(ISSN: 2582-158X)
Vol. 01, Issue 05, pp.189-197, August, 2019 Available online at http://www.journalijrar.com
RESEARCH ARTICLE
A COMPARATIVE STUDY OF RELATIONAL AND SEMANTIC APPLICATION DEVELOPMENT
FOR MANAGING KNOWLEDGE IN THE ENGINEERING SECTOR
*Aliyu Musa Bade and Idi Mohammed
Department of Computer Science, Yobe State University Damaturu, Nigeria
ARTICLE INFO ABSTRACT
The use of semantic technology to represent the knowledge for car maintenance is the main purpose of this research. The comparison between Relational and Semantic models in terms of notations used and critically assigning their strength and weaknesses has been discussed. The different ontology development tools were also critically analyzed. Enterprise applications are mostly managed using Relational database management systems which lacks meaning associated with data sharing and database integration. Recently, companies are realising the importance of managing existing knowledge which will boast their intellectual capital. Therefore, through a semantic-based approach, knowledge can be enhanced and maintained. A five-phase methodology has been adopted for the purpose of this research project.
Key Words: Relational Modelling, Semantic Modelling, Ontology, Notations.
Copyright © 2019, Aliyu Musa Bade and Idi Mohammed. This is an open access article distributed under the Creative Commons Attribution License, which
permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
INTRODUCTION
Overview on relational model: In 1970, the relational model
was first proposed by E. F Codd (Cited in Ramez and Shamkant, 2007). A relational database can be viewed as the collection of data items which are organized as a set of formally described tables. Each of the tables contains set of information which relates to the other tables. From the tables data can be accessed or reconstructed in many different ways without reorganizing the database. It simply allows the user to autonomously use and edit tables in the database. A relational database management system is used extensively in enterprise applications and they host the majority of a company’s assets. However, the relational approach has its limitations, particularly with respect to lack of meaning associated with
data sharing, and database integration (Zang et al., 2014).
Relational database contains massive unstructured or unorganized data which causes difficulties for the user to retrieve and manage data. Unstructured data is simply information which is not understandable by the user. Therefore, unstructured data is meaningless to the user as far
as it remains unorganized (Yafooz et al., 2013).
An overview of the semantic model: In 2001, Tim Berners
introduces the concept of the Semantic web (SW), the semantic web is just an extension of the current web that retrieves important information from the web and involves an intelligent web in order to make enable human and computers to work in cooperation (Rana and Singh, 2014). The development of Semantic Database Model was a collaborative work between Michael Hammer from Massachusetts Institute of Technology and Dennis McLeod at the University of Southern California. Semantic Database Model was designed in order to solve the limitations of the Relational Database Model such as: lack of
*Corresponding author: Aliyu Musa Bade
Department of Computer Science, Yobe State University Damaturu, Nigeria.
meaning associated with data sharing, and database integration
(Yafooz et al., 2013). Some of the main features of the
Semantic Model are: entities, relationships between entities, integrity constraints and abstraction. Semantic web technology is been used by both companies and individuals, due to its capability of finding accurate information by representing the meaning of the words and their relations with ontology which really contributes towards the user’s satisfaction (Chang-Hoo
et al., 2013). There is no universal agreement on how to
develop a Semantic Web application but it’s possible to develop semantic applications with the help of the software reuse techniques. Therefore, a user trying to develop a Semantic Web application encounters a lot of obstacles such as: the current existing types of technologies, the functionalities, and the dependencies between the technologies
(Garcia-Castro et al., 2008). A semantic model can simply be
defined as a set of machine interpretable representations used to model an area of knowledge; it is considered to be another type of information model which helps to define the data and the relationships between their entities and also supports their modelling (Zhaoqiang and Jianchun, 2012). Semantic model is also another type of a knowledge modelling which basically describe the meaning of a data and also where exactly the data is to be fixed. It allows the extraction and understanding of useful knowledge and also how all the pieces of information relate to one another. The components in the semantic modelling, concepts and relationships are the basic topic or idea which the user is concerned and focused with. All these concepts and their relationships are considered to be an ontology which is concerned with a detailed description of knowledge. The Semantic model currently is considered as the
global conceptual model (Xiaoming et al., 2007). The main
aim of this research is to explore a semantic application prototype to represent the knowledge of car maintenance. The particular car selected for the purpose of this project is the Ford Focus (Diesel) 2005-2009 (54 to 09 registration). The most famous instruction manual in the world ‘Haynes Owners
Article History:
Received 19th May 2019,
Received in revised form 12th June 2019,
Accepted 20th July 2019,
Workshop manual’ is used as the case study (Haynes, 2009). There are many problems which were addressed in the manual; such as: Flat battery, Coolant level, Engine oil level, Starter problem, wheel changing among others. The problem of wheel changing is the main focus in this research; issues are discussed such as the causes of the problem and also the actions to be taken when these problems happened. In order to achieve all of these, some of the existing ontology development tools were critically analysed and one among them is selected to carry out the exercise. The Protégé software was selected and this is because it is free and open source software. Therefore, it allows developers to define special-purpose facets of base classes that are “instances” of the metaclasses, Knowledge-visualization systems and also the PAL which allows developers to specify
complex semantic constraints using logic (Garcia-Penalvo et
al., 2012)
Literature Review
Relational modeling: Yonggang et al. (2012) explored a
method of the Semantic data to be stored into a relational database. Relation is the key aspect of semantic data and also a major key problem in terms of semantic data storage. Resource Description Framework (RDF) is used as the standard model for the semantic data storage method in the following stages: Externer Speicher (magnetic disk), Interior Memory (main memory) and at the Relational Database. The Relational Database is capable of storing the RDF data which uses the ideology of meta-modelling the semantic data object, it’s efficiency of storage, index and data modification mechanism, data consistency ability etc. The breath first search algorithm which is based on a vertical-storage algorithm can traversal horizontally layer- by-layer, is suitable for the complete search and for the RDF graph traverse and storage. Shufeng (2012) did a further work which uses RDF as the language for mapping the relational database. They presented an approach which can map relational database for semantic web without transforming the content of the database into RDF triples and, to answer queries through a mediated ontology.
