School of Science and Technology
Faculty of Information and Natural Sciences
Degree Programme of Computer Science and Engineering
Antti Sepp¨al¨a
Improving software quality with
Continuous Integration
Master’s Thesis Espoo, 2nd May, 2010
Supervisor: Professor Tomi M¨annist ¨o, Aalto University Instructor: Lic. Tech. Juan Guti´errez Plaza, F-Secure Oyj
School of Science and Technology ABSTRACT OF Faculty of Information and Natural Sciences MASTER’S THESIS Degree Programme of Computer Science and Engineering
Author: Antti Sepp¨al¨a
Title of thesis:
Improving software quality with Continuous Integration
Date: 2nd May, 2010 Pages: 63
Professorship: Software Engineering Code:T-76
Supervisor: Professor Tomi M¨annist ¨o
Instructor: Lic. Tech. Juan Guti´errez Plaza
When building large software systems from several modules, integrat-ing them into a workintegrat-ing product is difficult and time consumintegrat-ing. Con-tinuous Integration aims to help with this problem by automating the integration phase and thus enabling it to be done in several small inte-grations. The goal is to integrate software so often and in such small steps, to the extent that over time, it becomes smooth and in effect, the process becomes a ”non-event”.
In this master’s thesis, the idea of Continuous Integration is presented. It uses test automation, static code analysis, automatic documentation and automatic deployment in a continuous manner in order to provide just in time information about possible problems in software code. It also improves the visibility regarding current problems by notifying Software Developers as soon as a problem is identified.
A qualitative study, primarily using interviews, has been conducted in an agile software development team to discover whether Continuous Integration helps the team to build working software. An additional goal is to identify how Continuous Integration helps and which specific features of Continuous Integration are the most useful.
Keywords: Continuous Integration, Software Quality, Test automation
Language: English
Teknillinen korkeakoulu DIPLOMITY ¨ON Informaatio- ja luonnontieteiden tiedekunta TIIVISTELM ¨A Tietotekniikan koulutusohjelma
Tekij¨a: Antti Sepp¨al¨a
Ty ¨on nimi:
Ohjelmistojen laadun parantaminen jatkuvan integroinnin menetelm¨all¨a
P¨aiv¨ays: 2. toukokuuta 2010 Sivum¨a¨ar¨a: 63
Professuuri: Ohjelmistotuotanto Koodi:T-76
Ty ¨on valvoja: Professori Tomi M¨annist ¨o
Ty ¨on ohjaaja: Tekniikan lisensiaatti Juan Guti´errez Plaza
Laajoja ohjelmistoj¨arjetelmi¨a rakennettaessa useista eri komponenteista niiden integrointi toimivaksi tuotteeksi on vaikeaa ja hidasta. Jatku-van integroinnin menetelm¨an tarkoituksena on auttaa automatisoimal-la ohjelmiston integrointivaihe siten, ett¨a se voidaan tehd¨a useis-sa pieniss¨a osisuseis-sa. Menetelm¨an tavoitteena on tehd¨a integrointi in pieniss¨a osissa ja niin usein, ett¨a ajan kuluessa se sulautuu ni-in hyvni-in ohjelmistokehitysprosessini-in, ettei erillist¨a ni-integroni-intivaihetta en¨a¨a tarvita.
T¨ass¨a diplomity ¨oss¨a esitell¨a¨an jatkuvan integroinnin menetelm¨a. Menetelm¨a k¨aytt¨a¨a testausautomaatio-, ohjelmakoodin analysointi-ja dokumentointity ¨okaluja sek¨a automaattista asennusta, jotta ohjelmakoodista saadaan ajantasalla olevaa tietoa siin¨a olevista on-gelmista. Ongelmista yritet¨a¨an tehd¨a my ¨os n¨akyv¨ampi¨a l¨ahett¨am¨all¨a ohjelmistokehitt¨ajille ilmoitus heti, kun jokin ongelma havaitaan. Haastattelemalla ohjelmistokehitt¨aji¨a, jotka k¨aytt¨av¨at ketteri¨a menetel-mi¨a, t¨ass¨a ty ¨oss¨a tehd¨a¨an kvalitatiivinen tutkimus, jonka tavoitteena on selvitt¨a¨a, auttaako jatkuvan integraation menetelm¨a toimivan ohjelmis-ton kehitt¨amisess¨a. Toisena tavoitteena on selvitt¨a¨a miten menetelm¨a auttaa ja mitk¨a sen ominaisuuksista ovat kaikkein hy ¨odyllisimpi¨a.
Avainsanat: jatkuva integrointi, ohjelmistojen laatu, testiautomaatio
Kieli: englanti
Abbreviations and Notations vi 1 Introduction 1 1.1 Motivation . . . 1 1.2 Scope . . . 2 1.3 Research Questions . . . 2 1.4 Structure . . . 2 2 Continuous Integration 3 2.1 History . . . 3
2.2 Continuous Integration as a process . . . 3
2.2.1 Benefits of Continuous Integration . . . 4
2.2.2 Continuous Integration work cycle . . . 5
2.2.3 How Continuous Integration fits with other develop-ment practices . . . 6
2.3 Continuous Integration is a mix of people and systems . . . . 7
2.3.1 Developers . . . 7
2.3.2 Version Control Repository . . . 8
2.3.3 Continuous Integration Server . . . 8
2.3.4 Build Script . . . 9
2.3.5 Feedback Mechanism . . . 9
2.3.6 Integration build machine . . . 10
2.4 Features of Continuous Integration . . . 10
2.4.1 Source Code Compilation . . . 11
2.4.2 Testing . . . 11 2.4.3 Database Integration . . . 14 2.4.4 Continuous Inspection . . . 14 2.4.5 Deployment . . . 17 2.4.6 Documentation . . . 19 2.4.7 Continuous feedback . . . 19 iii
3 Methods 21
3.1 Research method . . . 21
3.2 Data collection . . . 21
4 Case Environment 23 4.1 Software under development . . . 23
4.2 Software development process . . . 24
4.2.1 Scrum in LabDev . . . 25
4.2.2 How Continuous Integration fits in . . . 26
4.2.3 Development Team . . . 27
4.3 Security in mind . . . 27
5 Implementation 28 5.1 Choosing the tools . . . 28
5.1.1 Scaling . . . 28
5.1.2 Choosing the Continuous Integration server . . . 29
5.2 Used software and tools . . . 32
5.2.1 Continuous Integration server . . . 32
5.2.2 Software Configuration Management . . . 32
5.2.3 Build tools . . . 33
5.2.4 Static code analysis . . . 33
5.2.5 Test automation and coverage . . . 33
5.2.6 Continuous documentation . . . 35
5.2.7 Continuous deployment . . . 35
5.2.8 Continuous feedback . . . 37
5.3 Architecture . . . 38
5.3.1 Continuous Integration servers . . . 38
5.3.2 Software Configuration Management . . . 38
5.3.3 Network division and deployment . . . 39
5.4 Configuration . . . 39
5.4.1 Build jobs . . . 39
5.4.2 Reporting . . . 40
5.5 Deliverables and build artifacts . . . 41
6 Observations and findings 42 6.1 Starting point . . . 42
6.2 Taking the first steps . . . 43
6.3 Experiences of usage . . . 43
6.3.1 Ways of working . . . 43
6.3.2 Noticed benefits . . . 45
7 Discussions and Conclusions 47
7.1 Other Continuous Integration studies . . . 47 7.2 Results . . . 47 7.3 Future research and development . . . 48
Bibliography 49
API Application Programming Interface CI Continuous Integration
CNN Cyclomatic Complexity Number CPU Central Processing Unit
CVS Concurrent Versions System DBA Database Admin
ER Entity Relationship FTP File Transfer Protocol GUI Graphical User Interface HTML Hyper Text Markup Language HTTP Hyper Text Transfer Protocol
IDE Integrated Development Enviroment LDAP Lightweight Directory Access Protocol JRE Java Runtime Environment
PM Project Manager PO Product Owner QA Quality Assurance QE Quality Engineer
REST REpresentational State Transfer RSS Really Simple Syndicate
SCM Source Code Management SCP Secure Copy
SMS Short Messaging System SOA Service Oriented Architecture SOAP Simple Object Access Protocol SSH Secure Shell
SQL Structured Query Language SVN Subversion
TDD Test Driven Development URL Uniform Resource Locator WAR Web ARchive
XML eXtensible Markup Language XML-RPC XML Remote Procedure Call XP Extreme Programming
Introduction
We are living in a world where software is present almost everywhere. From the cash registers of a local grocery store to devices used in health care. It is, therefore, obvious that software quality assurance is an important part of software engineering. Unreliable software, which does not work as ex-pected may not be worth much. In the worst case, software controlling med-ical devices might cause health issues for patients upon failure.
