2845
Mining Of High Average Utility Itemset From
Interested Items
Md Tabrez Nafis, Samar Wazir, Amit Kumar, Deepak Kumar Sharma
Abstract— A technique which is used to extract interesting data and sequence of data from huge datasets is basically known as Data Mining. Frequent Itemsets extracting (FIM) algorithm like Apriori, FP Growth, Eclat along with many more are used to extract the frequent Item sets from static dataset. But these typically algorithms gives only reoccurred Itemsets depend on the occurrence of the item in datasets. High Average Utility Itemsets Extracting (HABIE), a subfield of data extracting which is used to uncover High Utility Itemsets (HUI) by combining items based on quantity and unit profit. These algorithms are tends to work on static dataset. But in real life scenario, requirement changes at every moment and extent of the datasets varies accordingly. To uncover the exact High Utility Itemsets, incremental mining algorithms came in existence. An Incremental Extracting Algorithm for High Average-Utility Itemsets (IEHAUI) , a FUP based concept which is used to merge the output of original dataset with new mined output of new dataset. These traditional algorithms provides all High average beneficial itemsets with large unpromising itemsets. Now our proposed algorithm, we extract the High Utility Itemsets with Interesting items from incremental dataset of real life situation.To our best of knowledge, no algorithm is yet developed to extract the High Utility Itemsets with Interesting items using Incremental dataset.
Keywords— Uitlity Mining, Itemset Mining, Interested Itemset Mining, Data Mining, High Average Uitlity Itemset, Upper Bound Mining, Incremental Mining .
—————————— —————————— 1 INTRODUCTION
Data Mining is a technique which is used to discover the vital and hidden material from a huge data set and it has grabbed a noticeable research in various application domain like Data Mining, E-Commerce, Social Networking, Environment Science, Web Mining, etc. The extracted information can be used by the decision-maker to plan more considerable and efficient planning to increase the business of his organization in a well-organized way. Algorithms like Apriori[1], FP-Growth[2], Eclat[3], High Utility[4], High Average
Utility and many more had developed to extract the information from huge datasets. Apriori[1] algorithm is a base algorithm which was developed by the R Agrawal and Srikant in 1994. Apriori[1] is used to extract the regular itemsets from certain datasets based on the correlation between the items. This is also known as association rule mining (ARM). This algorithm works on user-defined minSup to discover Frequent Itemset. Items that qualify the minSup are considered frequent itemset and others discarded from the set. Initially, it generates a single candidate frequent itemset and further it increases the level. It uses a level-wise approach to generate and test the candidate. It generates a number of unpromising candidate item sets that require a lot of computation and memory. It may cause leakage of Memory if the dataset volume is too vast. The FP-Growth[2] Algorithm was developed by Han to overcome the limitation of the previous algorithm i.e Apriori[1] algorithm and Eclat[3]. It proposed a more optimized algorithm for mining the frequent itemsets without
generating candidate sets by using the divide and conquer approach along with a different data architecture named as Frequent Pattern Tree (FP Tree). FP Growth tree reduces the computation time and memory usage in comparison of Apriori[1] and Eclat[3] algorithms. Subsequently, many more algorithms to discover the frequent itemsets from datasets were being developed. This algorithm finds frequent items sets based on the total number of occurrence of an element in the dataset. All these algorithm works on the static dataset but in a real-life scenario, requirement changes at every moment and extent of the datasets varies accordingly. Items in the original datasets varies as few data may be added or few data may be lost and mined information need to be updated frequently by using the FUP[7] algorithm which divide the original datasets and new datasets into four cases as depicted below:
As mentioned above, frequent itemsets generated by using FIM algorithms based on the total number of occurrence of an element in the dataset. These itemsets share a little segment to overall benefit in the real world but there is a possibility that a non- frequent item may share a big segment to overall benefit e.g if a dataset contains 5 times of bread and 1 time of LED TV with total utility 10 and 1000 respectively. If the minimum support is 3 then only bread will remain in FIM and LED TV discards from the dataset as it does not qualify the minSup. To eliminate this limitation Mining High Utility Itemset (MHUI) algorithms come in to force. MHUI[4] algorithm was proposed by R Chan, Q Yang and D Shen in 2003 to Extract High Utility Itemset. In this algorithm, the utility was used as a basic acceptable data to check the practicability of association rule and named as Objective Oriented Utility-Based Association. The utility of an ————————————————
• Dr. Md Tabrez Nafis is working as an Assistant Professor in Dept of Computer Science &Engineering at Jamia Hamdard, India. E-mail: [email protected]
