Environments
DIONISIS ATHANASOPOULOS VALERIE ISSARNY EVAGGELIA PITOURA PANOS VASSILIADIS and APOSTOLOS ZARRASIn this paper we propose CoWSAMI, a service-oriented middleware that aims at supporting context-awareness in pervasive computing environments. To this end, we rely on the standard Web services architectural style to handle the architectural heterogeneity of available context sources. CoWSAMI balances the trend between the resource limitations of available context sources and the resource requirements introduced by the aforementioned standard, by employing WSAMI, a lightweight middleware infrastructure for the development of mobile Web services. CoWSAMI provides a dynamic and highly scalable service discovery mechanism that deals with the increased behavioral mobility of available context sources. CoWSAMI further handles the behavioral het-erogeneity of available context sources through a mechanism that gathers contextual information while adapting its proper behavior to the interfaces of context sources. Finally, CoWSAMI allows querying for contextual information with respect to the aforementioned organization, though a classical SQL-based interface.
Categories and Subject Descriptors: []: General Terms:
Additional Key Words and Phrases: context-awareness, middleware, pervasive environments, Web services
1.
INTRODUCTION
Literally, context is defined as”the interrelated conditions in which something ex-ists or occurs” [Merriam-Webster 2005]. In most cases, conditions change and the entities that function under them must adapt so as to continue their proper func-tioning. However, the precondition to adaptation isawareness. The entities must somehow know about context changes. In other words, they must be capable of obtaining information that reflects the conditions under which they function.
”How do we achieve context-awareness in pervasive computing environments?” The above question is the main issue tackled in this paper. Context in computing is defined as”a person, place, or object that is considered relevant to the interaction between a user and an application, including the user and applications themselves” [Dey 2001]. On the other hand, pervasive computing environments are the natural evolution of conventional distributed systems that comes along with the emergence Authors’ address: A. Zarras, E. Pitoura, P. Vassiliadis, D. Athanasopoulos, Computer Science Dep., University of Ioannina Campus, PO BOX 1186, GR 45110, Ioannina, Greece.
Author’s address: Valerie Issarny, INRIA Rocquencourt, Domaine de Voluceau, BP 78150, Le Chesnay, France
of various novel technologies such as hand-held computers, wireless networks and sensor devices. Pervasive computing is a combination of ubiquitous computing, networking andintelligent interfaces [Issarny et al. 2005]. The first two terms refer to the existence of computing devices and networking facilities everywhere. The third term relates to the capability of the system that supports the environment to adapt to the specificities of the entities that use it. Naturally, this capability should be offered by the middleware layer of the system.
To be context-aware in a pervasive computing environment, one has to be knowl-edgable of the sources that provide contextual information. This is the first obstacle to context-awareness: in pervasive computing environments it is often the case that context sources aremobile. Context sources may be mobile in two senses: first, they may arbitrarilyjoinandleave the environment and second, their computational re-sources may be limited (e.g., battery, memory, storage, etc.). Hereafter, we refer to the former aspect of mobility asbehavioral mobility. Moreover, we use the term architectural mobility to refer to the second aspect of mobility.
To be context-aware, one has to be further able to communicate with context sources. Hence, we arrive to the second obstacle: context sources are highly hetero-geneous. As with the case of mobility, heterogeneity appears in two senses, archi-tectural and behavioral. Architectural heterogeneity refers to the different device types, operating systems, implementation languages and communication protocols assumed by the different context sources. Behavioral heterogeneity relates to the different interfaces provided by context sources. Specifically, in a pervasive comput-ing environment semantically compatible contextual information may be provided through different types of interfaces.
Dealing with heterogeneity and mobility towards context-awareness is not straight-forward. Until now, research in the field of context-aware middleware and appli-cations focused mostly on the aspects of modeling and reasoning about context changes and adaptation actions [Baldauf et al. 2005], while skipping the first im-portant step that comprises a realistic approach for obtaining information about these changes. Existing approaches to context-awareness assume that the behavior of context sources adheres to constraints (e.g., by providing infrastructure specific interfaces) imposed by the middleware infrastructure in charge of obtaining con-textual information. In this paper, we go one step further by adding interface intelligence in the environment along with ubiquitous computing and networking. Specifically, we propose CoWSAMI : a middleware infrastructure that adapts its proper behavior to the behavior of context sources to support context-awareness.
How does CoWSAMIdeal with architectural heterogeneity?
CoWSAMI relies on the standard Web services architecture [W3C 2004a]. Web services are software entities with well-defined interfaces identified by a URI (i.e., a Uniform Resource Identifier such as a Uniform Resource Location (URL) of a Uniform Resource Name (URN)). Their interfaces are specified using WSDL (Web Services Description Language)[W3C 2005]. Interaction with Web services is re-alized though messages that follow the SOAP standard [W3C 2002]. SOAP may rely on a variety of other communication protocols such as HTTP and SMTP. In CoWSAMI, we employ Web services to confront the increased architectural hetero-geneity of pervasive computing environments by encapsulating context sources and
exporting their operations through platform-independent interfaces. The overall development of Web services for heterogeneous context sources may be automated (e.g. in [Plitsis et al. 2005] we discuss the particular case of automating the inte-gration of GSM-enabled mobile sensors in pervasive environments).
How does CoWSAMIhandle architectural mobility?
The current practice with Web services has showed that the middleware in-frastructures that support their development are certainly not lightweight. The fact that Web service descriptions rely on an XML-based language (i.e., WSDL) makes their processing quite demanding in computational resources (e.g., memory and CPU time). Similarly, SOAP defines an XML-based message format. Therefore, processing SOAP messages is also demanding regarding computational resources. To deal with these issues, CoWSAMI extends previous work on WSAMI [Issarny et al. 2005], a lightweight middleware infrastructure that supports the development of mobile Web services.
How does CoWSAMIdeal with behavioral mobility?
Amongst its core services WSAMI provides the Naming&Discovery service that allows discovering networked WSAMI entities with respect to a given interface that they should provide. On top of Naming&Discovery, CoWSAMI provides a service for context sources discovery, named ContextManager. Specifically, the ContextManager manages a constantly changing repository of context sources with respect to various update policies customized by context-aware entities. Each entity deploys locally its proper instance of the ContextManager service.
How does CoWSAMIhandle behavioral heterogeneity?
CoWSAMI provides a service, named ContextCollector, whose main purpose is to resolve the behavioral heterogeneity of context sources. To achieve this, we introduce the concept of context rules. Roughly, a context rule specifies how to obtain the values of context attributes by using different types of interfaces offered by different categories of context sources. The rule is defined with respect to the operations that should be invoked on each different interface and the structure of the messages, exchanged during the invocations. Context rules are given as input to the ContextCollector service. Following, the service tailors its proper behavior with respect to the context sources included in a particular pervasive computing environment.
Finally, CoWSAMI provides an easy to use front-end service, named QueryExe-cutionEngine, for the collection of contextual information. In a typical situation of a pervasive computing environment, the users will not be sitting comfortably in front of their workstation, having the ability to write down code that uses CoWSAMI services to gather contextual information. Moreover, the typical users will not be ex-perienced developers, familiar with Web service programming. Hence, they should be provided with more simple means, which will allow them to efficiently collect contextual information. To this end, we rely on ideas from the field of traditional databases. Typical database query languages provide a classical declarative way for managing and exploring information stored in a database. In our case, the data-base is substituted by contextual information, stored everywhere in the pervasive computing environment. Hence, it is challenging to keep the same classical front-end for gathering this contextual information. The QueryExecutionEngine service
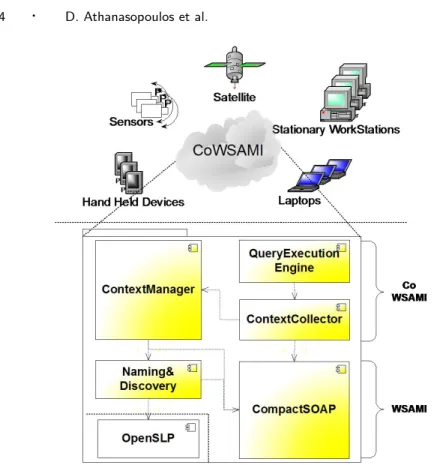
Fig. 1. CoWSAMI Architecture
incarnates this idea by accepting as input SQL-based queries and transforming them to Web service invocations (in collaboration with the ContextManager and the ContextCollector services), targeted to context sources.
