Analysis of Big Data Processing Using Data Mining
Full text
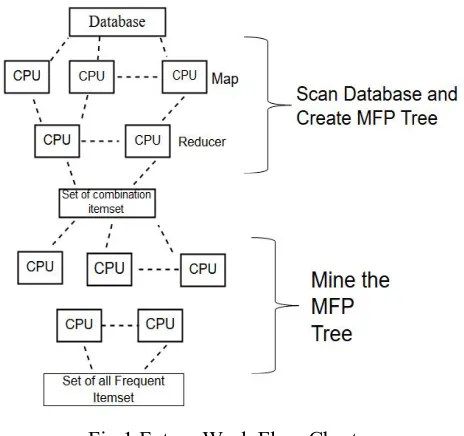
Figure
Related documents
Khenchouche et al Virology Journal 2013, 10 340 http //www virologyj com/content/10/1/340 RESEARCH Open Access Human Papillomavirus and Epstein Barr virus co infection in Cervical
Hindawi Publishing Corporation EURASIP Journal on Wireless Communications and Networking Volume 2007, Article ID 35946, 14 pages doi 10 1155/2007/35946 Research Article A Markovian
Hindawi Publishing Corporation Advances in Difference Equations Volume 2009, Article ID 256165, 10 pages doi 10 1155/2009/256165 Research Article A Fixed Point Approach to the Stability of
The Oxford Ankle Foot Questionnaire for Children (OxAFQ-C) was completed at baseline, 1, 2, 6 and 12 month time points by both child and parent.. Results: A total of 133 children
TX 1~AT/TX 2~AT Vol 11, Issue 7, 2018 Online 2455 3891 Print 0974 2441 PUBLIC KNOWLEDGE AND ATTITUDE TOWARD DEPRESSION AND SCHIZOPHRENIA FINDINGS FROM QUANTITATIVE STUDY IN UAE
The predominance of the two-child family and the decline of larger families are similar to trends in other European countries, but it is noteworthy that the
This study demonstrates for the first time that intermittent running exercise designed to closely simulate team and games-play activity, carries a lower risk of early
tendencies of the rising capitalist order in his. presentation of Biprodas’s