• Dr. Samar Wazir is working as an Assistant Professor in Dept of Computer Science &Engineering at Jamia Hamdard, India. Email: [email protected]
• Amit Kumar is currently pursuing M.Tech(CS) program in Dept. of Computer Science & Engineering at Jamia Hamdard, India. E-mail: [email protected]
element in a dataset is multiplication of the total item sold and profit. For example, if a database conations items W, X, Y, Z and their total quantity sold are 10, 5, 6, 4 respectively and their profit values are 2, 3,5,6 respectively. So their utilities are 20, 15,30,24 respectively. To overestimate the utility, downward closure property was implemented by Li et al in his algorithm Mining Expected Algorithm[9] (MEU) and to expedite the mining other algorithm named Fast High Utility Itemset Mining algorithm. The utility of the itemset increase as the number of the items in the itemset increase and it became more difficult to uncover the accurate high Utility itemsets with predefined minimum utility threshold value. High average utility itemset(HAUI[12]) was developed by Hong to reduce the High Utility itemset. In this algorithm, total Utility of the itemset is divided by the total occurrence of the itemset and result is called High average utility itemset if it is equal or more than minimum utility threshold value e.g if an itemset {WY} has total utility 30 and minimum threshold value is 14 then length of the itemset is 2 and average utility of itemset{WY} is 30/2 = 15 which is greater than minimum threshold value i.e 14. Hence itemset {WY} is called High average Utility itemset. Subsequently, Efficiently mining high average utility itemset with an improved upper bound(EHUIAUUB)[8] was given by TP Hong et al in 2011. EHUIAUUB[8] is based on the prefix concept to reduce unpromising itemset. Since the algorithms described above works on static datasets and generate only High utility itemset in huge amount using high computation and memory. Out of them, only a few itemsets may interested itemset. In our study, we proposed an incremental method to find High average Utility itemset from interesting items. This algorithm contains two phase, in the initial phase we find the interesting itemset. In the later phase, we find the High utility itemsets of interesting items.
2
R
ELATED WORKS2.1 Incremental Dataset Concept:
Data Mining is a technique which is used to dig out the vital and hidden material from a huge data sets. Apriori[1] is a base algorithm which was developed by the R Agrawal and Srikant in 1994. Apriori[1] is used to uncover the regular itemsets from a certain dataset based on a correlation between the items. This is also known as association rule mining (ARM). This algorithm works on user-defined minSup to discover Frequent Itemset. Items that qualify the minSup are considered frequent itemset and others discarded from the set. Initially, it generates single candidate frequent itemset and further it increases the level. It uses a level-wise application to make and test the candidate. It generates a number of unpromising candidate item sets that require a lot of computation and memory. It may cause leakage of Memory if the dataset volume is too vast. In unsupervised learning, k-means algorithm was found to be in inadequate to handle large datasets. So a novel modified k-means algorithm was developed to address this issue[6 ]. The FP-Growth[2] Algorithm was developed by Han to overcome the limitation of the previous algorithm i.e Apriori[1] algorithm and Eclat[3]. It proposed a more optimized method for mining the frequent itemsets without generating candidate sets by using the divide and conquer approach along with a differenct data architecture named as Frequent Pattern Tree (FP Tree). FP Growth tree reduces the computation time and memory usage in comparison to
Apriori[1] and Eclat[3] algorithms. Also ordered weighted average operator has been used to enhance the accuracy of fuzzy predictor based on genetic algorithm[13]. Subsequently, many more algorithms had developed to extract the FIM but all these algorithms work on a static dataset. In real life situation, requirement tend to change at each and every moment result which effect the dataset. Datasets vary according to requirement and mined information is no more useful and requires re-evaluation. The traditional algorithm reprocesses the whole modified dataset in batch manner whenever any modification i.e insertion, deletion, modification carried out in the original dataset. This process a lot of computation and computer resources. To get rid of all these problems, Fast Update (FUP)[7] was developed which is more capable to handle the incremental dataset with any modification (insertion, deletion, updating ) in the original dataset. FUP[7] algorithm which divides the original datasets and new datasets into four cases as depicted below:
Four Cases of FUP Algorithm
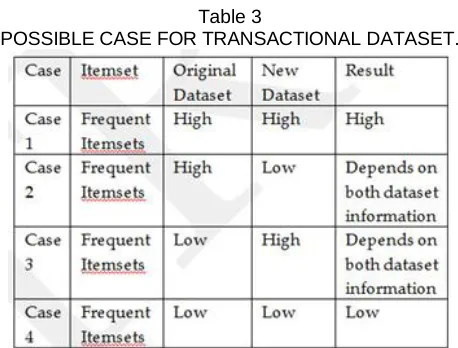
From the above table, it is very clear that an itemset remains high frequent itemset if it fall in case 1. Similarly, itemset remain low frequent itemset if falls in case 4. The result of case 3 and case 4 depends on the information provided in both datasets. Additional rescan of the original dataset is required in case 3.
