ABSTRACT
DIRSCHERL, HAYLEY LAUREN. The Major Histocompatibility Complex Class I Genes of Zebrafish. (Under the direction of Dr. Jeffrey A. Yoder).
While the genes of the major histocompatibility complex (MHC) were named after the discovery that they encode the primary antigens responsible for determining transplant compatibility, MHC molecules also play a central role in adaptive immunity through
presenting antigens to T cells. Mammalian MHC class I molecules present cytosolic antigens to CD8+ cytotoxic T cells and serve as inhibitory ligands to natural killer (NK) cells. MHC class I genes can be classified as classical or nonclassical where the classical MHC class I genes encode molecules that present antigens to T cells, are highly polymorphic, and are ubiquitously expressed. The nonclassical MHC class I genes encode molecules that are structurally similar to classical molecules but exhibit different functions, have low-level polymorphism, and display tissue-specific expression.
Genes encoding MHC class I molecules have been identified in all jawed vertebrate species examined, including cartilaginous fish, but are absent from jawless fish. After the MHC had been described in several mammalian species, researchers became interested in identifying orthologous genes in bony fish, or teleosts, in order to gain perspective on the evolutionary origins of adaptive immunity. Zebrafish provide an ideal animal model in which to study the MHC class I genes as they have a complete reference genome, though the
description of all the zebrafish MHC class I genes is incomplete. The goal of this research was to characterize the sequence diversity of the zebrafish MHC class I genes and
hypothesize about the functional consequences of this diversity.
lineage proteins are predicted to bind peptides in a manner similar to mammalian classical MHC class I. Zebrafish encode a U lineage locus on chromosome 19 that displays significant haplotypic variation and is the only zebrafish locus that shares conserved synteny with the mammalian MHC core locus. In chapter 3, two additional MHC class I U lineage genes encoded on chromosome 22 are characterized that differ from the other genes in the U lineage in that they do not exhibit many of the characteristics of classical MHC class I genes. A second, alternate haplotype at this locus is also described with a ~30 kb deletion that completely removes the MHC class I genes. In chapter 2 twelve unique MHC class I genes of the Z lineage are introduced that are encoded on zebrafish chromosomes 1 and 3. This
chapter provides genomic and experimental evidence that these twelve Z genes represent at least two different haplotypes for each locus. The functional significance of the Z lineage MHC class I genes remains unclear as they exhibit features of both classical and nonclassical molecules. In chapter 4 a preliminary analysis of the zebrafish L lineage is provided
identifying 14 unique genes in the latest draft of the reference genome encoded on
The Major Histocompatibility Complex Class I Genes of Zebrafish
by
Hayley Dirscherl
A dissertation submitted to the Graduate Faculty of North Carolina State University
in partial fulfillment of the requirements for the degree of
Doctor of Philosophy
Biomedical Engineering
Raleigh, North Carolina 2015
APPROVED BY:
________________________________ ________________________________ Dr. Jeffrey A. Yoder Dr. Michael Gamcsik
Committee Co-Chair Committee Co-Chair
________________________________ ________________________________ Dr. Albert Banes Dr. Jeffrey Macdonald
ii DEDICATION
iii BIOGRAPHY
Hayley Dirscherl was born in Dunedin, FL and grew up in the sunny town of
Clearwater, FL. She is a proud graduate of the International Baccalaureate program at Palm Harbor University High School where her love for science was made clear. For her
undergraduate studies, she moved to New York City to attend the Columbia University School of Engineering and Applied Science. Outside of her studies in Biomedical
Engineering she was a member of the Columbia University Dance Team for four years and captain for two. Some of her favorite memories from this time include performing at Madison Square Garden and participating with her classmates in a midnight bicycle ride all across Manhattan.
In 2009 she came to Raleigh to join the Joint Department of Biomedical Engineering at UNC and NC State where as a fully-funded Royster Fellow, she was able to join the lab of her choice. Having recently learned about the zebrafish model, she was lucky enough to find the Yoder Lab using zebrafish as a model of human immunity. She plans to continue
iv ACKNOWLEDGMENTS
v TABLE OF CONTENTS
LIST OF TABLES ... ix
LIST OF FIGURES ... x
CHAPTER 1: Introduction and literature review ... 1
Discovery of the Major Histocompatibility Complex ... 1
Structure and function of MHC genes ... 2
Classical and nonclassical MHC class I molecules ... 5
Evolutionary context of the MHC ... 6
Analysis of MHC class I in fish ... 7
The U lineage ... 8
The Z lineage... 11
The nonclassical L lineage... 12
The S and P lineage genes are absent from zebrafish ... 13
Outline of dissertation ... 14
References ... 15
CHAPTER 2: Characterization of the Z lineage Major histocompatibility complex class I genes in zebrafish... 20
Abstract ... 20
Introduction ... 20
Materials and methods ... 21
Gene nomenclature ... 21
Zebrafish lines ... 22
Genomic annotation and data mining... 22
Phylogenetic analyses ... 22
Amplification of zebrafish cDNAs ... 22
Genotyping PCR ... 23
vi
Results and discussion ... 24
Identification of 12 MHC class I Z loci in zebrafish ... 24
Loci encode highly similar MHC class I Z proteins ... 25
Phylogenetic analyses ... 27
Variable expression of MHC class I Z genes ... 27
Evidence for polymorphic, haplotypic, and transcriptional variation ... 29
Zebrafish Z genes primarily show ubiquitous expression ... 30
Z gene polymorphism and genetic background ... 30
Concluding remarks ... 32
Acknowledgements ... 32
References ... 32
CHAPTER 3: MHC class I gene loss through haplotypic variation ... 47
Abstract ... 47
Introduction ... 48
Materials and methods ... 51
Zebrafish and cell lines ... 51
Transcriptome analyses ... 52
Data mining and sequence analyses ... 53
Amplification of zebrafish mhc1ula and mhc1uma sequences ... 54
Southern blot ... 55
Chromosome walking... 56
Chromosome 22 U locus genotyping ... 56
Evaluation of tissue expression ... 57
Results ... 57
Zebrafish mhc1ula and mhc1uma map to chromosome 22 ... 57
Transcript variants... 61
Divergent residues at locations of functional consequence ... 63
vii
A genotyping strategy for the chromosome 22 U locus ... 69
Tissue-specific expression ... 71
Discussion... 72
Acknowledgements ... 75
References ... 76
CHAPTER 4: Preliminary Characterization of the L Lineage MHC class I genes in zebrafish ... 84
Introduction ... 84
Methods ... 86
Database queries ... 86
Sequence analyses ... 86
Transcriptome analysis of a CG2 individual ... 87
Amplification of L cDNAs ... 87
Results ... 88
Improved sequence coverage in GRCz10 reveals fewer L genes on chromosome 25 ... 88