Yafooz et al. (2013) investigated on the methods and purpose
in managing unstructured data in a relational database. Unstructured or unorganized data have no any meaning to the user which can affect the performance of processing query and other analysis. Three different methods were presented by the authors on how to manage unstructured data in a relational database: 1) by creating a database schema, 2) by developing a new data model, and 3) by Query-based approach. Keyword search using a Structured Query Language (SQL) is another simple method which serves as a mediator and also used in searching over both structured and unstructured data in a relational database to obtain useful information. NoSQL is a new generation of database which is designed to be implemented in a distributed environment to solve the problems encountered by the Relational Database Management System (RDBMS). Even after the implementation of the NoSQL, it cannot still substitute the use of Relational Database Management System (RDBMS) as it lacks the Atomicity, Consistency, Isolation and Durability (ACID) properties of a database.
Zhou and Xing (2013) presented an ROSM: RDB-based Ontology Storage Model focusing on the basis of the existing ontology storing model and the OWL ontology language characteristics of storing Ontology in relational database. Most
of the past researches done regarding this problem yields an incomplete description of the ontology and can only support RDF storage. Among the current existing ontology storage systems are: 1) Memory-based storage method, 2) File system-based storage method, 3) Native storage method, and 4) Relational database-based storage method which is feasible and more matured technology. The design of the ontology storage model based on relational databases is the combination of both vertical and mixed decomposition storage model which focuses on; analysing the ontology structure and designing ideas of the ontology storage model (Resource, Triple, RDFS, Attributes, Property restrictions, Mapping relation and Complex classes).
Semantic modeling: In the modern enterprise, the knowledge
about the product development and its reuse constitutes the most valuable assets. Every designer virtually has a way of
defining terms to represent a product design. Wei et al. (2008)
represented an ontology-based knowledge management system (KMS) which provides a user with a product knowledge model (PKM). It helps them to locate proper information, and supports the reuse of product data among different applications system throughout the product life cycle, by utilizing ontology to add semantics to the product development information for semantic searching. The information resource ontology (IRO), management activity ontology (MAO), product semantic ontology (PSO), organization competence ontology (OCO) were used in order to achieve semantic match search for knowledge research, also enhancing the performance of organization capability and knowledge sharing. Furthermore, (Zhonghai, 2010) went further and enhanced the generic knowledge management in digital design process and it reuse. In the digital design of mechanical products, there are basically two problems which are: 1) Structure design: the user reviews the current structure and come up with a new solution and, 2) Parametric design: has a fixed structure of the design objects and the user just need to change some variables. Knowledge reuse is very important and it can only be achieved if the domain knowledge towards the application is very well organised. There are a lot of information’s on the Web nowadays, but the main problem is how to find meaningful information and to interpret them. Rana and Singh (2014) addressed the issue of semantic heterogeneity issues and proposed a knowledge-based grid for retrieving valuable information according to the user’s necessities. Uncertainty and redundancy are the two major key problems in semantic heterogeneity. Ontology matching techniques was used in order to find the correspondence between semantically related entities of ontologies and determines the set of synonym concepts which are parallel in meaning but have different names and structures. Furthermore, (Gracia and Mena, 2012) discussed this issues of semantic heterogeneity on the web basically (ambiguity and redundancy) by developing a set of techniques in addition to the one discussed earlier. These techniques are: 1) Sense clustering: to reduce the amount of redundancy on the web, and 2) Sense disambiguation: to handle the problem of ambiguity. Accurate searching services tend to be a major problem associated with the types and number of information to be acquired and analysed. These problems can be solved using more accurate searching services such as vertical or semantic search for specified domains.
Chang-Hoo et al. (2013) proposed a system which will
conversion. The authors developed an OntoURI system which is capable of registering and managing ontologies, editing the DBMS-ontology mapping rule, registering and editing authority data and editing the entity identification rule, and identifying entities. PLOT (Person, Location, Organization and Terminology) is one of the major ways to analyse unstructured text and to use them for the purpose of generating semantic triples. Reverse engineering is another method suggested by (Hainaut, 2009) in order to convert DBMS to ontology. Reserve engineering is used in mostly huge and complex data’s in as much as they are unstructured or unorganized. It helps in restructuring missing technical and/or semantic schemas of a database. Many web applications today uses JSON (JavaScript Object Notation) as a lightweight data-interchange format even though it lacks semantic descriptions. Therefore, JSON is used in NoSQL because of its flexibility and to meet the large amount of unstructured or semi-structured web data storage and processing requirement
(Severance, 2012). Yao et al. (2014) proposed an automatic
semantic extraction and modelling method for schemaless JSON data, which takes advantage of semantic web technology to enrich semantic in web data. The automatic semantic extraction method focuses on; a) Semantic Extraction Framework, b) Semantic Extraction Processes, c) Keys in semantic extraction (Ontology Construction which aims at extracting data structure hierarchies and data properties, Instance Creation, and Multi-ontology Merging which integrate the annotates concepts and attributes that have semantic association between different ontologies to form a unified ontology model).
