Predicting breast cancer risk, recurrence and survivability
119
0
0
Full text
Figure
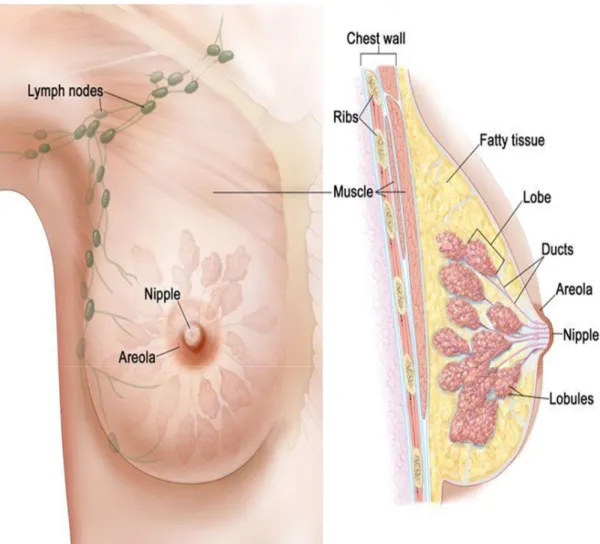
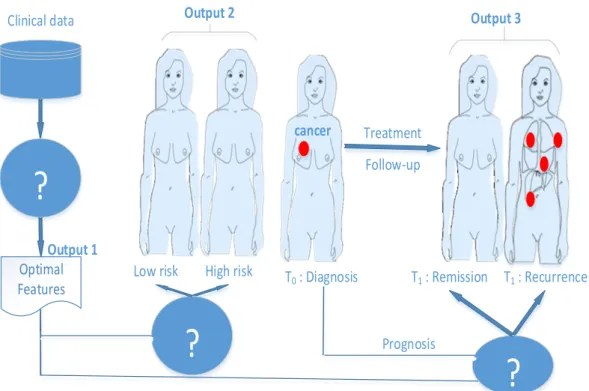
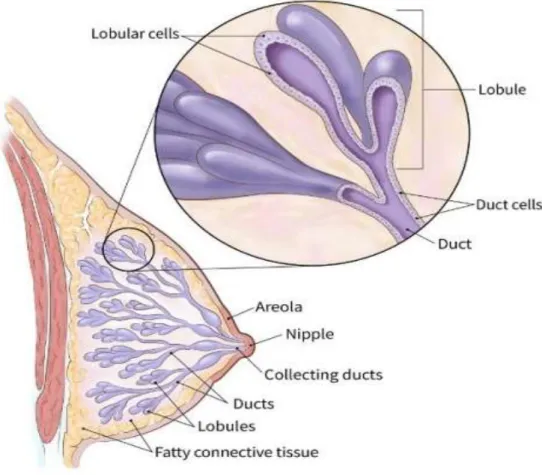
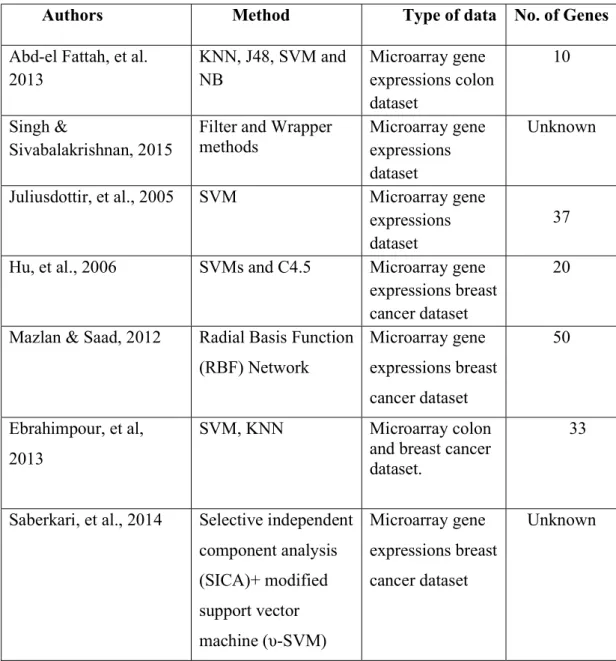
+7
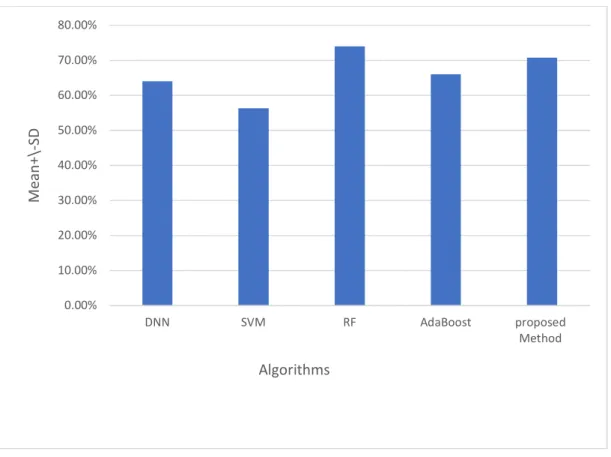
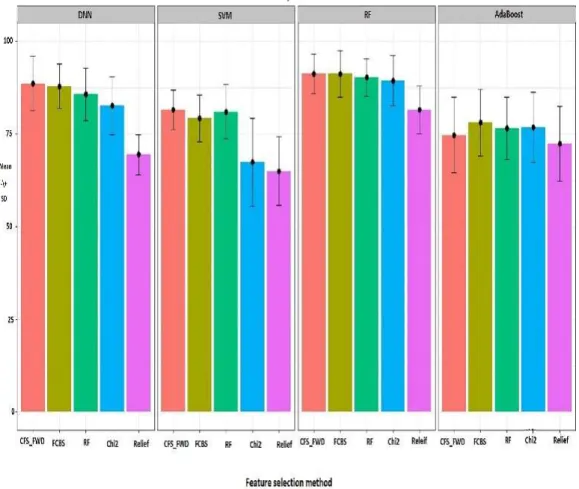
Outline
Related documents