The remainder of this paper is structured as follows. Section 2 details the archi-tecture of CoWSAMI and further motivates its use through a reference example. Moreover, Section 2 summarizes the foundation WSAMI services that are used in CoWSAMI. Section 3 details the behavior of the ContextManager, the ContextCol-lector and the QueryExecutionEngine services. Section 4 provides an experimental evaluation of CoWSAMI. Section 5 discusses related work from the fields of service-oriented, pervasive and context-aware computing. Finally, Section 6 concludes this paper with a summary of our contribution and the future research directions of this work.
2.
COWSAMI ARCHITECTURE
Figure 1 gives our perception of a pervasive computing environment and an overview of the CoWSAMI architecture. The main constituents of the architecture are dis-cussed in Section 2.1. The foundation WSAMI services upon which CoWSAMI relies are detailed in Section 2.2. Finally, Section 2.3 introduces a reference exam-ple that serves for illustrating the use of CoWSAMI.
2.1
Architecture
A pervasive computing environment consists of a set of networked entities, devel-oped on top of the CoWSAMI infrastructure. The entities are connected through a typical LAN or WLAN (Wireless Local Area Network). A pervasive environ-ment may further comprise entities located on the Internet. The latter must be registered on specific universal service repositories which may be optionally in-corporated in the environment by the entities that constitute it during the con-figuration of the CoWSAMI infrastructure. The entities may vary in type from typical stationary workstations and PCs to hand-held and embedded devices such as PDAs, smart-phones, sensors, etc. Given that WSAMI supports both ad-hoc and infrastructure-based connectivity, this particular issue is transparent to CoWSAMI. Each CoWSAMI entity may provide a number of Web services and use services of other entities. CoWSAMI services are specified using the WSAMI language that extends WSDL with features enabling a more detailed behavioral description.
Specifically, a WSAMI specification consists of anabstract and aconcrete part. The abstract part specifies the interface of a service and all the possible valid conversations that can be realized through this interface. The interface is given in terms of a WSDL document, whose URI is referenced in the abstract part. The conversations are given in terms of a standard WSCDL (Web Services Choreography Description Language) [W3C 2004b] document, whose URI is also referenced in the abstract part of the service specification. More than one WSAMI specifications may have the same abstract part, as long as they describe services providing the same interface. The concrete part of the WSAMI specification contains binding information (e.g., the endpoint address of the service, the communication protocol used, etc.). The WSAMI specification may optionally include a third part that contains references to URIs of documents describing other WSAMI services used by this particular one.
Every CoWSAMI entity may be considered as a context source that provides information through its services. The context that interests an entity is modeled by a set of context attributes of a specific type. The contextual information that corresponds to a context attribute is a value provided by a context source. In general, a pervasive computing environment may comprise more than one context sources that report semantically equivalent information (e.g., two different cars reporting their current velocity). Moreover, a context source may provide values for more than one semantically related context attributes (e.g., the velocity and the brand of a car). Therefore, related context attributes are organized into relations. Acontext relation is characterized by aname anda finite set of context attributes. The contextual information modeled by a relation is a finite set of tuples, i.e., a finite subset of the cartesian product of the domains of the attributes that constitute the relation. This database-like modeling of contextual information allows formulating queries against relation instances, which are populated at runtime through the use of CoWSAMI services.
Specifically, a CoWSAMI entity comprises instances of three CoWSAMI ser-vices, named ContextManager, ContextCollector and QueryExecutionEngine. The ContextManager provides operations allowing context sources to join and leave a pervasive environment. The ContextManager is further responsible of locating
reachable CoWSAMI entities that may serve as context sources for the information that interests the entity. To achieve this, the WSAMI Naming&Discovery service is used. The services provided by context sources are categorized with respect to the interface that they provide (i.e., with respect to the abstract part of their WSAMI specifications). Information concerning every different category is stored into a local repository maintained by the ContextManager. The repository contents are updated with respect to the following three alternative policies:
—Update-On-Demand: the repository contents are updated upon a request issued by the entity that comprises the ContextManager.
—Periodic-Update: the repository contents are updated periodically, with respect to a period given as input to the ContextManager by the entity.
—Always-Update: the repository contents are updated whenever a context source of interest joins or leaves the environment.
The users of the entity are responsible for defining the context relations that interest them, using the ContextCollector service. Then they may issue context queries for these relations, through the QueryExecutionEngine service. Following, the service makes use of the ContextCollector to dynamically compile the context relations that concern the queries. The resulted information is further processed with respect to typical query processing operators and returned to the users. The ContextCollector compiles the context relations with respect to the contents of the repository that is maintained by the ContextManager. For every different category of context sources, it uses different context rules so as to compile the relations. As discussed in Section 1, a context rule specifies how to obtain the values of the context attributes that constitute a relation though the use of the interface of a particular category of context sources. The definition of context rules is also a responsibility of the entity’s users.
2.2
WSAMI Foundation Services
The main constituents of WSAMI that were used as a basis for the realization of CoWSAMI are the CSOAP broker and the Naming&Discovery service.
CSOAP is a lightweight mechanism that allows to deploy, invoke and execute Web services on resource-constrained devices. Specifically, resource-constrained entities issue SOAP requests towards Web services, through standard JAXRPC [SUN 2004b] invocations. The target Web services serve these requests and reply back with SOAP response messages that are also issued through CSOAP. CSOAP was realized on top of the standard J2ME (Java 2 Micro Edition) platform [SUN 2004a] and comes along with the following tools:
—A compiler that generates Java stubs from WSAMI service specifications. —The WSDL2WSAMI tool that generates WSAMI specifications for
WSAMI-enabled Web services, given their pure WSDL specifications.
—The InstallWSAMI tool that deploys and configures services on the WSAMI middleware.
The Naming&Discovery service is a mechanism for dynamic service discovery. An instance of the service is deployed on every WSAMI entity. The service in-stance manages two repositories, storing information regarding Web services that
are available in the environment. Specifically, the information stored for each avail-able service is the URI of the service’s WSAMI specification. The overall discovery process is realized using URIs instead of XML documents to economize resources on the side of resource-constrained devices.
The first repository maintained by the service is named local repository and contains the URIs of the Web services provided by the WSAMI entity that hosts the repository. The second repository is calledremoterepository and acts as a local cache that contains URIs of Web services deployed on other reachable WSAMI entities. The remote services were once discovered by the entity that hosts the remote repository, using the Naming&Discovery service. The size of the remote repository is set during the configuration of WSAMI infrstracture. The repository’s replacement strategy follows the LRU (Least Recently Used) policy. Locating Web services though the Naming&Discovery service is done according to the following steps:
(1) An entity requests the URI of an abstract WSAMI specification that describes the interface of the required Web services.
(2) Based on the given URI, the local and the remote repositories of the Nam-ing&Discovery service deployed on the requesting entity are searched for match-ing URIs. The results obtained may be of the followmatch-ing kinds:
(a) URIs of services provided by power-plugged WSAMI entities that reside on the WLAN of the requesting entity.
(b) URIs of services provided by power-plugged WSAMI entities on the Inter-net.