Shoaib et al. (2009) addressed the issue of searching and
retrieval of information in the Holy Quran. The Holy Quran discusses about all the aspect of life and has a unique way of addressing different topic areas. It is considered as an ocean of information and collection of diverse knowledge and different subject matters. A semantic search in the Holy Quran simply means that on querying the Quranic text by putting a query word or a synonym of it, all the verses that are relevant to a specific topic should be retrieved. The semantic search in the Quran bases on two steps; 1) Word sense disambiguation (WSD), and 2) Synonymy, which means to perform search against each and every synonym of the sense identified in the first step. Though a lot of work has been done related to this issue, but still the Quranic fundamental text authenticity has not been addressed yet. Therefore, (Alshareef and Saddik, 2012) considering the population of Muslims and how the Quran is used in their daily activities and decision making went further and proposed an algorithm which considers special Quranic symbols and also consider the regular expression patterns to overcome the problems of suffix and prefix. The model of the Quranic authentication focuses on two different stages: The Quranic Quote Filtering Algorithm and the Verification Mechanism.
Garcia-Castro et al. (2008) presented the Semantic Web
framework based on the structure on how the Semantic Web application can be organized and developed. A Semantic Web can be considered as an extension of the current web but providing information which is more meaningful and also understandable by humans and computers in order to work in cooperation. The Semantic Web architecture is structured in hierarchical layers (ontology, middleware and application) even though it has several disadvantages such as difficulties in structuring and finding the right level of obstruction. The
framework is based on the design principles (Developer-oriented, Easy to understand, Inexpensive to adopt, Semantics focused, Component based and Evolving). Association Rule Mining is the automatic extraction of useful information from a large transaction. This technique happens to be the most challenging data mining techniques since it is focusing on the representation of data. Researches has been carried out on how to combine semantic web and data mining looking at the two
ontology languages OWL and RDFS. Heydari et al. (2014)
proposed a novel method using the semantic web technologies that will find semantic association rules from semantic web data, enabling the processing of massive volume of semantic data, perform association rule discovery, store the new semantic techniques using the semantic richness and also apply the technologies in all the phases of the data mining. The authors used techniques such as; Linking Open Data (LOD), FUM-LD and Apriori Algorithm to evaluate the semantic association rule mining model. The semantic annotated data are transformed into semantic transaction using semantic query language SPARQL in order not to lose the semantic richness of the semantic web data.
Notations used in Relational Model
E-R Approach: This was used to document pre-relational
database designs in the 1960s; it is widely used in practice and is similar to the Bachman diagrams. This approach has its limitations as it does not support the direct implementation of a relational DBMS (Graeme and Graham, 2005).
Chen E-R Approach: This was proposed by Peter Chen in the
year 1976, the idea was to develop a conceptual modelling language that could be used to specify either a relational or a network database. The language is not commonly used by industries but rather in academic work. The Chen E-R approach uses a symbol of a diamond for relationships such as: one-to-one, one-to- many or many-to-many. More than two entity classes’ relationships can be represented using the Chen convention, considering the role which an entity instances may play, the Chen convention allows a name to be given to that role (Graeme and Graham, 2005). Chen also introduces the two concepts of weak and regular entities (classes). A regular entity is a stand-alone key while a weak entity is that which relies on another entity for its identification. Therefore, different diagrams are used in representing the two entities in order to distinguish them. Some of the basic problems with the Chen approach is that:
1. Too many objects are put on a page,
2. People who verify and contributes to the model needs to
see the final database design and,
3. The diamond convention is not supported by most of the
documentation tools (Graeme and Graham, 2005).
Notations used in Semantic Model: There are so many
different notations used in Semantic modelling. Though, some of the notations such as Unified Modelling Language (UML) and Object Role Modelling (ORM) can be used to model both Relational and Semantic. Below are some of the notations that are mostly used in the Semantic model.
Unified Modelling Language (UML): This is a very useful
are representing tables and columns with at least one UML case tool from an E-R CASE tool. The business requirement of a system compared to the physical system to be build is given less attention in the UML class models. A simple UML class diagram is constitute of boxes and each box is representing object class, an association is represented by the line between two boxes which are of different types considering the symbols that are at the end of the line. A relationship is represented by a line which has an open arrowhead symbols or with no arrow heads on itself. Symbols such as: 0..1 (optional “1” end), 1…1 or 1 (mandatory “1” end), 0…*or* (optional “many” end), and 1…* (mandatory “many” end) are placed near to the end of a line in order to represent the optionality of a relationship. By placing a numeral value giving a range like (2…5) at the end of the relationship line, this simply means that the relationship line must be associated with at least or more instances but should not be more than five (Graeme and Graham, 2005). The boxes used in UML can be divided by the use of horizontal lines into compartments. When the box is divided into two-compartment, the object class attributes are listed in the lower compartment of a two-compartment box or at the middle compartment box of a three-compartment box while the object class methods or operations are listed at the lowest compartment of a three-compartment box. UML has many notational facilities which distinguished it from the standard E-R modelling, among these features are: (derived attributes and relationships, association classes, n-ary relationships and on- diagram constraint
documentation) for business information requirement
modelling. Even with all these functionalities, the major drawback of the UML is its notation for relationship cardinality (Graeme and Graham, 2005).
Object Role Modelling (ORM):This is a well-known approach
which is widely used in practice and provides a rich constraint language. The use of the approach is considered to be highly increasing looking at how tools such as: Microsoft Visio for Enterprise Architects supports the use of Object Role Modelling (ORM) diagramming and the generation of business sentences and a relational logical data model from the Object Role Modelling (ORM) model. In the Object Role Modelling (ORM) model, relationships between two or more object classes are represented by a multi-compartment box which also allows the same way modelling of an entity class and the relationships in which it participated (Graeme and Graham, 2005). The major limitation of this approach is that when we consider the E-R and Unified Modelling Language (UML) as a means of capturing business information requirement in representing a model, the Object Role Modelling (ORM) has more additional shapes which can be tedious for the business stakeholders. Also, in terms of the learning process, the ORM takes a longer time in order to learn as it is a little bit complicated (Graeme and Graham, 2005).
