The Neural Computation of Trust and Reputation
137
0
0
Full text
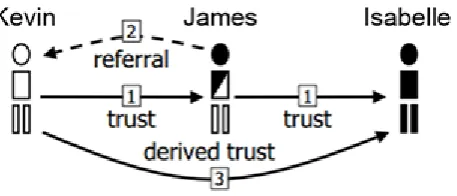
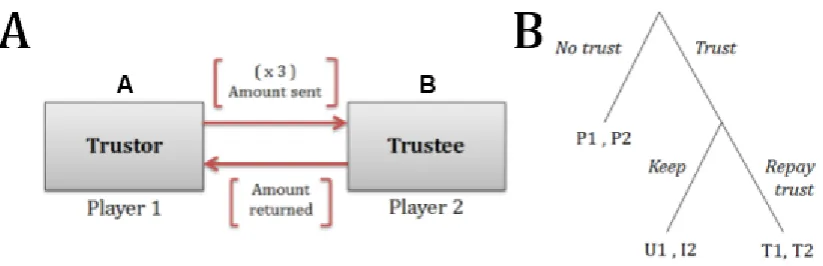
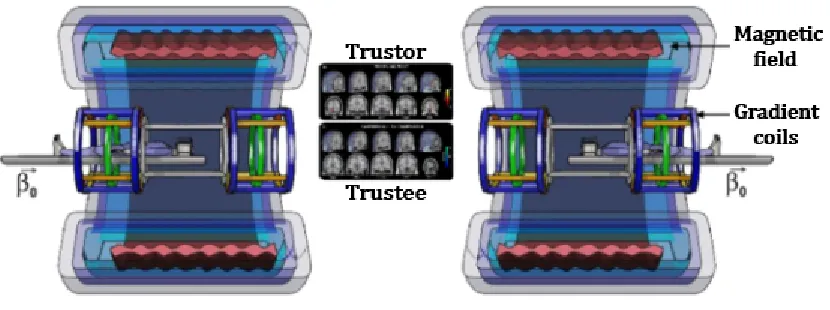
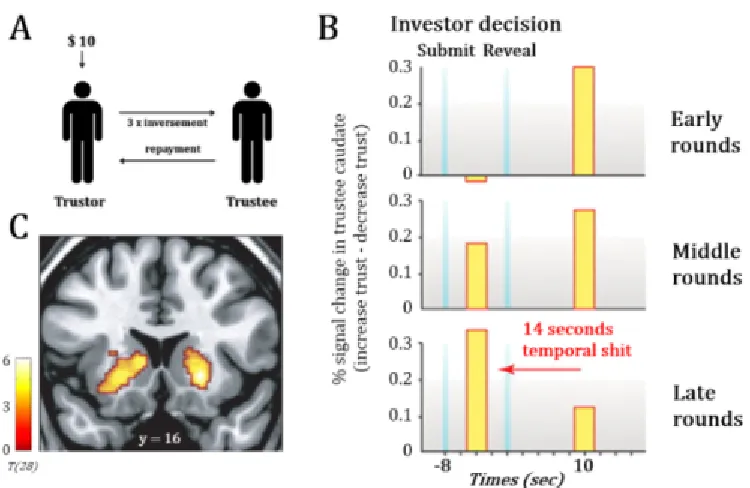
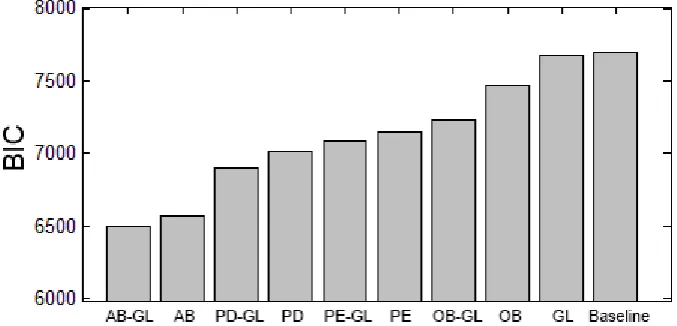
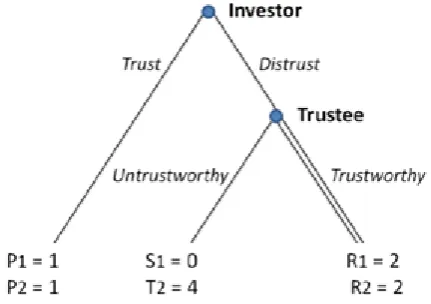
Figure
+7
Related documents