© 2018 IJSRCSEIT | Volume 3 | Issue 4 | ISSN : 2456-3307
Multi-Topic Tweet Stream Summarization Based on Tweet
Vector Clustering
1Yashashri Pahade, 1Prajakta Bhagat, 1Payal Bele, 1Rohini Talokar, 2Prof. Dinesh V. Jamthe 1BE Scholar, Department of Computer Science & Engineering Priyadarshini Bhagwati College of Engineering,
Nagpur, Maharashtra, India
2Assistant Professor, Department of Computer Science & Engineering, Priyadarshini Bhagwati College of
Engineering, Nagpur, Maharashtra, India
ABSTRACT
Immense volume of short messages that is tweets are being shared among various clients and information on long range informal communication locales and microblogging destinations, for example, Twitter, Facebook and so forth. Twitter gets more than 400 million tweets for every day. Constant examination is extremely troublesome and testing undertaking on such gigantic information likewise questioning and recovery of information is additionally troublesome. Such a huge number of tweets contain colossal measure of commotion and repetition. Existing frameworks were generally chipped away at the static and the constrained information. The different existing frameworks were proposed to address these issues and furthermore they gave some arrangement. Summarization is the way toward involving a content document in such way that short summary produced by using the essential keywords of the first document. There is need of dynamic way to deal with condense information delivered by Twitter feeds. This paper proposes the novel method, which produce the significant substance based summery inside less measure of time. Especially, in the proposed framework multi-subject summarization is performed on the online dataset which thusly require the less measure of time when contrasted with the other existing framework. So time productivity is improved by using the proposed framework.
Keywords: Tweet Stream, Continuous Summarization, Tweet Clustering, Summary, Timeline
I.
INTRODUCTION
Twitter has turned into a basic wellspring of data. Twitter is a microblogging website began in 2006 has turned out to be extraordinary prevalence, for example, Twitter, Facebook and so forth. Individuals post different remarks on occasions occurring the world over. In February 2011, Twitter had 200 million enlisted clients and 25 billion tweets in all of 2010. Tweets, in their crude shape, while being instructive, can likewise be colossal. The looking for an intriguing issue may yield a large number of tweets, traversing weeks. The client superfluously experiences the huge number of tweets and it is
increments, and as a result of the amount of information is expanding, there is a need programmed summarization. This innovation makes utilization of a lucid summary, for example, length, style of composing and language structure. Machine learning and information mining in which programmed information summarization is a critical territory. These summarization innovations are generally utilized today, in countless enterprises. Here are a few cases of web crawlers in which summarization methods are utilized, for example, Twitter, Facebook, and google and so on. Other classification incorporates document summarization, picture gathering summarization and video summarization. The principle thought behind summarization is to look through an agent and normal subset of the information, which speak to exceptional data of the whole set. Document summarization, tries to consequently make an agent summary or dynamic of the whole document, by finding the most educational sentences. Thus, in picture summarization the framework finds the most illustrative and imperative (or remarkable) pictures. For tweet summarization for the most part document summarization strategy is utilized.
Two kinds of programmed summarization
approaches: extraction and reflection. The extractive summarization distinguishes important sentences that have a place with the summary. In extraction based summarization assignment, the programmed framework removes objects from the whole accumulation, without adjusting the articles itself. Cases of this incorporate key expression extraction, where the objective is to choose singular words or expressions to "tag" a document and The objective of document summarization is to choose entire sentences (without changing them) to make a short section summary. So also, in picture gathering summarization, the framework separates pictures from the accumulation without adjusting the pictures themselves. Then again, deliberation based summarization assignment, includes rewording areas
of the source document. When all is said in done, reflection can gather a content more emphatically than extraction, however the projects which can do this are harder to create as they require the utilization of common dialect age innovation, which itself is a developing field. The gathering of comparable tweets shapes distinctive bunches. These bunches utilized for summarization of tweet streams. Abridging is characterized as lessens the measure of substance and show which specific theme is examined on social destinations. Top tweets are discovered from bunches by utilizing positioning calculation.
Conventional document summarization strategies are not compelling for huge size tweets and in addition not reasonably material for tweets which are arrived quick and continuously. To overwhelm this issue tweet summarization is requires which ought to have new usefulness fundamentally not the same as conventional summarization. Tweet summarization needs to think about the worldly element of the arriving tweets.