Genomic organization of the zebrafish L genes ... 89
Phylogenetic analyses of the L lineage ... 91
Sequence features of the zebrafish L genes... 94
Evidence for L gene expression ... 97
Discussion... 99
References ... 102
CHAPTER 5: Summary and future directions ... 103
Summary: The genetic diversity of the three lineages of zebrafish MHC class I genes ... 103
The Z lineage... 103
The U lineage ... 104
The L lineage... 105
viii
β2M-binding assay ... 106
Cytotoxicity assay ... 111
Characterize the cytotoxic cells within the mixed effector population ... 114
Concluding thoughts ... 115
References ... 116
APPENDICES ... 118
Appendix A – Published review article ... 119
Appendix B – β2M-binding assay protocol... 132
Appendix C – Cytotoxicity assay protocol ... 136
ix LIST OF TABLES
CHAPTER 2
Table 1 Primer sequences and PCR cycling parameters for cloning
full-length cDNAs ... 23 Table 2 Primer sequences and PCR cycling parameters for genotyping PCR ... 24 Table 3 Zebrafish Z gene information and accession numbers ... 25 Table S1 Zebrafish Z genes identified in the de novo genomic assemblies
from double haploid homozygous AB (DHAB) and Tübingen (DHTu2)
individuals ... 41 Table S2 Predicted sizes of Southern blot fragments containing Z gene
α1 sequences based on HindIII restriction sites ... 41 CHAPTER 3
Table S1 Summary of primer sequences and PCR conditions for all figures ... 79 CHAPTER 4
Table 1 Zebrafish MHC class I L gene nomenclature ... 89 Table 2 Summary of L genes detected in the CG2 zebrafish transcriptome ... 98 Table 3 Primer sequences and PCR cycling parameters for cloning
x LIST OF FIGURES
CHAPTER 1
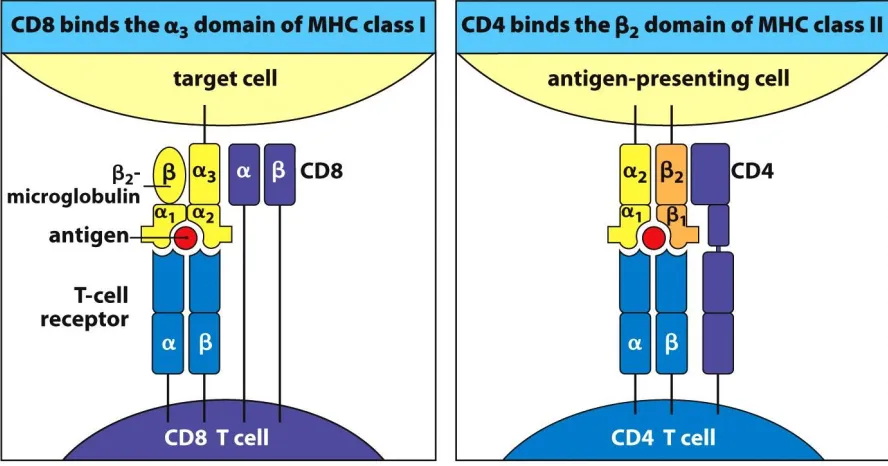
Figure 1 Structure and function of MHC class I and class II proteins ... 3
CHAPTER 2 Figure 1 Genomic organization of zebrafish Z genes ... 23
Figure 2 Z protein sequences ... 26
Figure 3 Phylogenetic analyses of MHC class I Z genes ... 27
Figure 4 Variable expression of Z genes across individual zebrafish... 28
Figure 5 Genotyping PCR and Southern blot analysis ... 29
Figure 6 Z gene expression ... 31
Figure 7 Allelic variation of Z genes ... 31
Figure S1 Full-length zebrafish MHC class I Z proteins ... 34
Figure S2 Organization and classification of zebrafish Z sequences ... 39
Figure S3 Alignment of transmembrane and cytoplasmic domains ... 40
Figure S4 Sequence variation of MHC class I Z proteins... 42
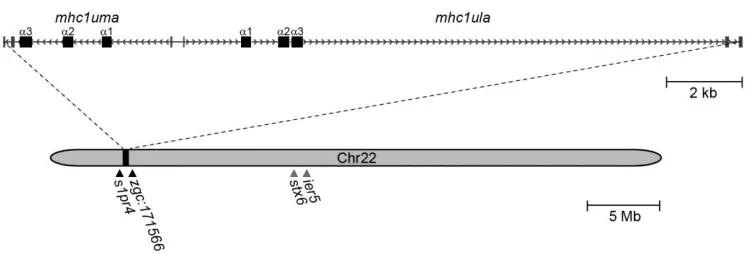
CHAPTER 3 Figure 1 Genomic annotation of mhc1ula and mhc1uma on chromosome 22 ... 58
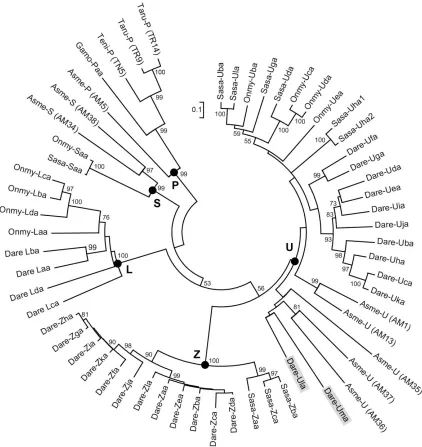
Figure 2Phylogenetic comparison of Ula and Uma to representative MHC class I sequences of teleosts ... 60
Figure 3Zebrafish MHC class I U lineage protein sequence alignment ... 64
Figure 4Presence or absence of mhc1ula and mhc1uma from individual zebrafish ... 67
Figure Sequencing an alternate haplotype ... 68
Figure 6 Genotyping strategy for the chromosome 22 locus ... 70
Figure 7 Tissue-specific expression of mhc1ula and mhc1uma ... 71
Figure S1 Full-length zebrafish Ula and Uma protein sequences ... 81
xi
Figure S3Genomic PCR to identify regions for chromosomal walking ... 83
CHAPTER 4 Figure 1 Genomic map of the zebrafish L genes ... 90
Figure 2 Phylogenetic analysis of the L lineage ... 92
Figure 3 Phylogenetic analysis of individual α domains ... 95
Figure 4 Alignment of the zebrafish L proteins ... 96
Figure 5 Variability plot of the L lineage MHC class I proteins ... 97
CHAPTER 5 Figure 1 Strategy for expressing recombinant proteins in the β2M-binding assay ... 108
Figure 2 Preliminary β2M-binding assay results ... 110
Figure 3 Validation of the fluorescence-based cytotoxicity assay ... 113
1 CHAPTER 1: Introduction and literature review1
Discovery of the Major Histocompatibility Complex
Since the early 1900s there has been a great clinical interest in achieving successful
tissue transplantations and blood transfusions between related and non-related individuals
(Hakim and Danovitch 2001). Research done by Peter Medawar in the 1940s involving skin
grafts between rabbits helped establish the fact that a specific adaptive immune response was
the cause of transplant rejection (Gibson and Medawar 1943). This encouraged researchers to
identify immunosuppressive therapies to improve transplantation success rates. The therapies
they developed included whole-body irradiation as well as chemical treatments like
cyclosporine, but these methods had many side effects and often still resulted in chronic
transplant rejection (Hakim and Danovitch 2001). In 1951, research published by George
Snell was the first to identify a genetic locus, termed the histocompatibility-2 locus, that was
responsible for determining susceptibility or resistance to tumor transplantation between
congenic mouse strains (Snell and Higgins 1951; Klein 2001). It wasn’t until the early 1970s
that this locus was designated as the major histocompatibility complex, or MHC, after the
identification of an orthologous gene cluster in humans (Bach et al. 1972).
Having an understanding of the genetic determinants of transplant compatibility was
critical to enabling many of the medical procedures we have today. Matching at MHC loci
between donors and recipients is important to ensure successful transplant outcomes by
2
minimizing acute graft rejection and/or graft-versus-host disease in the case of bone marrow
transplantation (Groth et al. 2000). However, this wasn’t the only impact of Snell’s research.
As Bach et al. wisely pointed out in 1976, researchers who were drawn to the
histocompatibility antigens never could have anticipated the complexity of the genes
encoding them, as the MHC also plays a central role in the immune response and in
determining disease susceptibility (Bach et al. 1976). While detailing the complete history of
this field of research is beyond the scope of this dissertation, I will include some of the
interesting and historical findings that gave us the understanding of the MHC we have today.
Structure and function of MHC genes
When the membrane-bound histocompatibility antigens were solubilized by
enzymatic digestion and analyzed by chromatography, two classes of protein fragments were
revealed that differed in molecular weight: class I fragments ranged from 58 to 65 kilodaltons
(kDa) while class II fragments were only about 33 to 37 kDA (Stimpfling 1971). As we
know today, this is because MHC class I molecules are heterodimers of a membrane-bound
heavy chain with three immunoglobulin-like α domains (α1, α2, and α3) and a
non-covalently associated light chain encoded outside the MHC (β2-microglobulin) while MHC
class II molecules are heterodimers of α and β chains, each with two immunoglobulin-like
domains (α1 and α2; β1 and β2) tethered to the cell surface (Figure 1). The original MHC
characterization studies were limited in methodology with one of the most prevalent
3
technique led to the key observation that some histocompatibility antigens (class I) are
present on nearly all cells while others (class II) are only encoded by a subset of leukocytes
(Hakim and Danovitch 2001).