When the software grows in size and complexity, maintaining good qual-ity becomes even more difficult. There is no easy solution to improve soft-ware quality and thus many methodologies and techniques like test au-tomation, static code analyzing, pair programming and code review have been proposed.
It is also common that requirements for software change constantly dur-ing development and that also sets another set of challenges for quality as-surance and software development process in general. To counter chang-ing requirements, agile software development started to emerge in the mid 1990s. Agile processes like Extreme Programming (XP) emphasize the im-portance of doing small changes and integrating with code base regularly. This strategy is called Continuous Integration (CI) and is the focus of this thesis.
1.1
Motivation
LabDev is a part of F-Secure labs department and is responsible for develop-ing systems used to handle file and Uniform Resource Locator (URL) sam-ples. It is a fairly new team in the company and before the work on this thesis was started, no Quality Assurance (QA) practices were enforced or processes defined. The complexity of systems had already grown to a de-gree that tracking changes and making all the bits and pieces of the large
system to work together, without proper tools and processes, became next to impossible. A solution had to be investigated and a project to implement CIto improve software quality started during the summer of 2008.
1.2
Scope
This thesis presents the experience of using CIin a case environment to im-prove software quality. We cover the basic ideas and practices behind CI, what kind of architecture is needed to takeCIinto use and which tools can be used to set it up. We also cover one example implementation and make observations of the setup process and how it was adopted. It was also stud-ied how the system was used and if it brought any benefits.
1.3
Research Questions
The main goal of this thesis is to find out if practicingCIimproves software quality. The study is made in a real business environment and therefore an additional goal is to share information about howCIwas adopted and used.
The research questions can be stated as:
• What kind of benefitsCIbrings if any?
• What features ofCIare the most beneficial? • How the system can be improved?
1.4
Structure
We begin with describingCIas a process and its features. When the needed foundation with ideas and concepts is introduced, we continue to the actual research study. Study design, methods and type of data used are docu-mented. We briefly go through what kind of environment the study was conducted in and take a closer look at the actual implementation. In the latter part of this thesis we discuss what was observed in the study and end up with conclusions along with future research ideas.
Continuous Integration
This chapter introduces the necessary background for this thesis.
2.1
History
The idea of Continuous Integration was developed by the Extreme Pro-gramming community and was described by Beck [KB99] in his book. Mar-tin Fowler was also one of the first contributors who wrote aboutCI[Fow00]. Later the work was continued by Duvall who wrote a whole book aboutCI which still remains as one of the few resources about the topic [Duv07].
2.2
Continuous Integration as a process
Continuous Integration is a process where software is built at every change. This means that when a change made by developer has been detected in source code, an automated build will be triggered on a separate build ma-chine. The build contains several predefined steps like compiling, testing, code inspection and deployment - among other things. After the build has been finished a build report will be sent to specified project members. The build report tells the result of each build step with detailed information about possible errors that may have occurred.
Fowler [Fow06] describesCIas
“Continuous Integration is a software development practice where members of a team integrate their work frequently, usu-ally each person integrates at least daily - leading to multiple in-tegrations per day. Each integration is verified by an automated build (including test) to detect integration errors as quickly as
possible. Many teams find that this approach leads to signifi-cantly reduced integration problems and allows a team to de-velop cohesive software more rapidly”.
2.2.1
Benefits of Continuous Integration
According to Duvall [Duv07], integrating software is not an issue in small, one person, projects, but when multiple persons or even teams start to work together in one project, integrating software becomes a problem, because several people are modifying pieces of code which ought to work together. To verify that different software components work together raises the need to integrate earlier and more often. The following sections describe what kind of benefits Duvall has been able to identify.
Reduce risks
By integrating many times a day, risks can be reduced. Problems will be no-ticed earlier and often only a short while after they have been introduced. This is possible because CI integrates and runs tests and inspections auto-matically after each change.
Reduce repetitive processes
CI automates code compilation, testing, database integration, inspection, deployment and feedback. Doing these steps automatically saves time, cost and effort. By automating the process, it is also made sure that all steps are done exactly the same way every time. All this frees people to do more thought-provoking, higher-value work and helps to avoid making mistakes in repetitive tasks.
Generate deployable software
One of the goals of agile software development is to deploy early and of-ten. CIhelps to achieve this by automating the steps to produce deployable software. Deployable and working software is the most obvious benefit of CIfrom an outside perspective, because customer or end user is not usually interested ifCIwas used as part of QA. It is also the most tangible asset, as software which works and is deployed, is the final output ofCI.
Enable better project visibility
The fact that CI runs often provides the ability to notice trends and make decision based on real information. Without CI, the information must be
gathered manually and this takes a lot of time and effort. A CIsystem can provide just-in-time information on the recent build status and quality met-rics such as test coverage or number coding convention violations.
Greater product confidence
By having CI in place, the project team will know that certain actions are always made against the code base. CIwill act as a safety net to spot errors early and often and that will result in greater confidence for the team to do their job. Even bigger changes can be made with confidence.
2.2.2
Continuous Integration work cycle
While CI is usually orchestrated by aCI server, it is also a way of working. The main idea is to integrate changes to source code as often as there is new code which adds value, i.e. many times a day. This makes integrating the code easier because there is less code to go through at a time. It also helps in a situation where multiple people modify the same code base, because developers will then have changes made by others earlier at hand to make sure that all changes work together. Integrating changes to code base in-volves several steps. The work cycle is illustrated in the following diagram (see Figure 2.1). It is based on the ideas presented by Fowler [Fow06] with an additional update phase after running the tests. The update phase is needed in a situation where test run takes several minutes or more so there might be already new changes committed during the run.
