A unified system for accessing typological databases
Paola Monachesi
∗, Alexis Dimitriadis
∗, Rob Goedemans
†,
Anne-Marie Mineur
∗∗Utrecht University, Uil-OTS
Trans 10, 3512 JK Utrecht, The Netherlands
{Paola.Monachesi, Alexis.Dimitriadis, Anne-Marie.Mineur}@let.uu.nl
†Leiden University
Leiden, The Netherlands [email protected]
Abstract
We present the goals and architecture of the Typological Database System, a project for the creation of a unified interface to numerous independently developed typological databases. The aim of the project is to develop a software system that allows a user to simultaneously query different databases through a single interface. The challenge of the project lies in the variability of the included data. In order to overcome the diversity, the system relies on detailed formal descriptions (metadata), prepared in advance and describing in detail the structure and content of each component database. The metadata is used to match a user’s query against the capabilities of the component databases.
1.
Introduction
Typology, the study of the variation that language ex-hibits, is one of the most important and interesting fields within linguistics. Typological databases are a valuable tool for this enterprise, and numerous typological databases have been developed by researchers in the field, often for personal or small-group use. Increasingly, these databases are being made available to the linguistic community over the Internet, providing the potential for enormous increases in the power of exploratory typological investigation. How-ever, these databases can be quite heterogeneous. A typolo-gist seeking information on a particular subject may find parts of it scattered over several databases, organized in various forms and expressed in ways that reflect different research traditions. As the number of potentially relevant databases increases, so does the amount of effort required by a user to locate them, understand how they are orga-nized, figure out the query system and perform a query, and interpret the results.
The aim of the Typological Database System (TDS) project is to facilitate this process, by developing a soft-ware system that allows a user to simultaneously query many different typological databases through a single in-terface. This system, which is currently under development, will reside on a server computer that a user can query over the internet by use of a standard web browser. The compo-nent databases can in principle reside in separate, remote servers, although for performance reasons the server may need to maintain local copies of some or all of them. By ac-cessing the single gateway site, the user will gain access to the data contained in all the databases participating in the project. The goal is for the system to behave as much as possible like a single, virtual database.
The TDS project (http://www-uilots.let.uu.nl/td/ ) is be-ing carried out by a research group in the Netherlands Grad-uate School of Linguistics (LOT), with members represent-ing the Universities of Amsterdam, Leiden, Nijmegen and
Utrecht. A number of typological databases developed by participating researchers constitute the initial components of the TDS, and have been providing us with concrete ex-perience of the problems that need to be addressed.
2.
Exploring multiple typological databases
The problem of managing and presenting information becomes ever more important as the information available on the internet grows (Abiteboul et al., 2000). As more ty-pological databases become accessible to users other than their creators, colleagues, and others already familiar with them, the following tasks become more challenging:
1. Resource discovery. This is simply the step of finding a datasource that contains information on some given topic.
2. Correct and effective use. As we have stated, databases use varying terminology, notation, organiza-tion of the data, and search commands. Even if these are documented in detail, they can be quite difficult for a new user to assimilate and employ properly.
3. Efficiency of resource utilization. As the amount of online information grows, the time and effort involved in searching databases one by one and collating the re-sults becomes an obstacle to their efficient utilization.
The first of these problems is being addressed by var-ious initiatives that are currently developing standards for resource description and discovery, including the Dublic Core Metadata Initiative (general) (Dublin, n.d.), the Open Language Archives Community initiative (linguistics spe-cific metadata and harvesting protocol) (OLAC, n.d.), and the International Standards in Language Engineering (ISLE, n.d.) metadata initiative.
V27 PRED ADJ AGR
Predicative adjs agree with the subj in nb and/or gender V106 ATTR ADJ AGR CASE
Attributive adjs agree with their nominal heads in case V456 VERB FLEX SUBJ
Finite verbs agree with their subjects V469 FLEX ORDER = VERB-TMA-X
In a V the morpheme order is Stem-Tense/Mood/Aspect-Agr V475 DEF ART
Finite verbs agree with their subjects V469 FLEX ORDER = VERB-TMA-X
In a V the morpheme order is Stem-Tense/Mood/Aspect-Agr V475 DEF ART
The definite article is obligatory
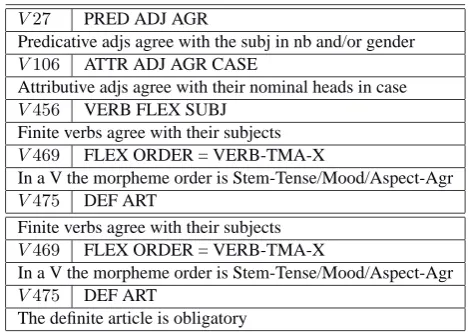
Table 1: Example from the Typological Database Nijemegen
much as possible a consistent interface, terminology, and command language. The results will be summarized and perhaps transformed for more efficient presentation. The TDS project will explore the limits of combining diverse databases and presenting them as a unified virtual database.