Another method that was frequently used was the mixed leukocyte culture (MLC) or
mixed leukocyte reaction (MLR) in which stimulating lymphocytes from one individual are
prevented from proliferating by treatment with a DNA cross-linker and co-cultured for
several hours with responding lymphocytes from another individual (Bach et al. 1976). If the
individuals encode different MHC molecules, then the responder lymphocytes will undergo
proliferation as measured by the incorporation of tritiated thymidine. In humans it was
determined that three class II loci are responsible for determining a positive MLC response
4
(Hakim and Danovitch 2001). This is because the class II molecules present extracellular
antigens, such as bacterial peptides, to CD4+ helper T cells which can then stimulate the
increased uptake by macrophages of extracellular pathogens and/or activate B cells to elicit a
humoral response (Alberts et al. 2002). In contrast, the class I molecules present cytosolic
antigens, such as viral peptides, to CD8+ cytotoxic T cells which can directly kill the infected
target cell by causing it to undergo apoptosis, or programmed cell death.
More recently, an additional role for MHC class I molecules as inhibitory ligands for
natural killer (NK) cells has been described (Raulet and Vance 2006). NK cells are
lymphocytes that are generally considered part of the innate immune system due to their lack
of recombining antigen receptors. Instead they express an assortment of inhibitory and
activating receptors, the stimulation of which is balanced when an NK cell comes in contact
with a normal cell that is recognized as “self”. As even normal cells express a certain level of
activating ligands, the expression of MHC class I as the primary inhibitory ligand of NK cells
is critical to protect normal cells from lysis. In contrast, cells that have been infected or
transformed can be recognized as “non-self” and targeted for lysis by NK cells if they have
been induced to express additional activating cell surface ligands (stress proteins, virally
encoded proteins, etc.) or recognized as “missing self” and targeted for lysis by NK cells if
they are lacking or expressing low levels of the appropriate MHC class I allele(s). The later
scenario is thought to have evolved to counter the immune-evasion strategy of MHC class I
down-regulation employed by many viruses.
The human MHC locus comprises a 3.6 Mb section of chromosome 6 and is
5
(Vandiedonck and Knight 2009). This level of polymorphism results in diverse MHC class I
sequences that can present diverse peptides for interrogation by T cells. There is evidence
that MHC loci are subject to over-dominant selection in which heterozygosity is favored over
homozygosity, likely due to the associated ability to respond to diverse pathogens (Shiina et
al. 2009). The human MHC remains of great interest to many researchers as it has been
associated with over 100 diseases, mostly of the autoimmune or infectious variety (Shiina et
al. 2009).
Classical and nonclassical MHC class I molecules
The focus of this dissertation is on the characterization of MHC class I genes and the
molecules they encode. MHC class I molecules can be further classified as being classical or
nonclassical. Classical MHC class I molecules are defined based on their function of
presenting peptide antigens to CD8+ T cells in order to initiate an immune response. Because
of this function, classical MHC class I molecules have extremely high levels of
polymorphism, often found as specific patterns of substitutions among residues associated
with the peptide binding site in the α1 and α2 domains (Bjorkman et al. 1987). Additional
characteristics of classical MHC class I molecules include nearly ubiquitous expression,
conservation of peptide anchor residues, and conservation of surface residues that promote
binding to other molecules such as 2M and CD8 (Rodgers and Cook 2005; Hee et al. 2013).
Nonclassical MHC class I molecules have a similar structure as the classical
6
with other immune cells or present non-peptide antigens while others have non-immune
functions (Watanabe et al. 2004; Rodgers and Cook 2005). The nonclassical MHC class I
genes are frequently at least an order of magnitude less polymorphic than their classical
counterparts and are often expressed in limited tissues (Shiina et al. 2009). Interestingly,
some MHC molecules considered classical, such as HLA-C, also have nonclassical
characteristics, and are thus capable of initiating an immune response by more than one
mechanism (Colonna et al. 1993). It has been hypothesized that classical MHC genes are
periodically duplicated within the genome and thus over time may be free to be selected upon
to acquire diverse roles (Klein et al. 2007). Of note, a large fraction of the nonclassical MHC
genes are not found within the core MHC locus but are instead scattered on additional
chromosomal loci in humans and many other vertebrate species (Horton et al. 2004).
Evolutionary context of the MHC
While they have been best characterized in humans, mice, and other mammals, MHC
molecules have been found in all jawed vertebrate species examined including cartilaginous
fishes (Flajnik and Kasahara 2010). It is thought that the adaptive immune system that relies
on the existence of MHC molecules, B and T cells, immunoglobulins, and T cell receptors
came about in a “big bang” as no jawed vertebrates have been found with an intermediate
version of the system (Parham 2005). Its emergence could have been made possible by the
incorporation of a transposon encoding the recombination activating gene (RAG) capable of
7
(WGD) that produced an abundance of raw genetic material (Flajnik and Kasahara 2010).
After the MHC had been described in several mammalian species, researchers became
interested in trying to identify orthologous genes in bony fish, or teleosts, in order to gain
perspective on the evolutionary origins of adaptive immunity. The teleost species have been
diversifying for ~350 million years and represent the largest group of living vertebrates (Stet
and Egberts 1991).
Analysis of MHC class I in fish
The first experiments looking for evidence of an MHC in a teleost relied on the
indirect methods of allograft rejection and the MLR. Due to the popularization of the
polymerase chain reaction (PCR), researchers were eventually able to find direct evidence for
MHC-like genes. First, a genomic locus encoding an MHC class I-like sequence called
TLAIα-1 was amplified from Cyprinus carpio, the common carp (Hashimoto et al. 1990).
The first evidence of MHC class I expression from any teleost was the identification of a
full-length class I transcript from a cDNA library from Salmo salar, the Atlantic salmon
(Grimholt et al. 1993). Eventually, this first MHC class I transcript was designated as being a
part of the U sequence lineage (for “uno” meaning “one”), the lineage that is best conserved
throughout diverse teleost families (Pinto et al. 2013). Four other sequence lineages have
been identified in teleosts which are designated Z, L, S, and P. The focus of this dissertation
is on the characterization of the MHC class I genes of zebrafish which include the U, Z, and
8
time of the zebrafish make it a suitable model for evaluating the effects of selection on an
immunologically important gene such as MHC class I (Takeuchi et al. 1995). I will
summarize what was known about each of these sequence lineages prior to the start of my
dissertation research with an emphasis on zebrafish data.
The current zebrafish MHC class I gene nomenclature follows the guidelines
proposed for all species (Klein et al. 1990). If the zebrafish “mhc1uaa” gene symbol is dissected as an example, the “mhc1” is included to define the sequence as class I. The first
letter “u” (or “z” or “l”) corresponds to the MHC class I lineage. The variable second letter
“a” (or “b” or “c” etc.) designates the gene, named alphabetically in order of discovery. The
third letter “a” indicates the alpha chain. For MHC class II genes that form heteromeric
complexes of an alpha and a beta chain, the beta chain gene is designated with “b”. When
zebrafish MHC class I genes are compared to sequences from other species, then the
inclusion of a species identifier is crucial. In this case, the four letter prefix, Dare (which refers to the first two letters of the genus and species, Danio rerio), is added to the gene symbol (Dare-mhc1uaa).