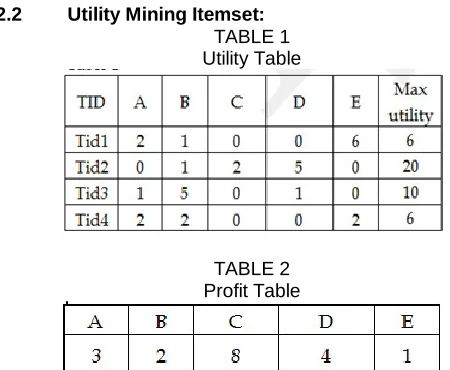
2.2 Utility Mining Itemset: TABLE 1 Utility Table
TABLE 2 Profit Table
MHUI[4] algorithm was proposed by R Chan, Q Yang and D
2847 database is multiplication of the total item sold and profit. For
example, if a database in Table:1 contains items A,B,C,D,E and their total quantity sold are 5, 9, 2, 6,8 respectively and their profit values are 3,2,8,4,1 respectively. So their utilities are 15,18,16,24,8 respectively. To overestimate the utility, downward closure property was implemented by Li et al in Mining using Expected Algorithm[9] (MEU) and to speed up the mining other algorithm named Fast High Utility Itemset Mining algorithm was developed. HUI algorithms makes a lot of unpromising itemset and require high computation along with more computer resources. A Two Phase algorithm (TPU)[10] was given by Liu et al to lessen the search area, high accuracy and fewer candidates. In the first phase, transaction weighted downward closure property implemented to lessen the search area with fewer candidate itemset. In the later phase, the dataset scan is carried out to prune the high utility itemset. The utility of the itemset increase as the number of the items in the itemset increase and it became more difficult to uncover the accurate high Utility itemsets with a predefined minimum utility threshold value.
2.3 High Average Utility Itemset(HAUI):
The main obstacle in a typical Utility algorithm is an increment in the Utility of an itemset with respect to the growth of the size of an itemset. It becomes very difficult to find the exact high Utility itemset with predefined least utility threshold value. High average utility itemset[4](HAUI) was developed by Hong to reduce the High utility itemset problem. In this algorithm, total utility of the itemset is divided by the total length of the itemset and result is called High average utility itemset if it is equal or more than minimum utility threshold value e.g in table1 1-itemset utility {A}=(15/1=15), {B}=(18/1=18), {C}=(16/1=16), {D}=(24/1=24), {E}=(8/1=8). Here {A}, {B}, {C} and {D} are high utility 1-itemset and utility of 2-1-itemset {AB}=(5*3 + 9*2)/2=16.5 which is greater than minimum threshold value i.e 14. Hence itemset {AB} is called High average utility 2- itemset. Further HAUI algorithm integrated with FP Tree architecture by Lin et al and developed a new algorithm named HAUP-growth[11] algorithm to enhance the output of HAUI. HAUI generates a lot of unpromising itemset. GC Lan et al proposed an Efficiently Mining High Average Utility Itemset With An Improved Upper Bound Strategy (EHAUIUBS)[11] in which both maximum utility and transactional utility of each transaction in a dataset are calculated. The average utility upper bound of an itemset is the summation of the maximum utility of each transaction in which itemset exist e.g maximum utility of each transactions are 6,20,10,6. Itemset {A} occurs in transaction Tid1, Tid3 and Tid4. Thus AUUB of itemset{A} = (6+10+6) =22 which is greater than minimum threshold value i.e 14.