Stemming is the term utilized as a part of etymological morphology and data recovery to depict the procedure for diminishing curved (or now and again determined) words to their oath stem, base or root frame by and large a composed word shape. The stem require not be indistinguishable to the morphological foundation of the word; it is generally adequate that related words guide to a similar stem, regardless of whether this stem isn't in itself a legitimate root. Calculations for stemming have been considered in software engineering since the 1960s. Numerous web crawlers treat words with an indistinguishable originate from equivalent words as a sort of inquiry development, a procedure called conation.
the fact that stop words as a rule allude to the most widely recognized words in a dialect, there is no single widespread rundown of stop words utilized by all regular dialect preparing instruments, and to be sure not all devices even utilize such a rundown. A few instruments particularly abstain from evacuating these stop words to help state seek.
Consider case of Apple tweets. A tweet summarization framework will screen Apple related tweets which are created an ongoing timeline of the tweet stream. Given a timeline go, the document framework may produce a progression of current time outlines to feature focuses where the point or subtopics developed in the stream. Such a framework will adequately empower the client to learn significant news or exchange identified with Apple without reading through the whole tweet stream.
II.
LITERATURE SURVEY
Tweet summarization incorporates two phases. Introductory advance requires tweet information clustering and after that summarization is performed.
A twitter post is at most 140 characters in length and here we consider English posts. The twitter posts are casual, non-standard spelling and as often as possible do not have any accentuation. The crossover TF-IDF based calculation [2] utilized for multi-post synopses of twitter post. Here are some document summarization approaches are clarified. Arbitrary Summarizer is an approach which haphazardly chooses k posts or every subject as summary. This strategy was helpful keeping in mind the end goal to give most pessimistic scenario execution and furthermore set the lower bound of execution. Latest Summarizer approach picks the latest k posts as a summary from the determination pool. It can pick the initial segment of a news article as summary. This approach is executed in light of the fact that the smart summarizers can't perform superior to
straightforward summarizer. This summarizer just uses the initial segment of the document as summary.
Calculation for stream information clustering has been broadly examined by different creators in writing. BIRCH is the adjusted iterative diminishing and clustering utilizing progressions' calculation. This calculation is an unsupervised information mining calculation [5]. It is utilized to perform various leveled clustering over expansive informational collections. Favorable position of BIRCH is that, it has capacity to make groups in augmentation and dynamic way to incoming information focuses. This calculation handles commotion successfully and reasonable for extensive databases. It uses estimation that catches the characteristic closeness of information. This estimation put away and refreshed in stature adjusted tree.
Twitter is a decent stage for individuals to express their conclusions. The tweets are available in colossal volume, it require part of push to comprehend what occurs inside occasions. Here new technique for outlining occasions that endeavors great journalists and produces live game updates from Twitter posts on occasions. Great journalists chose illustrative tweets from dominant part of non-educational tweets[4].
Constant occasion summarization [6] give data about occasion at whatever point any sub-occasions happen. This strategy is a two stage procedure to detailing sub-occasions happen. In initial step is to identify sub-occasions as of late happen and in second step tweets about sub-occasions are chosen. In the wake of consolidating these two stages we get summary of amusement from set of tweets.
LexRank. This is happens on the grounds that it semantic learning. TextRank calculation is diagram based approach used to discover top positioned sentences. TextRank incorporates the entire many-sided quality of the diagram as opposed to simply match shrewd likenesses.
ETS (Evolutionary Timeline Summarization) [3] is a web mining administration which creates timelines for huge measure of information. ETS gives developmental directions on specific dates. ETS gives outlines as indicated by score of timeline characteristics. The preferred standpoint is that it encourages quick news perusing and learning understanding. ETS errand as an adjusted enhancement issue by means of iterative substitution.