1. Get code from repository
2. Modify the code and create a tests for modifications 3. Check if someone else have modified the code
4. Run all tests to verify that changes have not broken anything else 5. Check again if someone else have modified the code
6. Commit changes to the repository 7. Start new cycle
The work cycle starts by getting a copy of code which is about to be changed. If code had previously already been checked out, an update is made instead. Then changes, e.g. new features or code refactoring, are applied to code and proper developer tests are written to check that new
Figure 2.1: CI work cycle based on ideas of Fowler [Fow06]
changes work as they should. A proper developer test does not only exer-cise the code once, but it also checks that expected output is received with certain input. XP recommends that tests are written before the actual code [Bec04], this is called Test Driven Development (TDD).
In a software project it is typical that many developers are working on the same parts of the code simultaneously. Therefore, to check if someone else had modified the code, an update must be made. In an unfortunate case, another developer had modified exactly the same lines of code and one or several conflicts occur. In this case, conflicts must be resolved and all tests run to check that everything still works. After the developer is confident that new changes work with the code, another update is made to check that it is safe to check-in changes back to repository. If there were new updates made in the meanwhile, previous step must be repeated until no new changes are detected and a check-in can be made.
2.2.3
How Continuous Integration fits with other
develop-ment practices
CIincorporates a set of rules which all developers should follow: • commit code frequently
• do not commit broken code
• fix broken builds immediately
• write automated developer tests
• all tests and inspections must pass
• run private builds
• avoid getting broken code
These rules are not new in software development and are actually adopted from other development practices. Therefore if practices such as developer testing, coding standards, refactoring, small releases and collective owner-ship are already in use, it is easy to start using CI. Though when using CI, these practices are enforced more or even better, they come in naturally as skipping one step may prevent someone else from working. E.g. Someone refactored code and broke some tests, but did not notice this because he did not run them. Then he committed changes to repository and left from work. Now the build broke because ”all tests must pass” rule was not followed. If another person starts working with the code, first thing he needs to do is to fix what had been broken. This may take quite a bit of time if that person is not familiar with that part of code which causes the tests to fail. Notice the difference between “do not commit broken code” and “avoid getting broken code”. To not commit broken code is easy by running private build before committing, but to avoid getting broken code, developers must fol-low build reports (see Section 2.4.7) that they do not accidentally get broken code which would not allow continuing working.
2.3
Continuous Integration is a mix of people and
systems
2.3.1
Developers
Practising CIrequires discipline from developers. Once a developer thinks he is ready with his task, he runs a build on his own development machine. This is called a private build. This step verifies that the changes made did not break integration with rest of the code base. It is important to run the private build before committing changes to version control repository be-cause submitting broken code may prevent other developers from contin-uing their work. After running the private build successfully, developer can commit the changes including tests. Should the integration build fail despite the precautions, fixing the build is priority number one.
2.3.2
Version Control Repository
Continuous integration cannot be done without version control repository. Version control repository, also known as Source Code Management (SCM), is a system which is used to store source code and other aspects of software like documentation in a centralized manner. It also keeps track of version history and changes done during the development. Software developers have the possibility to go back to any version orrevisionof a software or just to check what changes were done on any given revision.
This repository provides a single point of access to the codebase for both developers andCI system. It may consist of differentbranchesof the stored software. A branch could be created for major rewrite or for prototyping an interesting idea which might not end up in final product.
Integration build is run against themainlineof the version control repos-itory [Duv07]. Mainline is the branch of source code where most of the development takes place. Some version control systems calls this also as trunk or head. The mainline should always be stable and integration build should not fail when run against it.
2.3.3
Continuous Integration Server
TheCIserver is the orchestrator of the whole process. It runs the integration build when a change has been made. The server is usually configured to check for changes every few minutes or so [Duv07]. Another way is to use a post commit hook which is configured in SCM. By using a post commit hook, SCM can tell CI server immediately when a change has been made. This way a build is surely run for each commit. With polling approach there might be several changes between each poll. A third option is run a build at regular intervals, but if the interval is long the benefit of fast feedback is lost.
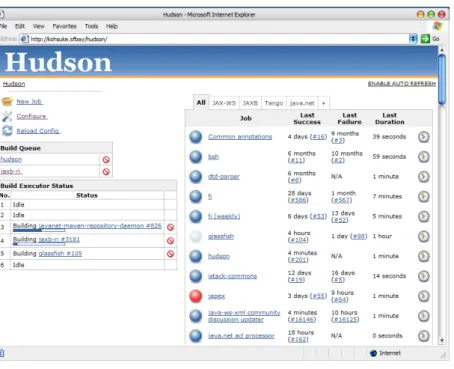
CI Server also provides a view, usually a web page, which shows the health of all configured build jobs (see Figure 2.2). This dashboard view can be shown for instance on a large screen in development team’s room to give a quick overview on what is happening on the server. On that view, it can be seen if there are any builds running. Many CI servers also provide a traffic light type of visualization whether builds are broken or not.
A full featured CIserver is not necessarily needed to do continuous in-tegration. A bunch of custom scripts can do the same, but having a server designed for the purpose helps a lot [Duv07] and there are many free and commercial ones available [Tho09].
In its simplest form, CI could be achieved with a single dedicated com-puter which has scripts to check out source code fromSCM, run a build and
Figure 2.2: Hudson CI Server dashboard
send feedback after build is finished. CIservers in the other hand provide user interface to configure multiple build jobs and to view results.
2.3.4
Build Script
Typically many of the steps in a build are defined using a build script. A build script may consist of one or multiple scripts and it is used, for exam-ple, to compile, test, inspect and deploy software. All the steps which can be automated to build and deploy working software should be automated. This saves time and nerves of developers. There are many techniques avail-able like Ant, Make or Scons. Some developers are used to use their In-tegrated Development Enviroment (IDE) to build software, however using only IDE based builds will not fit in with CI because the build needs to be able to run without theIDE as well [Duv07].
2.3.5
Feedback Mechanism
When integration build is finished, the results should be accessible as soon as possible. Ability to provide fast feedback is one of the benefits ofCI. The feedback is immediately available after the build is finished. The feedback can be provided in different ways, for instance via email. In case of broken
build, fixing can be started immediately after receiving the notice.
Other mechanisms like Short Messaging System (SMS) or Really Simple Syndicate (RSS) feeds can be used as well. Creative people also use extreme feedback devices like lava lamps or ambient orb [Sav04] (see Figure 2.3).
Figure 2.3: CI extreme feedback mechanism: Ambient orb
2.3.6
Integration build machine
CIserver needs a host to run on. Integration build machine is a separate ma-chine which should mimic the production environment. If possible, exactly the same operating system, database server version and library versions should be used as is planned to be used in production. Every difference increases the risk of tests not catching something what might happen in production [Fow06].
In case there are many build jobs configured for software, which is ac-tively worked on, there might be a need for more than one build server in order to keep building times down and to get fast feedback. SomeCIserver software provide master-slave architecture to divide the load upon multi-ple hosts [Tho09]. Sometimes multimulti-ple environments are needed to build on different platforms. Then virtualization is something worth using as the penalty of virtualization decreases [Bar03]. Some CI server software like Hudson enables same build job to run simultaneously on several virtual hosts and to collect results for each environment.
2.4
Features of Continuous Integration
According to Duvall [Duv07] only four features are required forCI. • A connection to a version control repository
• Some sort of feedback mechanism (such as e-mail)
• A process for integrating the source code changes (manual orCIserver) These features alone are needed to build an effective CI system, which are explained in more detail in following sections.
