Deep Learning : A perspective on
Representation Learning
Dr. Noman Islam Associate Professor & HoD
Introduction
• It is our motive to develop machines that could think
• We look to intelligent software to automate routine labor,
understand speech or images, make diagnoses in medicine and support basic scientific research.
• Computer can easily solve problems that can be
described by a list of formal, mathematical rules
• What about problems that we solve intuitively, that feel
Deep Learning
• This solution is to allow computers to learn from
experience and understand the world in terms of a hierarchy of concepts, with each concept defined in terms of its relation to simpler concepts
• If we draw a graph showing how these concepts are
built on top of each other, the graph is deep, with many layers.
• For this reason, we call this approach to AI deep
Multiple layers of deep learning models
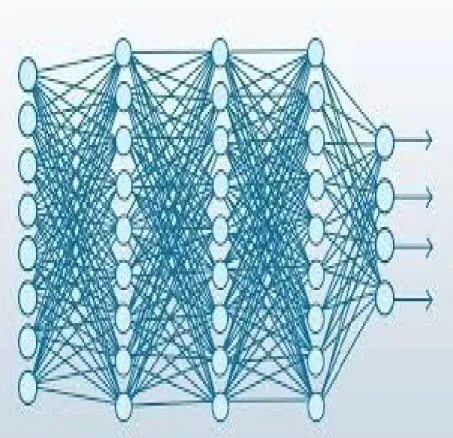
Feed forward neural network
• Input layer is interfaced with features/ data
• Output layers are used to present the results of deep learning models to outer world
• There can be multiple hidden layers with each layer learning increasing complex representation gradually
• Fully connected layers are normally used for classification
Features
• The performance of these simple machine learning
algorithms depends heavily on the representation of the data they are given
• Each piece of information included in the representation of the patient is known as a feature
Selection of right features is very important
• Many artificial intelligence tasks can be solved by
designing the right set of features to extract for that task, then providing these features to a simple machine learning algorithm.
• For example, a useful feature for speaker
identification from sound is an estimate of the size of speaker’s vocal tract.
• It therefore gives a strong clue as to whether the
Representation learning
• One solution to this problem is to use machine learning
to discover not only the mapping from representation to output but also the representation itself.
• This approach is known as representation learning
• Learned representations often result in much better
performance than can be obtained with hand-designed representations.
• They also allow AI systems to rapidly adapt to new
Representation learning – cont…
• Representation learning also called feature learning
is the subdiscipline of the machine learning space that deals with extracting features or understanding the representation of a dataset
Factors of variation
• A major source of di culty in many real-world artificial ffi
intelligence applications is that many of the factors of variation influence every single piece of data we are able to observe
• When analyzing a speech recording, the factors of
• When analyzing an image of a car, the factors of variation include the position of the car, its color, and the angle and brightness of the sun.
• Deep learning solves this central problem in
representation learning by introducing representations that are expressed in terms of other, simpler representations.
Deep Learning: learning concepts based on simple concepts
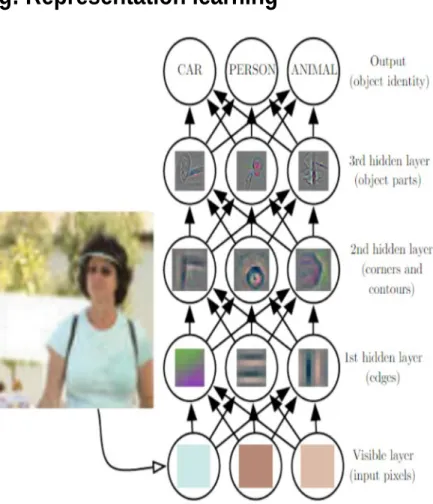
Representation learning in Deep learning
• Each layer learning increasingly abstract representation
• First layer learns edges, second layer corners, 3rd layer
object parts and final layer learns the complete object identity
Autoencoders
• A good example of a representation learning algorithm is the autoencoders
• Autoencoders are a specific type of feedforward neural networks where the input is the same as the output
• They compress the input into a lower-dimensional code and then reconstruct the output from this representation
Components of autoencoder
• An autoencoder consists of 3 components: encoder,
code and decoder.
Properties of autoencoders
• Autoencoders are mainly a dimensionality reduction
(or compression) algorithm
• The output of the autoencoder will not be exactly the same as the input, it will be a close but degraded representation
Explanation
• First the input passes through the encoder, which is a
fully-connected ANN, to produce the code.
• The decoder, which has the similar ANN structure, then produces
the output only using the code.
• The goal is to get an output identical with the input.
• Note that the decoder architecture is the mirror image of the
encoder.
• This is not a requirement but it’s typically the case.
• The only requirement is the dimensionality of the input and output
Convolutional Neural Networks
• Convolutional Neural Networks (ConvNets or
CNNs) are a category of Neural Networks that have proven very effective in areas such as image recognition and classification.
• ConvNet architectures make the explicit assumption that the inputs are images, which allows us to encode certain properties into the architecture.
• A simple ConvNet is a sequence of layers, and
every layer of a ConvNet transforms one volume of activations to another through a differentiable function.
Why ConvNets?
1. Makes the input representations (feature dimension) smaller and more manageable
3. Makes the network invariant to small transformations, distortions and translations in the input image (a small distortion in input will not change the output of Pooling - since we take the maximum / average value in a local neighborhood).
Summary
• In this presentation, an overview of representation
learning is presented
• Two case studies based on autoencoders and convolutional neural networks have been discussed where representation learning is used
• For instance,
– LSTM models are used for extracting features from sequential data