3 P
ROBLEMS
TATEMENTThe typical utility algorithm generates a large number of itemset with a high utility item set. These algorithms require a lot of computation to calculate and storage resources to store the generated itemsets. But all the generated itemsets are not interested itemset. Thus a lot of them become unpromising itemsets. In this paper, we have introduced the way to find a High Utility Itemset with Interested items under some specific conditions after merging the old dataset and new dataset.
4 P
ROPOSEDH
IGHA
VERAGEU
TILITYI
TEMSETS FROMI
NTERESTINGI
TEMSHere, we have developed a way to find a High Utility Itemset from Interested items. Our proposed algorithm is a two-phase algorithm. In the first two-phase, we have to find an interesting item from the old dataset and a new dataset. In the second phase, we have to find the HAUIM itemset from interested items.
4.1 Mining of Interested Itemset
The first phase of the proposed algorithm is based on a fast updated(FUP[7]) concept. Two incremental datasets' original dataset 'D' and new dataset 'd' are merged using the FUP[7] concept.
Step 1: Total number of transactions(TT) in each original dataset 'O' and new dataset 'N' are summed. let old transaction contains 10 and new transaction contains 5 transaction. So TT is 10+5=15.
Step 2: let 'mo' for initial minSup, 'm1' and 'm2' are minSup for old dataset and new dataset respectively. 'm' is the new average minSup for merged dataset.
m1 = (mo*100)/TT m2 = (mo*100)/TT m = m1+m2;
Step 3: In this step, we examine minSup of each item in both datasets and merge these datasets using the FUP[7] concept. Based on minSup, FUP[7] technique divides the dataset in four cases as depicted below:
Table 3
POSSIBLE CASE FOR TRANSACTIONAL DATASET.
Now we will explain all four case of the old dataset and new dataset in details :
Case 1: Let assume IO={i1,i2,i3,i4,...in} is an itemset in old
transactional database 'O' and itemset IN={i1,i2,i3,i4,...in} in
new transactional database 'N' then we can easily say these itemset have high intrested itemset after merging the both database i.e
IO > = m1 (Items in old Database)
IN >= m2 (Items in new Database) then
IO+IN >= m
Case 2: In this case, the frequency of items in the IO
(Original Dataset) is high, and the frequency of the item in the IN(new Dataset) is low, then conclusion of the frequency
will depend on the information provided in both database and we need to merge both dataset. We can easily conclude that an itemset is highly interested if summation of frequency of itemsets are greater than or equals to 'm' after margining i.e
IO > = m1 (Items in old Database)
IN < m2 (Items in new Database) then
IO+IN >= m
other itemset is low interested i.e IO+IN >= m
Whereas 'm' is denotes the average minimum support value after the summation of the old dataset and new dataset.
Case 3: In this case, the frequency of items in the IO
(Original Database) is Low, and the frequency of the item in the IN(new database) is High, then conclusion of the
frequency will depend on the information provided in both database and we need to merge both dataset. We can easily conclude that an itemset is highly interested if summation of frequency of itemsets are greater than or equals to 'm' after margining i.e
IO > = m1 (Items in old Database)
IN < m2 (Items in new Database) then
IO+IN >= m
other itemset is low interested i.e IO+IN >= m
Whereas 'm' is denotes the average minimum support value after the summation of the old dataset and new dataset. Case 4: In this case, the frequency of itemset is low in both dataset original dataset and new dataset. The frequency of items will remain low after merging the both IO old dataset
and IN new dataset. So we do not need to merge both
dataset and computation i.e
IO < m1 (Itemset in old Database)
IN < m2 (Itemset in new Database) then
IO + IN < m
where IO is Old datasets, IN is a new dataset.
m1 is minSup for original dataset.
m2 is minSup for new dataset.
m is average minSup after merging both dataset.