2.4.1
Source Code Compilation
Compiling source code is one of the basic and most common features of CI system. Compilation creates executable binaries from human-readable source. When using dynamic languages like Python or Ruby compilation is different. Binaries are not compiled, but instead there is capability to perform strict checking, which can be thought as compilation in context of these languages [Duv07].
2.4.2
Testing
Testing is the most vital part of CI. Many consider CI without automated, continuous testing not to beCI[Duv07]. It is difficult to have confidence in software changes without good test coverage. Tests can be automated using unit testing tools such as JUnit, NUnit, or other xUnit frameworks.
testchoice (__main__.TestSequenceFunctions) ... ok testsample (__main__.TestSequenceFunctions) ... ok testshuffle (__main__.TestSequenceFunctions) ... ok ---Ran 3 tests in 0.110s OK
Figure 2.4: xUnit output
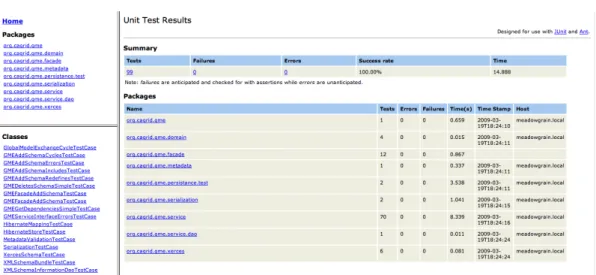
Some of these frameworks can also generate machine readable reports, which can be parsed and used to generate graphical representations such as web pages or charts (see Figure 2.5). Charts and other graphical test reports are easier to read and gives better visibility.
Testing levels
Testing can be done on different levels (see Figure 2.6). The lowest level of testing is called unit testing. A unit is the smallest testable part of an
Figure 2.5: Unit Test Result Report
application. This could be a single function or a method in a class. The goal of unit testing is to verify that individual parts of code work as they should. Unit tests are usually written by the developer who wrote also the code.
Next level is integration testing. In this context integration means to test individual software modules as a group. This group could be called a com-ponent. E.g. a typical software component is database layer. It provides Application Programming Interface (API) for underlying database. Compo-nent level tests exercise code through thisAPI.
System tests exercise a complete software and requires a fully installed environment to run. These tests verify that externalAPIworks and does not take advantage of knowing how the system works internally. This method is called black box testing.
4th level in testing is functional testing. Functional tests try to use the software like a real client would do. Frameworks like Selenium could be used to test web applications. It takes control over the whole browser and clicks through the application like real users would. Functional testing can be used to do acceptance testing and to verify that software meets accep-tance criteria.
Run faster tests first
When software grows in size and number of tests gets higher, the amount of time spent in running the tests also increases. If all of the tests are run in a single go it may take such a long time that the benefit of fast feedback is lost. To tackle this syndrome, tests should be categorized and faster ones run first. Then tests can be divided in multiple steps and feedback can be
Figure 2.6: Testing levels
received after each step finishes.
Unit tests require least time in setup and are the fastest tests to run. A unit test should take only a fraction of a second to run, if it takes longer, it is either broken or is actually an integration test. These tests are run by the developer many times a day, and if they take too much time, they be-come something to avoid instead of depend on [Duv07]. Unit tests are good candidates to run in the first step.
Integration and system tests require a lot more time setup than unit tests. Setting up database with some test data and starting the actual software might be time consuming tasks. To run the tests also take longer than unit tests. These time consuming tests can be run in subsequent steps or on periodic intervals.
E.g. a full test suite might take several hours to run. These could be then run every night. A test suite which is run every day is called Daily Build [McC96].
Write tests for defects
Writing tests and running them automatically withCIdecrease the frequency of software defects, but there is no such thing as perfect software and defects still occur [Duv07]. When a defect is found, it can be fixed and a lesson can be learned, but to prevent making the same mistake twice, a test could be written for the defect. The underlying idea is to become better and better all the time, i.e. to improve continuously.
2.4.3
Database Integration
CI is not limited only to building source code but can also be used in de-veloping database driven applications. When using a database, it is an in-tegral part of software application and therefore needs to be involved in integration process. To create a working database inCIbuild, a set of scripts are needed in version control repository which can be used for building a working database. This includes table definitions, stored procedures, parti-tioning and so on. For testing purposes, some data is usually also needed, which is inserted to database after its creation.
For instance, when a developer or Database Admin (DBA) makes a change to database script and commits it to the version control system, the same in-tegration build which is used to integrate source code builds also a fresh database using the latest modifications. Then tests can be run against latest database schema and project members can see if the tests still pass.
Unit testing database functions
For security and performance reasons or to utilize a cluster of database nodes, code accessing database can also be stored in database itself. For example PostgreSQL supports writing database functions in multiple dif-ferent languages such as perl or python. To test these functions a frame-work like pgTAP [pgTAP] can be used. Tests written with pgTAP can also be automated and made part of theCIbuild.
2.4.4
Continuous Inspection
Software code can be reviewed manually and automatically. Manual code reviews made by a peer are beneficial in overall code quality because they present opportunities for an objective analysis by a second pair of eyes [Duv07]. XP way to review code is pair programming, which offers some of the same objective analysis benefits. For automatic code review, static code analyzers can be used. These tools scan files for violations of prede-fined rules and offer some of the same analysis benefits.
Code reviews performed by humans are time consuming and many times there is a danger that people collaborating in a working environment tend to subjectively review one another’s code. This means it is sometimes hard to tell a colleague that their code is not following all rules. People can also be biased if they have written some part of the code themselves or are part of the project in some other way.
The difference between human-based inspection and that done with a static analysis tool is twofold. Running tools often is really cheap and they
only need to be configured once - after that, they are automated and pro-vide savings as compared to person’s hourly rate. In addition a computer is always objective and does not get tired to check code every time a change is committed to version control repository.
Automated static code analysis scales efficiently for large code bases. It allows developers to focus on the parts which really matter and will take care of the big picture. If a particular important rule is violated such as highcyclomatic complexity(see Inspection reports below) value, someone can take a look. The key to remember is that automated code review is not a replacement for for manual ones - they are merely an enhancement for applying human intelligence where it is mostly needed [Duv07].
Many IDEs have built-in inspection features to assist developers with automated code formatting, unused variables and illegal use of language to name a few. While it is highly encouraged to use these features inIDE, same kind of inspections should also be run with an automated build and CI to prevent false positives and to ensure that these tools are always used.
There are also tools, which look for duplicate code blocks. These tools can be used to detect copy-paste coding. One example of such tool is Simian [Simian].
Differences between inspection and testing
Testing is dynamic and executes the software in order to test the function-ality. Inspection analyzes the code on a set of predefined rules. Both are similar concepts in a sense that both do not change the software code; they only show where problems may reside [Duv07].
Inspection reports
Static code analysis tools provide a number of metrics and reports. Already decades ago, people started studying code to see if there were measure-ments one could take that correlate to defects [McC76]. One metric that arose is called the Cyclomatic Complexity Number (CNN). It is a plain in-teger that measures complexity by counting the number of distinct paths through a method [Kan03]. Studies suggest that a good limit for this num-ber is 10, greater numnum-ber means higher risk of defects [Wat96]. JavaNCSS [JavaNCSS] is an excellent tool for Java which countsCNN, CCMetrics [CCMetrics] and Source Monitor [SourceMonitor] are similar tools for .NET. The most effective way to reduce cyclomatic complexity is to apply theextract method techniqueand distribute the complexity into smaller, more manageable, and therefore more testable, methods [Duv07].
automatically. These are afferent coupling and efferent coupling. These simple integer metrics count the relationships to or from objects. There is a problem if an object has a responsibility to too many other objects (af-ferent) or the object is not sufficiently independent of other objects (effer-ent) [Duv07]. These dependency metrics are also helpful in determining the risk in maintaining a code base. If objects, which have high coupling, need a change, a risk of breaking something else is high. Other objects in the software may stop functioning as intended. Duvall introduces the usage of these two values combined to calculate an instability value. For example the following equation can represent the level of instability of an object in the face of change. A value of one is unstable, while a value of zero is stable.