LexRank [8] summarizer utilizes a chart based strategy. It recognizes pairwise likeness between two sentences or between two posts. It influences the closeness to score that is the heaviness of the edge between the two sentences. The last score of posts is processed in view of the weights of the edges that are associated with each other. This summarizer is useful to give summarization in light of standard to chart rather than coordinate recurrence summarization. Despite the fact that it depends on recurrence, this framework utilizes the connections among sentences to include more data. This is more perplexing calculation than recurrence based calculation
Twitter streams additionally utilized for occasion summarization to speak to data in live way. The member based approach is utilized for occasion summarization. The key segments utilized for summarization are Participant Detection, Sub-occasion Detection and Summary Tweet Extraction. Member identification distinguishes occasion
members. Member implies individual take an interest in occasions. Sub-occasion discovery recognizes sub-occasions identified with members. The tweets are removed from sub-occasions utilizing Summary Tweet Extraction segment [7].
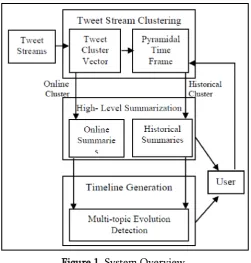
Zhenhua Wang et al. present a summarization structure called Sumblr. This is the continuous summarization by stream clustering. Continuous summarization is troublesome errand as it contains expansive number of boisterous and excess tweets. This is the principal which contemplated continuous tweet stream summarization. This system comprises of three principle parts, in particular the Tweet Stream Clustering module, the High-level Summarization module and the Timeline Generation module. Sumblr is helpful to take a shot at dynamic, quick arriving, and expansive scale tweet streams [9].
I. PROPOSED APPROACH
Actualizing continuous tweet stream summarization isn't a simple undertaking, since countless are good for nothing, immaterial and uproarious in nature, because of the social idea of tweeting. Tweets are unequivocally related with their posted time and new tweets have a tendency to touch base at a quick rate. Tweet streams are constantly substantial in scale; consequently the summarization calculation ought to be exceptionally effective. It ought to give tweet synopses of self-assertive time spans. It ought to naturally identify sub-theme changes and the minutes that they happen. This paper proposes a multi subject rendition of a continuous tweet stream summarization structure, to be specific Sumbler to create rundowns and timelines with regards to streams and assess it on more total and substantial scale informational collections.
incremental clustering is utilized to keep up tweets in online form. The theme based tweet stream is given, it can productively bunch the tweets and keep up reduced group data. The abnormal state summarization module gives two sorts of synopses: on the web and recorded rundowns. An online summary portrays what is as of now examined among people in general. Along these lines, the contribution for creating on the web synopses is recovered specifically from the present bunches kept up in memory. Then again, a verifiable summary enables individuals to comprehend the fundamental happenings amid a particular period, which implies we have to dispense with the impact of tweet substance from the outside of that period. Thus, recovery of the required data for creating authentic outlines is more entangled. The center of the timeline age module is a multi-subject development recognition calculation which delivers ongoing and run timelines likewise.
Figure 1. System Overview
III.
IMPLEMENTATION
Algorithm 1: Multi-topic version of Sumblr
Input: Multiple tweets (online or dataset), Number of cluster k;
Output: Summary of Multiple Topic
Process:
1. While! topic.end () do 2. Topic t= topic.next ();
3. Study continuous tweet stream summarization.
4. For Tweet Stream Clustering module run Algorithm 2
5. Input the clusters CL generate using Algorithm 2 to Algorithm 3
6. For High-level Summarization module run Algorithm 3
7. For Timeline Generation modules run Algorithm 4.
8. Get the output of algorithm as Summary of multiple Topics.
9. END
Algorithm 2: Tweet Stream Clustering Input: a cluster set C_set
1. While! stream.end () do 2. Tweet t= stream.next ();
3. Choose Cp in C_ set whose centroid is the closest to t;
4. If MaxSim (t) < MBS then 5. Create new Cluster Cnew = {t} 6. C_set.add (Cnew)
7. Else
8. update Cp with t
9. If TScurrent%(αi) == 0 then 10. Store C-set into PTF.
Algorithm 3: TCV-Rank Summarization Input: a cluster set D(c)
Output: a summary set S 1. S= ∅, T= All tweets
2. Build a similarity graph on T; 3. Compute LexRank scores LR;
4. Tc = tweets with the highest LR in each cluster;
5. While | S |< L do
6. For each tweet ti in Tc − S do 7. Calculateυi;
9. S.add(tmax); 10. While | S |< L do
11. for each tweet ti’ in T-S do 12. Calculate υ 0 i;
13. Select t 0 max with the highest υ 0 i ; 14. S.add(t 0 max);
15. Return S;
Algorithm 4: Topic Evolution Detection Input: tweet stream binned by time units Output: timeline node set TN
1. TN =∅;
2. Whilestream.end() do 3. Bin Ci = stream.next(); 4. If hasLargeVariation() then 5. TN.add(i);
6. Return TN;
IV.
RESULT ANALYSIS
Figure 2 shows time comparison between Sumbler with single topic and Sumbler with multiple topic. Sumbler with single topic required more time than the Sumbler with multiple topic.
Figure 2. Time Comparison
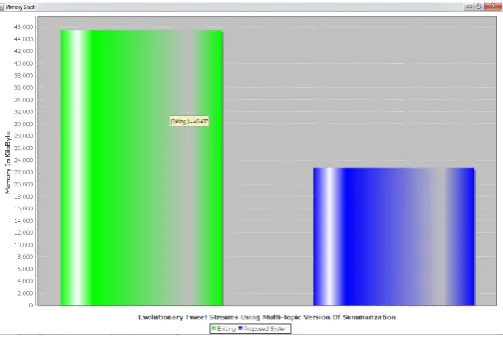
Figure 3 shows memory comparison. Existing system required more CPU utilization compare to proposed system. Above graph shows the memory comparison between the systems.
Figure 3. Memory Comparison
V.
CONCLUSIONS
The examination of different methodologies for document summarization, for example, sifting and tweet summarization is finished. These methodologies are utilized for overseeing tremendous measure of tweets. Sifting isn't an effective approach in light of twitter information is uproarious and excess. As a result of the summarization is utilized to compress the tweet information. Customary document summarization strategies are not viable for enormous size tweets and additionally not appropriately pertinent for tweets which are arrived quick and continuously, likewise they are not center around static and little scale informational index. To conquer this issue, a multi subject adaptation of a continuous tweet stream summarization system, to be specific Sumbler is created to produce rundowns and timelines with regards to streams and assess it on more entire and substantial scale informational indexes, which manages dynamic, quick arriving, and expansive scale tweet streams. Our approach will finds the changing dates and timelines progressively amid the
procedure of continuous summarization.
VI.
REFERENCES
[1].Prof R. Mihalcea and P. Tarau, "TextRank: Bringing order into texts," in EMNLP. Barcelona: ACL, 2004, pp. 404–411.
[2].David Inouye and Jugal K. Kalita, "Comparing Twitter Summarization Algorithms for Multiple Post Summaries", IEEE Trans. Knowl. Data Eng., 23(8):1200–1214, 2011.
[3].R. Yan, X. Wan, J. Otterbacher, L. Kong, X. Li, and Y. Zhang, "Evolutionary timeline summarization: A balanced optimization framework via iterative substitution," in Proc. 34th Int. ACM SIGIR Conf. Res. Develop. Inf. Retrieval, 2011, pp. 745–754.
[4].Mitsumasa Kubo, Ryohei Sasano, Hiroya Takamura, and Manabu Okumura, "Generating Live Sports Updates from Twitter by Finding Good Reporters," in IEEE,2013.
[5].T. Zhang, R. Ramakrishnan, and M. Livny, "BIRCH: An efficient data clustering method for very large databases," in Proc. ACM SIGMOD Int. sConf. Manage. Data, 1996, pp. 103–114. [6].Arkaitz Zubiaga, Damiano Spina, Enrique Amigó
and Julio Gonzalo,"Towards Real-Time Summarization of Scheduled Events from Twitter Streams", in Proc. 23rd ACM Conf. Hypertext Social Media,2012.
[7].C. Shen, F. Liu, F. Weng, and T. Li, "A participant-based approach for event summarization using twitter streams," in Proc. Human Lang. Technol. Annu. Conf. North Amer. Chapter Assoc. Comput. Linguistics, 2013, pp. 1152–1162.
[8].G. Erkan and D. Radev, "Lexrank: graph-based centrality as salience in text summarization," Journal of Artificial Intelligence Research, vol. 22, pp. 457–480, 2004.