The U lineage
There is abundant evidence to suggest that the MHC class I molecules of the U
lineage exhibit classical function in teleosts. First, there is direct experimental evidence of
peptide presentation for U molecules from studies performed in grass carp
9
binding of peptide to U molecules, 3) association of U molecules with 2M, and 4) the
interaction of labeled U complexes with T cells (Chen et al. 2010). Notably, cytotoxic T cell
function appears to be highly conserved in teleosts (Nakanishi et al. 2011), which likely
relies on antigen presentation via U molecules to activate the immune response of CD8+
cells. It has been demonstrated in rainbow trout (Oncorhynchus mykiss) that a U protein known as UBA is expressed in similar cell types as mammalian classical MHC class I
molecules (Dijkstra et al. 2003). Specific alleles of the single classical U locus, UBA, in
Atlantic salmon have been implicated in pathogen resistance (Grimholt et al. 2003; Kjøglum
et al. 2008). Finally, at the genomic level, only the U lineage genes are consistently
associated with the core MHC locus within teleosts, meaning that they maintain linkage to
additional class I pathway genes such as psmb8, tapbp, and abcb3/tap2 (Matsuo et al. 2002). Full-length transcripts and genomic sequence for β2M from zebrafish were reported
in 1993 (Ono et al. 1993) followed shortly by the cloning of three MHC class I genes of the
U lineage (Takeuchi et al. 1995). The sequences identified from a cDNA library were
designated mhc1uaa and mhc1uba while a third sequence identified from a genomic library was designated mhc1uca. Linkage studies in haploid zebrafish embryos showed that the class I loci are closely linked on chromosome 19 (Bingulac-Popovic et al. 1997). In zebrafish,
haplotypic variation greatly contributes to the diversity of U gene loci. Genomic sequences
have been assembled for two different haplotypes on zebrafish chromosome 19 (Michalova
et al. 2000). Chromosome walking on BAC and PAC clones revealed one haplotype
10
linked flanking genes, with each distinct haplotype carrying one, two, or three unique U
lineage genes (McConnell et al. 2014). Southern blot analyses of genomic DNA from
zebrafish that are homozygous for each of the six haplotypes support the conclusion that each
haplotype contains one to three U genes.
The zebrafish has been increasingly used in transplantation assays due to its several
advantages over the more traditional mouse including higher fecundity, optical clarity at the
embryonic and larval stages, and ease of manipulation for forward or reverse genetics
(Taylor and Zon 2009). Zebrafish transplantation assays have been especially useful for the
study of hematopoietic stem cells (Li et al. 2011). However their use in this type of assay
highlights a current limitation: attempts at generating inbred zebrafish lines met with only
limited success (Shinya et al. 2011), resulting in standard laboratory “lines” of zebrafish
harboring a multitude of polymorphisms as well as haplotypic variation especially at immune
loci (Patowary et al. 2013). As immunologically compatible zebrafish donors and recipients
are not readily available, genotyping strategies have been and are being developed for
identifying MHC-matched zebrafish. It has been shown that MHC matching at the U locus
on chromosome 19 significantly increases engraftment in hematopoietic transplantation
assays (de Jong et al. 2011). This result represents the only functional data for MHC class I
genes in zebrafish. The researchers subsequently performed hematopoietic transplantations
between individual zebrafish that were matched at an additional MHC class I locus on
chromosome 1 (encoding Z lineage genes) and the MHC class II locus on chromosome 8 in
addition to the U locus on chromosome 19 but saw no significant increase in engraftment
11
transplants between individuals matched at the chromosome 19 U locus still fail to
successfully engraft, it remains to achieve a better understanding of this and other MHC class
I loci to achieve optimal success rates in zebrafish transplantation assays. Through my
doctoral research I have identified two additional genes of the U lineage that map to a novel
locus on chromosome 22. These genes are described in detail in Chapter 3 of this
dissertation.
The Z lineage
The Z lineage genes in zebrafish have historically been referred to as ZE lineage
genes (Kruiswijk et al. 2002); however, the zebrafish nomenclature committee
(http://zfin.org/) recently agreed to employ a nomenclature similar to that used for the
zebrafish U genes as well as the Z gene nomenclature in Atlantic salmon. In order to
understand the history of the Z gene nomenclature in zebrafish one needs to first understand
the origins of the nomenclature in carp. The first Z lineage genes to be reported were
described from common carp and ginbuna crucian carp (Carassius auratus langsdorfii) and named ZA, ZB, ZC, and ZD (Okamura et al. 1993). Approximately ten years later, an
additional MHC class I gene was described from zebrafish, common carp, and barbus
(Barbus intermedius), that is phylogenetically distinct from the U and ZA/ZB/ZC/ZD gene lineages. This gene shares more similarity with the ZA/ZB/ZC/ZD sequences than the U
lineage sequences, and thus was named ZE (Kruiswijk et al. 2002). However, differences
between ZE and the ZA/ZB/ZC/ZD genes soon became apparent, as the ZA/ZB/ZC/ZD
12
(Kruiswijk et al. 2002). Also, while the ZA/ZB/ZC/ZD genes have properties consistent with
nonclassical MHC genes, ZE genes are distinguished by having features of both classical and
nonclassical MHC genes. Since the only MHC class I Z genes identified outside of carp
species are the ZE genes, the zebrafish ZE genes are now referred to simply as Z genes in
accordance with MHC class I nomenclature guidelines.
The initial full-length Z transcripts from zebrafish were named Dare-ZE*0101 and
Dare-ZE*0102 not knowing if they represented different genes or different alleles of a single gene (Kruiswijk et al. 2002). However, it was clear then that these sequences were likely not
derived from a single copy gene as 14 unique Z sequences were amplified from only five
individual zebrafish. Further evidence of the Z lineage being a multi-gene family came in
2005 when a genome-wide survey of zebrafish MHC loci placed one full length Z gene on an
unplaced scaffold as well as four similar genes on chromosome 1 (based on the fourth
zebrafish genome assembly, Zv4) but no sequence data was provided (Sambrook et al. 2005).
My in-depth analysis of the Z lineage MHC class I genes is provided in Chapter 2.
The nonclassical L lineage
A third lineage of MHC class I genes in teleosts was first reported in 2007 and
designated the L lineage due to the linkage of at least one of its members with MHC class II
(Dijkstra et al. 2007). This linkage of MHC class I and class II genes in zebrafish was in
contrast to the previously described absence of linkage between these genes in teleosts
(Bingulac-Popovic et al. 1997). While this lineage was most extensively characterized in
13
Atlantic salmon, and fathead minnow (Pimephales promelas) but not in species outside the teleosts (Dijkstra et al. 2007). The L lineage molecules are thought to be nonclassical in
function mostly due to the fact that they lack most of the residues thought to be important for
anchoring the ends of bound peptide. My preliminary analysis of the L lineage genes in
zebrafish is presented in Chapter 4.