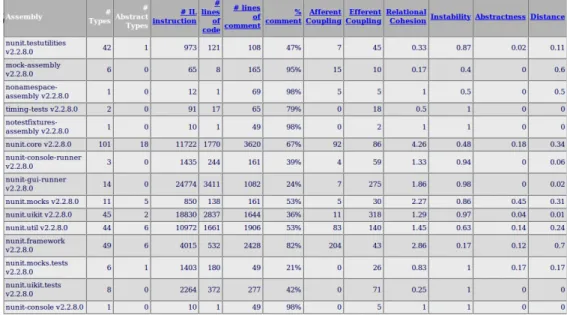
Instability=E f f erentcoupling/(E f f erentcoupling+A f f erentcoupling) NDepend for the .NET platform is a tool which calculates these metrics (see Figure 2.7).
Figure 2.7: NDepend Report
Note how the nunit.framework assembly has an affarent coupling of 204 and efferent coupling of 43. This is the core code of NUnit framework, which mean this code cannot change easily. The instability value for this assembly is 0.17 so there is a big probability that if this code changes it will break something else.
great value for the invested time. Problems in maintainability can be spotted early on and risk for having defects can be reduced.
2.4.5
Deployment
One of the goals ofCIis to have working software ready for deployment at any point of time. Actually all the steps previously discussed are parts of the deployment process which aims to generate the bundled software artifacts with the latest code changes available to a testing environment [Duv07]. It is even possible to install software automatically with CI. For this, Duvall lists following six high-level steps.
• Label the assets of a repository
• Produce a clean environment, free of assumptions
• Generate and label a build directly from the repository and install it on the target machine
• Successfully run tests at all levels in a clone of the production environ-ment
• Create build feedback reports
• If necessary, the release can be rolled back by using labels in version control system
Label the assets of a repository
By using tagging feature of version control repositories, a group of files can be labeled. This delineates certain group of files as belonging together. La-bels also enable historical tracking of a group of files. For instance a release of a product could be labeled as ’release-4’.
Produce a clean environment
To reduce the risk of seeing the software behaving differently in production and in testing environments it is important to make no assumptions on the environment where the software runs. Ideally all steps can be automated to produce a working environment for software to run on. For example virtualization can be used to deploy a clean server and apply the following layers to it.
• Operating system configurations (e.g., users, firewall)
• Server components (e.g., web server, database server)
• Server configuration
• Third-party tools (e.g., web frameworks, libraries)
• Any custom software
It is possible to do only some of these steps like reinstalling the custom software, and the decision will depend on the desired level of risk [Duv07].
Label each build
To create a unique identifier for a build requires that code in repository has been labeled (as just discussed). Second, the actual build needs a label. A common naming scheme for builds is to use a running number. By labeling each build provides an easy way to track which version of code is in a par-ticular environment. Moreover defects, features and new requirements can be issued against that instance of a code base.
Note the difference between a repository label and build label. Repos-itory label groups a set of, usually uncompiled, files together. Build labels in the other hand label binary output of a build being unique. The naming schemes are however usually related. For instance, if the repository label is 4-32, a build of that snapshot of code could be 4-32.01.
Run all tests
Before packaging a deployment build all tests must run and pass. All test levels from unit tests to functional tests should be run. In the best scenario, these tests should be run in as similar environment as possible to production environment.
Create build feedback reports
Build reports include information of what was done in a build (tests, static analysis, etc), which files changed, which issues has been addressed and which features implemented. A test report tells how many tests were run, how many of them passed or failed, what was the test coverage. A diff file tells exact changes in source code. Static analysis reports tell possible viola-tions in coding practices. Changelog collects notes written by developers to get an idea what issue was resolved or which feature was implemented.
Capability to roll back release
Some times the inevitable happens and broken software is deployed. Then having the capability to undo is priceless. When using proper labeling for builds, requesting an older version of software is simple. Moreover, if ev-erything is automated, the time needed is minimal.
2.4.6
Documentation
Agile development methods such as eXtreme Programming emphasize “Working software over comprehensive documentation” [HF01]. The doc-umentation is built into the source code by using clear naming conventions and writing documentation to methods themselves. When the documen-tation is built in to source code a CI system can use tools such as Javadoc [Javadoc], NDoc [NDoc] or Pydoc [Pydoc] to create an up to date documen-tation for each build. Tools can be also used to create class diagrams or to solve all library dependencies. All these automatically generated docu-ments are based on the code in version control repository and significant benefits may be found in obtaining near-real-time documentation of source code, and project status using aCIsystem [Duv07].
2.4.7
Continuous feedback
Feedback is an important feature of CI system, and if it is continuous, it constantly gives information about the health of builds. It is much more useful to get a notification of a failed build immediately when it happened than until several hours later in the day. If immediate action cannot be taken due to lack of information, more problems could propagate and cause other failures.
Although feedback is really valuable, not every person need all the in-formation all the time. Feedback should be sent to only interested parties. The purpose of feedback is to create a notification that most quickly and pre-cisely stimulates action [Duv07]. Feedback itself does not take the action to improve software, project members do - typically, software developers. The information may be valuable also to others such as testers or management.
Sending feedback too often and in cases where action is not required will make project members to ignore the messages. To always send a “success” message after each successfull build will only create unnecessary spam and hide the important “failure” messages. Also if developers learn to ignore all the messages they receive, failures might be left unnoticed.
It is also important that the right people will receive feedback. A Project Manager (PM) needs to make decisions that center on resources allocation
(people, hardware and supplies), time and costs. PMs need high-level feed-back with information about software completion as it relates to time, cost, quality and scope. Software architect or lead developer want see the status of all builds because they are responsible of the entire system. They might find reports from static code analyzers interesting in order to track coding standards. Developers are interested in reports which concern the code they have just checked in. This might include failure notification of a certain unit test, or static analysis of their code. Testers will probably be interested in full report of all automated tests and inspections including code coverage report. In a nutshell the team will get most benefit when the right informa-tion is sent to the right people and at the right time.
Feedback mechanisms
The most common feedback mechanism is e-mail. It is easy to setup since having an email server already available can almost be taken for granted. Moreover everyone has an email address and an email client set up. One advantage of e-mail is that it can send information asynchronously to the right people. On a negative side, too much email is considered as spam and might end up being ignored. SMSis a bit more harder to set up than e-mail. It requires a special server capable of sending SMSs. As an advantage SMS almost guarantees recipient’s attention, anywhere and even any time. On the other handSMS messages can not be very long.
Ambient orb is a device which glows in different colours. It could be set in the team room on a visible spot. To set up an orb requires a script capable of sending Hyper Text Transfer Protocol (HTTP) requests through a network connection. Once it is set up, it gives visual feedback of build at one glance. And it definitely has a “cool factor”.