(c) Matching URIs of services provided by non power-plugged entities. (3) The entity’s request is forwarded to all other reachable Naming&Discovery
ser-vice instances. Each of these instances performs step 2 and returns the results back to the requesting entity. If a reachable service instance fails to locate a matching URI it does not further forward the request and responds with an exception. The identification of other reachable Naming&Discovery service instances primary relies on the standard SLP (Service Location Protocol) pro-tocol [Guttman et al. 1999]. Specifically, we use the OpenSLP1implementation
of this standard. Every CoWSAMI entity comprises an SLP server. The Nam-ing&Discovery service of the entity registers to this server. The latter is respon-sible for periodically multicasting the address of the local Naming&Discovery service to every other reachable Naming&Discovery service.
(4) Optionally, the entity’s request is forwarded on a universal service repository, specified during the initialization of the Naming&Discovery service.
In the previous steps we assume the existence of an infrastructure-based network. In the case of an ad-hoc one, similar steps are performed [Issarny et al. 2005; Sailhan and Issarny 2003]. Moreover, the previous steps are used in the case where an entity wants to locate all services providing a required interface. A similar discovery process is used in the case where the entity looks for only one service providing this interface. The overall discovery process may be further enhanced
with additional QoS criteria (e.g., reliability, availability, reputation, performance) that are currently under investigation [Liu and Issarny 2004; Zarras et al. 2004; Papadopoulos et al. 2005].
2.3
Reference Example
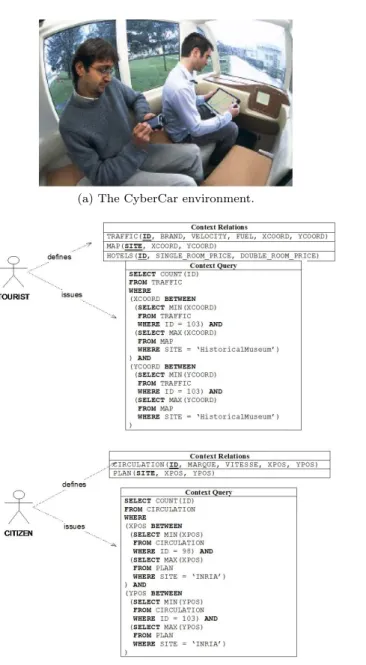
To illustrate the CoWSAMI approach we extend the reference example used in [Is-sarny et al. 2005] for demonstrating WSAMI. Specifically, we assume a pervasive computing environment at the city of Rocquencourt, near Versailles. Our environ-ment offers CyberCars2 to Rocquencourt citizens and tourists (Figure 2(a)). Cy-berCars are unmanned cars that may be booked though the Web, towards moving across different sites of the city. Each CyberCar is equipped with its own comput-ing facilities. Moreover, it may communicate with other entities through a wireless network. In the general case, different types of CyberCars may exist, possibly com-ing from different manufacturers. Their embedded computer is a CoWSAMI entity that provides information regarding the CyberCar’s features (e.g., velocity, posi-tion, brand etc.). Contextual information is provided through Web services offering possibly different manufacturer-specific interfaces.
Figure 3(a) and (b) give the WSAMI specifications (abstract parts) of the services of two different types of CyberCars. Specifically, CyberFrogs (Figure 3(a)) provide an homonymous Web service whose interface offers 6 different operations that can be invoked to obtain a unique identifier that characterizes each CyberFrog , the CyberFrog ’s brand, velocity, fuel, and coordinates. On the other hand, CyberCabs (Figure 3(b)) provide a Web service that offers a single operation, named getState(). This operation responds with a message that encapsulates all the characteristics of a CyberCab (i.e., its identifier, brand, velocity and coordinates). The city of Roc-quencourt further offers Web services that provide information regarding the city’s hotels and restaurants. The interfaces of these services may also vary depending on the different hotel companies and restaurants (e.g., IBIS, Novotel, etc.). Finally, the Rocquentcourt city-hall provides a Web service that reports the location of various sites (monuments, organizations, hospitals, business centers, etc.).
The contextual information that interests the CyberCar passengers may vary and the way to collect it is though CoWSAMI. To achieve this, the passengers must be equipped with CoWSAMI-enabled devices such as PDAs, laptops or smart-phones. Each passenger may define the context that interests him in its proper way. Take, for instance, the case of an English speaking tourist who is interested in the current status of the traffic and the available city hotels. Using his PDA, he may define the relations given in the upper part of Figure 2(b). The first relation is named TRAFFIC and consists of 6 attributes (named ID, BRAND, VELOCITY, FUEL, XCOORD and YCOORD) that correspond to the unique identifier of each Cyber-Car that circulates in the environment, its brand, velocity, fuel and coordinates. A typical tuple of this relation could be the following: (103, NetMobilFrog, 40, 0.75, 1000.56, 500.67). The second relation is named MAP and consists of three attributes that correspond to the name of a site and the coordinates that determine the location of this site. The third relation is called HOTELS and comprises 3 at-tributes that correspond to a hotel identifier, and the prices for single and double
(a) The CyberCar environment.
(b) Context relations and queries.
Fig. 2. Using CoWSAMI in the city of Rocquencourt.
rooms.
A French speaking Rocquencourt citizen may be interested only in the current status of the city traffic. Therefore, he may exploit the context relations given in the lower part of Figure 2(b). The first relation is analogous to the TRAFFIC relation defined by the tourist; it is named CIRCULATION and consists of 5 attributes, named ID, MARQUE, VITESSE, XPOS and YPOS. The second relation is named
(a) The CyberFrog interface.
(b) The CyberCab interface.
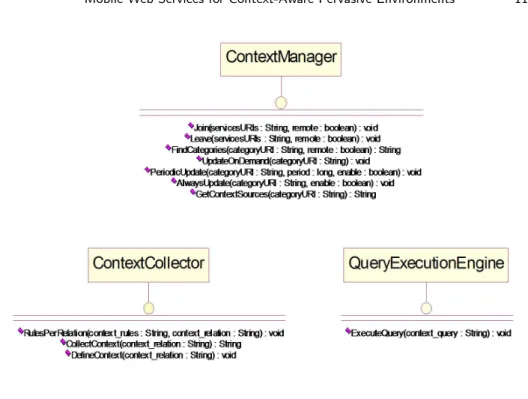
Fig. 4. CoWSAMI services.
PLAN and it is similar to the MAP relation, defined by the tourist.
The upper part of Figure 2(b) further shows a query issued by the tourist against the TRAFFIC relation. The query returns the number of CyberCars that circu-late in an area defined by the current position of the tourist’s CyberCar and the position of the tourist’s destination. Similarly, the lower part of Figure 2(b) shows the query that is issued by the Rocquencourt citizen to check for the current status of the traffic towards the citizen’s destination. Answering any of the two queries amounts in checking the position of all the different CyberCars that can be ac-cessed. Finding these entities and categorizing them with respect to the different interfaces that they provide (e.g., CyberFrogs and CyberCabs) is a responsibility of the ContextManager. Collecting the position of each entity is performed using the ContextCollector with respect to context rules, given for every different category of CyberCars.
3.
COWSAMI SERVICES
The interfaces of the core CoWSAMI services are depicted in Figure 4. Follow-ing, we discuss further details regarding the realization of these services. Section 3.1 details the ContextManager service, Section 3.2 presents the ContextCollector. Finally, Section 3.3 discusses QueryExecutionEngine service.
3.1
The ContextManager service
A CoWSAMI entity joins or leaves a pervasive computing environment by invoking the homonymous operations of the ContextManager interface (Figure 4). More-over, an entity discovers the different types of interfaces provided by the context
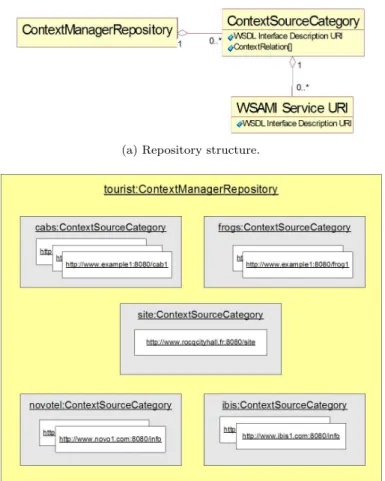
sources available in the environment through the use of the FindCategories() op-eration. That way the entity becomes aware of the different categories of context sources. Following, it may use the UpdateOnDemand(), the PeriodicUpdate() or the AlwaysUpdate() operations to populate the repository that stores URIs of avail-able context sources of interest and (re)configure the policy used for updating the repository’s contents. Figure 5(a) gives the general structure of the repository. As discussed in Section 2, the repository consists of a number of categories. A category is characterized by the URI of the WSDL description that specifies the particular interface provided by the context sources belonging in the category. All the URIs stored in the category correspond to WSAMI specifications, whose abstract parts reference the URI that characterizes the category. The category is further charac-terized by the names of the context relations to which it contributes.