S and P lineage genes are absent from zebrafish
A fourth MHC class I lineage in bony fish is referred to as the S lineage as it was first
described in salmonid species, including Atlantic salmon and rainbow trout, although a
related cDNA also has been identified from channel catfish (Ictalurus punctatus) which is a siluriforme species (Lukacs et al. 2010). Atlantic salmon appear to encode a single S lineage
gene, mhc1saa, which was renamed from mhc1uaa based on its lack of identity to other U lineage genes (Lukacs et al. 2010). We have strengthened the claim that the S lineage is
absent in zebrafish (Grimholt et al. 2015) by showing that there are no sequences in the
zebrafish reference genome (Zv9) with significant identity to Atlantic salmon SAA and that
the sequences with the greatest similarity are more similar to genes of the U lineage
(Dirscherl et al. 2014). A fifth MHC class I lineage was recently described from teleosts
named P for “penta” (Grimholt et al. 2015). P lineage sequences were identified in seven
species including Atlantic salmon but were not found in zebrafish. Both the S and P lineages
are thought to encode nonclassical MHC class I molecules due to their lack of
peptide-binding residues (Grimholt et al. 2015). For the P lineage this assertion is supported by the
14 Outline of dissertation
While our understanding of the MHC class I genes in zebrafish will continue to grow
in the coming years, I have made significant contributions in this regard through my doctoral
research. Chapter 2 shows my published work characterizing the unique
classical/nonclassical Z lineage encoded on chromosomes 1 and 3. In Chapter 3, which has been submitted for publication, I report my finding of two additional genes of the U lineage
that map to a novel locus on chromosome 22. Chapter 4 presents my initial analysis of the L lineage MHC class I genes which map to chromosomes 3, 8, and 25. Finally, in Chapter 5 I highlight some of the future directions of this research geared toward the functional
characterization of the three different lineages of MHC class I molecules in zebrafish. This
includes my development of a β2M-binding assay as well as a fluorescence-based
cytotoxicity assay and some preliminary results. It remains of interest to determine if the
MHC class I molecules of an early vertebrate species such as the zebrafish carry out the
diverse array of functions as do the MHC class I molecules that have been well characterized
15 References
Alberts B, Johnson A, Lewis J, et al. (2002) Molecular Biology of the Cell, 4th Edition. Garland, New York
Bach FH, Bach ML, Sondel PM (1976) Differential function of major histocompatibility complex antigens in T-lymphocyte activation. Nature 259:273–281. doi:
10.1038/259273a0
Bach FH, Widmer MB, Segall M, et al. (1972) Genetic and immunological complexity of major histocompatibility regions. Science 176:1024–1027. doi:
10.1126/science.176.4038.1024
Bingulac-Popovic J, Figueroa F, Sato A, et al. (1997) Mapping of mhc class I and class II regions to different linkage groups in the zebrafish, Danio rerio. Immunogenetics 46:129–134. doi: 10.1007/s002510050251
Bjorkman PJ, Saper MA, Samraoui B, et al. (1987) The foreign antigen binding site and T cell recognition regions of class I histocompatibility antigens. Nature 329:512–518. doi: 10.1038/329512a0
Chen W, Jia Z, Zhang T, et al. (2010) MHC class I presentation and regulation by IFN in bony fish determined by molecular analysis of the class I locus in grass carp. J Immunol 185:2209–2221. doi: 10.4049/jimmunol.1000347
Colonna M, Borsellino G, Falco M, et al. (1993) HLA-C is the inhibitory ligand that determines dominant resistance to lysis by NK1- and NK2-specific natural killer cells. Proc Natl Acad Sci U S A 90:12000–12004. doi: 10.1073/pnas.90.24.12000
De Jong JLO, Burns CE, Chen AT, et al. (2011) Characterization of immune-matched hematopoietic transplantation in zebrafish. Blood 117:4234–4242. doi: 10.1182/blood-2010-09-307488
De Jong JLO, Zon LI (2012) Histocompatibility and hematopoietic transplantation in the zebrafish. Adv Hematol. doi: 10.1155/2012/282318
16 Dijkstra JM, Köllner B, Aoyagi K, et al. (2003) The rainbow trout classical MHC class I
molecule Onmy-UBA*501 is expressed in similar cell types as mammalian classical MHC class I molecules. Fish Shellfish Immunol 14:1–23. doi: 10.1006/fsim.2001.0407 Dirscherl H, McConnell SC, Yoder JA, de Jong JLO (2014) The MHC class I genes of
zebrafish. Dev Comp Immunol 46:11–23. doi: 10.1016/j.dci.2014.02.018
Flajnik MF, Kasahara M (2010) Origin and evolution of the adaptive immune system: genetic events and selective pressures. Nat Rev Genet 11:47–59. doi: 10.1038/nrg2703 Gibson T, Medawar PB (1943) The fate of skin homografts in man. J Anat 77:299–310.4. Grimholt U, Hordvik I, Fosse VM, et al. (1993) Molecular cloning of major
histocompatibility complex class I cDNAs from Atlantic salmon (Salmo salar). Immunogenetics 37:469–473.
Grimholt U, Larsen S, Nordmo R, et al. (2003) MHC polymorphism and disease resistance in Atlantic salmon (Salmo salar); facing pathogens with single expressed major
histocompatibility class I and class II loci. Immunogenetics 55:210–219. doi: 10.1007/s00251-003-0567-8
Grimholt U, Tsukamoto K, Azuma T, et al. (2015) A comprehensive analysis of teleost MHC class I sequences. BMC Evol Biol. doi: 10.1186/s12862-015-0309-1
Groth CG, Brent LB, Calne RY, et al. (2000) Historic landmarks in clinical transplantation: Conclusions from the consensus conference at the University of California, Los
Angeles. World J Surg 24:834–843. doi: 10.1007/s002680010134
Hakim NS, Danovitch GM (2001) Transplantation Surgery. Springer, New York Hashimoto K, Nakanishi T, Kurosawa Y (1990) Isolation of carp genes encoding major
histocompatibility complex antigens. Proc Natl Acad Sci U S A 87:6863–6867. Hee CS, Beerbaum M, Loll B, et al. (2013) Dynamics of free versus complexed
β2-microglobulin and the evolution of interfaces in MHC class I molecules. Immunogenetics 65:157–172. doi: 10.1007/s00251-012-0667-4
Horton R, Wilming L, Rand V, et al. (2004) Gene map of the extended human MHC. Nat Rev Genet 5:889–899. doi: 10.1038/nrg1489
17 Klein J (2001) George Snell’s first foray into the unexplored territory of the major
histocompatibility complex. Genetics 159:435–439.
Klein J, Bontrop RE, Dawkins RL, et al. (1990) Nomenclature for the major
histocompatibility complexes of different species: a proposal. Immunogenetics 31:217– 219. doi: 10.1007/BF00204890
Klein J, Sato A, Nikolaidis N (2007) MHC, TSP, and the origin of species: from immunogenetics to evolutionary genetics. Annu Rev Genet 41:281–304. doi: 10.1146/annurev.genet.41.110306.130137
Kruiswijk CP, Hermsen TT, Westphal AH, et al. (2002) A novel functional class I lineage in zebrafish (Danio rerio), carp (Cyprinus carpio), and large barbus (Barbus intermedius) showing an unusual conservation of the peptide binding domains. J Immunol 169:1936– 1947. doi: 10.4049/jimmunol.169.4.1936
Li P, White RM, Zon LI (2011) Transplantation in Zebrafish, Third Edit. Methods Cell Biol 105:403–417. doi: 10.1016/B978-0-12-381320-6.00017-5
Lukacs MF, Harstad H, Bakke HG, et al. (2010) Comprehensive analysis of MHC class I genes from the U-, S-, and Z-lineages in Atlantic salmon. BMC Genomics 11:154. doi: 10.1186/1471-2164-11-154
Matsuo MY, Asakawa S, Shimizu N, et al. (2002) Nucleotide sequence of the MHC class I genomic region of a teleost, the medaka (Oryzias latipes). Immunogenetics 53:930–940. doi: 10.1007/s00251-001-0427-3
McConnell SC, Restaino AC, de Jong JLO (2014) Multiple divergent haplotypes express completely distinct sets of class I MHC genes in zebrafish. Immunogenetics 66:199– 213. doi: 10.1007/s00251-013-0749-y
Nakanishi T, Toda H, Shibasaki Y, Somamoto T (2011) Cytotoxic T cells in teleost fish. Dev Comp Immunol 35:1317–1323. doi: 10.1016/j.dci.2011.03.033
Okamura K, Nakanishi T, Kurosawa Y, Hashimoto K (1993) Expansion of genes that encode MHC class I molecules in cyprinid fishes. J Immunol 151:188–200.