Using sounds can also add a little bit of fun to the workplace. To use sounds a sound card with speakers are required. Sounds can reach many people at the same time, but might start to get annoying after a while. Also the sound is typically played only once, so it might get missed if people are not present or have their headphones on.
Another feedback device to consider is a big wide-screen TV. It can show real time information about CI system. Many CI servers provide a dash-board view which will fit on one screen. With this kind of dashdash-board, all builds can be monitored in one glance. Although, it is still needed to check the screen every now and then and as with sound, people need to be present.
Methods
This chapter describes the research methods used as well as how the re-search was actually done.
3.1
Research method
In this thesis, the researcher was a member of the team which adopted CI. The researcher also had a genuine interest in the case as the team was look-ing for a worklook-ing solution to improve their operations. Because of this, intrinsic case study [Sta95] was chosen as the research method. Stake uses the term intrinsic and suggests that researchers who have a genuine interest in the case should use this approach when the intent is to better understand the case. This research was not undertaken primarily because the case rep-resents other cases or because it illustrates a particular trait or problem, but because in all its particularity and ordinariness, the case itself is of interest.
The researcher worked as a Quality Engineer (QE) in the team during the study and one of his roles was to be the main developer of theCIin the team. Therefore it is possible that the researcher is biased and this should be considered when interpreting the results of this thesis.
3.2
Data collection
This study was made in a qualitative manner and as in any other qualitative study the data collection and analysis occurred concurrently [Bax08]. Espe-cially in this case, where the researcher had a big role in the implementation ofCI, observations were done on a daily basis.
Observations started from the time whenCIsystem was set up and ready to be used. However, not all of the features ofCIwere in use from the
ning and theCIsystem developed during the study. Therefore development of theCIsystem and observations were done simultaneously.
After theCIsystem had stabilized, semi structured interviews were made with the team members. The objective was to lead interviewees’ answers as little as possible, by using questions which did not give hints about expected answers. Questions used to guide the interview are listen in Appendix A. Depending on the answers, specifying questions were asked to get reason-ing to the answers. The goal of the interviews was not only to get answers to the current research questions, but also to find out areas which need im-provement for future study (see Section 1.3).
By the time the interviews were conducted, the team consisted of 4 de-velopers and 1 QE. As researcher being the only QE, only developers were interviewed. All interviews were both noted down and tape-recorded.
All interviewed developers have had experience in working without CI in previous work places or in the current team, and all had at least a year of experience working withCIin the current team.
Case Environment
This chapter introduces the project where CI was taken into use as the work started on this thesis. Also the software development process, resources, etc., which play a big role, are explained.
4.1
Software under development
As mentioned in introduction, LabDev is developing systems which are used to handle malware samples and URL classifications. These systems consist of several smaller services, which each provide specific functionality, e.g. malware scanning or importing incoming sample. This kind of archi-tecture is called Service Oriented Archiarchi-tecture (SOA) [HS05] (see Figure 4.1). The basic idea behind SOAis to create autonomous services, which can be used to provide needed business feature by cooperation of these individual services.
Figure 4.1: Service Oriented Architecture [Haa03]
On top of these services, a set of tools have been developed for malware 23
and network analysts, who work around the clock and fight the “bad guys”. It is absolutely critical that LabDev systems are stable and fully functional 24 hours a day, because next virus outbreak might happen any time and anywhere. These systems are also used by researchers, who are actively looking for new ways to detect malware.
Currently LabDev systems consist of almost 20 separate services and all these need to work together with well defined interfaces. When using CI, these interfaces are tested frequently, given that tests exist. We also get up to date documentation, which describes what kind of input the service expects and what is the output (see Section 5.2.6).
4.2
Software development process
F-Secure is one of the companies which has made a huge turnaround from traditional waterfall [Roy87] like development model towards agile. One example of an agile development method is scrum, which is used at F-Secure.
Figure 4.2: Scrum process [gs02]
Figure 4.2 illustrates the scrum process. Product backlog can be seen as a long term work list. It has all future work prioritized by the customer. Items from backlog are then assigned to sprints which usually last from two to four weeks. Each backlog item is split into several smaller tasks to make it easier to divide work and to follow the progress. Each day team has a short meeting called scrum, in which each person goes through shortly what he has done, did he have any obstacles and what will he do next.
4.2.1
Scrum in LabDev
In LabDev we do not do only traditional product development, but we also provide a service for our in-house users. We follow the principles of scrum for active development which aims to improve the service we provide. We work on projects, which each have high level goal which we try to acchieve. We call these high level goalsepics. Each epic then consists of several stories, which in our case are backlog items.
Before a project starts, we estimate the stories in project backlog. We also have a rough idea of how much capacity we have and how much work we can do during one sprint. When we know how much time each story takes to implement, and how many stories we can do in each sprint, we assing stories to sprints according to priorities set by Product Owner (PO). POrepresents our “customer”. We do not have a real customer because we do in-house software.
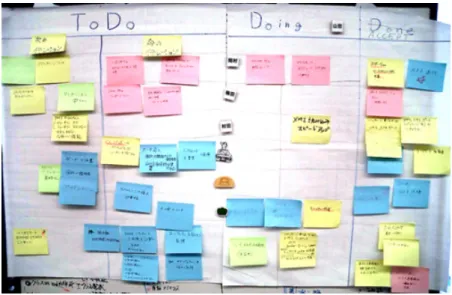
At the beginning of each sprint we split the stories for current sprint to tasks. We create a post-it note for each task, which we then put on a white board in our team room (see Figure 4.3).
Figure 4.3: Example whiteboard
In daily scrum we follow the progress of tasks by moving post-it notes betweentodo,doinganddonestates. We also update how much work is left in each task and update sprint burndown chart. The burndown chart is a visual way of tracking if all planned work is going to get done in current sprint, or is something going to be postponed to later sprints. In figure 4.4 straight line is optimal and curved line is actual progress.
Figure 4.4: Burndown chart
After each sprint, we represent the results of the sprint in a demo session. Within the team we also have retrospection meeting to discuss what went well, what not so well and what can we do about it.
4.2.2
How Continuous Integration fits in
Continuous integration is one agile software development practice. Scrum as such does not dictate which practices should be used, it only defines how the process is managed and its iterative model. Nevertheless Scrum works with agile software practices and they are encouraged to be used. In fact it is very common to use a hybrid of Scrum andXP, where practices are adopted fromXPand management from Scrum.
CI is one of the practices of XP and it supports daily development by providing test automation, build reports and automatic deployment. It also supports agile approach by encouraging to do small improvements instead of huge changes.
WithCIit is also possible to manage software releases by definining sep-arate build configurations for releases. All changes which have been applied between releases can be logged and reported in build report.
4.2.3
Development Team
LabDev consists of 3 teams: administration, development and maintenance. This thesis focuses onCIfrom the development teams’ perspective. During the work on this thesis the team consisted of 4 software engineers and one QE.
In this teamQEs have the main responsibility of creating and developing CI with the help from administrators to set up servers and environments. This includes creating build scripts, setting upCIbuilds, improving deploy-ment automation, etc. Maintenance work of servers and environdeploy-ment is done by the administrators. From testing perspective, software engineers write tests for the first two layers and QE for last two layers (see Section 2.4.2).