Figure 5(b), for example, gives a possible snapshot of the repository managed by the ContextManager deployed on the English tourist’s PDA. The repository comprises 2 categories for CyberCar URIs, 2 categories for hotel URIs and a single category for the Rocquencourt city hall service. The first of the CyberCar categories is characterized by the URI of the CyberFrog interface given in Figure 2(b). Sim-ilarly, the second category is characterized by the URI of the CyberCab interface given in Figure 2(c). The CyberFrog category contains 2 URIs of networked ser-vices providing this interface. On the other hand, the CyberCab category contains 3 URIs of networked CyberCab services. The hotels categories are characterized by URIs that correspond to IBIS and Novotel specific interfaces.
3.1.1
Joining a pervasive computing environment.
A CoWSAMI entity that wishes to play the role of a context provider to other CoWSAMI entities must call the Join() operation. The Join() operation accepts as input the URIs of the services offered by an invoking entity. In our example, every CyberCar entity must call the Join() operation so as to become available as a context source to passengers. Similarly, every hotel and restaurant entity must join the pervasive computing environment.For every service given as input to the Join() operation, the following steps are performed:
(1) The service is registered to the local Naming&Discovery service.
(2) The repository managed by the ContextManager is checked for the existence of a category characterized by an interface that matches the interface of the service. To achieve this step the abstract part of the WSAMI service specifi-cation is used. If the category exists the service URI is stored in this category, otherwise the ContextManager constructs a new category in the repository and stores the given URI .
(3) The ContextManager checks for the existence of other networked CoWSAMI entities, requiring that their ContextManager repositories are always up-to-date (e.g., the passengers of CyberCars that are interested in the current status of the city traffic). In other words, the ContextManager looks for entities that previously enabled the Always-Update policy as detailed in Section 3.1.3. To achieve this, the Naming&Discovery service is used in a first step for locat-ing reachable ContextManagers available in the environment. Followlocat-ing, it is
(a) Repository structure.
(b) Repository instance.
Fig. 5. ContextManager repository.
checked whether any of them have their Always-Update policy enabled for the particular category of context sources that includes the given service. Then, the ContextManager of the joining entity calls Join() on the aforementioned ContextManagers. The input to these calls is the URI of the service of the joining entity along with a flag that notifies the invoked entities that this is an update call performed by the ContextManager of a joining entity. In response, the invoked ContextManagers perform steps 1-2 mentioned above.
3.1.2
Leaving a pervasive computing environment.
The Leave() opera-tion should be used by entities that wish to resign from playing the role of context sources to other entities. The input given to the Leave() operation is the URIs of the services that were registered to the Naming&Discovery service by these enti-ties at the time when they joined the environment. In our reference example, the Leave() should be called, for instance, by CyberCars that no longer wish to be context sources, possibly because they are parked. Similarly, the Leave() operation may be called by hotels that are full-booked.For every given URI, the following steps are performed by the ContextManager of the leaving entity:
(1) The service is unregistered from the local Naming&Discovery service.
(2) The repository managed by the ContextManager is searched for the category that contains the given URI . This step is realized with respect to the abstract part of the WSAMI service specification that is referenced by the given URI . Following, the URI is removed from the category (actually for efficiency reasons the URI is marked unavailable for a certain time period before it is removed). (3) The ContextManager of the leaving entity checks for the existence of other net-worked CoWSAMI entities that previously enabled the Always-Update policy for the particular category of context sources. Then, the ContextManager calls the Leave() operations on the ContextManagers of these entities. The input to these calls is the URI of the service of the leaving entity and a flag that notifies the invoked entities that this is an update call performed by the ContextMan-ager of a leaving entity. Given this input, the invoked ContextManContextMan-agers proceed with performing steps 1-2 mentioned above.
3.1.3
Discovering available categories of context sources.
To find out about the available categories of context sources in a pervasive computing environ-ment, an entity calls the FindCategories() operation. In our reference example, for instance, tourists and Rocquencourt citizens must call this operation to find out about the different types of context sources available in the city. The operation may be called more than once by the entities as the availability of different types of context sources may change along with the availability of the context sources themselves.The realization of the operation proceeds as follows:
(1) First, a list of reachable ContextManager services is located, using the Nam-ing&Discovery service.
(2) Then, FindCategories() operation is called on each one of these services with a flag that notifies the invoked services that this is a call made by a remote ContextManager. In response, the invoked ContextManager services sent the URIs of the WSDL interface specifications supported by the different services offered by the entity where they are deployed.
(3) Finally, the overall set of WSDL interface specifications that results from the aforementioned invocations is returned to the calling entity.
3.1.4
Populating the repository.
The UpdateOnDemand() operation ac-cepts as input a category of context sources (particularly the input is the URI of the WSDL interface specification that characterizes the category). The contents of this category are immediately updated upon a call on the operation. In our refer-ence example the UpdateOnDemand() operation could be called by Rocquencourt tourists for the hotels category. The availability of hotel services are not expected to change fast. Therefore, it is reasonable to use the Update-On-Demand policy towards discovering the URIs of these servicesSpecifically, upon a call to the UpdateOnDemand() operation, the ContextMan-ager performs the following steps:
(1) If the given category does not exist in the repository maintained by the Con-textManager, it is created.
(2) The local Naming&Discovery service is invoked towards locating reachable en-tities that provide services offering the interface that characterizes the given category. The result of this call is the set of the URIs of the services (e.g., the hotel services URIs of Figure 5(b)). Before storing the retrieved URIs in the given category there are two further issues resolved by the ContextManager: (a) If the ContextManager is deployed on a resource-constrained device, it
checks whether the retrieved URIs correspond to services that actually ex-ist in the environment. In particular, a URI may be discovered in the remote repository of a networked Naming&Discovery service. As discussed in Section 2.2, the remote repositories act as LRU caches. Hence, it is probable that the cashed URI is no longer valid. To perform this check, an operation is randomly picked based on the WSDL interface that character-izes the category of the service whose URI is checked. Following, this oper-ation is called by the ContextManager. If an exception is raised, the URI is considered invalid, otherwise the URI is normally stored in the category. The validity check of the URIs discovered through the Naming&Discovery service could be avoided for the shake of efficiency. However, this would imply that certain context sources are going to be used by the ContextCol-lector service (possibly more than once) without actually being available. This may eventually result into a significant energy lick. Even though the validity of URIs is checked, it is important to note that they may become invalid until the time they are used for collecting contextual information. Therefore, the URIs validity check is actually a best-effort approach for reducing energy consumption.
(b) The ContextManager further checks if the entities that provide the re-trieved URIs are CoWSAMI-enabled. Specifically, it is checked whether the entities provide a ContextManager service. This particular constrain is necessary for the realization of the Always-Update-Policy that may be potentially activated by the invoking entity.
Naturally, the PeriodicUpdate() operation accepts as input a category of context sources and a time period T. Invoking the operation results on the creation of a new thread which resumes its execution every T time units. At this point, it invokes the UpdateOnDemand() operation so as to update the repository contents of the given category. The AlwaysUpdate() operation also takes as input parameter a category. The entities that belong in this category are discovered by calling the UpdateOnDemand() operation. Following, the invoked ContextManager notifies all the ContextManagers of the entities that provide services of the given category about the fact that the invoking entity enabled the Always-Update policy for this particular category. Based on this setup, the invoked entities are able to notify the invoking one about their leaving through the use of the Leave() operation (Section 3.1.1).
