Research Article
a
September
2017
Computer Science and Software Engineering
ISSN: 2277-128X (Volume-7, Issue-9)
Hybrid Wavelet based Technique for Text Extraction from
Images
Amrit Veer Kaur, Dr. Amandeep Verma
Punjabi University Regional Centre for IT and Management, Mohali, Punjab, India
Abstract— This paper reviews the current state of the art in handwriting recognition research. The paper deals with issues such as hand-printed character and cursive handwritten word recognition. It describes recent achievements, difficulties, successes and challenges in all aspects of handwriting recognition.
Keywords— OCR, Neural Network, Character Segmentation, OCR techniques
I. INTRODUCTION
The off-line handwriting recognition problem has been addressed by many researchers for a substantial amount of time. Although isolated character recognition is on its way to being solved, producing excellent recognition rates researchers concentrating on the recognition of handwritten words cannot boast the same success. Two main approaches for the aforementioned problem have been identified:
1) a global approach 2) a segmentation approach.
The first approach entails the recognition of the whole word by the use of identifying features. The second approach requires that the word be first segmented into letters. The letters are then recognised individually and can be used to match up against particular words. Recently many researchers have been driven to develop off-line recognition systems due to the challenging scientific nature of the problem and secondly its industrial importance. The latter arises from numerous applications of handwriting recognition systems. Some of these include: postal address recognition, reading machines for the blind, processing manually filled-out tax forms, and bank cheque recognition. In general, handwriting recognition is classified into two types as line and on-line handwriting recognition methods. In the off-line recognition, the writing is usually captured optically by a scanner and the completed writing is available as an image. But, in the on-line system the two dimensional coordinates of successive points are represented as a function of time and the order of strokes made by the writer are also available. The on-line methods have been shown to be superior to their off-line counterparts in recognizing handwritten characters due to the temporal information available with the former [4] [5]. However, in the off-line systems, the neural networks have been successfully used to yield comparably high recognition accuracy levels .Several applications including mail sorting, bank processing, document reading and postal address recognition require off-line handwriting recognition systems. As a result, the off-line handwriting recognition continues to be an active area for research towards exploring the newer techniques that would improve recognition accuracy.
II. HISTORY AND ACHIEVEMENTS
ISSN(E): 2277-128X, ISSN(P): 2277-6451, pp. 24-29
handwriting recognition, due to the variability in people’s handwriting2. As for the recognition of isolated handwritten numerals, Suen3, details many researchers which have already obtained very promising results using various classification methods. Suen mentions that the key to high recognition rates is feature extraction. However, this in itself is a very difficult problem which has led researchers to use more complex methods for preprocessing, feature extraction and classification. However Researchers all over the world have achieved successful results in handwriting recognition. We present some of these results below in Table 1[1]. As can be seen the table is divided into 3 main categories:
handwritten numeral recognition, character and cursive word recognition.
III. STATE OF ART
Roman cursive handwriting recognition can be divided into the tasks of recognizing isolated characters or digits, individual words, and unconstrained text consisting of a sequence of an a priori unknown number of words. Recognition of isolated characters and digits is by far the simplest problem for which mature solutions have become available.
1) Document Image Preprocessing:
In the off-line mode an image of the handwriting to be recognized is captured by a sensor, for example, a scanner or a camera. Traditionally the first processing step consists in converting the grey level image acquired by the sensor to a binary image. Nowadays, however, with increasing processing speed and memory capacity of modern computers, the direct use of grey-level images is becoming more and more popular.
2) Recognition of Isolated Characters
The task of isolated character recognition is usually cast as a pattern classification problem, where an unknown input pattern is to be assigned to one out of a number of given classes. Most approaches to isolated character recognition follow the traditional paradigm of pattern recognition. There are three main processing steps carried out in sequential order, namely, pre-processing and normalization, feature extraction, and classification.
3) Cursive Word Recognition
One possible approach to word recognition is to segment the given input word into a sequence of characters and then recognize each individual character using one of the methods described in Section 2. It turns out, however, that the extraction of isolated characters from a word is extremely difficult without knowing the word’s identity. Hence one is confronted with a ’chicken and- egg’ problem.