3.
The component databases
Several databases developed by participating researches constitute the core of the TDS project and have provided us with concrete experience of the problems that need to be addressed. In the rest of this section we provide a brief description of the component databases.
• Stresstyp database (University of Leiden). This
database encodes information about the stress system of 500 languages. It contains both analytic data and examples. Software: 4th dimension.
• Word order database (University of Amsterdam).
The database contains analytic data about word order for 150 languages. Software: Microsoft Access.
• Person Agreement Database (University of Amster-dam and Lancaster University). The database
con-tains analytic data about agreement for 400 languages which constitute a balanced sample of all the lan-guages of the world. Software: Microsoft Access.
• Typological Database Nijmegen (University of Nij-megen). The database contains analytic data on
var-ious topics including basic word order, intransi-tive predication, case marking, temporal sequencing, relative clause formation, comparatives, possessive constructions, verbal morphology, tense/aspect, noun phrase coordination, manner adverb encoding, verbal derivation. The number of languages varies from topic to topic, with a minimum of 140 for all topics, and a maximum of 410 for some topics. Software: MS Ac-cess.
• Spinoza database (University of Nijmegen/Leiden).
The database will encode information about 100 languages. Ortographic, phonological, morphological and syntactic information is provided. It is a database
of sample sentences annotated with glosses and trans-lations. An analytical component is currently being developed. Software: Microsoft Access.
• Anaphora database (Utrecht University). This
database contains exhaustive descriptive information on the linguistic behavior of anaphors (i.e., reflexives and reciprocals). It includes some information on or-dinary pronouns, and general descriptive information on each language. The information will be limited to a relatively small, but typologically diverse sample of approximately 50 languages. It contains both analytic data and examples. Software: SQL server.
• Aspect database (Utrecht University). The database
will contain in-depth information on about 25 lan-guages (mainly Slavic, Romance and Germanic). The data consists of collected examples (which will be an-notated) and text articles about (sets of) examples, covering the field of aspect and related areas like tense, quantification and argument structure. Software: SQL server.
• Inflection/agreement database (Utrecht Univer-sity). The database focuses on agreement morphology
in a number of typologically distinct languages, and its relation to the occurrence of empty subjects, empty objects and the syntactic position of the verb in the clause. Software: SQL server.
4.
Obstacles to combining the databases
The aim of the TDS project is to combine diverse databases (including the ones discussed above) and present them as a unified virtual database. The challenge lies in the great heterogeneity of the included data. The diversity can be of several types.
Diversity of content type Typological databases consist mostly of logical variables describing each language as a whole. Table 1 illustrates a fragment of the Typological
Database Nijmegen which employes variables to encode
Text line: 1 Representations
Orthographic Njadi nuna j`aka na-laku-ka i Umbu Ndilu n`ahu la woka Phonemic ndj\adi nuna dj\Aka na=laku=ka=l Umbu Ndilu nAhu la wOka Morphological njadi nu-na j`aka na=laku=ka i Umbu Ndilu n`ahu la woka
Morphological Gloss thus DEM-3s if/when 3sNom=go=PFV DEF lord male.name LOC garden Idiomatic So, that one, when Umbu Ndilu goes to the garden
Table 2: Example from the Spinoza Database
However, several of the component databases in this project contain example sentences with detailed annota-tions, as can be seen in table 2 which contains an example from the Spinoza database with several levels of descrip-tion. The ultimate goal of the project is to integrate different types of content so that, for example, a single query could return both examples and logical variables as an answer.
Diversity of theoretical commitments Because there is no single, universally accepted, and exhaustive linguistic theory, the information in the various databases reflects the analytical and theoretical commitments of its creators. A linguist can recognize the descriptive content of a state-ment based on identifiable assumptions. The TDS project will place a high priority on preserving and making visible the framework of assumptions that will allow a (linguist) user to properly interpret any data extracted from a compo-nent database.