JavaScript Object Notation (JSON): This stands for
JavaScript Object Notation, it is a lightweight data-interchange format, format friendly, easy to read and write even though it lacks semantic descriptions (Severance, 2012). Even though the JavaScript Object Notation (JSON) uses habits of the C family (C, C++, C#, Perl, Python, etc...), it is still using a text format which is completely independent from the programming
language (Boci et al., 2012). In terms of describing data object,
JavaScript Object Notation (JSON) uses array and objects. Array is the ordered set of values which starts from “[” and end with “]”, also, “,” is used to separate the values in the array. An object in JSON is similar to an object in Java, it starts with “{”
and ends with “}”. Every name is followed by a “,” and every
name/value pair is separated by “,” (Boci et al., 2012).
eXtensible Markup Language (XML): This stands for
Extensible Markup Language, it started and was proposed to the W3C in 1995 after which it was recognized as a W3C standards (XML 1.0) in February 1998. Extensible Markup Language (XML) was derived from Standard Generalized Markup Language (SGML) and its very simple and flexible which made it accepted in today’s industry standard. XML organized data as a structure of a tree and it uses attributes to
describe data (Boci et al., 2012).
Document Flow Model (DFM): This simply stands for
Document Flow Model which is a message-based workflow notation; it is simply used in order to specify systems of independent web services which are coordinated via asynchronous messages. Document Flow Model (DFM) uses a structure of a tree to specify documents; it uses one-way method for notification and also as its communication pattern. Document Flow Model consists of some unique identities, these different identities are the major constraints which are used in order to differentiate between the processes and sub-processes. In order words, the systems which are specified in the Document Flow Model supports concurrency, and as such, multiple operations are carried out at the same time. Whenever there is an incoming message, identities are automatically generated which are then used in outgoing messages as
parameters (Jingtao et al., 2005).
Strength and limitations of relational and semantic models
Tools for ontology development: There are many different
tools that can be used in the development of ontologies. These tools have different features in them and their evaluation is based on the different ontology editors. Therefore, the selection of a tool to be used in an ontology development depends on the ability of the ontology editor tool to develop certain ontology and also depends on the user’s ability to use the tool in the ontology development. Hence there is the need for critical evaluation on these tools in order to select the appropriate tool for the ontology development. Below are the brief explanations on the existing tools.
Protégé-2000: Protégé 2000 was developed by the Stanford
Medical Informatics (SMI) at the University of Stanford, it is a desktop based editing tool; it is not internet dependent and it
can be retrieved by anyone (Islam et al., 2010). It is considered
to be the widely used editing tool for ontologies
(Garcia-Penalvo et al., 2012). According to (Norta et al., 2010),
Protégé 2000 is an ontology editing tool which is free, open source and knowledge-based framework. It can export ontologies in various representation formats including RDF(S), OWL, and XML Schema and it allows the collaboration
development of ontologies. (Mukhtar et al., 2013) said,
Protégé 2000 supports a rich knowledge model and is a graphical tool for developing ontology. Protégé 2000 is considered to be an extensible tool by its Java-based
Programming Application interface (API) (Preventis et al.,
2012), its plug-in features such as: Flogic, Jess, OIL, XML and, Prolog which adds extra functionalities to the
environment for ontology language importation and
exportation. It also processes PAL which is used in the constraints creation and execution, and PROMPT for ontology
Protégé 2000 also permits ontology reasoners such as Pellet to
be attached with the tools (Islam, et al. 2010). It is an
extensible knowledge model and has the ability to customize: output files format, user interface and extensible architecture
which support integration with other applications (Noy et al.,
2001).
Ontolingua Server: This is considered to be the first ontology
tool that was created. It was developed at the Stanford University in the Knowledge Systems Laboratory (KSL) in
early 1990s (Oscar et al., 2003). It is a web-based tool for
making ontologies which allows multiple of users from different part of the world to interact with the server via a standard web browser and work together in building an
ontology (Duineveld et al., 2000) and It has the capability to
support a number of ontology languages such as DAML and
RDF(S) (Islam et al., 2010). Initially, ontology editor was the
only module that was inside the Ontolingua Server after which some additional modules such as: Webstar, equation solver, Open Knowledge Based Connectivity server (OKBC), Chimaera was added into the environment. It was designed with a form based web application in order to soften the development of Ontolingual ontologies and also language such as: Loom, Prolog, CORBA’s IDL, CLIPS, etc. can be translated
with the ontology editor (Oscar et al., 2003). The Ontolingua
Server basically has its main saver located at the university of Stanford were the ontology editor was developed and a mirror stationed located in Nijmegen is used in case of system failure. Creation of new ontologies, modifying the existing and also merging some part of the existing ontology to develop a new
one is also possible because of the Ontolingua server which provides a repository of ontologies. Reuse of ontology (ontologies which were developed and stored in the repository) is fully supported by the ontology editor with the
permission of the owner (Duineveld et al., 2000). Furthermore,
the ontology consists of two interfaces (the top frame which consists of icons and menus, and the bottom frame which is
used to input new data) and it’s very easy to use (Duineveld et
al., 2000).