Ono H, Figueroa F, O’hUigin C, Klein J (1993) Cloning of the β2-microglobulin gene in the zebrafish. Immunogenetics 38:1–10. doi: 10.1007/BF00216384
18 Patowary A, Purkanti R, Singh M, et al. (2013) A sequence-based variation map of zebrafish.
Zebrafish 10:15–20. doi: 10.1089/zeb.2012.0848
Pinto RD, Randelli E, Buonocore F, et al. (2013) Molecular cloning and characterization of sea bass (Dicentrarchus labrax, L.) MHC class I heavy chain and β2-microglobulin. Dev Comp Immunol 39:234–254. doi: 10.1016/j.dci.2012.10.002
Raulet DH, Vance RE (2006) Self-tolerance of natural killer cells. Nat Rev Immunol 6:520– 531. doi: 10.1038/nri1863
Rodgers JR, Cook RG (2005) MHC class Ib molecules bridge innate and acquired immunity. Nat Rev Immunol 5:459–471. doi: 10.1038/nri1635
Sambrook JG, Figueroa F, Beck S (2005) A genome-wide survey of Major
Histocompatibility Complex (MHC) genes and their paralogues in zebrafish. BMC Genomics 6:152. doi: 10.1186/1471-2164-6-152
Scharsack JP, Kalbe M, Schaschl H (2007) Characterization of antisera raised against stickleback (Gasterosteus aculeatus) MHC class I and class II molecules. Fish Shellfish Immunol 23:991–1002. doi: 10.1016/j.fsi.2007.03.011
Shiina T, Hosomichi K, Inoko H, Kulski JK (2009) The HLA genomic loci map: expression, interaction, diversity and disease. J Hum Genet 54:15–39. doi: 10.1038/jhg.2008.5 Shinya M, Sakai N, Andrews BJ (2011) Generation of Highly Homogeneous Strains of
Zebrafish Through Full Sib-Pair Mating. Genes|Genomes|Genetics 1:377–386. doi: 10.1534/g3.111.000851
Snell GD, Higgins GF (1951) Alleles at the histocompatibility-2 locus in the mouse as determined by tumor transplantation. Genetics 36:306–10.
Stet RJM, Egberts E (1991) The histocompatibility system in teleostean fishes: From multiple histocompatibility loci to a major histocompatibility complex. Fish Shellfish Immunol 1:1–16. doi: 10.1016/S1050-4648(06)80016-1
Stimpfling JH (1971) Recombination within a histocompatibility locus. Annu Rev Genet 5:121–142. doi: 10.1146/annurev.ge.05.120171.001005
Takeuchi H, Figueroa F, O’hUigin C, Klein J (1995) Cloning and characterization of class I Mhc genes of the zebrafish, Brachydanio rerio. Immunogenetics 42:77–84. doi:
19 Taylor AM, Zon LI (2009) Zebrafish tumor assays: the state of transplantation. Zebrafish
6:339–346. doi: 10.1089/zeb.2009.0607
Vandiedonck C, Knight JC (2009) The human Major Histocompatibility Complex as a paradigm in genomics research. Briefings Funct Genomics Proteomics 8:379–394. doi: 10.1093/bfgp/elp010
20 CHAPTER 2: Characterization of the Z lineage Major histocompatibility complex class I
47 CHAPTER 3: MHC class I gene loss through haplotypic variation1
Abstract
Three sequence lineages of MHC class I genes have been described in zebrafish (Danio rerio): U, Z, and L. The U lineage genes encoded on zebrafish chromosome 19 are predicted to provide the classical function of antigen presentation. This MHC class I locus displays significant haplotypic variation and is the only MHC class I locus in zebrafish that shares conserved synteny with the core mammalian MHC. Here we describe two MHC class I U lineage genes, mhc1ula and mhc1uma, that map to chromosome 22. Unlike the U lineage proteins encoded on chromosome 19, Ula and Uma may play a nonclassical role as they lack conservation of key peptide binding residues, display limited polymorphic variation, and exhibit tissue-specific expression (primarily in the gills). We also describe a second
haplotype at this chromosome 22 locus in which the mhc1ula and mhc1uma genes are absent due to a ~30 kb deletion with no other MHC class I sequences present. Functional and non-functional transcript variants of mhc1ula and mhc1uma were identified; however, mhc1uma
transcripts were often not amplified or amplified at low levels from individuals encoding the gene. Ula and Uma show sequence similarity to U proteins recently predicted from the genome of the blind cavefish (Astyanax mexicanus) suggesting that these distinct U lineage genes may be restricted to the superorder Ostariophysi.
48 Introduction
While the genes of the major histocompatibility complex (MHC) were named after the discovery that they encode the primary antigens responsible for determining transplant compatibility (Klein 2001), MHC molecules also play a central role in adaptive immunity through presenting antigens to T cells. MHC class I molecules present cytosolic antigens to CD8+ cytotoxic T cells while MHC class II molecules present exogenous peptides to CD4+ helper T cells (Horton et al. 2004). MHC class I molecules also serve as inhibitory ligands to natural killer (NK) cells to prevent the killing of normal “self” cells (Raulet and Vance 2006). MHC class I molecules can be further classified as classical or nonclassical where the classical MHC class I molecules are defined by their function of peptide presentation to CD8+ T cells. The genes encoding classical MHC class I molecules are highly polymorphic and ubiquitously expressed. The nonclassical MHC class I molecules have a similar structure to the classical molecules but exhibit different, often immune-related functions. They’re also characterized as having low-level polymorphism and tissue-specific expression. The classical MHC class I molecules serve as the primary marker of “self” to NK cells, though many nonclassical MHC class I proteins are also recognized by different classes of NK receptors (Halenius et al. 2014).
49 evolutionary origin falls shortly after that of the MHC class I genes themselves, especially in comparison to other common model species. However, it has yet to be determined if the zebrafish MHC class I molecules carry out a similar repertoire of functions as the well-characterized human HLA molecules or if these functions arose later in mammalian evolution. This question is especially relevant since the genomic organization of the genes encoding MHC class I molecules in zebrafish differs greatly from that of mammals.
Five phylogenetic lineages of MHC class I genes, termed U, Z, L, S, and P, have been identified from multiple bony fish (Dirscherl et al. 2014; Grimholt et al. 2015). The U and Z lineage proteins are predicted to bind peptides in a manner similar to classical MHC class I; however, only the U lineage genes share conserved synteny with the mammalian MHC core locus (Michalová et al. 2000). Although no functional data has been reported on the MHC class I Z lineage, there is direct experimental evidence of peptide presentation by U lineage MHC class I proteins (Scharsack et al. 2007; Chen et al. 2010). In contrast the L, S and P lineage proteins are considered nonclassical due to their lack of a classical peptide binding groove, although virtually nothing has been reported on their function (Dijkstra et al. 2007; Lukacs et al. 2010; Dirscherl et al. 2014; Grimholt et al. 2015).
Zebrafish possess only the MHC class I U, Z and L lineages and have been reported to encode a single U lineage locus on chromosome 19 that displays significant haplotypic variation (McConnell et al. 2014). The zebrafish Z lineage genes are encoded on
50 It is unclear to what extent the different zebrafish MHC class I genes encoded across multiple chromosomes contribute to the immune system’s ability to differentiate “self” from “non-self”. Using tissue transplantation as a model for evaluating the role of MHC class I matching in allorecognition, de Jong et al. have shown that matching the donor and recipient zebrafish at the MHC class I U locus on chromosome 19 significantly increases the percent of donor cells that successfully engraft; however, matching at this locus alone is insufficient to predict successful engraftment 100% of the time (de Jong et al. 2011). Additionally, it has been shown that matching individuals at the MHC class I and class II loci on chromosomes 1 and 8, respectively, in addition to the chromosome 19 locus does not significantly improve the success of engraftment (de Jong and Zon 2012). This suggests that additional MHC class I loci may be important for allorecognition.
Recent work characterizing the haplotypes of the U genes on chromosome 19 identified a putative U gene on chromosome 22 which was designated mhc1ula in accordance with nomenclature conventions (McConnell et al. 2014). McConnell et al. predicted that this chromosome 22 locus may display haplotypic variation due to the occasional presence of a band matching the predicted size of the fragment containing the
mhc1ula gene in a Southern blot hybridized with a mhc1uda probe. We recently reported the presence of a second putative U gene adjacent to mhc1ula which has been designated
mhc1uma (Dirscherl et al. 2014). This U locus was also depicted in a recent analysis of MHC class I sequences predicted from various teleost genomic databases (Grimholt et al. 2015).
Here, we report the cloning and characterization of full-length transcripts for both
51 ~30 kb deletion that completely removes the mhc1ula and mhc1uma genes. In addition, we show that mhc1ula and mhc1uma differ from the other genes in the U lineage in that they do not exhibit many of the characteristics of classical MHC class I genes including polymorphic variation, conservation of key residues, and ubiquitous expression. A better understanding of the recently identified U MHC class I locus on chromosome 22 and its relation to the core MHC class I locus on chromosome 19 will inform the evolutionary history of this dynamic gene family and may improve the success of experimental tissue transplants in zebrafish.