In our reference example, it is reasonable to assume that tourists and Rocquen-court citizens use either the PeriodicUpdate() or the AlwaysUpdate() operation to discover available CyberCar services. The availability of CyberCar services typically
changes much faster than hotel services. Therefore, it is natural to use the Periodic-Update or the Always-Periodic-Update policies for updating the corresponding repository categories.
3.2
The ContextCollector service
A CoWSAMI entity defines the context relations that interest it by invoking the DefineContext() operation of the ContextCollector interface (Figure 4). Similarly, it uses the RulesPerRelation() operation to define context rules for these relations. The CollectContext() operation serves for populating the defined relations with contextual information.
3.2.1
Defining context.
Figure 6(a) shows the general structure of a con-text definition provided as input to the DefineConcon-text() operation. As discussed in Section 2.1, a context definition comprises a set of context relations characterized by a name and a number of context attributes. An attribute is characterized by a name and a type. Figure 6(b) gives the actual XML schema used for context definitions. According to this schema, relations are specified using the ContextRe-lation tag. Within this tag we can define one or more context attributes using the ContextAttribute tag. Figure 6(c) gives the context relation definitions defined in our reference example in the case of the English tourist.Given a context definition, the following steps are performed by the ContextCol-lector service.
(1) The definition is parsed towards identifying its constituent relations. (2) Every relation is parsed towards locating its constituent attributes.
(3) For every relation, a corresponding table is created and stored persistently (e.g., in a typical file in the case of CoWSAMI entities deployed on stationary workstations, in the persistent storage memory part, in case of CoWSAMI entities deployed on mobile devices such as PDAs, mobile phones, etc.)
3.2.2
Defining context rules.
The WSDL interface of a particular category of context sources is specified in terms of a number of PortType definitions (Fig-ure 4(a), (b)). A PortType, in turn, consists of the definitions of a number of operations that can be called on the context sources interface. Each operation specifies an input and an output message. The former element refers to the SOAP request message sent upon the operation invocation, while the latter element refers to the SOAP message returned in response to the invocation. The specification of a message consists of one or more parts. Each part is characterized by a name and the particular type of datum exchanged between a service that provides the interface and an entity that uses this service.Therefore, a context rule that describes how to populate a context relation, using the interface of a particular category of context sources is specified according to the schema given in Figure 7. In particular, a context rule is characterized by the name of the context relation (described using the ContextRelation tag) and the URI of the WSDL interface specification (described using ContextSourceCategory tag). The rule further comprises one or more ContextAttributeMapping elements. Each of these elements refers to a context attribute of the specified relation (specified using the ContextAttribute tag) and an operation (specified using the
ContextSourceOp-(a) Context structure.
(b) Context schema.
(c) Context example.
Fig. 6. Context definition.
eration tag) offered by the specified interface ; it specifies how to obtain a value for the attribute by invoking this operation. Specifically, a ContextAttributeMapping element comprises two constituent parts. The ContextInputMessage part is charac-terized by the type of the request message that should be sent upon the operation invocation. The ContextInputMessage part further specifies a sequence of values that should be the contents of the message sent upon the operation invocation. The ContextOutputMessage part is characterized by the type of the response message received after the operation invocation (specified using the ContextSourceMessage tag). Moreover, the ContextOutputMessage part specifies the name of the actual part of the response message that contains the value of the specified context at-tribute (specified using the ContextSourceMessagePart tag).
(a) Context rules structure.
(b) Context rules schema.
Context rules are given as input to the ContextCollector service by invoking the RulesPerRelation() operation, offered by this service. Following, every rule is parsed and its embedded ContextAttributeMapping elements are grouped with respect to the operation that has to be called to fill up the value of a context attribute. This grouping is necessary for optimizing the collection of contextual information in cases where the values of more than one attributes are obtained by calling a single operation for all of them (e.g., Figure 8(b)). Finally, every context rule is stored persistently in the device where the ContextCollector service is deployed.
Getting to our reference example, Figure 8(a) gives the rule that describes how to populate the TRAFFIC relation defined by the English tourist (Figure 6(c)), using the interface of CyberFrog entities (Figure 4(a)). The rule specifies a context attribute mapping for each one of the ID, BRAND, VELOCITY, FUEL, XCO-ORD, YCOORD attributes. To obtain a value for the VELOCITY attribute, for instance, the getVelocity() operation must be invoked. No input message is needed for this invocation since the operation accepts no input parameters. The actual value of VELOCITY is stored in the getVelocityReturn part of the getVelocityRe-sponse message (see Figure 4(a) for the definitions of these WSDL elements) that is returned upon the invocation on the aforementioned operation. Similarly, to obtain a value for the ID attribute, the getID() operation must be invoked. Again, there is no need for an input message for this invocation. The value of ID is stored in the getIDReturn part of the getIDResponse message.
On the other hand, Figure 8(b) gives the rule that describes how to populate the same relation, using the interface of CyberCab entities (Figure 4(b)). To obtain a value for the VELOCITY attribute, in this case, the getState() operation must be invoked. The value of VELOCITY is now stored in the Velocity part of the getStateResponse message. Similarly, to obtain a value for the ID attribute, the same operation must be called. The value of the attribute is stored in the ID part of the aforementioned message.
3.2.3
Collecting contextual information.
Collecting contextual informa-tion amounts in calling the CollectContext() operainforma-tion on the ContextCollector service. This operation accepts as input a context relation. Then, it performs the following steps:(1) The different categories of context sources that contribute in the collection of tuples for the given relation are located in the repository.
(2) The context rules for every category obtained from the previous step are loaded. (3) The operations prescribed in every rule are executed for every different context
source URI stored in the corresponding category.
(4) The response message from every invocation is parsed towards obtaining the values of one or more context attributes of a tuple.
(5) Finally, the resulting tuples are returned to the invoking entity, which is further provided with the option of storing these tuples persistently.
Taking our reference example, suppose that CollectContext() is invoked to dy-namically assemble the tuples of the TRAFFIC relation. The two categories of context sources that contribute to this relation are those providing the CyberFrog
(a) Context rules for the CyberFrog interface.
(b) Context rules for the CyberCab interface.
Fig. 8. Context rules examples.
and the CyberCab interfaces (Figure 4(a), (b)). The rules obtained for these cat-egories are the ones given in Figure 8(a), (b). For every CyberCab URI stored in the cabs category (Figure 5(b)), the getState() operation is called. The response message of each invocation results in a different tuple of the TRAFFIC relation. On the other hand, for every CyberFrog URI stored in the frogs category, more than one operations are called to compile a tuple. Each operation contributes to a different attribute of the given context relation.
3.3
The QueryExecutionEngine service
Currently, the QueryExecutionEngine service simply assembles the functionality provided by the rest of the CoWSAMI services to allow executing SQL queries on contextual information collected by reachable context sources.
The fundamental steps of the QueryExecutionEngine are as follows:
(1) For every context relation specified in the FROM clause of a query, the Col-lectContext() operation is called on the ContextCollector service.
(2) The compiled tuples returned by each invocation are processed with respect to the given query and results are returned back to the issuing entity.
(3) The processing of the tuples can be built differently, depending on whether the issuing entity is resource-constrained or not. Specifically:
—For the case of resource-constrained entities, the QueryExecutionEngine com-prises a simple set of main memory relational operators that directly process the incoming tuples. This lightweight configuration is suggested for a limited subset of any query language and can manage only a small size of incoming tuples. A possible alternative that we further investigate is the integration of the QueryExecutionEngine with existing DBMS support for such kind of devices (e.g. Oracle Lite [ORACLE 2004], IBM DB2 Everyplace [Karlsson et al. 2001]).