4.3
Security in mind
F-secure is an IT security company, which needs to take good care of its reputation. The most valuable asset is trust. If customers loose trust in their security provider the company cannot survive. That is why security must be built in in all operations includingCI. All components of CImust be secured in a way that no one else than persons who need access can have access to those. Communication between SCM and CI server must be secured with encryption and no clear text passwords sent within network. User authentication toCIserver must also be secured.
LabDev systems handle malware which is unsafe to have in the same network as developer workstations. Therefore development is made in dif-ferent network than where the actual systems are running. All connections between these two networks are limited. When implementing deployment part ofCI, this network boundary must be addressed. It is needed to have a way to safely deploy software to production and testing environments without risking the operations in other networks.
Implementation
This chapter discusses the issues which were considered when the tools were chosen for the work of this thesis. The selected tools are introduced and how they are used. Also the architecture for LabDev’s CIis described. Finally an example build configuration is made and its output and build artifacts are explained.
5.1
Choosing the tools
CIcan be implemented with countless of different tools. It is important to understand what features ofCIare needed when choosing the tools. BasicCI can be implemented with really simple set of homegrown tools, but usually in corporate environment it is best to use tools which are widely adopted and supported.
5.1.1
Scaling
As discussed in section 2.4,CIcan be implemented using only version con-trol, build script, email and a periodic call to script which then runs the integration build. This may be sufficient for a simple project with only few components, but when the amount of buildable component rises, it soon be-comes a maintenance nightmare. To solve the scaling problem, a properCI server may be of help. Using CI server, configuring builds is a trivial task. CIservers provide a Graphical User Interface (GUI) to help configuration of builds.
When the number of builds, amount of code to compile, tests to run, etc. grows, the computation power needed also grows. To get more processing power the amount of CPU cores in one server can be extended to certain limit, but real solution is to have multiple servers with several cores
Figure 5.1: Bamboo repository configuration
cated forCI. Several servers are also needed when builds need to run in sev-eral environments, e.g. when components need to be built on sevsev-eral plat-forms like windows, mac or linux. Some CIservers like Bamboo [Bamboo] (see Figure 5.1) and Hudson [Hudson] have support for slave machines or cloud computing.
5.1.2
Choosing the Continuous Integration server
Programming language support
There are several CIservers to choose from. Some of them are designed for building with specific programming languages, e.g. CI Factory [CI Factory] for .Net, Java, C++ and VB6, while others like CruiseControl [CruiseControl] or BuildBot [Buildbot] can build with any language [Tho09]. If there is no clear picture what programming languages will be used in the future, it is good to select a CI server which can build with any language. In the other hand, if language requirements are well known, it is safe to choose one which is designed for those languages, because there is no need to sup-port other languages.
SCM support
SCM is one of the mandatory things CI needs. CI servers support a wide range ofSCMs, but some servers miss the support for someSCMs. When us-ing Concurrent Versions System (CVS) or Subversion as SCM, almost anyCI server can be chosen. But when there is a need for Mercurial or Git support, CIserver must be chosen from shorter list of applicants.
Another thing to consider is the integration possibilities with different source code browser tools. There are several tools for Subversion, e.g. Sven-ton [SvenSven-ton] or Fisheye [Fisheye], which integrate nicely with Hudson or Bamboo.
Build management
One important field of CI servers is how builds are managed. CI servers provide several ways to trigger builds, possibility to run several builds in paraller, set interproject dependencies among other things. It is a good idea to try out severalCIservers to find out which ones meet the needs.
Security
When setting up CI there is often a need for user authentication. CIserver has access to SCM where all source code is stored, and if SCM is secured it makes also sense to secureCI. Almost allCIservers have support for basic user authentication[Tho09], but in corporate environment the possibility to integrateCIserver with already existing authentication mechanism like Ker-beros [KerKer-beros] or Lightweight Directory Access Protocol (LDAP) [LDAP] is definately something which helps when setting accounts for several peo-ple.
Other features
CIservers have a wide range of features which have not yet been discussed, but should be considered when making the decision which one to use. One of these is publishing. Publishing means how build reports and other ar-tifacts can be made visible. Most basic way to publish is via email. Some servers also support Secure Copy (SCP), File Transfer Protocol (FTP), Jabber [Jabber],RSS, etc.
The most visible feature ofCIservers is its user interface. The trend is to have a web interface and allCIservers have one. What makes the difference is what can be done through it. It is again a good idea to try out several ones to find out the one which pleases the most.
Like when checking the programming language support, also build tool support should be considered. In Java world, Maven and Ant are widely used. ManyCIservers have direct support for these tools. Also Make, Rake (Ruby) and MSBuild are widely supported[Tho09].
If there is an issue tracking system in use, it can also be integrated withCI server. E.g. Bugzilla [Bugzilla] and JIRA [Jira] are supported by some. Test tools in the other hand are supported in broader front. Almost all servers support result rendering of JUnit or others in the xUnit family. This is a feature which improves the visibility of test results and is therefore good thing to check when choosing the server.
Some CI servers can also be integrated with IDEs. Two popular IDEs, Eclipse[Eclipse] and its commercial alternative IntelliJIDEA [IDEA] have plugins to integrate with some CI servers. Also Visual Studio has a plu-gin to integrate with someCIservers. With such a plugin build statuses can be seen directly fromIDEwithout launching a browser to check the statutes fromCIserverGUI. This way feedback is almost immediately available even when developer is concentrated in programming and does not check emails or any feedback devices such as wide-screen TV.
Some times there is also a need to integrateCIwith systems which do not have official support or plugin to make the integration. For these occations remote API can be used. CIservers may exposeAPIfor remote management by using for example REpresentational State Transfer (REST), Simple Object Access Protocol (SOAP) or XML Remote Procedure Call (XML-RPC).
Extendability
In case there is not anyCI server available which meet all the needs by de-fault, a server which can be extended with plugins is a good pick. With a plugin support virtually any tool can be integrated, though time and re-sources are needed to create the plugin.
Installation and configuration
CIservers can be installed in many ways. For windows environment almost all provide installer, which will then do all necessary steps to have a work-ing installation. For other environmentsCIserver providers have some sort of self contained distribution, e.g. Debian package or Web ARchive (WAR) package for running with Tomcat [Tomcat]. Before installation additional dependencies should be checked. E.g. if server is implemented with Java, Java Runtime Environment (JRE) is required. These dependencies are usu-ally mentioned in installation guide.
provide a GUIfor making the configurations. E.g. locations of SCMclients and buildtools or access control need to be set beforeCIserver can be used. In many cases configuration can also be made by editing a text file, which may be e.g. in eXtensible Markup Language (XML) format.
Other issues to consider
Cost is always an interest of management. There is both free and commer-cial server software available. Thanks to open source projects such as Hud-son or CruiseControl, getting CIis not a resource problem. When choosing an open source tool, there might not be commercial support it, but in the other hand it is free to use.
When choosing a CIserver which is widely used, there is an active com-munity which may be of help. Solutions for most common installation and configuration problems are available in message boards or in other forums like mailing lists. Questions can also be asked from other users for specific issues. Good online community may be a substitution for commercial sup-port.
5.2
Used software and tools
In this section we explain which tools were used to implementCI.