Materials and methods
Zebrafish and cell lines
All experiments involving live zebrafish were performed in accordance with relevant institutional and national guidelines and regulations and were approved by the North
52 Chicago (Mizgirev and Revskoy 2010). The zebrafish ZF4 fibroblast cell line was purchased from ATCC and grown at 28°C with 5% CO2 in DMEM:F-12 medium (ATCC) with 10% fetal bovine serum (Atlanta Biologicals).
Transcriptome analyses
A single CG2 zebrafish was euthanized and the kidney, intestine, gills and spleen were dissected and combined for RNA extraction (TRIzol Reagent, Life Technologies). RNA was prepared for sequencing with the TruSeq RNA kit (Illumina) and sequenced (2 x 100 bp paired end reads) on a single lane of a HiSeq2000 (Illumina). In effort to detect rare
53
Data mining and sequence analyses
Protein domains were identified using SMART software (Letunic et al. 2012). Ula and Uma α domains were used as queries to search (BLASTp) the zebrafish non-redundant protein database as well as to search (tBLASTn) the zebrafish non-redundant nucleotide database, the zebrafish EST database, and the de novo genomic assemblies from double haploid homozygous AB and TU individuals generated by the Wellcome Trust Sanger Institute (www.sanger.ac.uk). Protein sequences were aligned by Clustal Omega (Sievers et al. 2011) and phylogenetic trees constructed using MEGA4 software (Tamura et al. 2007). MHC class I sequences were from blind cavefish (Asme, Astyanyx mexicanus), zebrafish (Dare, Danio rerio), Atlantic cod (Gamo, Gadus morhua), rainbow trout (Onmy,
Oncorhynchus mykiss), Atlantic salmon (Sasa, Salmo salar), pufferfish (Taru, Takifugu rubripes), and green pufferfish (Teni, Tetraodon nigroviridis). MHC class I sequences used for comparisons (and their GenBank accession identities) are as follows: Dare-Laa
(NP_001017904.1), Dare-Lba (XP_001920787.3), Dare-Lca (XP_001340413.4), Dare-Lda (XP_001920290.4), Dare-Uba (AAH74095.1), Dare-Uca (XP_005159526.1), Dare-Uda (AAI28863.1), Dare-Uea (AAH53140.1), Dare-Ufa (AAH66754.1), Dare-Uga
(AAH56726.1), Dare-Uha (AAI24258.1), Dare-Uia (AAH93149.1), Dare-Uja
(AAH54592.1), Dare-Uka (AAI22402.1), Dare-Ula (KR086339), Dare-Uma (KR086346), Dare-Zaa (AHA37369.1), Dare-Zba (AHA37371.1), Dare-Zca (AHA37375.1), Dare-Zda (NP_001274026.1), Zea (AHA37389.1), Zfa (AHA37394.1), Zga and Dare-Zha (XP_001919291.4, two sets of α domains in one predicted transcript), Dare-Zia
54 (AHA37403.1), Gamo-Paa (GW844691.1), Onmy-Laa (ABI21842.1), Onmy-Lba
(ABI21844.1), Onmy-Lca (ABI21845.1), Onmy-Lda (BAF37937.1), Onmy-Saa (AAB57877.1), Onmy-Uba (AAG25197.1), Onmy-Uca (BAD89552.1), Onmy-Uda (AAS93695.1), Onmy-Uea (BAD89553.1), Sasa-Saa (ACY30362.1), Sasa-Uba (AAN75116.1), Sasa-Uda (ACY30371.1), Sasa-Uga (ACX35601.1), Sasa-Uha1 (ACY30367.1), Sasa-Uha2 (ACY30368.1), Sasa-Ula (ABO13870.1), Sasa-Zaa (ACX35596.1), Sasa-Zba (ACX35613.1), and Sasa-Zca (ACX35618.1). Additional
sequences include those predicted in a recent publication characterizing teleost MHC class I sequences (Grimholt et al. 2015). The sequence identifiers used by Grimholt et al. are included in the phylogenetic analyses.
Amplification of zebrafish mhc1ula and mhc1uma sequences
Adult zebrafish were euthanized, frozen in liquid nitrogen, and pulverized by mortar and pestle. Total RNA was purified from half of each individual as well as from ZF4 cells (TRIzol® Reagent, Invitrogen) and reverse transcribed into cDNA (SuperScript® III Reverse Transcriptase, Invitrogen). Primers pairs were designed to amplify the entire coding
sequences of mhc1ula and mhc1uma by RT-PCR. A primer pair that amplifies a portion of the β-actin transcript was used as a positive control for cDNA quality as previously described (Dirscherl and Yoder 2014).
55 span a single intron. The same β-actin primer pair described above was used as a positive control for genomic DNA quality.
Primer sequences and cycling parameters are provided in Online Resource 1, Table S1. All primer pairs were validated by sequencing of representative amplicons. New sequence data including transcript variants have been deposited with GenBank under accession numbers: KR086338- KR086356.
Southern blot
56
Chromosome walking
PCR primer pairs were designed to amplify 150 to 250 bp flanking genomic
amplicons (FGAs) at intervals upstream (-) and downstream (+) of mhc1ula and mhc1uma on chromosome 22 based on the reference genome (Zv9). Primer pairs were used with genomic DNA from different individual zebrafish to identify conserved FGAs. Using the Universal GenomeWalker 2.0 kit (Clontech), adapter-ligated libraries were generated by digesting genomic DNA with four different blunt-end restriction endonucleases. Chromosome walking was then accomplished by performing long-range nested PCR with gene-specific and
adapter-specific primers starting from the genomic regions encoding the -5 kb and +13 kb FGAs. FGA and chromosome walking primer sequences are provided in Online Resource 1, Table S1.
Chromosome 22 U locus genotyping
Based on the sequence results from chromosome walking, primers were designed to genotype the chromosome 22 U locus by a duplex PCR assay (primer sequences in Online Resource 1, Table S1). In this assay a single forward primer upstream of the MHC class I locus is used with two different reverse primers that amplify a 634 bp fragment from the chromosome 22 haplotype in the reference genome encoding mhc1ula and mhc1uma
(haplotype A) or a 747 bp fragment from a haplotype in which the mhc1ula and mhc1uma
sequences have been deleted (haplotype B). The assay was applied to the same panel of genomic DNA from individual zebrafish described above. The assay was also used to
57 used to genotype representative offspring at three days post fertilization (dpf) in order to define inheritance ratios.
Evaluation of tissue expression
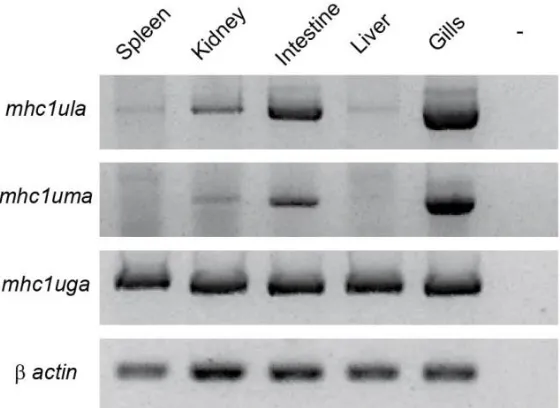
Additional primer pairs were designed to amplify transcript segments encoding the α1 to α3 domains of mhc1ula, mhc1uma, and mhc1uga from a panel of tissue-specific cDNAs derived from an EKW individual that had been genotyped as described above. β-actin primers were used as a control for tissue cDNA quality. Primer sequences and cycling parameters are provided in Online Resource 1, Table S1.