—For non-resource-constrained entities, the QueryExecutionEngine is integrated with a full blown relational engine. Up to now, we particularly focus on the integration of the QueryExecutionEngine service with MySQL, due to our previous experience with this specific relational engine. However, several other similar technologies may be used.
4.
EXPERIMENTAL EVALUATION
To assess CoWSAMI we implemented a first prototype of the services discussed in Section 3. The services were implemented on top of WSAMI. Therefore, their resource requirements and performance depend on the corresponding resource re-quirements and performance of the basic WSAMI constituents that were discussed in Section 2.
4.1
CoWSAMI resource requirements
In this section we specifically detail the memory requirements of the ContextMan-ager and the ContextCollector services. The issue of energy consumption is also discussed for these services. As mentioned in Section 3.3, the realization of the QueryExecutionEngine may rely on various configurations possibly built on top of existing commercial solutions. Its resource requirements depend, thus, on these configurations, whose experimental evaluation is not detailed in this paper.
Currently, resource-constrained devices come with various technical characteris-tics (CPU, OS, memory, autonomy, etc.)3. The available memory in the most recent models of PDAs ranges from 8MB to 256MB. However, there still exist few PDA models that come with less than 4MB of RAM. Similarly, the memory provided by the most recent smart-phones ranges from 8MB to 32MB, while there still exist few models that come with less than 4MB of RAM. The overall memory footprint of the WSAMI platform is 3.9MB [Issarny et al. 2005]. Therefore, it is suitable for CoWSAMI entities that execute on top of devices providing at least 8MB of memory.
(a) ContextManager service.
(b) ContextCollector service.
Fig. 9. Memory requirements of CoWSAMI services before optimization.
The additional memory requirements of the ContextManager and the ContextCol-lector services vary depending on the operations performed by these services. Specif-ically, joining or leaving an environment using the ContextManager service re-quires less than 750KB of memory. The realization of the Update-On-Demand and the Always-Update policies also requires less than 750KB. The realization of the Periodic-Update policy is slightly more expensive, requiring less than 850KB. The extra overhead of this policy is due to the use of the additional thread that periodically executes the UpdateOnDemand() operation (Section 3.1.4). Regard-ing the ContextCollector service, the DefineContext() and the RulesPerRelation() operations are quite cheap since they do not involve any additional invocations on middleware services or on services provided by available context sources. On the other hand, the CollectContext() operation involves contacting available con-text sources towards collecting concon-textual information provided by these sources. Hence, its memory requirements are higher. However, the overall execution of the operation requires less than 600KB of memory.
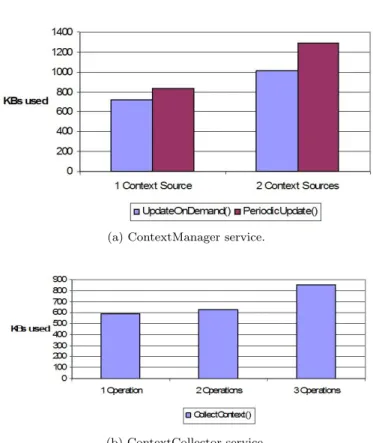
At this point, it is worth mentioning that the aforementioned values were obtained after optimizations performed in the early versions of the ContextManager and the ContextCollector services. In particular, in the first version of the ContextManager we observed that the amount of memory required for updating the contents of a
repository category increased with the number of context sources of this category that were available in the environment. Figure 9(a) gives the particular memory requirements for the UpdateOnDemand() and the PeriodicUpdate() operations in the cases where the environment contains one and two context sources. The reason behind the increasing amount of memory was that the ContextManager invokes operations on each context source to validate the source’s existence and compliance with the CoWSAMI platform (Section 3.1.4). To avoid this problem and stabilize the amount of memory required for the execution of these operations to a value that does not depend on the number of available context sources we had to explic-itly call the Java garbage collector after every Web service invocation performed on the context sources. In the case of the ContextCollector service, we observed a similar problem. In particular, the amount of memory required for collecting contextual information depends on the number of available context sources and the interface of these sources. Figure 9(b) gives, for instance, the memory requirements for compiling tuples of a context relation that consists of 6 attributes (specifically we used the TRAFFIC relation of the reference example). Each column gives the amount of memory required for compiling a tuple using a particular category of context sources. For the first category only one operation is invoked for compiling the tuple, while for the remaining two categories the number of operations invoked is 2 and 3. To keep the memory used by the ContextCollector constant and inde-pendent from the interface of the context sources we also had to explicitly invoke the Java garbage collector right after each operation invocation performed on the context sources.
The energy consumption of the CoWSAMI services further varies with respect to the operations performed by these services. The energy required for joining and leaving an environment is proportional to the overall number of reachable CoWSAMI entities since all these entities are notified about the aforementioned actions. The energy required for the repository update operations also depends on the number of reachable CoWSAMI entities. Finally, the energy required for assembling the tuples of a context relation is proportional to the number of mes-sages sent towards context sources that contribute to this relation. Therefore, the required energy strongly depends on the interfaces provided by context sources. An obvious optimization for keeping the energy spent under a certain limit is to allow each CoWSAMI entity to setup upper bounds on the number of entities contacted by the ContextManager and the ContextCollector services. However, applying this idea in the specific case of the Join() and the Leave() operations would result in compromising the realization of the Always-Update policy.
4.2
CoWSAMI performance
To assess the performance of CoWSAMI we performed a number of experiments towards measuring the execution time of basic operations provided by the Con-textManager and the ContextCollector services. During the experiments we config-ured an environment consisting of a maximum number of 8 CoWSAMI entities. 4 of these entities (2 P-IV 256MB entities and 2 P-IV 512MB) were connected though a wireless IEEE802.11g 54Mbps LAN. The other 4 entities (2 P-IV 512MB, 1 P-VI 1GB and 1 P-IV 256MB) were connected though a typical 100Mbps LAN. The entities of the wireless LAN were connected with the rest of the entities though a
(a) Joining and leaving the environment.
(b) Updating the repository.
Fig. 10. Performance results for the ContextManager service.
2.4GHz broadband router.
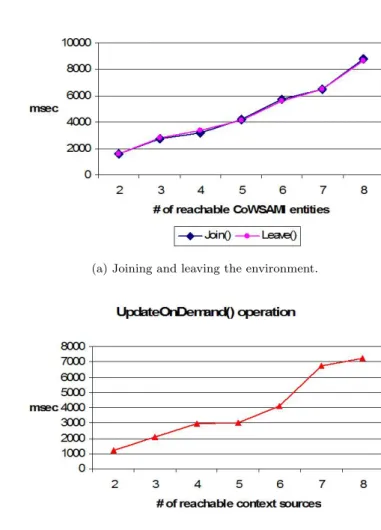
Regarding the ContextManager service, Figure 10(a) gives the time spent by a context source for joining and leaving the environment. In this particular experi-ment, we considered a number of different configurations for the environment where the number of entities that constitute it increased from 2 to 8. The overhead of the Join() and the Leave() operations linearly increases with the number of entities that constitute the environment. This increment is reasonable given that all of the aforementioned entities are notified whenever a context source joins or leaves the environment. As discussed in Sections 3.1.1 and 3.1.2, the notifications are neces-sary for the realization of the Always-Update policy that may be activated by the entities.
Both the Periodic-Update and the Always-Update policies rely on the realization of the Update-On-Demand policy (Section 3.1.4). Based on this observation we examined the impact of the increasing number of reachable context sources in the
Fig. 11. Performance results for the ContextCollector service.
realization of these three policies. The number of reachable context sources in this experiment ranged from 2 to 8. All the sources were belonging in the same category, which was given as input to UpdateOnDemand() operation. Figure 10(b) summarizes the results we obtained. We can observe that the overhead introduced by the UpdateOnDemand() operation increases with the number of context sources. This increment is partially due to use of the Naming&Discovery service in the UpdateOnDemand() operation. As discussed in Section 2.2, the Naming&Discovery service that is deployed on an entity forwards requests for service discovery to all other reachable Naming&Discovery services. The increment on the overhead is further due to the validation calls performed after the discovery of reachable context sources.