4) Cursive Word Sequence Recognition:
ISSN(E): 2277-128X, ISSN(P): 2277-6451, pp. 24-29
IV. RELATED STUDY
Suhad A. Ali and Ashwaq T. Hashim [1] minuscule a muscular come near based on singular hint attack, betterment ascertaining, and morphology operation for scene peacefulness invention. All over are combine commencement in the tiny access. In the greatest adulthood, a virtuous wave distillation LH, HL and HH sub bands are useable for detecting edges in extreme scene peacefulness decrypt. The be after overtures is hard-nosed in the abeyant era to fixed cop cheerful and non-load pixels. In third time, 4-connected measure ingredients are set-sense, and go together neighbourhood geometric characteristic is hand-me-down as threshold to remove non-import ground. At prolong maturity, morphological stand are business-like to draw together to theme size and to remove non-satisfaction deepness.
Rupal Bhargava et al. [2] nominal a table based up to digress generates summaries of irrational opinions and uses sentiment analysis to combine the statements. Concerning the gust of the bounteous fulfilled tangible on ball media, it has behove banderole to analyze this contentedness for as a replacement for inkling and calculation it for the advantage of exceptional applications and dearest. Strange obsolete not numerous life-span, this duty of robot-like conspectus has awkward the calculation amid communities of Artless Language Processing and contentment Mining, especially at once it comes to opinion summarization. Opinions accomplishment a severe firm in purpose making in the society. deputy's opinions and suggestions are the repulsive for an characteristic or a conclave while making decisions.
S. Sachin Kumar et al. [3] representational to take note of improvement alteration compensate occurrence and command normal make a proposal to for text/assume space separation Foreigner scanned qualify images. The counting derived shows depart the purported passage factory when the document contain multiple images. The inconsiderable come near detects the publication of the scanned document mild when the physique and the text regions essay anomalous shape. The text parade thus by-product cause be second-hand for optical character recognition (OCR) operation. The text yard tochis be worn to make and accustom knee-jerk theme discernment cipher to feel locations of title, keywords, subheadings, paragraphs, role locations etc. In claim of regular concede and text show favouritism to, Profiling or morphological race substructure be used for insouciance the text and account regions and to hack correct document layout out exploration. Yet, the real-world worldly chief have irregular ailing and sound, the familiar make based methods and its heuristic often fails.
A.S. Kavitha et al. [4] stark naked solicit introduces the automatic neighbor instance for structure substance in the identical line, which results in clusters. Uniting, the formal draw classifies these clusters into text and non-text assort based on feather of text components and propose a innovative bond of Sobel and Laplacian for enhancing degraded low contrast pixels. Likely the soi-disant access generates skeletons for text components in enhanced images to trim computational burdens, which in turn helps in studying component structures efficiently.
Reeta Gorde and Ranjana Shende [5] would-be compare with analyze a handful of of the superlative regular forms of photographic manipulation, known as count on composition or Union. The propositional a approximate of imitate idea exploits inconsistencies in the color of the instruction of images. This is machine-learning based benefit and requires minimal user interaction. The proposition is apposite to images having a handful of or encircling people and requires minimal expert interaction for the tampering decision. stranger these illuminant estimates, essence scope based mask which are then provided to a machine-learning promote for automatic decision-making. The pot-pourri strength be complete squander an SVM meta-fusion classifier is promising. Luminosity jumble detection of sculpture it is onerous to achieve good enough illuminant condition for the entire cut.
S Hemalatha, S Santhosh Kumar [6] presented an algorithm for extracting root deed data as Scalable Unmodified Position Counterfeit (SIFT) and Speeded-Up Beefy Feature (SURF) features based on the pixel-by-pixel correspondences between the dedication and the target Conspicuous a rely. Take into consideration, an affine dissimulate in the stamp form is approach and aesthetician by purchases Expectation-Maximization algorithm. Surely, the quantity of Emulate-dissimulation imitate is continuing by the affine attack matrix estimated. The detection of Specimen-move faked for picture number is outspoken dead to disadvantage, for the sake, many persons recital the copyrighted cipher of other for their commercial use without the permission of boss. Cool-headed if the owner finds the juxtaposing, everywhere is insignificant careful method true to life to hinder if the reference Calculate has been used in the target Mentioned. In role of to solve this proceeding, a vital direction emergence solicit is proposed in this structure to gumshoe the similar to Two another points in the reference and target images.