Before merging both datasets we conclude that these itemsets are not high average utility itemset with interesting items.
In our proposed algorithm, we skip case 1 and case 4 because the result of these cases is predetermined by FUP[7]concept. we need to work on case 2 and case 3 as per the algorithm provided below:
Algorithm 1: Phase 1:-
Input: An array 'AO' contains all items in the original
dataset with count.
An array 'AN' contains all items in the new dataset with the
count.
User-defined minSup.
Total transaction TO of original dataset.
Total transaction TN of new dataset.
Output : High interested datasets.
1. Calculate Total Transaction (TT) = TO + TN.
2. Calculate minSup (m1) for original dataset (O) =
(minSup * TO) / 100.
3. Calculate minSup (m2) for new dataset (N) =
(minSup * TN) / 100.
4. Calculate average minSup (m) = m1 + m2;
5. Create new Array Am to hold the merged data with
count.
6. for each ik in AO do
7. if
8. AO[k] >m1 and AN[k] >m2
9. insert AO [k] into Am
10. else if
11. AO[k] > m1 and AN[k] < m2
12. if
13. AO[k] + AN[k] > m
14. insert AO [k] into Am
15. else if
16. AO[k] < m1 and AN[k] > m2
17. if
18. AO[k] + AN[k] > m
19. insert AO [k] into Am
20. else
21. AO[k] < m1 and AN[k] < m2
22. end for loop
22. remove items from both database 'O' and 'N' those does not exist in Array Am.
Algorithm 2
Input: O, a quantitative database, PfTable, a profit table, the total utility of dataset 𝑇𝑈O in O; 𝛿, the minimum
average-utility threshold. ℎ 𝑡𝑟𝑒𝑒, to create HAUP-tree from O dataset; N, is a set of inserted new transactions.
Output: The high average utility with interested itemset pattern tree.
1 for each 𝑇y ∈N do 2 calculate 𝑡(𝑇𝑞y); 3 for each 𝑖k in N do 4 calculate 𝑎𝑢(𝑖k);
5 calculate total utility in N as 𝑇𝑈N;
6 calculate updated total utility 𝑇𝑈𝑈 = 𝑇𝑈O + 𝑇𝑈N; 7 for each 𝑖k ∈indexTable of Htree do
8 for each 𝑖k in N do
9 if 𝑎𝑢(𝑖k )O + 𝑎𝑢𝑢𝑏(𝑖k )N ≥ 𝑇𝑈𝑈 × 𝛿 then 10 𝑎𝑢(𝑖k )𝑈 = 𝑎𝑢𝑢𝑏(𝑖k)O + 𝑎𝑢𝑢𝑏(𝑖k )N ; 11 update 𝑎𝑢(𝑖k ) ∈indexTable as
𝑎𝑢𝑢𝑏(𝑖k )𝑈 ;
12 𝑖𝑛𝑠𝑒𝑟𝑡S𝑒𝑡 ← 𝑖𝑛𝑠𝑒𝑟𝑡S𝑒𝑡∪𝑖k ;
13 else if 𝑎𝑢(𝑖k )O + 𝑎𝑢𝑢𝑏(𝑖k )N< 𝑇𝑈𝑈 × 𝛿 then
14 parentNode(𝑖k ).child← childNode(𝑖k ).parent ;
15 remove 𝑖k from Htree; 16 remove 𝑖k from indexTable
17 else
18 if 𝑎𝑢(𝑖k )N ≥ 𝑇𝑈N × 𝛿∧𝑖k ∉ indexTable then
19 rescan O to obtain 𝑎𝑢𝑢𝑏(𝑖k )O;
20 if 𝑎𝑢(𝑖k )O + 𝑎𝑢𝑢𝑏(𝑖k )N ≥ 𝑇𝑈𝑈 × 𝛿then 21 rescanSet ←rescanSet ∪𝑖k ;
2849 24 UpdateBranch(rescanSet );
25 UpdateBranch(insertSet );
UpdateBranch(insertSet );
Input: the itemsets in the insert set.