5.2.1
Continuous Integration server
LabDev is using mainly Python as a programming language so CI server must have a support for it. Also some systems are made with Java so it has to be supported as well. As python being the main language, the ability to easily use tools made for python played a big role when the server was chosen. Because of these reasons a good candidate was Hudson. Hudson was the first server which was tried out and it was immediately seen that it was a good fit. It has an extendable plugin architecture and scalability with slave machines. It is open source and free to use. It is also developed actively and new builds were released several times during the research period of this thesis.
5.2.2
Software Configuration Management
LabDev was already using Subversion (SVN) asSCMand there was no need to change it because Hudson natively support for it. The communication betveen Subversion repositories and Hudson is made through Secure Shell
(SSH) communication. As an authentication mechanism we used public and private keys.
Tracking changes
For tracking changes Hudson provides changes view, which lists latest com-mits with attached comments. Changes view by itself provides quick overview on what changes have been made to the code, but to see the actual changes we integrated SVN browser calledSventon. It is a web application which can be used to browse code in SVN repositories and view differences between revisions. When integrated with Hudson, changes view contains also direct links to diff views in Sventon.
5.2.3
Build tools
As a build tool we used Make. In Makefile we had separate targets for each step in our CI process run in Hudson. By having a Makefile it is ensured that each developer can run same steps locally asCIbuild in Hudson does.
5.2.4
Static code analysis
Python is dynamic language, which does not require compiling. Therefore syntax errors are discovered only when code is run. To help in this problem static code analysis can be used. For python there is a powerfull tool called Pylint, which checks for syntax and coding conventions. In Labdev we use it on both local development machines and as one step inCI. Hudson parses Pylint reports and build status can be defined based on the number of cod-ing violations. Hudson violations plugin also creates reports which can be used visually see on which lines of codes the violation occurred.
5.2.5
Test automation and coverage
As a test framework for python we used python unittest. It belongs to xU-nit family and produces standard xUxU-nit report files which Hudson can parse and generate test result reports. To automatically run unit tests we used a tool called Nose [Nose]. It automatically discovers unit tests from source code and runs them. To divide tests to different suites, command line op-tions can be used to specify which tests to run.
Nose has also plugins. We used coverage plugin to generate test cov-erage reports. Covcov-erage report tells which parts of the code is excercised by the tests and which are not. It helps to find out flaws in tests. It also calculates coverage ratio, which can used as a quality metric. E.g. If target
-- Start a transaction. BEGIN; SELECT plan( 2 ); \set domain_id 1 \set src_id 1 -- Insert stuff. SELECT ok(
insert_stuff( ’www.foo.com’, ’{1,2,3}’, :domain_id, :src_id ), ’insert_stuff() should return true’
);
-- Check for domain stuff records. SELECT is(
ARRAY(
SELECT stuff_id FROM domain_stuff
WHERE domain_id = :domain_id AND src_id = :src_id
ORDER BY stuff_id ),
ARRAY[ 1, 2, 3 ],
’The stuff should have been associated with the domain’ );
SELECT * FROM finish(); ROLLBACK;
Figure 5.2: Example pgTAP test case
line coverage is 80% and coverage report has lesser value, build can be set to unstable and a warning email be sent.
For database function testing we used pgTAP. With pgTAP database schema, views, functions and triggers can be tested within the database us-ing SQL. Database functions could also be tested by writus-ing unit tests for database layer in the actual software code, but then the tests must connect to the database, set up transactions, execute the database functions, fetch back data into Python data structures, and then compare values. Instead, same thing can be done in pgTAP with the example in figure 5.2. There is no need to do any extra work to get the database interface to talk to the database, fetch data, convert it, etc.
5.2.6
Continuous documentation
To automatically generate documentation for source code, we use Epydoc [Epydoc]. It is a similar tool as Javadoc is for Java. It generates Hyper Text Markup Language (HTML) pages from documentation written in source code. Each python module (file), class, method, function, variable etc. may have documentation as a string attached, which is then parsed by Epydoc and formatted to generate always up to date documentation.
Figure 5.3: Example epydoc page
For database schema and function documents we used Postgres Autodoc. It generates documentation inHTMLformat from Structured Query Language (SQL) schema definition files. It also generates Entity Relationship (ER) dia-grams to visualize database schema and relations between database entities (see Figure 5.4).
5.2.7
Continuous deployment
Python software can be packaged as a python egg. An egg is actually a stan-dard zip file with some specific features, very much like Java jar files. We used python setuptools for creating them. It requires a setup file (setup.py) which tells which source files to include in the package. It is also possible to
Figure 5.4: Example Postgres Autodoc diagram
package static elements like configuration files or init scripts, which might be needed by the packaged software. Entry points to create launch scripts for packaged software can also defined in setup file (see Figure 5.5).
LabDev has several software modules which are packaged as part of the first step of CI build (see Section 5.4). We used separate naming conven-tions for development and production grade eggs. For development eggs we used software version number with dev suffix and SVN revision num-ber, e.g. ’my service-1.0 dev r123-py2.5.egg’. For production releases dev and revision suffixes were not used.
After an egg is created, it is copied to an egg repository (see Section 5.3). An egg repository is a location which can be accessed throughHTTPto fetch packages for deployment. Development and production eggs are copied to separate repositories to avoid accidentally installing development eggs to production systems. These repositories are also used to provide eggs for otherCIbuilds which depend on other software modules.
Installing eggs from repository is done usingeasy install, which is a com-mand line tool and part of python setuptools. We used it to install depend-ing modules forCIbuilds as well as to deploy software to testing or produc-tion environment.
#!/usr/bin/env python
from distutils.core import setup setup(name=’MyService’, version=’1.0’, description=’Simple service’, author=’John Doe’, author_email=’[email protected]’, packages=[’my_service’, ’my_service.lib’], entry_points={ ’console_scripts’: [ ’start_my_service = my_service:main’ ], data_files=[(’config’, [’cfg/data.cfg’]), (’/etc/init.d’, [’init-script’])] )
Figure 5.5: Example python setup file
Managing dependencies
Python setuptools can also be used to handle software dependencies. De-pendencies can be listed in setup file and when installing with easy install all the dependencies will be automatically installed. By defaulteasy install will try to install the latest version available. In some cases software updates may break backwards compatibility. In such case, a version number for each dependency can be set. We used this feature when we knew that latest ver-sion of a dependency would break build for a particular module (see Figure 5.6). When this module is then later refactored to work again with the latest version of dependencies, we removed specific version setting from setup file.
5.2.8
Continuous feedback
As a primary feedback channel we used email. Email reporting was re-ally easy to setup and Hudson can be configured to send emails after each failed build or only when build status changes. As recipients, predefined addresses can be configured with the possibility to include also the latest committer (person who broke or fixed the build).
As a secondary feedback channel we used large TV screen to show Hud-son dashboard, which displays build status and currently executing builds.
![Figure 2.1: CI work cycle based on ideas of Fowler [Fow06]](https://thumb-us.123doks.com/thumbv2/123dok_us/814785.2603031/14.892.227.706.151.540/figure-ci-work-cycle-based-ideas-fowler-fow.webp)


![Figure 4.1: Service Oriented Architecture [Haa03]](https://thumb-us.123doks.com/thumbv2/123dok_us/814785.2603031/31.892.328.608.787.987/figure-service-oriented-architecture-haa.webp)
![Figure 4.2: Scrum process [gs02]](https://thumb-us.123doks.com/thumbv2/123dok_us/814785.2603031/32.892.171.768.583.834/figure-scrum-process-gs.webp)