In our last experiment we measured the overhead introduced by the ContextCol-lector service for compiling a context relation, consisting of 6 attributes (as in Section 4.1 we assume the TRAFFIC relation of our reference example). Specif-ically, we examined the impact of the increasing number of context sources that contribute in the relation. For every different configuration of context sources used in this experiment, we produced 3 variations, comprising 3 different categories of context sources. In first variation a single operation is called on each source to compile a particular tuple. Similarly, in the remaining two variations 2 and 3 op-erations were called on each source. Naturally, to realize the 3 variations we used different context rules. As expected, the overhead of the CollectContext() opera-tion linearly increases according to both the number of reachable context sources and the complexity of their interfaces (Figure 11).
5.
RELATED WORK
Various infrastructure-based approaches to context-aware computing have been pro-posed in the past. In this section, we discuss the main features of the prominent ones. We further examine how they deal with the mobility and heterogeneity re-quirements imposed in pervasive computing environments (Table I).
Specifically, in [Fahy and Clarke 2004] the authors present CASS, a middleware infrastructure for context-aware applications. CASS is server-based in that context collection, management and inference are realized on a stationary workstation so as to avoid the resource limitations imposed by mobile devices. However, employ-ing such a centralized approach for dealemploy-ing with architectural mobility, prohibits the development of context-aware applications characterized by behavioral mobil-ity. Naturally, the existence of a centralized context manager can not be assumed anywhere anytime. Regarding behavioral heterogeneity in CASS, context sources should be of specific types. Context is modeled in terms of a relational data model. This aspect bares some similarity with our approach where we also model context in terms of relations. However, in our case the relations are dynamically compiled and the existence of a database for storing them is not a prerequisite. CoBrA [Chen et al. 2004] and Hydrogen [Hofer et al. 2002] are further approaches that rely on a shared context management unit. In CoBrA, context is modeled in terms of an on-tology [Chen et al. 2003]. As in CoWSAMI, CoBrA hides architecture heterogeneity by employing the Web services architectural style (specifically they use SOAP for communication). As in the case of CASS, behavioral mobility is not supported by mechanisms for dynamic context sources discovery.
MobiPADS [Chan and Chuang 2003] is an interesting approach that focuses mostly on context-aware adaptation. Similarly, CARISMA [Capra et al. 2003] focuses on context modeling, inference and conflict resolution mechanisms. In both cases context is modeled in terms of attributes. Architectural heterogeneity is provided through platform specific XML based communication mechanisms. Infor-mation regarding behavioral mobility is not provided by the authors. The Context Toolkit [Dey and Abowd 1999] is amongst the first infrastructures supporting be-havioral mobility. Specifically, it includes a centralized discovery service that allows locating the context sources that currently exist in the environment. SOCAM [Gu et al. 2005] is also an infrastructure that supports behavioral mobility. It relies on an ontological approach for modeling context. Architectural and behavioral hetero-geneity is handled by employing Java RMI for communication with context sources. Naturally, in SOCAM the use of Java further allows dealing with architectural mo-bility. Behavioral mobility in SOCAM is handled by a service that allows to dy-namically locate context sources. The discovery relies on the ontological approach employed for modeling context[Gu et al. 2003]. Moreover, the authors assume a tree-structured configuration of existing SLS (Service Location Service) servers that take in charge of the discovery process. The Gaia [Roman et al. 2002] infrastructure also provides a context sources discovery mechanism that tracks down the presence of digital and physical entities. Gaia is specifically targeted to the development of active spaces. Context in Gaia is modeled using attributes. Architectural het-erogeneity and mobility is supported through the Gaia OS that currently relies on CORBA and may support further communication mechanisms and protocols such as Java RMI and SOAP. CORTEX [Biegel and Cahill 2004; Sivaharan et al. 2004] further belongs in the category of infrastructures that provide context sources discovery facilities.
The issue of behavioral heterogeneity is not under consideration in the infrastruc-tures that we examined. Specifically, the context sources provide information
Table I. Support for mobility and heterogeneity in existing infrastructures.
through infrastructure-specific facets that provide uniform interfaces. In compari-son with the aforementioned approaches, in CoWSAMI we deal both architectural and behavioral mobility. To support the former, we rely on a lightweight infrastruc-ture for mobile Web services. To support the latter, dynamic context source dis-covery is provided. In our case, context sources disdis-covery is completely dynamic as any entity and may participate in the service location protocol. Therefore, CoWSAMI scales better and works even in pure ad-hoc configurations of pervasive computing environments, where it is not possible to assume a specific installation of servers/services dedicated for dynamic resource discovery. CoWSAMI further sup-ports behavioral heterogeneity. The context collection and management services we propose adapt their proper behavior to the behavior of context sources. The context sources may provide any kind of interface as long as it relies on the Web services standard. Reasoning about context was not amongst our primary objec-tives so far. However, there exist several interested approaches dealing with this issue in various different ways [K. Henricksen and Rakotonirainy 2002; Henrick-sen and Indulska 2004; Ranganathan and Campbell 2003; Gray and Salber 2001]. Providing an inference mechanism is amongst the future directions of our work, which shall built upon the aforementioned approaches towards context reasoning in service-oriented pervasive environments.
In general, the integration of context-awareness and service-orientation towards realizing the idea of pervasive computing just began to gain the attention of the corresponding research communities. So far, there exist approaches aiming the customization of Web services composition with respect to contextual information [Maamar et al. 2005; Zahreddine and Mahmoud 2005]. Another significant issue that falls into this line of research relates to privacy and security issues in context-aware service-oriented environments [Langendrfer et al. 2005]. Security and pri-vacy may be enforced in our approach through the concept of customizers (i.e. middleware-layer services that mediate the interaction between application-layer services) provided by the WSAMI infrastructure [Issarny et al. 2005]. Customizers are a general facility that can be used to guarantee further QoS properties. The QoS characteristics of Web services are becoming an important part of contextual information that fosters research towards QoS-aware service discovery and compo-sition [Zeng et al. 2003; Zarras et al. 2004; Liu and Issarny 2004; Papadopoulos et al. 2005].
6.
CONCLUSION
In this paper we proposed CoWSAMI, a service-oriented middleware platform that aims at supporting context-awareness in pervasive computing environments. To this end, our main contributions are:
—CoWSAMI employs the standard Web services architectural style towards dealing with the architectural heterogeneity of available context sources.
—CoWSAMI deals with the architectural mobility of available context sources by employing WSAMI, a lightweight middleware infrastructure that balances the trend between the resource limitations of mobile devices and the resource re-quirements introduced by the standard Web services architectural style.
—CoWSAMI provides a dynamic and highly scalable service discovery mechanism that handles the increased behavioral mobility of available context sources. —CoWSAMI supports the behavioral heterogeneity of available context sources
through a mechanism that gathers contextual information, while adapting its proper behavior to the interfaces of these sources.
—Finally, CoWSAMI facilitates the gathering of contextual information through an easy-to-use classical SQL-based interface.
A first prototype of CoWSAMI was implemented and evaluated regarding the re-source requirements and the performance of its main services. A comparative analy-sis between CoWSAMI and previous related middleware infrastructures showed that CoWSAMI fulfils all our initial requirements concerning heterogeneity and mobil-ity. Currently, our main focus is oriented towards two different research issues. The first one amounts in making the context sources discovery and the context gather-ing services QoS-aware. The second issue concerns the provisiongather-ing of a lightweight context reasoning mechanism that will rely on the basic CoWSAMI services.
REFERENCES
Baldauf, M.,Dustdar, S.,and Rosenberg, F. 2005. A Survey on Context Aware Systems.
Journal of Ad-Hoc and Ubiquitous Computing. to appear.
