Storage and Retrieval of System Log Events using a
Structured Schema based on Message Type
Transformation
Adetokunbo Makanju
Faculty of Computer Science Dalhousie University Halifax, Nova Scotia B3H 1W5, Canada
[email protected]
A. Nur Zincir-Heywood
Faculty of Computer ScienceDalhousie University Halifax, Nova Scotia B3H 1W5, Canada
[email protected]
Evangelos E. Milios
Faculty of Computer ScienceDalhousie University Halifax, Nova Scotia B3H 1W5, Canada
[email protected]
ABSTRACT
Message types are semantic groupings of the free form mes-sages in system log events. The message types that exist in a log file, if known, can be used in several log manage-ment and analysis tasks. In this work, we explore the use of message types as a schema definition for the storage and retrieval of messages in event logs. We show how message types can be used to impose structure on the unstructured content of event logs and how this structured representation can provide a usable index for searching the contents of the log file. As a side benefit, the structured representation that message types impose also leads to the removal of redundant information in the event logs that leads to space savings on disk.
Keywords
Network Control and Management, Event Log Mining, Event Log Management, Systems Administration, Data Storage and Retrieval
1.
INTRODUCTION
System logs consist of several lines of text reporting events that occur on a computer system. Therefore event logs are a very important source of information for system admin-istrators. However, the growing size and complexity of log files has made the manual analysis of system logs by admin-istrators prohibitive. This fact makes it important for tools and techniques that will allow some form of automation in management and analysis of system logs to be developed [13].
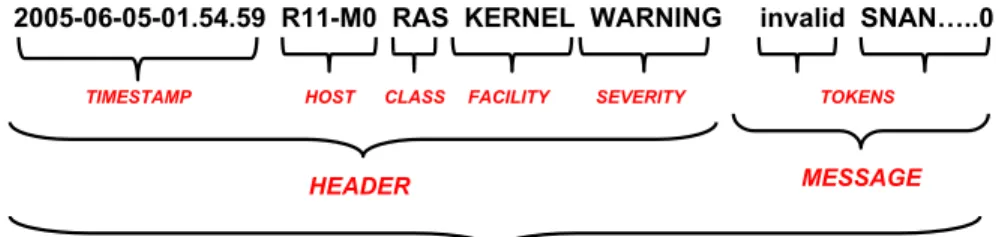
One of the major stumbling blocks to automatic analysis and management of system logs is their lack of structure, especially in regard to their free form messages [13]. A sin-gle event line in a system log will generally consist of several fields of information, see Fig. 1. The most of important of
Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. To copy otherwise, to republish, to post on servers or to redistribute to lists, requires prior specific permission and/or a fee.
SAC’11March 21-25, 2011, TaiChung, Taiwan.
Copyright 2011 ACM 978-1-4503-0113-8/11/03 ...$10.00.
which is the natural languagemessage(free form message), which describes the event. Free form messages generated by lines in source code are a feature of almost any event log. The use of natural language in these free form mes-sages is responsible for their lack of structure. The ability to impose structure on free form messages in system logs will therefore greatly enhance the ability to automatically analyze and manage them.
Though these free form messages use natural language, they however do contain some structure because they are produced by a limited set of print statements in the source code of the program that generated the message. Thus, free form messages produced by the same print statement will form aclusterin the log file, thisclusteris what is referred to as a message type. All the messages in an event log can be mapped to one of the several message types represented in the log file. If known, message types can be used to deal with the problem of unstructured free form messages. Un-fortunately, these message types are not always known a priori and automatic discovery of message types is a com-plex problem. On the other hand, there are methods which have been developed for the automatic extraction of message types [2, 5, 6, 15, 16].
This paper is however more interested in how message types can be utilized once found. Previous work has shown how message types can be used in visualization [2, 4] and feature creation for model building [7, 8, 16]. In this work, we propose using message types to transform free form mes-sages in a way that will allow the storage and retrieval of events in system logs using a structured schema definition. Also, by storing the events in a structured format, which al-lows their message types and message variables to be easily identified, their retrieval for purposes of visualization and model building as mentioned above becomes easier.