Diversity in form In many cases the different databases use equivalent, or near-equivalent, ways of describing data. One obvious example is the use of different abbreviations for broadly accepted linguistic notions, such as accusative or plural. There is also great variation in the choice of ab-breviations used to label properties such as part of speech, gender and agreement features, etc. It is generally easy to reconcile purely notational differences, but the definitions of such notions can also differ in their details. It is thus nec-essary to establish guidelines for distinguishing notational variation from theoretically important differences, and to normalize the data with respect to the former but not the latter.
Different design choices Beyond purely notational is-sues, there are many ways to organize a given body of in-formation into a database. The decisions made by the cre-ators of various databases in organizing similar information introduce an additional element of variation that must be compensated for.
Different software Databases are embedded in various database management systems (DBMSs) representing dif-ferent generations of software and adhering to difdif-ferent conventions: SPSS, SQL Server, Access, 4th Dimension, custom-made database engines, etc.
Consultations with the community of prospective users have established that the preservation of the specific claims made by the creators of the individual databases is of the ut-most importance. Extensive normalization of the collected data into a common form would result in unacceptable dis-tortion. Therefore a major focus of research will be the question of how to best strike a balance between
improv-ing usability and preservimprov-ing the reliability of the collected information.
5.
The architecture of the system
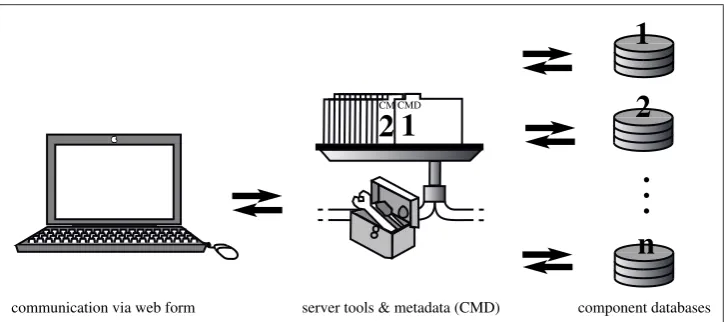
Figure 1 shows the general structure of the Typological Database System (TDS). Its core component is a database server that acts as an intermediary between the user and the component databases. Communication between the user and the central component is performed exclusively via a web interface. The protocol that is used to communi-cate with the various databases depends on the type of the database, but the user is not aware of that: the translation of the user query into the proper format is performed at the server. From the user’s perspective, the system behaves as a single but very heterogeneous database.
The system relies on detailed formal descriptions
(con-tent metadata), prepared in advance and describing in
de-tail the structure and content of each component database. The server stores a separate set of content metadata (CMD in the diagram) for each database, which is used to match a user’s query against the capabilities of the component databases. The TDS will then transform the user’s query into queries suitable to the one or more databases found to contain relevant information, submit the queries to the appropriate databases, collect their responses, and present them to the user.
Once the query is dispatched to the relevant databases, the metadata can again be used to partially transform the results into a more consistent format, or to aid various types of aggregation.
5.1. From query to answer
We now consider the steps that will take place during the processing of a user query. Their execution relies on the presence of detailed metadata (discussed in more detail in section 6.), which has been prepared in advance and de-scribes the component databases in all the relevant respects.
1. Generate a user query. The user creates a query through an HTML form or applet downloaded to his or her browser. This query is then submitted to the server for processing. An interactive process of query refine-ment is envisioned, as discussed in section 7. The sys-tem could also provide multiple interfaces tailored to different skill levels and requirements.
1
2
..
.
n
communication via web form server tools & metadata (CMD) component databases
1
CMD CM2
Figure 1: The Typological Database System (TDS)
3. Translate query into forms suitable to each
database. The system needs to know where in a
com-ponent database the desired information is stored; if particular values are being sought, it must also know how the desired value is represented in each database. This information is provided by the content metadata, which must describe in detail the structure and seman-tics of each field in each component database.
4. Interact with the database servers. The server will transmit the transformed queries to those servers con-taining relevant information, and wait for their re-sponse. This step is entirely dependent on communi-cation protocols: For example, communicommuni-cation with an SQL Server database, or over an HTTP port. Although it is of course essential to the operation of the TDS, it is primarily a matter of supporting the appropriate communication protocols.1
5. Translate results and present to the user. This step might involve changing the encoding or vocabulary used in the results, as well as merging responses from different databases. In the simplest case, this step could do nothing: results are simply presented as they are received. i.e., in database format. More compli-cated transformations will be aided by the content metadata, which tells us, for example, how to interpret the value 0 or 1 in a certain field of some database. In order to ensure that the reliability of the retrieved information is not endangered by the transformation process, the system will be very conservative in this respect.
6.