Web Onto: It was developed by the Knowledge Media Institute
(KMI) at the Open University in 1997 to complement Tadzebao. Basically it was designed for Operational Conceptual Modelling Language (OCML) ontologies and secondly, it allows users to browse, develop and also edit the
ontologies collaboratively (Oscar et al., 2003). WebOnto is an
ontology editor which is a web-based tool, completely graphical in representation and fully accessible using Internet, added that WebOnto a fully graphically orientated tool which has the ability of distinctly saving diagrams of structure, viewing the relations, classes, rule and other more. WebOnto also support multiple of user to work together towards an ontology development by using drawing broadcast and the receive function; comment or any other changes (by the use of different colors) made by an individual can be viewed by the other users accessing the same ontology. Functions such as broadcast and receiving mode are also features of the ontology editor; when a user enables the broadcast mode and enters the editing mode, other users in the receiving mode can view any changes made but cannot have access to the ontology. This is so
Table 1. Strengths of Relational Model
Author(s) Strengths of Relational Model
Yonggang et al. (2012) 1. Strict data safety control 2. Data consistency control ability
3. Efficiency of storage, index and data modification mechanism
4. Multi user access mechanism; this simply means that multiple of user can access and use the database, tables, columns or rows at the same time depending on the privileges given.
Ramez & Shamkant (2007) 5. It is easy to understand and to use considering the structure of the data model and the access to the model.
6. Data’s are stored in different tables; an administrator can lock a certain table preventing others from making changes to that table only with approval; it’s highly secured.
7. Information that is stored in different tables can be formed together using some of the queries to extract information needed. This particular feature of the Relational Model made it more flexible.
Table 2. Limitations of Relational Model
Author(s) Limitations of Relational Model
Yafooz et al. (2013) 1. Contain massive unstructured or unorganized data which affects query processing performance and also causes difficulties to the user in retrieving and managing data.
2. A relational database model does not support Object-oriented programming languages which are used in large scale software systems.
3. Lacks meaning associated with data sharing, and database integration.
Table 3. Strengths of Semantic Model
Author(s) Strengths of Semantic Model
Wei et al. (2008) 1. By the explicit representation of the semantic buried in the ontology, Semantic Web provides a constant and integrated access to information sources and services as well as to the intelligent applications
Chang-Hoo et al. (2013) 2. Due to its capability of finding accurate information by representing the meaning of the words and their relations with ontology, it really contributes towards the user’s satisfaction
Garcia-Castro et al. (2008) 3. Well-defined meaning is given to information which enables the better cooperation between computers and human
Table 4. Limitations of Relational Model
Author(s) Limitations of Semantic Model
Rana & Singh (2014) 1. Semantic Heterogeneity: this problem is looking at two different aspects; Uncertainty and redundancy. Uncertainty comes as a result of disorientation, a single word having different meaning while redundancy comes as a result of duplicity of information
Chang-Hoo et al. (2013) 2. Representing and managing the semantic knowledge is not easy based on the current level of semantic web technology Garcia-Castro et al. (2008) 3. There is no any universal agreement on how to develop a Semantic Web application, therefore, users trying to develop a
because only a single user can get access to ontology at a time and when access is granted to that user, the ontology will be locked and other users can only browse through the ontology
(Duineveld et al., 2000).
Top Braid Composer: This was developed by Top Quadrant
(Islam et al., 2010). It is an enterprise-class modelling
environment for developing Semantic Web ontologies and also in building the semantic applications. This was developed based on the W3C standard. Configuration of knowledge model testing, managing, developing and their instances knowledge bases are fully supported by the TopBraid Composer. TopBraid Composer incorporates an application programming interface (API) for developing semantic server/client based solutions that can integrate applications and data resources
(Norta et al., 2010). There are basically three versions of the
TopBraid Composer: a Free Edition, Standard Edition and Maestro Edition. The operations in ontologies such as inference, consistency checking, and the inclusion of SPARQL query engine are also performed by the TopBraid Composer
(Garcia-Penalvo et al., 2012).
OILEd: This was developed by the Free University of
Amsterdam, University of Manchester and the Enterprise GmbH. At first, this was developed in the context of the European IST On- To-Knowledge as an ontology editor for OIL ontologies after which it advanced to DAML+OIL ontologies editor. The Fast Classification of Terminologies (FaCT) inference engine provides support to the user which automatically classifies the ontologies and checks the consistency. HTML and the graphical visualization are some
of the documentation options of the OILEdits (Oscar et al.,
2003).
OntoEdit: This is developed by AIFB in Karlsuruhe
University. Functionalities such as browsing and editing of ontologies can be performed based on its plugin architecture
(Oscar et al., 2003). OntoEdit is a multilingual ontology editor
which was developed by Ontoprise; it supports ontology activities for RDF(S) and DAML+OIL languages. OntoEdit
provides a defined methodology for ontology creation (Islam et
al., 2010). Flogic and XML are also language formats used by
the ontology editor for the purpose of importing and exporting. Basically, OntoEdit Free and OntoEdit Professionals are the
available versions of the OntoEdit (Oscar et al., 2003).
Cmap Tools: This is an ontology editor tool which is developed
at the Institute for Human and Machine Cognition (IHMC). Its uses the concept of map in representing the understanding of a person’s domain of knowledge which allows the users (individually/collaboratively) to express, share and publish their knowledge in concept of a map. Roundtrip translation for ontology development is also supported by the CmapTool and it support XML, RDF(S) for both importation and exportation
(Norta et al., 2010).
WebODE: WebODE is an ontology editor which replaced
ODE (Ontology Design Environment) (Oscar, et al. 2003). It
was developed by the Artificial Intelligent Lab at the University of Madrid (UPM). It is a web based tool and operate in server/client mode which provides a collaborative environment
for the multi-user for creating and editing ontology (Islam et
al., 2010). WebODE ontologies are stored in a relational
database and it uses (XML, RDF(S), OIL, DAML + OIL, CARIN, Flogic, Jess, Prolog), axioms edition with WebODE
Axiom Builder (WAB), ontology documentation, ontology evaluation and ontology merge as part of its languages/services
for importation/exportation of ontology (Oscar et al., 2003)
Altova Semantic Works: It is a commercial ontology editing
tool which supports OWL and RDF (Islam et al., 2010). It uses
a graphical design view to design RDF Schema and OWL ontologies, convert them into RDF/XML and N-Triples format and also export the ontologies in the RDF/XML and N-Triples
format (Garcia-Penalvo et al., 2012). Altova Semantic Works
has some visual features such as context sensitive help,
syntactive and semantic error checking (Islam et al., 2010).