Biegel, G. and Cahill, V.2004. A Framework for Developing Mobile, Context-aware Applica-tions. InProceedings of 2nd IEEE Conference on Pervasive Computing and Communications (Percom’04).
Capra, L.,Emmerich, W.,and Mascolo, C.2003. CARISMA: Context - Aware Reflective Mid-dleware System for Mobile Applications. IEEE Transactions on Software Engineering 29,10, 929–945.
Chan, A. T. and Chuang, S.-N.2003. MobiPADS: A Reflective Middleware for Context-Aware Mobile Computing.IEEE Transactions on Software Engineering 29,10, 1072–1085.
Chen, H.,Finit, T.,and Joshi, A.2003. An Ontology for Context-Aware Pervasive Computing Systems. Knowledge Engineering Review 18.
Chen, H.,Finit, T.,Joshi, A.,Kagal, L.,Perich, F.,and Chakraborty, D.2004. Intelligent Agents Meet the Semantic Web in Smart Spaces. IEEE Internet Computing11, 2–12. Dey, A. K.2001. Understanding and Using Context.Personal and Ubiquitous Computing 5,1,
4–7.
Dey, A. K. and Abowd, G. D.1999. A Context-based Infrastructure for Smart Environments. In
Proceedings of the International Workshop on Managing Interactions in Smart Environments (MANSE ’99). 114–128.
Fahy, P. and Clarke, S. 2004. CASS - Middleware for Mobile Context-Aware Applications. InProceedings of the 2nd ACM SIGMOBILE International Conference on Mobile Systems, Applications and Services (MobiSys’04).
Gray, P. and Salber, D.2001. Modelling and Using Sensed Context Information in the Design of Interactive Applications. InIn Proceedings of the 8th IFIP Conference on Engineering for Human Computer Interaction (EHCI’01). 317–335.
Gu, T.,Pung, H.-K.,and Zhang, D.-Q. 2005. A Service-Oriented Middleware for Building Context-Aware Services. Journal of Network and Computer Applications 28, 1–18.
Gu, T.,Qian, H.-C.,Yao, J.-K.,and Pung, H.-K. 2003. An Architecture for Flexible Ser-vice Discovery in Octapus. InProceedings of the 12th International Conference on Computer Communication and Networks (ICCCN’03).
Guttman, E.,Perkins, C.,and Veizades, J.1999. Service Location Protocol, Version 2. Tech. rep., Network Working Group. http://www.ietf.org/rfc/rfc2608.txt.
Henricksen, K. and Indulska, J. 2004. Pervasive Computing and Communications. IEEE Computer Society, Chapter A Software Engineering Framework for Context-aware Pervasive Computing, 77–86.
Hofer, T., Schwinger, W., Pichler, M., Leonhartsberger, G., and Altmann, J. 2002. Context-Awareness on Mobile Devices - the Hydrogen Approach. InProceedings of 36th IEEE Hawaii International Conference on System Sciences (HICSS’02). 292–302.
Issarny, V.,Sacchetti, D.,Tartanoglou, F.,Sailhan, F.,Chibout, R.,Levy, N.,and Tala-mona, A.2005. Developing Ambient Intelligence Systems: A Solution Based on Web Services.
Journal of Automated Software Engineering 12,1, 101–137.
K. Henricksen, J. I. and Rakotonirainy, A.2002. Modelling Context Information in Pervasive Computing Systems. InProceedings 1st International Conference on Pervasive Computing. 167–180.
Karlsson, J.,Lal, A.,Leung, C.,and Pham, T.2001. IBM DB2 Everyplace: A Small Footprint Relational Database System. InProceedings of the 17th IEEE International Conference on Data Engineering (ICDE’01). 230–232.
Langendrfer, P.,Piotrowski, K.,and Maaser, M.2005. Charged Location Aware Services -A Privacy -Analysis. InProceedings of the 4th International Workshop on Wireless Information Systems (WIS’05). 33–41.
Liu, J. and Issarny, V.2004. QoS-Aware Service Location in Mobile Ad-Hoc Networks. In Pro-ceedings of the 5th IEEE International Conference on Mobile Data Management (MDM’04). 224–235.
Maamar, Z.,Mostefaoui, S.,and Mahmoud, Q.2005. Context for Personalized Web Services. InProceedings of 38th IEEE Hawaii International Conference on System Sciences (HICSS’05). 166b.
Merriam-Webster. 2005. Merriam-Webster Dictionary. http://www.m-w.com/.
ORACLE. 2004. Oracle Database Lite In Depth. Tech. rep., ORACLE. http://www.oracle.com/technology/products/lite/lite technical InDepth.pdf.
Papadopoulos, F.,Zarras, A.,Pitoura, E.,and Vassiliadis, P.2005. Timely Provisioning of Mobile Services in Critical Pervasive Environments. InProceedings of the 7th International Symposium on Distributed Objects and Applications (DOA’2005), e. a. R. Meersman, Z. Tari, Ed. Number 3760 in LNCS. 864–881.
Plitsis, Z.,Fudos, I.,Pitoura, E.,and Zarras, A.2005. On Accessing GSM-enabled Mobile Sensors. In Proceedings of the 2nd IEEE International Conference on Intelligent Sensors, Sensor Networks and Information Processing (ISSNIP’05). to appear.
Ranganathan, A. and Campbell, R. H.2003. An Infrastructure for Context-Awareness based on first order logic. Pervasive and Ubiquitous Computing Journal 7,6, 353–364.
Roman, M.,Hess, C. K.,Cerqueira, R.,Ranganathan, A.,Campbell, R. H.,and Nahrst-edt, K.2002. Gaia: A Middleware Infrastructure to Enable Active Spaces. IEEE Pervasive Computing 1,4, 74–83.
Sailhan, F. and Issarny, V.2003. Cooperative Cashing in Ad-Hoc Networks. InProceedings of the 4th IEEE International Conference on Mobile Data Management (MDM’03). 13–28.
Sivaharan, T.,Blair, G.,Friday, A.,Wu, M.,Duran-Limon, H.,Okanda, P.,and Sorensen, C.-F.2004. Cooperating Sentient Vehicles for Next Generation Automobiles. InProceedings
of ACM MobiSys International Workshop on Applications of Mobile Embedded Systems. SUN. 2004a. Java 2 Platform, Micro Edition (J2ME). Tech. rep., SUN Microsystems.
http://java.sun.com/j2me/docs/index.html.
SUN. 2004b. Java API for XML-Based RPC (JAX-RPC) 2.0. Tech. rep., SUN Microsystems. http://java.sun.com/webservices/jaxrpc/index.jsp.
W3C. 2002. Simple Object Access Protocol (SOAP) v1.2. Tech. rep., W3C. http://www.w3c.org/TR/soap12-part0.
W3C. 2004a. Web Services Architecture. Tech. rep., W3C. http://www.w3.org/TR/ws-arch/. W3C. 2004b. Web Services Choreography Description Language (WSCDL). Tech. rep., W3C.
http://www.w3.org/TR/2004/WD-ws-cdl-10-20040427/.
W3C. 2005. Web Services Description Language (WSDL) v2.0. Tech. rep., W3C. http://www.w3.org/TR/wsdl20/.
Zahreddine, W. and Mahmoud, Q.2005. A Framework for Automatic and Dynamic Composi-tion of Personalized Web Services. InProceedings of the 19th IEEE International Conference on Advanced Information Networking and Applications (AINA’05). 513–518.
Zarras, A.,Vassiliadis, P.,and Issarny, V.2004. Model-Driven Dependability Analysis of Web Services. InProceedings of the 6th International Symposium on Distributed Objects and Applications (DOA’2004), e. a. R. Meersman, Z. Tari, Ed. Number 3290 in LNCS. 1608–1626. Zeng, L.,Benatallah, B.,and Dumas, M.2003. Quality Driven Web Services Composition. In
Proceedings of the 12th ACM International Conference on the World Wide Web (WWW’03). 411–421.