The metadata
The heart of the TDS is the content metadata, which de-scribes the component databases to the central component and allows queries to be matched to databases. For each
1
Since the TDS will interact with multiple remote databases, the system must be able to support parallel queries, and be able to respond properly even if some of the databases fail to respond. But these issues are completely independent of the linguistic content of the databases, and will not be further discussed here.
field in a database, the metadata must provide the follow-ing information:
1. Its location. This is provided by means of a key (i.e., a field name or column number) that identifies its lo-cation in the database and thus allows its retrieval.
2. Its subject matter. For example, the system must know that the field named V27 contains information on whether a language allows null subjects.
3. Its encoding. For example, that a 0 value in V27 means that null subjects are disallowed, and a 1 that they are allowed.
The first and third of these are more or less present in the system catalog (data dictionary) of the component databases, since the system catalog of every database in-cludes information about the name, location, and data type of each variable in it. The “subject matter” of the variables is another matter: In order for the TDS to logically combine diverse databases, it must know when variables in differ-ent databases contain information about the same subject matter. To achieve this, the meaning of each variable will be defined in terms of a standardized linguistic vocabulary, whose development is a major part of the linguistic aspect of the TDS project.
We refer to the standard linguistic vocabulary, some-what confusingly, as the linguistic metalanguage. The met-alanguage will contain a general dictionary of linguistic ter-minology, alternative terms or near-synonyms with a de-scription of their relationship to the preferred terms, gloss-ing standards, and database specific terminology.
The linguistic metalanguage is the core element of the content metadata. The content metadata for each database must describe the subject matter of each field in terms of the metalanguage. We discuss this in more detail in section 6.2.
6.1. The linguistic “metalanguage”
The metalanguage needs to satisfy some important con-ditions:
able via the individual interfaces.2For the same reason, the
system should provide some means of browsing the full set of variables for more powerful query construction. This can take advantage of the available content metadata to al-low searches (or browsing) over the variable lists: the user should be able to ask which variables have to do with sub-jects, and be referred to variables related to a non-standard category (e.g., “Agent-like argument of a transitive verb”) employed by a component database.
Finally, these features can be combined with an inter-active process of query refinement as suggested in the pre-vious section: the user is presented with the set of search terms provided by the unified interface, or types in unre-stricted search terms. In either case, the user’s selection is then matched against the metadata describing the contents of the component databases, and the user is presented with a list of near-matches. The user then constructs a query that requests information actually present in one or more databases.
8.
Conclusion
The aim of the Typological Database System project is the creation of a unified interface to numerous indepen-dently developed typological databases which will allow the user to simultaneously query them from a single gate-way. By accessing the single gateway site, the user gains ac-cess to the data contained in all the databases participating in the project. This aim must be achieved while preserving the integrity of the data; among other things, the user must be able to trace how the information was obtained and what its source is.
The TDS will be part of a Language Typology Resource
Centre (LTRC), a web-accessible electronic archive for
ty-pological description including tyty-pological databases, cor-pora, and grammars. The initial steps in developing such an archive are being made in the context of the research net-work Language Typology Resource Centre that is funded by the EC for 2001–2004. The LTRC will promote the de-velopment of standards in typological description, and will make available knowledge and resources for developing ty-pological databases.
9.
References
Serge Abiteboul, Peter Buneman, and Dan Suciu. 2000.
Data on the Web: From Relations to Semistructured Data and XML. Morgan Kaufman, San Francisco.
Dik Bakker, Osten Dahl, Martin Haspelmath, Maria¨ Koptjevskaja-Tamm, Christian Lehmann, and Anna Siewierska. 1993. EUROTYPguidelines. Technical re-port, European Science Foundation Programme in Lan-guage Typology.
2We recognize that it may not be possible to adapt all of the
content of the component databases into the standardized format. The design goal is satisfied by ensuring that the unified inter-face provides ways to bypass the standardized format, querying directly the variables native to each database. For example, even if the standard vocabulary only provides a notion subject, the user should still be able to search for S or A in those databases that make use of the notion.
Bernard Comrie. 1989. Language Universals and
Linguis-tic Typology. The U. of Chicago Press, second edition.
Dublin core metadata initiative. Web page,
http://dublincore.org/.
Barbara F. Grimes, editor. 2000. Ethnologue. SIL, Dal-las, 14th edition. Online version:
http://www.ethno-logue.com/.
International standards in language engineering (ISLE). Web site, http://www.mpi.nl/world/ISLE/.
Open language archives community (OLAC). Web site,
http://www.language-archives.com/.
Typological database system (TDS). Web site, Typological