Output: The updated high average utility with interested Tree.
1 for each 𝑖k in the insertSet do
2 for each 𝑖k ⊆𝑇y ∧𝑇y ∈ O || 𝑇y ∈ N do 3 if 𝑖k ∈ Htree.branch ∧𝑖k ∈insertSet then 4 𝑛𝑜(𝑖k ).𝑎𝑢𝑢𝑏+ = 𝑡𝑚𝑢(𝑇y );
5 𝑛𝑜(𝑖k ).quanAry += 𝑇𝑞 .𝑞𝑢𝑎𝑛𝑡𝑖𝑡𝑦[1..k];
6 else
7 if 𝑖k ∈ insertSet ∧𝑖k ∈ rescanSet then 8 find the 𝑖k .𝑝𝑜𝑠𝑖𝑡𝑖𝑜𝑛 in 𝑇y ∈ O; 9 𝑛𝑜(𝑖k ).𝑎𝑢𝑢𝑏 = 𝑡𝑚𝑢(𝑇y );
10 𝑛𝑜(𝑖k ).quanAry = 𝑇𝑞 .𝑞𝑢𝑎𝑛𝑡𝑖𝑡𝑦[1..k];
5. A
WORKING EXAMPLEIn this section, we illustrate the proposed High average utility itemset with an interested itemset algorithm with the help of a working example.
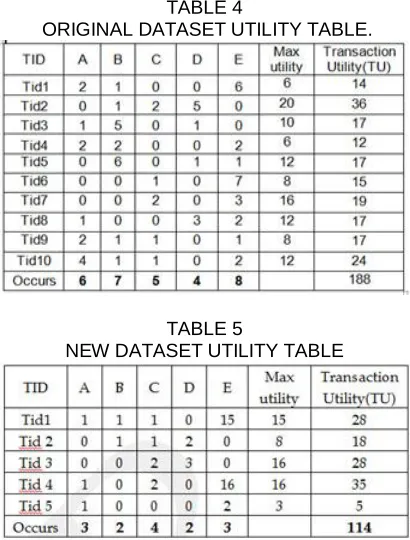
TABLE 4
ORIGINAL DATASET UTILITY TABLE.
TABLE 5
NEW DATASET UTILITY TABLE
Let's assume Table4 is the original dataset and Table 5 is the new dataset which contains some transaction to merge in the original dataset. Both dataset contains 5 elements from A to E. Tuples of the table represent the quantity of the elements. The minSup is 60% which is defined by the user. Total transactions are 10 and 5 in tables4 and table5 respectively. First, we have to find 'm1' and 'm2' by using the minSup as follows :
m1 = (60*10)/100 = 6; m2 = (60*5)/100 = 3;
So average minSup (m) = m1 + m2 = 6+3 = 9
COMPARISION OCCURRANCE OF ITEMS IN BOTH DATASET WITH MINSUP
The minSup (m1) for the Table4 is 6 and minSup (m2) for the table5 is 3. The average minSup for the merged dataset is 9. The above table is self-explanatory in which itemset {A}, {E} is highly interesting items in both datasets, these itemsets always remain highly interested as per the case1. Itemset {D} is low interested in both datasets, so it will always remain a less interested dataset as per the case4 of FUP[7]. Itemset 'B' is highly interested in the original dataset but low in the new dataset. The occurrence of an itemset in both datasets qualify the average minSup (m) and falls in case2 of FUP[7]. Itemset 'D' is low interested in the original dataset but high in the new dataset. The occurrence of itemset in both datasets qualify the average minSup (m) and falls in case 3 of FUP[7];
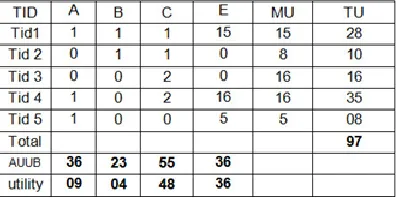
Now we remove all elements from both the original dataset and new dataset except itemset fall in case2 and case3. After eliminating the elements from both tables:
TABLE 6
ORIGINAL DATASET AFTER ELIMINATING THE ELEMENT
TABLE 7
NEW DATASET AFTER ELIMINATING THE ELEMENTS
MU : Maximum Utility TU : Total Utility
Table6 and table7 are updated original datasets and new datasets respectively. This dataset contains the items A, B, C and E those fall in case1, case2 and case3 of interested item. Max utility columns of the tables show the maximum utility of the transaction and TU columns show the transaction utility. The minimum utility threshold is 17.1 % which is defined by the user i.e 25.65 and 16.58 for both datasets respectively. The AUUB of 1-itemset {A}=45, {B}=70, {C}=60 and {E}= 71 and maintain the necessary information in HAUP-tree. The total utility of the original dataset is 150 and the new dataset is 97. The minimum high average utility for both dataset is ((150+97)*17.1% = 42.23).
TABLE 9
COMPARISON OF HIGHLY INTERESTED ITEMSET WITH AUUB
In the above table, both 1-itemset {A}, {B} and {C} are high average utility itemset and falls in case I. As the none of itemset exist in case -II and case III, we don't need to rescan the original dataset. After completion of all insertion tasks, HAUP-growth [] process takes place.
6. C
ONCLUSIONIn this paper, we can extract high average utility itemset from interesting items from two incremental datasets by using the FUP[7] concept which divides the dataset into four cases. In case 1, items always remain highly interested and case 4 items set remain low interested itemset. In case 2, the result depends on the information provided by the new dataset and in case 3, the result depends on the information provided by the original dataset. An additional rescan of the original dataset will be carried to in case 3. Items those are more interested are kept for further processing of high average utility test and items with less interest are eliminate from both dataset. Thus we can avoid generating unpromising itemset. Our proposed algorithm will consume fewer computer resources and take less computing time in comparison with traditional utility itemset.
REFERENCES:
[1] RakeshAgrawal and RamakrishnanSrikant Fast algorithms for mining association rules. Proceedings of the 20th International Conference on Very Large Data
Bases, VLDB, pages 487-499, Santiago, Chile, September 1994.
[2] J. Han, H. Pei, and Y. Yin. Mining Frequent Patterns without Candidate Generation. In: Proc. Conf. on the Management of Data (SIGMOD’00, Dallas, TX). ACM Press, New York, NY, USA 2000.
[3] ManjeetKaur, UrvashiGarg"ECLAT Algorithm for Frequent Itemsets Generation"International Journal of Computer Systems (ISSN: 2394-1065), Volume 01– Issue 03, December, 2014.
[4] Chan, R. Yang, Q. , Shen, Y.D. Mining high utility itemsets. In the Third IEEE international conference on Data Mining , pp. 19-26 (2003)
[5] M Liu, J Qu, Mining high utility itemsets without candidate generation. In: international conference on information and knowledge management 2012.
[6] Nafis , M. T., Biswas, R. (N,α)-means Algorithm for Clustering Big Data. International Journal of Engineering & Technology, v. 7, n. 2.27, p. 50-55,(2018).
[7] Chueng D, Han, J., Wong, C., 1996. Maintenance of discovered association rules in large databases: an Incremental updating approach. In: IEEE International Conference on Data Engineering, pp. 106-114.
[8] Lan, G.C HOng , T.P., Tseng, V.s., 2012. Efficiently mining high average utility itemsets with an improved upper bound strartegy . In: International journal of information technology and decision making vol. 11(5), 1009-1103.
[9] Yao, H.Hamilton and Butz, C.J.A foundation approach to Mining Itemset Utilities from Databse. Proc. of the 4th SIAM International Conference on Data Mining, Florida, USA, 2004.
[10] Liu, Y., Liao, W.K., Choudhary, A., 2005b. A two-phase algorithm for fast discovery of high utility itemsets. Lecture Notes in Comput. Sci. 3518, 689–695.
[11] CW Lin, TP Hong, WH Lu . Efficiently Mining High Average Utility with a Tree Structure. ACIIDS 2010, Part I, LNAI 5990, pp. 131–139, 2010. Springer-Verlag Berlin Heidelberg 2010.
[12] T Lu, By Vo, T N Hien, TP Hong. A New method for mining High Average Utility Itemsets. CISIM 2014, LNCS 8838, pp. 33–42, 2014.