Semantic works using a graph modeller checks the syntaxes and
semantic of the ontologies (Garcia-Penalvo et al., 2012).
HOZO: Ontology Manager, Ontology Editor, Onto-Studio and
Ontology server are the development environment for constructing ontologies. Using the Ontology Editor, a user can browse and modify ontologies which provide a graphical user interface. Ontologies from technical documents are designed using the Onto-studio, Ontology Manager helps the user in distributed ontology development and the build ontologies and
models are managed by the Ontology server (Norta et al., 2010).
Various languages and formats such as: hierarchical text, XML/DTD, DAML+OIL, RDF(S), and OWL) can be translated by the Hozo and by so doing, they become portable and reusable. Furthermore, by importing these ontologies and models, users can develop their own application.
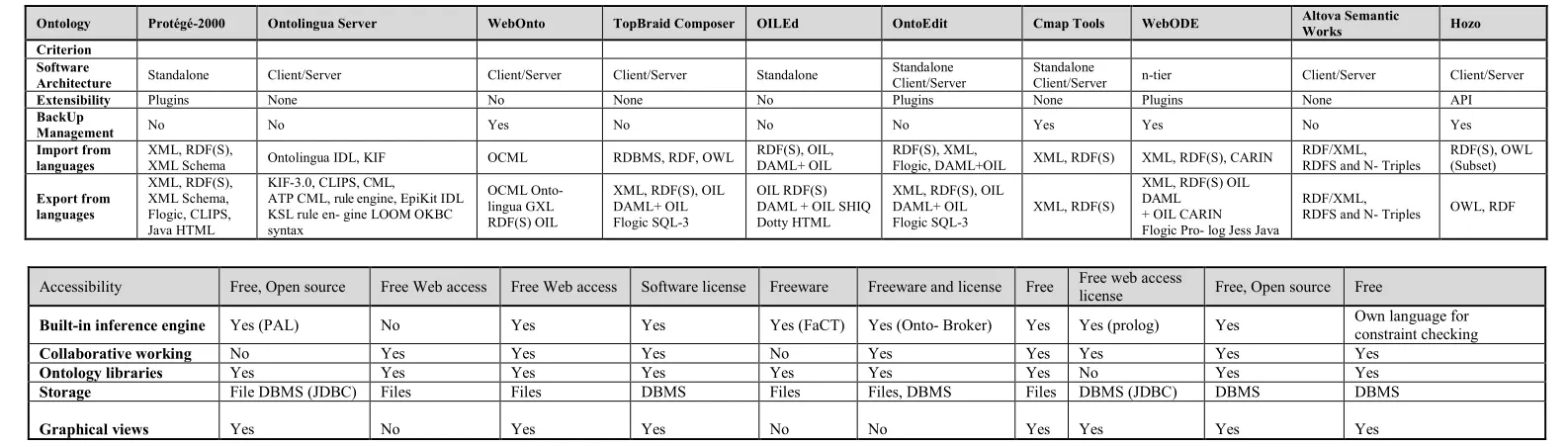
Table 2.5 below is showing a critical analysis on the ten (10)
ontology development tools discussed earlier. We can see from the table that there are some similarities and differences among the tools based on the software architecture (extensibility, storage of the ontology, failure tolerance, backup management, and stability). Protégé-2000 and OILEd are standalone, Ontolingua, WebOnto, Topbrid Composer, Altova Semantic Works and Hozo are Server/Client, Cmap Tools and OntoEdit are both Standalone and Server/Client while WebODE is n-tier.Considering the build-in inference engine, OILEd uses Fast Classification of Terminologies (FaCT) inference engine, OntoEdit performs inferences using OntoBroker, Prolog is used by WebODE while Operational Conceptual Modelling Language (OCML) is used by OntoWeb. OILEd which is based on Description Logic (DL) language is the only one which can perform automatic extraction. Ontolingua and OntoEdit are the only two which does not provide a graphical view. WebOnto is the only one that doesn’t have an ontology library while Protégé-2000 and OILEd are the only two that doesn’t support collaborative working.
and OIL RDF(S) DAML + OIL SHIQ Dotty HTML for exportation, TopBraid Composer support RDBMS, RDF, OWL for importation and XML, RDF(S), OIL DAML+ OIL, Flogic, SQL-3 for exportation, WebOnto support OCML for importation and OCML Onto- lingua GXL RDF(S) OIL for exportation, Ontolingua Server support Ontolingua IDL, KIF for importation and KIF-3.0, CLIPS, CML, ATP CML, rule engine, EpiKit IDL KSL rule engine LOOM OKBC syntax for exportation, and Protégé-2000 support XML, RDF(S), XML Schema for importation and XML, RDF(S), XML Schema, Flogic, CLIPS, Java HTML for exportation.
RESULTS AND ANALYSIS
Class hierarchy: Due to the massive number of the sub-classes under some of the parent
classes and the space limitation, the design showing the hierarchical view are divided into two (2) for easy understanding. The first design is that of the class car containing all of its subclasses while the second design is for the three (3) other different classes which are grouped: Car_problem, Cause_Of_Problem and then Solutions_To_Problem with all their subclasses.