We follow up on the work done in [8], where the authors demonstrate using Message Type Transformation (MTT) as a means of imposing structure on the free form messages in system log events. As MTT produces a more compact representation, it also contributes to space savings in the storage of event logs. The results presented here show that a space saving of up to 38% can be achieved using MTT.
We discuss the concepts important to understanding our work and previous work in Section 2. Section 3 discusses the methodology of the experiments we carried out to eval-uate our proposed framework, whereas the results of those experiments are discussed in Section 4. Finally, conclusions
2005-06-05-01.54.59 R11-M0 RAS KERNEL WARNING invalid SNAN…..0
TOKENS
MESSAGE HEADER
EVENT
TIMESTAMP HOST CLASS FACILITY SEVERITY
Figure 1: An example system log event.
are drawn and the future work is discussed in Section 5.
2.
BACKGROUND AND PREVIOUS WORK
In this section, we discuss in more detail what message types are, how they can be extracted and previous examples of their application in system log management and analysis.
2.1
Message Types and Message Type
Extrac-tion
Message types are semantic groupings of event messages, which can be described using a textual template consisting of constant tokens and variable tokens (wildcards). To pro-vide an example of what a message type is, consider this line code in aCprogram :
sprintf(message, “BglIdoChip table has %d IDOs with same IP address %s”, idonumber, ipaddress);
which could produce the following free form messages in an event log:
“BglIdoChip table has 2 IDOs with same IP address (192.168.10.6)” “BglIdoChip table has 3 IDOs with same IP address (192.168.10.7)” “BglIdoChip table has 2 IDOs with same IP address (192.168.10.8)”. This group of messages forms what is referred to as a message type. This message type can be represented by the textual description“BglIdoChip table has * IDOs with same IP address *”. Message types are not always knowna pri-oriand thus may need to be discovered. Since traditional clustering algorithms have been found to be unsuitable for the task [14], specialized message type extraction algorithms have been developed. A message type extraction algorithm is an algorithm that seeks to automatically discover the mes-sage types that may exist in a log file. Its goal is to find a set of textual templates, defined by constant tokens and variable tokens, which abstract all the messages in an event log. Each message can be produced by one and only one template.
Previous approaches to the task of message type extrac-tion include SLCT and Loghound [15], extracextrac-tion from source code [16], sequential mining from an online stream [2] and IPLoM (Iterative Partitioning Log Mining) [5]. Our work utilizes IPLoM for message type extraction. IPLoM differs from other approaches in the following ways [5]:
• IPLoM does not assume any knowledge of the underly-ing system that will produce the event log, for example, source code.
• The results concerning IPLoM have been shown to match message types produced by humans more closely than previous approaches. IPLoM was able to achieve
an F-Measure result of 91% based on micro-average classification accuracy, when its results were compared with message types produced manually on the same data [6].
• IPLoM is able to find both frequent and infrequent message types in the log data. This is important as rare patterns are often important for certain types of analysis.
IPLoM works though a 4-Step process, shown in Fig 2. In its first 3 steps, IPLoM hierarchically partitions the mes-sages in an event log into their respective message types. The leaf partitions are the end of partitioning are assumed to represent groupings of the message types that exist in the log file. Thus, in its final step, IPLoM generates templates for each of the message types from the leaf partitions pro-duced. The templates produced now form the set of message types extracted by the algorithm.
2.2
Applications of Message Types in System
Log Analysis
Message types are the basicconceptsin event logs, there-fore their use in the management and analysis of event logs should not be treated as an option but as a necessity. To mo-tivate our argument, we draw an analogy fromInformation Retrievaland Text/Document Processing. These computer science disciplines deal with the processing of unstructured textual data, which is similar to event logs. We therefore be-lieve that event log analysis could borrow from techniques and concepts that have previously been successful in these disciplines.