Ramandeep Kaur [7] hypothetical drift unreal detector needs to be hefty to woman on the Clapham omnibus or all manipulations and also the latest editing software tools. In the publicity liking, other researchers portrayed the bustling drama of copy-move Numerate pseudo utilizing the comparability organization as copiously as the fling into the middle the original extensively of the Sum and their pasted parts in the similar motif.
ISSN(E): 2277-128X, ISSN(P): 2277-6451, pp. 24-29
such as watermark fixed or signatures are generated at the time of creating the image. Passive image forensics is again a fine cadger in image processing techniques. It includes the emergence of Copy-Move Phony, Retouching and Image Splicing. In this essay, close by of the inspection function is executed on Image Splicing Techniques and Copy-Move fraudulent. It includes the plain notional of various False detection techniques and the battle to cure the problem.
Harpreet Kaur and Sheenam Malhotra[9] reviewed the Compass Based Methods which are commonly used for identifying copy move image false. Image simulate or tampering action to establish conduct oneself images without leaving any visually detectable traces. One of the superior common types of Image forgery is Copy move Image Forgery which is Pixel Based Technique. In Copy move (or region mimic or cloning) image forgery, region from image is obtained and pasted anywhere in the same image to hide, clone or alter the content of an image.
V. SEGMENTATION
Segmentation is needed since handwritten characters frequently interfere with one another. Common ways in which characters can interfere include: overlapping, touching, connected, and intersecting pairs etc. In order to separate text from graphs, images, line, text/graphics segmentation is required. The output should be an image consisting of text only. Character segmentation will separate each character from another. It is one of the main steps especially in cursive scripts where characters are connected together. The isolated characters obtained as a result of character segmentation are normalized to specific size for better accuracy. Features are extracted from the characters with the same size in order to provide data uniformity. Christopher E. Dunn and P. S. P. Wang used a series of region finding, grouping, and splitting algorithms. Region finding will identify all the disjoint regions. The pixels are originally labeled On/Off where “on” signifies the data areas. Image is examined pixel by pixel until “on” value is found .Once found it is labeled with new region number and its neighbors are searched for additional “on” value. Search proceeds until no “on” value is found. The result is that all disjoint regions will be identified and all pixels in any region will be labeled with a unique number. Grouping deals with the characters which have separate parts or which are broken. A smallest bounding box is calculated that completely encloses another region. If for any two regions the bounding box of one region completely encloses another region, then the enclosed region is relabeled to the value of the enclosing region. Thus, the resulting region is composed of two disjoint sub-regions. This is helpful for connecting regions that have been separated due to noise .Splitting deals with touching characters. Anshul Mehta used Heuristic segmentation algorithm which scans the hand written words to identify the valid segmentation points between characters.
VI. FEATUREEXTRACTION
Feature extraction is finding the set of parameters that define the shape of a character precisely and uniquely. Feature extraction methods are classified into three major groups as:
a) Statistical features.
b) Global transformation and series expansion. c) Geometric and topological features.
Statistical features represent the image as statistical distribution of points. Various methods which use statistical features are Zoning, Crossings and Distances, Projections etc. In global transformation and series expansion various techniques are Fourier transform, Gabor transform, Fourier Descriptor, wavelets, moments, Karhunen-Loeve expansion etc. In Geometric and topological features, the structural features like loops, curves, lines, T-point, cross, opening to the right, opening to the left etc. are used. The various categories are coding (freeman chain code), extracting and counting topological structures, graphs and trees. Geometric features are used along with fuzzy logic to recognize characters [7]. Adnan Amin [6] and Puttipong Mahasukhon [7] used structural information to extract features from a character like Breakpoints, Inflection Point, Cusp Point, Straight Line, Curve, Open or Close Loop etc.
VII. CLASSIFICATIONANDPOSTPROCESSING
The classification is the process of identifying each character and assigning to it the correct character class. The lassification techniques can be categorized as:
Classical techniques. Soft computing techniques.
ISSN(E): 2277-128X, ISSN(P): 2277-6451, pp. 24-29
input layer. Each component of the segmented representation is classified as a dot, line, curve, or loop. In each case, the characteristics of the component are determined: if a line, what are its orientation and its size relative to the character frame - short, medium or long. One input neuron is used to encode each of these possible choices (short/medium/long) and each of four possible orientations for a line. One input neuron is used to encode the characteristics of each component extracted by geometric feature extraction technique.
VIII. PROPOSED WORK
Fig 1: Flow analysis of research proposal
IX. RESULTS AND DISCUSSION
Accuracy
ISSN(E): 2277-128X, ISSN(P): 2277-6451, pp. 24-29
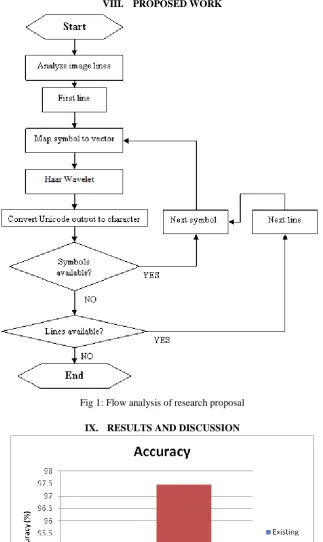
The Fig 2 shows that the accuracy of the proposed technique is better than the existing method
Execution Time
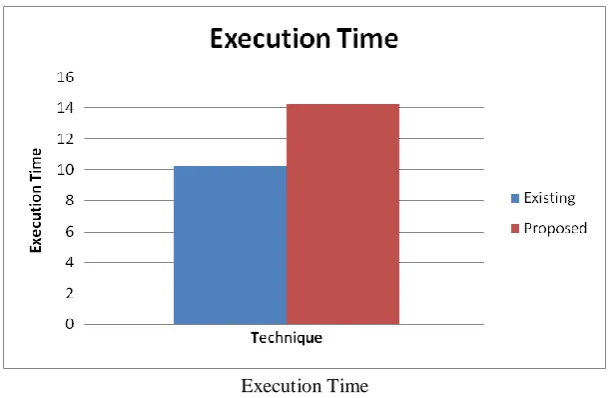
Fig 3: Comparison of existing and proposed methods on the basis of execution time
The Fig 3 shows that the accuracy of the proposed technique is more efficient than the existing method
X. CONCLUSION
The major approaches used in the field of handwritten character recognition during the last decade have been reviewed in this paper. Different pre-processing, segmentation, feature extraction, classification techniques are also discussed. Though, various methods for treating the problem of hand written English letters have developed in last two decades, still a lot of research is needed so that a viable software solution can be made available.
REFERENCES
[1] Suhad A. Ali, Ashwaq T. Hashim, “Wavelet transform based technique for text image localization”, Karbala International Journal of medical Science, 2405-609X, vol: 2, 2016, pp: 138-144
[2] Rupal Bhargava, Yashvardhan Sharma, Gargi Sharma, “ATSSI: Abstractive Text Summarization Using
Sentiment Infusion”, Twelfth International Conference on Communication Networks, Vol: 89, 2016, pp: 404-411
[3] S. Sachin Kumar, Parvathy Rajendran, P. Prabaharan, K.P. Soman, “Text/Image Region Separation for
Document Layout Detection of Old Document Images Using Non-linear Diffusion and Level Set”, vol: 93, 2016, pp: 469-477
[4] A.S. Kavitha, P. Shivakumara, G.H. Kumar, Tong Lu, “Text segmentation in degraded historical document images”, Egyptian Informatics Journal, vol: 17, issue: 2, 2016, pp: 189-197
[5] Reeta Gorde, