, by
slowing down its behavior in states where it is less certain about the correct action[Pen16].
2.3
Imitation Learning
In addition to work on learning from feedback, there is a growing body of work that examines the problem ofimitation learning, where the teacher provides demonstrations of the desired be-havior[Arg09]. Imitation learning has been applied effectively to robot control problems, such as navigation[CV07]. In imitation learning, the teacher provides a set of demonstrations in the form of state-action trajectoriesζi={s0i,a0i. . .sτi,aτi}, and the agent must find a policy which replicates the teacher’s behavior as closely as possible. As the teacher’s demonstrations will not cover the entire
state space, the agent must learn which actions to take in states for which no teacher action has been observed.
The simplest approach to imitation learning is to find an approximationπ?of the the teacher’s
policy (which we will refer to asπT) which minimizes the error in predicting the teacher’s individual
actions. This approach, which is often referred to asbehavioral cloning, maps the imitation learn-ing problem to a standard supervised learnlearn-ing problem, such that any algorithm for supervised
learning might be applied. This approach can be effective when sufficient training data is available, particularly cases where demonstration data can be generated synthetically.[Pom89]used such an approach to train a neural network to drive an autonomous vehicle, while more recently[Guo14] used synthetic data to train a deep neural network to play Atari games.
cloning can struggle to learn a policies which generalize well to new states. This can occur for a
number of reasons, including noise in the teacher’s behavior, and differences between the teacher’s capabilities and those of the agent[AS97]. Perhaps most importantly, small differences in the agent and teacher’s respective policies can accumulate over time, leading to large differences in their
distributions of state trajectories. To overcome these issues, a learning agent needs to consider how its long-term behavior under a given policy will compare against the teacher’s behavior. Two
popular approaches,inverse reinforcement learning(IRL) andapprenticeship learning(AL), address this problem by reasoning about the cost function which defines the task the teacher is perform-ing[AN04; CL12]. IRL algorithms estimate this cost function directly, and then compute a policy which minimizes this learned cost, while AL algorithms look for a policy that does at least as well as
the teacher’s policy for all possible cost functions.
Interestingly, some work has been done comparing the effectiveness of imitation learning against
that of learning from feedback[Kno11]. That work, however, suggested that the relative performance of the two approaches was task dependent. In addition, we note that in many cases it may not be possible for the trainers to actually demonstrate the desired behavior. Existing work has also shown
that feedback can be combined with user demonstrations, for example, by using feedback to weigh
the importance of different user demonstrations in estimating the correct policy[Arg07]. Other work has also shown that feedback can be combined with reward from some underlying Markov decision
process, or some predefined shaping reward[Jud10; Jud14]. It should be noted that in both of these examples, feedback was not given interactively, during the performance of a behavior, but was given
as a critique to portions of an agent’s performance that could be selected by the user after the agent
had finished performing the behavior. Our work considers on feedback given in real time, where the distinction between cases where the user is actively teaching the agent, and where the trainer is
passively observing the agent’s behavior is not always clear.
2.3.1 Apprenticeship Learning
To overcome the difficulties with behavioral cloning,[AN04]formulated apprenticeship learning as an approach to the imitation learning problem. Instead of finding a policy which matches the
teacher’s observed actions as closely as possible, an apprenticeship learning algorithm searches for
a policy that minimizes the worst-caseregret,Jc(π)−Jc(πT), relative to the teacher’s policy. The policyπ?output by an apprenticeship learning algorithm can be defined as
π?=arg min
π maxc∈C [Jc(π)−Jc(πT)], (2.4)
whereC is the space of possible cost functions, andJc(π)is the expected return under a specific cost
will be acceptable. As the agent does not have access to the teacher’s true policy, it can substitute an
empirical estimate ˆJc(π)of the teacher’s expected return, based on the demonstrations provided. AL
takes advantage of the fact that the teacher provides extended state-action trajectories, such that the
long-term behavior of the agent’s policy can be compared to that of the teacher. As a consequence
however, AL may not be effective in settings where the agent only observes partial trajectories generated by the teacher.
The spaceC of cost functions defines the inductive bias for apprenticeship learning, such that more complex cost function classes will lead to an algorithm with higher sample complexity. Much of the literature on apprenticeship learning has focused on the case where all cost functions can be
described as linear combinations of state features defined by a set ofnfunctionsfi:S7→ ℜ, such
thatc(s) =Pn
i=1w
c
i fi(s). In this case, the expected return of a policy can be defined in terms of the
expected feature counts ¯f, ¯fi=E
Pτ
t=0fi(st)
in the episodic case, and so the worst case regret can
be minimized by minimizing theL1orL2error between ¯f under the agent’s policy, and an empirical
estimate ˆfT of the feature counts under the teacher’s policy.
In[AN04]two algorithms were presented, the max-margin and projection algorithms, which compute the optimal policies for a series of cost functions. These algorithms output a distribution
over the learned policies, such that if the agent first selects a policy from this distribution, and then follows this policy for the duration of an episode, the agent’s expected feature counts ¯f will have a boundedL2error relative to ˆfT. The MWAL algorithm described in[SS08]generates a mixed
policy in a similar fashion, by computing a sequence of optimal polices, but MWAL treats the AL
problem in Equation 2.4 as a two player game, where policy distribution and cost function are the
players’ strategies. In this way, MWAL will return policies that perform better than the teacher’s policy across all cost functions, if such a policy exist for the given cost function class. The LPAL
algorithm described in[Sye08]formulates AL as a linear program instead, and in so doing is able to return a stationary policy that satisfies Equation 2.4.
We note that LPAL requires explicit knowledge of the transition probabilities of the environment,
while MWAL and the projection and max-margin algorithms simply require a means of generating
an optimal policy for a given cost function. When the dynamics of the environment are unknown, these algorithms can call a model-free RL algorithm, such asQ-learning, which finds the policy by interacting with the environment itself. The difficulty is that these algorithms must run the
underlying RL several times, which may be extremely time consuming in complex domains with unknown dynamics. Recent work has shown that apprenticeship learning can be addressed more
directly via policy search. In[Ho16a], the AL problem is solved via a policy gradient algorithm, which directly estimates the gradient of maxc∈C[Jc(π)−Jc(πT)]in terms of the parameters of the agent’s
policy, based on sampled trajectories. A similar approach is taken in[HE16], but the cost function space is nonlinear, and the current cost function is represented by a parametric model learned in
the agent’s current policy.
2.3.2 Inverse Reinforcement Learning
Inverse reinforcement learning can be broadly described as the problem of inferring the cost function being minimized by an agent (the teacher in our case) based on the observed behavior of that
agent. From our perspective, the key distinction between AL and IRL algorithms is the fact that
IRL algorithms produce a final estimate of (or a posterior distribution over) this cost function, whereas AL algorithms only return a policy which matches the teacher’s behavior. IRL algorithms
must therefore make assumptions about the internal reasoning process of the teacher, rather than
simply making assumptions about the space of possible cost functions as in AL. While this can be a disadvantage, we will see in Chapters 5 through 7 that the IRL framework allows us to learn about
the teacher’s reasoning process itself.
In the original formulation of the IRL problem[NR00], it was assumed that the teacher’s policy was optimal with respect to the agent’s cost function, and the learning agent required full knowledge
of the teacher’s policy and the dynamics of the environment to compute the teacher’s cost function. [NR00]also described a simple algorithm for the case where dynamics were unknown, and only demonstrations were available, and returned a cost function which made the teacher’s policy optimal
with respect to a finite set of alternative policies. We note that for the problem of imitation learning, the agent must use its estimate of the teacher’s cost function to compute a policy for the task being
taught. The process used compute the agent’s policy need not be the same as the process it is
assumed the teacher uses to compute their own policy.
In[Ram07], the IRL problem is described as one of Bayesian inference, with a prior distribution defined over cost functions. The Bayesian IRL algorithm assumes that a teacher’s actions are sampled
from a Boltzmann distribution defined by the optimalQ-function values for the given state. This assumption takes into account not only the noise present in a real teacher’s behavior, but also the
possible sub-optimality of the teacher’s policy (the teacher does their best, but it is likely that their
policy is not truly optimal). The Bayesian IRL algorithm uses a version of the Metropolis-Hastings algorithm to sample from the posterior distribution over cost functions, and returns a policy that is
optimal under the mean of these costs. As each step in this sampling process requires recalculating
the optimalQ-function, Bayesian IRL requires a complete model of the transition dynamics. Similar to Bayesian IRL, the gradient IRL approach described in[NS07]assumes that the teacher’s policy is a Boltzmann policy given the optimalQ-function. In that work however, the agent’s policy is parameterized in terms of the underlying cost function, and the error between the agent’s policy and the teacher’s policy is minimized via gradient descent. In computing the gradient, this algorithm
The algorithm we describe in chapter 5 is based on themaximum-likelihoodIRL (ML-IRL) algorithm, which searches for a cost function which maximize the probability of the teacher’s observed actions. Similar to gradient IRL, the version of ML-IRL described in[Vro14]uses gradient ascent find an estimate of the cost function. In ML-IRL however, the teacher is assumed to use
asoftform of value iteration, where the value of a state at each update assumes that actions will be selected randomly according the a Boltzmann distribution based on theQ-values from the previous iteration. Thus, ML-IRL considers the sub-optimal nature of the teacher’s entire planning
process, not only the final action selection. In[ML15], it is noted that when used with a discount factor, and a cost function that depends on actions as well as states, ML-IRL interpolates between
behavioral cloning and inverse reinforcement learning. ML-IRL has also been used to learn multiple
tasks simultaneously in[Bab11], though in that work the goal was distinguish between unlabeled demonstrations of different behaviors, rather than transfer information between demonstrations.
Closely related to maximum likelihood IRL methods aremaximum entropyIRL (ME-IRL) algo-rithms[Zie08; Zie10; BB14]. ME-IRL lies at the intersection of AL and IRL. ME-IRL algorithms search for a policy which maximizes the entropy of the state and action trajectory, while still matching the
teacher’s estimated feature expectations. The policies output by ME-IRL however are defined by a
set of parameters corresponding to the weights of a linear cost function. It has also been shown that the maximum causal entropy formulation of ME-IRL is equivalent to a form of ML-IRL (the causal
entropy formulation takes into account the stochastic nature of transition dynamics). In addition to imitation learning, ME-IRL has been used to predict human behavior, such as the movements
of pedestrians[Zie09b], or the routes drivers will follow[Zie09a]. A number of variants of ME-IRL have been developed for the case where dynamics are unknown. In[BB14], a version of ME-IRL was described that computes the parameter update by performing asoftversion of theQ-learning algorithm under the current cost function, while[Bou11]described relative entropy IRL, which uses a policy gradient algorithm to search for a policy that matches the teacher’s feature expectation, while maximizing the entropy of the trajectory distribution relative to a random baseline policy.
Both AL and IRL algorithms have typically employed or extended various model-free RL
ap-proaches to learn in cases where the dynamics are unknown. There has been work however that performs IRL using learned models of the transition dynamics. In[Abb10]for example, a model of the dynamics of helicopter flight was learned, and then used to infer a cost function for performing
various maneuvers with the helicopter. In that case, however, a great deal of background knowledge was incorporated into the formulation of the parametric dynamics model. As part of this work,
we will describe algorithms that learn a model of the dynamics based not only on direct
observa-tions, but also on the understanding that the dynamics will affect the teacher’s choice of policy. Contemporary work in inverse reinforcement learning has also considered this problem. The SERD
similar ML-IRL algorithm to learn the dynamics, but focuses on the case of learning multiple tasks
simultaneously from a human teacher, and transferring dynamics knowledge between tasks. We also consider cases where dynamics are too complex to model explicitly, and where we must learn
an abstract representation of the teacher’s internal planning process.
2.4
Discussion
The overall goal of this work is to address the key difficulty of interactive learning, namely the limited
amount of training data that a human teacher can provide, by extracting information from a teacher’s communication with an agent that has previously been ignored. In the context of learning from
feedback, we go beyond what has been done previously by learning about the context in which the
agent is being taught at the same time we are learning the task itself. For learning from demonstration, this work does not develop a new approach to the inverse reinforcement learning problem itself,
but instead explores the new question of how an agent can learn about its environment, in addition
CHAPTER
3
SABL: STRATEGY AWARE LEARNING
FROM FEEDBACK
This chapter is taken from:
Loftin, R. et al. "Learning behaviors via human-delivered discrete feedback: modeling implicit feedback strategies to speed up learning".Autonomous Agents and Multi-Agent Systems30.1 (2016), pp. 30-59
In this chapter we will describe the SABL and I-SABL algorithms for learning from human
generated feedback. These algorithms are built on the assumption that different teachers will provide feedback in different ways, which we refer to astraining strategies. Specifically, under different training strategies a teacher may prefer to give postive feedback more so than negative
feedback, or vise-versa. We will see that when a teacher prefers one form of feedback over the other, they may use the lack of explicit feedback to communicate with the agent. To learn from such implicit
feedback, we develop the SABL algorithm, which relies on a probabilistic model of the dependence
of a teacher’s feedback on both their training strategy and the task they are teaching the agent to perform. Because the teacher’s strategy will generally be unknown, we extend SABL with the I-SABL
algorithm, which can infer the teacher’s strategy online, based on the explicit feedback the agent has received, and use that knowledge to properly interpret the lack of feedback. In Chapter 4, we
from evaluative feedback.
3.1
Behaviorism
The notion that trainers may follow different strategies while teaching is motivated by work on
behaviorismand techniques for animal training using punishment and reward. Behaviorism, a field of psychology, considers how animals and humans learn from positive and negative feedback. Skinner introduced operant conditioning, a concept of providing feedback to modify the frequency
of voluntary behaviors[Ski38]. There are a number of ways in which punishment and reward can be combined to teach a behavior. These so-calledoperant conditioning paradigmscan be grouped into four categories[Ski53]: positive reward (R+), negative reward (R−), positive punishment (P+), and negative punishment (P−). Here, reward refers to any stimulus that would increase the frequency of an associated behavior, while punishment would be a stimulus that decreases the frequency
of a behavior. Positive refers to adding a stimulus and negative refers to removing a stimulus. An
example of R+would be the act of giving a dog a treat (reward by adding a desirable stimulus). An example of P−would be the removal of a prized toy (punishment by removing a desirable stimulus).
Thus, both positive and negative reward encourage an associated behavior, while both positive and
negative punishment discourage an associated behavior.
Dog trainers have learned that using only positive reward (R+) to encourage desired behaviors
results in fewer unintended side effects for dogs than when positive punishment (P+) is used to
reduce undesired behavior[Hib04]. We hypothesize that, in many cases, users will tend to apply this concept when training virtual agents (even if they don’t realize they are doing it). We will show how,
in situations where users do have a bias towards R+/P−operant conditioning paradigms, learning algorithms that take these strategies into account have a significant advantage when learning from human trainers.
3.2
Training Strategies
In this work, we use an idealized model of the training process, in which the learning agent takes a
single action, and thenmayreceive positive or negative feedback from the trainer. We hypothesize that different trainers can differ in how they provide feedback, even when teaching the same behavior. For example, when the learner takes a correct action, one trainer might provide an explicit positive
feedback while, another might provide no response at all.
Table 3.1Breakdown of the training strategies observed in our web-based user studies.
Strategy Number of Training Sessions Exhibiting Strategy
balanced feedback 93
reward-focused 125
punishment-focused 6
inactive 3
response for correct actions and explicit punishment for incorrect ones. Aninactivestrategy rarely gives explicit feedback of either type (making it impractical). Under a reward-focused strategy, the
lack of feedback can be interpreted as animplicitnegative feedback, while under a punishment-focused strategy, it can be interpreted as being implicitly positive.To a strategy-aware learner, the
lack of feedback can be as informative as explicit feedback.
These strategies roughly correspond to the operant conditioning paradigms described in the behaviorism literature. A balanced feedback strategy would correspond to a R+/P+paradigm, where both explicit punishment and explicit reward are used. A reward-focused strategy would roughly
correspond to a R+/P−paradigm, while a punishment-focused strategy would correspond to a R−/P+paradigm. An inactive strategy would correspond to a R−/P−paradigm.
We conducted three web-based users studies (see Chapter 4) as part of this work, in which each
participant went through one or more training sessions where they attempted to teach a virtual agent to perform a simple behavior. Table 3.1 shows the number of training sessions, from the first
two of these studies, in which each of these four types of strategies was used. A user was classified as balanced if she gave explicit feedback for correct and incorrect actions more than half of the time,
while inactive means she gave explicit feedback less than half the time in both cases. Reward-focused
means correct actions received explicit feedback more than half the time and incorrect actions received it less than half the time; punishment-focused is the opposite case. Note that all four types
were employed, but that a large percentage of users followed a reward-focused strategy. We provide
this sample of results here to help emphasize the point that human trainers do follow a variety of training strategies.
3.3
Probabilistic Model of Training Strategies
One of the main contributions of this work is a formal, probabilistic model of trainer feedback. We will use this model both to characterize the strategies followed by users in the studies we describe in
Chapter 4, and more significantly, to build learning algorithms which use probabilistic inference to
identify target behaviors, while taking into account the trainer’s strategy.