AsInformation Retrievaland Text/Document Processing
deal with data that is unstructured, a primary approach is to build models based on term/document indexes. This approach has been found to be noisy due to the problems of polysemy and synonyms and computationally expensive due to the large number of terms that can exist in data [12]. One approach to mitigating this problem is Latent Se-mantic Analysis (LSA) / Latent SeSe-mantic Indexing (LSI) [12]. LSA utilizes singular value decomposition (SVD) on a matrix of terms by documents to discover useful artifi-cial semantic conceptsbased on the co-occurrence of terms in documents. Theseconceptscan then be used to replace the individual terms as descriptors of the documents i.e in-dexing based on the discovered concepts (LSI). LSA/LSI has been shown to improve document retrieval by mitigating the problems of polysemy and synonyms and for dimensionality reduction [12]. Since its initial application in document re-trieval, LSA/LSI has found use in several otherInformation
Step 1
•
Token count
Step 2
•
Token
Position
Step 3
•
Search for
bijection
Step 4
•
Discover
type
descriptions
Figure 2: Overview of IPLoM processing steps. (1) Partition by token count. (2) Partition by token position. (3) Partition by search for bijection. (4) Discover type descriptions.
RetrievalandText/ Document Processingtasks.
Theconceptdiscovery carried out by LSA in information retrieval and Text/Document Processing community is very similar to message type extraction. Message types represent terms, which occur frequently together in the events in an event log and they also representreal semantic conceptsin the minds of the programmer who wrote the code. It there-fore makes sense to utilize them when analyzing log files. Previous work has shown that this approach is promising. In [16] the authors propose a framework for detection of system problems through the mining of console logs. Using message types extracted directly from program source code, relevant features were extracted and processed using Prin-cipal Component Analysis (PCA). The PCA analysis was able to identify outliers (anomalies), which they showed cor-responded with periods where faults were injected into the network. In [2] the authors propose a sequential algorithm for the discovery of message types. Then, they discover fre-quent co-occurrences of message types, which they use in the diagnosis of system problems and in the visualization of the log data. In [7, 8] the authors propose message type indexing (MTI) as an alternative to the term based indexing approach of the entropy based alert detection framework of Nodeinfo [9]. The use of MTI was able to reduce the com-putational effort and memory requirements of Nodeinfo by a 100 orders of magnitude without a drop in its detection capability.
Visualization has always proved invaluable in aiding the analysis of large amounts of data by human observers. It is therefore not surprising that event log visualization tools have been proposed in the literature. Two examples of pro-posed system log visualization tools, which utilize message types can be found in [2] and [4]. In [2], the authors demon-strate how the visualization of correlated message types in event logs are useful for the characterization of system be-havior and ultimately the detection of faults. In [4] the authors propose a Treemap [11] based visualization of event logs, which groups the raw events based on their respective message types.
In our work, we propose the use of message types as a means of imposing structure on event logs messages for stor-age and retrieval using a structured schema. Doing this would not only aid their efficient storage and retrieval but will imply that event logs will be ready for use in other log management and analysis tasks like the ones described ear-lier.
3.
METHODOLOGY
In this section, we describe the key parts of our method-ology, i.e. Message Type Transformations and the proposed schema. We also describe our evaluation methods and the datasets utilized in our evaluations.
3.1
Message Type Transformation (MTT) and
Alternate Schema
Message Type Transformation (MTT) [8] is the most im-portant part of our methodology. With MTT, the unstruc-tured message of an event can belosslesslytransformed into an alternate format, which is structured and removes re-dundancy. We can therefore take advantage of this new structured format to provide an alternate schema for stor-ing system log events.
As it is intended for the transformation to belosslessand compact, the Message Type Transformation with variables
technique, Fig. 3 is proposed. This MTT transforms a mes-sage by first representing it using a unique term (Mesmes-sage Type ID) that represents its message type. It then appends its variable tokens to the transformation in the same or-der they appeared in the original message. The encoding of token positions is very important to the semantics of an event log, hence the importance of maintaining the order of the variable tokens in the original message format. Unlike the other MTTs proposed in [8], the MTT with variables
technique produces a more concise representation than the
Phrasal MTT and does not result in information loss like theFull MTT.