Class Car:Figure 3.1 is showing the representation of the class ‘car’ alongside with all of it
subclasses in the hierarchy view. The class car is the parent class which have some child classes.
Ford is a child class which is under the class car and it also consists of about sixteen (16) sub-classes. Focus is one of the sub-class under Ford which have some other sub-classes such as Edge, Studio, Titanium_Navigator_ECOnetic, Edge_ECOnetic_88g …etc. Under Studio, there are four (4) child-classes (Hatchback, Estate, Convertible and Saloon); Ford Focus_(Diesel)_2005-2009_(54_to_09_registration) is the final child-class which falls under the parent-class Hatchback.
Car_problem, Cause and Solutions Classes:Figure 4.2 is the second representation of the
three (3) other classes in the hierarchical view (Car_problem, Cause_Of_Problem and then Solutions_To_Problem). Each of the three (3) classes as a parent class have its own sub-classes (child class) beneath it. The addressed car problem and the cause of problem are highlighted in bold while the solution to problem is mainly a step by step processes to addressing the selected problem. The car problem have five (5) subclasses, the cause of problem is having four (4) and the solution to the problem consists of ten (10) subclasses.
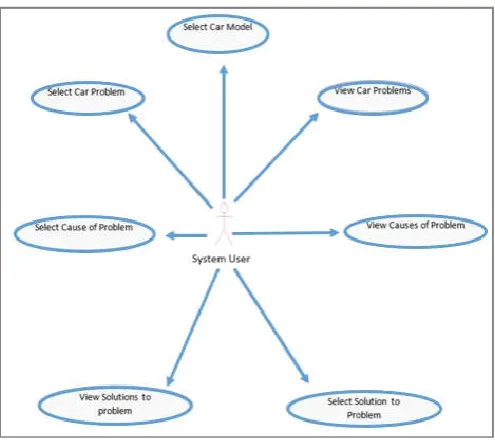
System Compatibility Requirements: Figure 3.3 shows how the system user can
communicate with the proposed system. The proposed system have seven different stages which the user can communicate with as mentioned above. The system user have the privilege to select a car model which on this case is Ford Focus (Diesel) 2005-2009 (54 to 09 registration), view car problems and select the addressed problem, select the cause of the problem and finally solutions to solve the problem.
Table 5. Comparison of Ontology Tools (Islam et al., 2010) and (Oscar et al., 2003)
Ontology Protégé-2000 Ontolingua Server WebOnto TopBraid Composer OILEd OntoEdit Cmap Tools WebODE Altova Semantic
Works Hozo
Criterion Software
Architecture Standalone Client/Server Client/Server Client/Server Standalone
Standalone Client/Server
Standalone
Client/Server n-tier Client/Server Client/Server
Extensibility Plugins None No None No Plugins None Plugins None API
BackUp
Management No No Yes No No No Yes Yes No Yes
Import from languages
XML, RDF(S),
XML Schema Ontolingua IDL, KIF OCML RDBMS, RDF, OWL
RDF(S), OIL, DAML+ OIL
RDF(S), XML,
Flogic, DAML+OIL XML, RDF(S) XML, RDF(S), CARIN
RDF/XML, RDFS and N- Triples
RDF(S), OWL (Subset)
Export from languages
XML, RDF(S), XML Schema, Flogic, CLIPS, Java HTML
KIF-3.0, CLIPS, CML,
ATP CML, rule engine, EpiKit IDL KSL rule en- gine LOOM OKBC syntax
OCML Onto- lingua GXL RDF(S) OIL
XML, RDF(S), OIL DAML+ OIL Flogic SQL-3
OIL RDF(S) DAML + OIL SHIQ Dotty HTML
XML, RDF(S), OIL DAML+ OIL Flogic SQL-3
XML, RDF(S)
XML, RDF(S) OIL DAML
+ OIL CARIN Flogic Pro- log Jess Java
RDF/XML,
RDFS and N- Triples OWL, RDF
Accessibility Free, Open source Free Web access Free Web access Software license Freeware Freeware and license Free Free web access license Free, Open source Free
Built-in inference engine Yes (PAL) No Yes Yes Yes (FaCT) Yes (Onto- Broker) Yes Yes (prolog) Yes Own language for
constraint checking
Collaborative working No Yes Yes Yes No Yes Yes Yes Yes Yes
Ontology libraries Yes Yes Yes Yes Yes Yes Yes No Yes Yes
Storage File DBMS (JDBC) Files Files DBMS Files Files, DBMS Files DBMS (JDBC) DBMS DBMS
Figure 1. Car Class hierarchy
Figure 3. System Compatibility Requirement
Conclusion
This research thoroughly discussed on two types of modelling; Semantic and Relational. It clearly compares and contrasts the two models in terms of the notations used, strength and weaknesses. Various notations were discussed such as: (UML, ORM, XML, DFM, and ERD). Notations such as UML and ORM can be used in both Semantic and Relational modelling. Different Ontology development tools were also discussed in details. Ten (10) different ontology development tools were
critically analysed (Protégé-2000, OILEd, Ontolingua,
WebOnto, Topbrid Composer, Altova Semantic Works, Cmap Tools, OntoEdit, WebODE and Hozo) and based on analysis, Protégé was selected and used for the ontology application development.
REFERENCES
Alshareef, A. and Saddik, A. 2012. A Quranic Quote Verification Algorithm for Verses Authentication. Abu Dhabi, IEEE Conference Publications, pp. 339 - 343, ISBN: 978-1- 4673-1100-7.
Boci, L., Yan, C., Xu, C. and Yingying, Y. 2012. Comparison between JSON and XML in Applications Based on AJAX. Nanjing, 1174 - 1177, ISBN: 978-1-4673-0721-5.