Results
Zebrafish mhc1ula and mhc1uma map to chromosome 22
In an effort to characterize novel MHC class I sequences, transcriptome (RNA-Seq) analysis was conducted from pooled tissues (spleen, kidney, intestine, and gills) of a single zebrafish from the double haploid, clonal CG2 line (Mizgirev and Revskoy 2010). BLASTn searches of this transcriptome database with mhc1uga, which is the only U lineage MHC class I gene encoded on chromosome 19 in CG2 zebrafish (McConnell et al. 2014), as a query identified mhc1uga as well as additional transcripts encoding two novel MHC class I sequences. The genes encoding these sequences have since been named mhc1ula and
58 map to a single scaffold on chromosome 22 (Zv9_scaffold3011; GenBank:
NW_001878374.3). Using the predicted CG2 transcripts as a reference, primer pairs (Online Resource 1, Table S1) were designed to amplify transcripts encoding the entire open reading frames of mhc1ula and mhc1uma (discussed in detail below). Recovered transcripts indicate that each gene possesses six exons and that the genes are separated by 248 bp in a head to head configuration in the reference genome (Figure 1).
As all previously identified U lineage genes map to a single locus on zebrafish chromosome 19, it was unexpected that mhc1ula and mhc1uma map to a region of
chromosome 22 with no apparent shared synteny to previously described MHC class I loci (Figure 1). The nearest identifiable genes, s1pr4 and zgc:171566, are located 200 to 300 kb from mhc1ula and mhc1uma in either direction. It is noted that stx6 and ier5, which
consistently flank the MHC class I-related gene MR1 in mammals (Tsukamoto et al. 2013),
Figure 1 Genomic annotation of mhc1ula and mhc1uma on chromosome 22. Exons are represented as rectangles and introns are represented as arrows pointing in the direction of transcription. Black triangles indicate the position of the genes flanking mhc1ula and
mhc1uma. Gray triangles indicate the approximate location of stx6 and ier5 which, in mammals, flank the MHC class I-related gene MR1. Annotation is based on
59 are present on zebrafish chromosome 22 (Figure 1); however there is no identifiable MHC class I-like gene between stx6 and ier5 in zebrafish and they are located approximately 11 Mb from mhc1ula and mhc1uma.
A phylogenetic comparison of Ula and Uma sequences to those representing all known MHC class I lineages in bony fish confirms that they are most similar to genes of the MHC class I U lineage (Figure 2) and validates their nomenclature. This comparison includes MHC class I sequences of interest that were predicted from a recent analysis of various teleost genomic databases (Grimholt et al. 2015). Ula and Uma show similarity to three U sequences predicted from a single scaffold (GenBank: KB882234.1) of the blind cavefish (Asme, Astyanyx mexicanus), a teleost species that diverged ~150 million years before the zebrafish (Carlson et al. 2014). However, the genes that are reported to flank this predicted U locus in cavefish display conserved synteny with zebrafish chromosome 5 rather than
chromosome 22 (Grimholt et al. 2015).
Multiple loci encoding U lineage genes have been described in the genome of Atlantic salmon (Lukacs et al. 2010), but orthologs of the genes that flank the salmon U loci are not found near the U locus on zebrafish chromosome 22. An additional lineage of MHC class I genes has been described in salmonids and has thus been termed the S lineage. The Atlantic salmon SAA gene was originally named UAA but renamed to indicate its
60 Figure 2 Phylogenetic comparison of Ula and Uma to representative MHC class I sequences of teleosts. A minimum evolution tree was constructed from the alignment of the α1-α3 domain sequences from the different MHC class I lineages of blind cavefish (Asme, Astyanyx mexicanus), zebrafish (Dare, Danio rerio), Atlantic cod (Gamo, Gadus morhua), rainbow trout (Onmy, Oncorhynchus mykiss), Atlantic salmon (Sasa, Salmo salar), pufferfish (Taru,
61 or P lineages. While the minimum evolution tree in Figure 2 shows that Ula and Uma are the most divergent members of the group, they do fall within the U lineage.
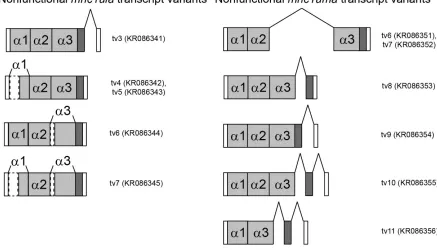
Transcript variants
Full-length transcripts of mhc1ula and mhc1uma were sequenced from each individual zebrafish from which they were detected. The amino acid sequences of each functional transcript variant (tv) are included in Online Resource 1, Figure S1. While almost no polymorphic variation was detected for either gene, both mhc1ula and mhc1uma are subject to alternative splicing as summarized in Online Resource 1, Figure S2. All identified splice variants of mhc1ula are presumably non-functional due to a frameshift caused by the retention of an intron (tv3) or by deletions at the beginning of the α1 domain and/or the α3 domain (tv4-7). A splice variant of mhc1uma was identified that lacks the α1 domain but with the reading frame maintained (tv4-5), possibly representing a functional isoform. All other recovered mhc1uma splice variants were presumably non-functional as they retained one or two introns resulting in frameshifts (tv6-11).
Predicted nucleotide and protein sequences were identified from GenBank that correspond to some of the transcript variants detected by PCR. The zebrafish non-redundant protein database includes one predicted protein corresponding to Ula (XP_001336749.4) and three predicted protein isoforms corresponding to Uma (isoform X1, XP_005161940.1; isoform X2, XP_005161941.1; isoform X3, XP_009294249.1). The majority of the
62 three nucleotide deletion at the beginning of exon 5, a polymorphism that was observed in Uma_tv5 and Uma_tv7. The sequence encoding Uma isoform X3 has a six nucleotide deletion at the beginning of exon 6, a polymorphism that was observed in Uma_tv3. A non-coding predicted transcript corresponding to mhc1ula (XR_659472.1) is present in the non-redundant nucleotide database with a deletion of 22 nucleotides at the beginning of the α3 domain, the same deletion that was observed in Uma_tv6 and Uma_tv7.
No full-length transcripts encoding Ula or Uma can be identified in the current EST database. However, the complete coding sequence of mhc1ula can be accounted for by the joining of two ESTs (start to α3 domain, EH452054.1; α3 domain to stop, EH477854.1). The
mhc1uma coding sequence is only supported by one EST that spans the start codon through part of the α1 domain (EB901873.1). In the de novo genomic assembly of a double haploid homozygous TU individual (www.sanger.ac.uk), contigs can be found that encode all three α domains for both mhc1ula and mhc1uma. In a similar de novo assembly from an AB
individual (www.sanger.ac.uk), all three α domains of mhc1uma are present, but only the α1 domain, transmembrane, and cytoplasmic exons of mhc1ula are present. It is unclear if this represents an alternate haplotype in which a functional copy of only mhc1uma is present or if this is due to insufficient sequence coverage in the assembly.
Searching outside the zebrafish database did not reveal any definitive orthologs of
mhc1ula or mhc1uma. When the α1 to α3 domains of Ula or Uma are compared to the
63 match U proteins encoded on chromosome 19. As discussed above, a phylogenetic
comparison of Ula and Uma to U proteins that were recently predicted from the genome of cavefish revealed three putative cavefish genes similar to zebrafish Ula and Uma (Figure 2).
Divergent residues at locations of functional consequence
64 Figure 3 Zebrafish MHC class I U lineage protein sequence alignment. The zebrafish U proteins included in Figure 2 were organized into domains and aligned. The leader and α domains are each encoded by a single exon while the transmembrane (TM) and cytoplasmic (Cyt) domains are encoded by a variable and sometimes unknown number of exons.
Numbering of amino acids is based on the Uba sequence starting with the first residue of the α1 domain. Positions that are at least 50% identical are shaded in black and similar residues are shaded in gray. Conserved features are indicated with the following symbols below the alignment: cysteine residues likely involved in the Ig-fold (*), putative anchor residues implicated in binding the amino- (n) or carboxy-terminus (c) of peptides, acidic residues in the α3 domain predicted to bind CD8 (a), and the putative transmembrane domains (/). Note: the indicated transmembrane region does not accurately portray the borders of all