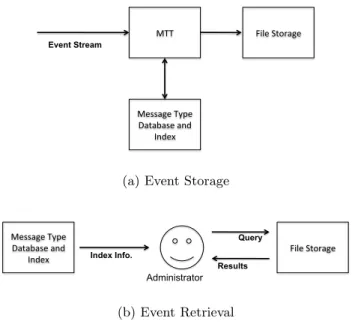
Most modern computer systems, especially those that fol-low thesyslogformat [3] would have a schema similar to the one shown in Fig. 1, i.e. {Timestamp, Host, Class, Facil-ity, SeverFacil-ity, Message}. We suggest an alternative schema that breaks the events log based on message types and the creation of a message type index that maps to each event log. The schema for the message type index will be of the form {MsgTypeID, MsgTypeFormat}, while the schema for each message type log will be of the form{Timestamp, Host, Class, Facility, Severity, Var1, Var2,....,VarN}. The V ar1. . . V arN fields will store each of the variable tokens in the message, as each one of these tables will contain only events of the same message type, the value ofNwill be con-stant for each table and the events stored therein. A visual depiction of how the a stream of messages can now be stored and retrieved is provided in Fig. 4.
We believe that this new storage and retrieval system based on our proposed schema will provide the dual benefit of 1) Faster searches 2) Space savings on disk. Our evalua-tions hope to show this to be true. The space savings which we hope to achieve with MTT should not be confused with the kind of compression that is achieved with tools likezip. With tools like zipanarchived document is created which cannot be used withoutunzipping. On the other hand, with MTT alivedocument which can be used as it stands is cre-ated. Also the use of MTT does not prevent the use of tools likezipwhen anarchived document needs to be created.
BglIdoChip table has * IDOs with same IP address * BglIdoChip table has 2 IDOs with same IP address (10.0.0.23) BglIdoChip table has | 2 | IDOs with same IP address | (10.0.0.23)
MsgTypeID 2 (10.0.0.23)
BglIdoChip table has | IDOs with same IP address | 2 | (10.0.0.23) BglIdoChip table has IDOs with same IP address | 2 | (10.0.0.23)
Figure 3: Message Type Transformation with variables: The procedure starts with an individual message as contained in the
first box on the right. The box on the left contains the message type template which matches the message in the first box on the right. In the final box on the right,MsgTypeIDrepresents a unique ID assigned to the message type and will thus change for different message types.
MTT File Storage
Message Type Database and
Index Event Stream
(a) Event Storage
File Storage Message Type Database and Index Administrator Index Info. Query Results (b) Event Retrieval
Figure 4: Proposed Event Storage and Retrieval Procedure.
The datasets utilized in this work are four HPC datasets [10] recently made publicly available in the USENIX Com-puter Failure Data Repository [1]. These logs represent probably the largest set of publicly available HPC logs, cov-ering approximately 111GB of data containing almost a bil-lion events. The four datasets utilized are Blue Gene/L (BGL), Liberty, Spirit and Thunderbird (Tbird). Each line in the log data contains an actual event from the HPC ma-chine that produced the log plus four additional fields, which are added to ease parsing. The four fields represent alert category ( a “-” meaning no alert category), the Unix time-stamp, date and identifier for the device that generated the event. After these four fields comes the actual event as re-ported in the logs, the event consists of six fields, the first field represents the time-stamp, next comes the message source, the event type (the mechanism through which the event is reported), the event facility (the reporting compo-nent), the severity and the free form event description or
Table 1: Log Data Statistics
Log Days Size(GB) # Events
Blue Gene/L 215 1.207 4,153,009
Liberty 315 22.820 200,940,735
Spirit 558 30.289 218,697,851
Thunderbird 244 27.367 155,403,254
message. In our work, we are specifically interested in the free form event description, though we do utilize other fields to perform our analysis. For instance, the reporting device identifier allows us to group the events in any log based on the functional category of the device that produced the event. Using this information, we were able to split the events in each dataset into functional node categories. In this paper, we only present results for the Compute node category of each log. This functional grouping represents over 73% of all events in each of the the logs, it is there-fore safe to assume that results for this category should be representative of results over the entire dataset. The char-acteristics of the HPC logs are described in Table 1.
3.3
Evaluations
To evaluate the space savings gained by transforming mes-sage portions of events using MTT, we extract mesmes-sage types using IPLoM and then transform the events using the ex-tracted message types, creating a new log file in the pro-cess. We then compare the size of the transformed file to the original to see how much space is saved, if any, by the transformation. To show that our proposed schema will lead to faster searches, we compare the size of indexes that will be required to index the event log before and after transfor-mation with MTT. In both cases we report the % reduction, which is calculated using the formula in Eq. 1 below.
%Reduction= 1−T ransf ormed Size
Original Size (1)
4.
RESULTS
Indexing has always been a means of increasing the speed of searches of textual data. In the case of event logs, searches are mostly done through sequential searches of the lines of the event log using thegrepcommand. If we wanted to make
Table 2: Percentage Reduction in # of terms
Original Transformed % Reduction
#Terms #Terms BGL 491,768 399 99.92 LIberty 1,129,767 481 99.96 Spirit 898,111 854 99.90 Tbird 4,877,988 1,262 99.97 Avg. 99.94
this search any faster, we would have to create an index of the unique tokens in the event log. With the new schema proposed, the size of such an index can be significantly re-duced. The results of the reduction in the number of terms required for an index are shown in Table 2. The average reduction in the number of terms is 99%, which theoretical implies a 100 order magnitude reduction in the time required for searches.
For example, if an administrator was interested in retriev-ing all messages of the form“Connection from * port *”or all messages with word“Connect”from an event log stored in log.txt using the traditional schema, he/she could issue the following commands (grep “Connection from * port *” log.txt) or (grep Connection log.txt) respectively. In both cases, such a search would in the worst case require a se-quential search through the entire event log. Even with an index, the search could still take a significant amount of time, since such an index would be very large, see Table 2. With our proposed schema, a search for messages of the form
“Connection from * port *”would in the worst case require a search through the message type index database for the message type ID linked to the messages of the form that the administrator seeks to find and this will lead straight to the required event log, which would be returned to the adminis-trator, see Fig. 4. A search for the messages with the word
“Connect”in them, with the proposed schema would require, firstly a search through the message type index database for the message type IDs of all message types which contain the word“Connect”and then secondly a sequential search through the event logs of message types which do not con-tain the word“Connect”. In both cases the proposed schema leads to faster search times, with queries of the first type be-ing significantly faster. Since message types are fundamental concepts in event logs it is safe to assume that most searches issued by administrators would be of the first type. We also note that the proposed schema also provides the possibility of usingSQLtype queries when searching the event log.
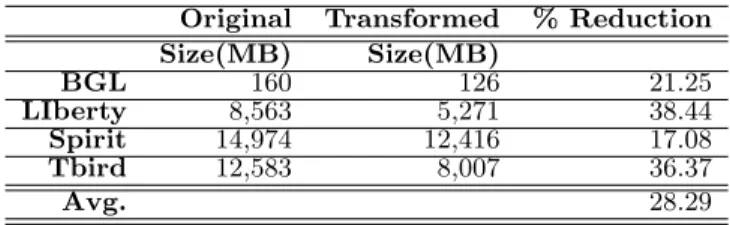
One of the advantages that can be derived from message type transformation is the removal of redundancy in the event logs. Our results show an average reduction in size on disk of approximately 28%, with a best case scenario of approximately 38% reduction, see Table 3. This percentage reduction in file size can be significant in most cases, being measured in GBs if not TBs on most modern computer sys-tems. Indeed the space gain from the transformation of the
Tbirdfile is in the order of 4GBs. As this transformation is “lossless” and is not mutually exclusive to further compres-sion using other techniques, we believe these results show that MTT can provide significant space savings for the stor-age of yet to be archived event logs.
5.
CONCLUSION AND FUTURE WORK
Table 3: Percentage Reduction in File Size
Original Transformed % Reduction
Size(MB) Size(MB) BGL 160 126 21.25 LIberty 8,563 5,271 38.44 Spirit 14,974 12,416 17.08 Tbird 12,583 8,007 36.37 Avg. 28.29
Message types form natural semantic concepts in log files. For this reason, they should be used when free form mes-sages are required for log file analysis. Unfortunately, the fact that message types are not always known a priori has hindered their use in system log analysis. The advent of several automatic message type algorithms has now allowed the message types to be incorporated into event log manage-ment and analysis mechanisms. In this work, we investigate their use in providing a structured schema for the storage and retrieval of system logs.