Car News, 2013. Run Flat Tires. [Online] Available at: http://www.car-addicts.com/ co- onsumer-reports/car-service/run-flat-tires [Accessed 27 June 2014].
Chang-Hoo, J. et al. 2013. Creating Semantic Data from Relational Database.
Alexandria, VA, IEEE Conference Publications, pp. 1081 - 1086. Duineveld, A. J. et al. 2000. WonderTools? A comparative study of
ontological engineering tools. International journal of Human-Computer Studies, 52(6), pp. 1111 - 1133, ISSN: 1071-5819. Garcia-Castro, R., Gomez-Perez, A. and Munoz-Garcia, O., 2008.
The Semantic Web Framework: a component-based framework for the development of Semantic Web applications. Turin, IEEE Conference Publications, pp. 185 - 189, ISSN: 1529-4188. García-Peñalvo, F. J., Ricardo, C.-P., Juan, G. and Roberto, T., 2012.
Towards an ontology modeling tool. A validation in software engineering scenarios. Expert Systems with Applications, 39(13), pp. 11468-11478, ISSN: 0957-4174.
Gracia, J. and Mena, E., 2012. Semantic Heterogeneity Issues on the web. IEEE INTERNET COMPUTING, 16(5), pp. 60 - 67, ISSN: 1089-7801.
Graeme, C. S. and Graham, C. W., 2005. Extensions and Alternatives. In: L. Homet and D. Corina, eds. Data Modeling Essentials. San Francisco: Morgan Kaufmann, pp. 207 - 227, ISBN: 0-12-644551-6.
Hainaut, J.L. 2009. Legacy and Future of Data Reverse Engineering. Lille, IEEE Conference Publications, pp. 4, ISSN: 1095-1350. Haynes, 2009. Ford Focus 2005 to 2009 (54 to 09 registration) Petrol
Owners Worksh-op Manual. Somerset: Haynes Owners Workshop Manual, ISBN: 978 1 84425 785 0.
Heydari, Y., Ashraf, S. and Kahani, M. 2014. A Novel Model for Mining Association Rules from Semantic Web Data. Bam, Iran, IEEE Conference Publications, pp. 1 - 4, ISBN: 978-1-4799-3350-1.
Ingham, J., 2013. Sunday Express. [Online] Available at: http://www.express.co.uk/ne- ws/uk/413713/AA-man-is-rescued-by-the-RAC [Accessed 27 June 2014].
Islam, N., Siddiqui, M. and Shaikh, Z. 2010. TODE : A Dot Net Based Tool for Ontology Development and Editing. Chengdu, IEEE Conference Publications, pp. V6-229 - V6- 233, ISBN: 978-1-4244-6347-3.
Jingtao, Y., Cirstea, C. and Henderson, P. 2005. An Operational Semantics for DFM, a Formal Notation for Modelling Asynchronous Web Services Coordination. s.l., IEEE Conference Publications, pp. 446 - 451, ISSN: 1550-6002.
Mukhtar, N., Shahzad, S., Khan, M. and Nazir, S. 2013. Ontology for Feature Based Selection of Web Development Tools. Islamabad, IEEE Conference Publications, pp. 90- 95, ISBN: 978-1-4799-0613-0.
Norta, A., Yangarber, R. and Carlson, L. 2010. Utility Evaluation of Tools for Collaborative Development and Maintenance of Ontologies. Vitoria, IEEE Conference Publications, pp. 207 - 214, ISBN: 978-1-4244-7965-8.
Noy, N. et al., 2001. Creating Semantic Web Contents with Protégé-2000. IEEE Intelligent Systems, 16(2), pp. 60 - 71, ISSN: 1541-1672.
Oscar, C., Mariano, F.L. and Asuncion, G.P. 2003. Methodologies, tools and languages for building ontologies. Where is their meeting point?. Data and Knowledge Engineering, 46(1), pp. 41 - 64, ISSN: 0169-023.
Preventis, A., Marki, P., Petrakis, E. and Batsakis, S. 2012. CHRONOS: A Tool for Handling Temporal Ontologies in Protégé. Athens, IEEE Conference Publications, pp. 460 - 467, ISBN: 978-1-4799-0227-9.
Ramez, E. and Shamkant, B. N. 2007. The Relational Data Model and Relational Database Constraint. In: G. Matt, H. Katherine and M. Patty, eds. Fundamentals of Database Systems. United States of America: Greg Tobin, pp. 141 - 166, ISBN: 0-321-41506-X. Rana, V. and Singh, G. 2014. An Analysis of Semantic
Heterogeneous issues and their Countermeasures prevailing in Semantic Web. Faridabad, Haryana, India, IEEE Conference Publications, pp. 80 - 85, ISBN: 978-1-4799-3958-9.
Severance, C. 2012. Discovery JavaScript Object Notation. IEEE Computer Society,
45(4), pp. 6 - 8, ISSN: 0018-9162.
Shoaib, M. et al. 2009. Relational WordNet Model for Semantic Search in Holy Quran. Islamabad, IEEE Conference Publications, pp. 29 - 34, ISBN: 978-1-4244-5631-4.
Shufeng, Z. 2009. Mapping Relational Database for Semantic Web. Sanya, IEEE Conference Publications, pp. 521 - 524, ISBN: 978-1-4244-4692-6.
Wei, S. et al. 2008. Application of Semantic Web Technologies for Ontology-based Knowledge Management in Product Development. Dalian, IEEE Conference Publications, pp. 1 - 4, ISBN: 978-1-4244-2108-4.
Yafooz, W., Abidin, S., Omar, N. and Idrus, Z. 2013. Managing Unstructured Data in Relational Databases. Kuala Lumpur, IEEE Conference Publications, pp. 198 - 203, ISBN: 978-1-4799-2208-6.