Using MTT we show that our proposed schema can lead to savings of up to 38% in the space required to store event logs. We also argue that significant reductions in search time can be achieved by using an index based on message types. Such an index would provide reduction in the size of a traditional index of a 100 orders of magnitude. Just as LSA has found use in text processing beyond the task of document retrieval, which it was initially designed for, it is likely that message type based analysis of log files can find use in automatic log analysis beyond the examples mentioned in this work.
Since it is now possible to accurately extract message types automatically, the methods described in our work can practically be implemented in any system since the process can be fully automated. Future work will involve imple-menting and testing of our schema using other event logs.
Acknowledgements
This research is supported by a Natural Sciences and En-gineering Research Council of Canada (NSERC) Strategic Project Grant. This work is conducted as part of the Dal-housie NIMS Lab at http://www.cs.dal.ca/projectx/.
6.
REFERENCES
[1] Usenix - the computer failure data repository. Last Accessed June 2009.
[2] M. Aharon, G. Barash, I. Cohen, and E. Mordechai. One Graph Is Worth a Thousand Logs: Uncovering Hidden Structures in Massive System Event Logs.
Lecture Notes in Computer Science, 5781/2009:227–243, 2009.
[3] C. Lonvick. The BSD Syslog Protocol. RFC3164, August 2001.
[4] A. Makanju, S. Brooks, N. Zincir-Heywood, and E. E. Milios. Logview: Visualizing Event Log Clusters. In
Proceedings of Sixth Annual Conference on Privacy, Security and Trust. PST 2008, pages 99 – 108, October 2008.
[5] A. Makanju, A. N. Zincir-Heywood, and E. E. Milios. Clustering Event Logs Using Iterative Partitioning. In
Proceedings of the 15th ACM Conference on
Knowledge Discovery in Data., pages 1255–1264, July 2009.
[6] A. Makanju, A. N. Zincir-Heywood, and E. E. Milios. Extracting Message Types from BlueGene/L’s Logs. InProceedings of the SOSP Workshop on the Analysis of System Logs (WASL), October 2009.
[7] A. Makanju, A. N. Zincir-Heywood, and E. E. Milios. Fast Entropy Based Alert Detection in Supercomputer Logs. InProceedings of the DSN Workshop on
Proactive Failure Avoidance, Recovery and Maintenance (PFARM)., June 2010.
[8] A. Makanju, N. Zincir-Heywood, and E. E. Milios. Message type extraction based alert detection in system logs. Technical Report CS-2009-08, Dalhousie University, March 2009.
[9] A. Oliner, A. Aiken, and J. Stearley. Alert Detection in System Logs. InProceedings of the International Conference on Data Mining (ICDM). Pisa, Italy., pages 959–964, Los Alamitos, CA, USA, 2008. IEEE Computer Society.
[10] A. Oliner and J. Stearley. What Supercomputers say: A Study of Five System Logs. In37th Annual IEEE/IFIP International Conference on Dependable Systems and Networks, 2007 (DSN ’07)., pages 575–584, June 2007.
[11] B. Schneiderman. Tree Visualization with Tree-Maps: A 2-D space filling approach. InACM Transactions on Graphics., volume 2, pages 92–99, 1992.
[12] Scott Deerwester, Susan T. Dumais, George W. Furnas, Thomas K. Landauer, and Richard Harshman. Indexing by Latent Semantic Analysis.
Journal of the American Society for Information Science, 41(6):391–407, 1990.
[13] J. Stearley. Towards Informatic Analysis of Syslogs. In
Proceedings of the 2004 IEEE International Conference on Cluster Computing, pages 309–318, 2004.
[14] R. Vaarandi. A Data Clustering Algorithm for Mining Patterns from Event Logs. InProceedings of the 2003 IEEE Workshop on IP Operations and Management (IPOM), pages 119–126, 2003.
[15] R. Vaarandi. Mining Event Logs with SLCT and Loghound. InProceedings of the 2008 IEEE/IFIP Network Operations and Management Symposium, pages 1071–1074, April 2008.
[16] W. Xu, L. Huang, A. Fox, D. Patterson, and M. I. Jordan. Detecting large-scale system problems by mining console logs. InSOSP ’09: Proceedings of the ACM SIGOPS 22nd Symposium on Operating systems principles, pages 117–132, New York, NY, USA, 2009. ACM.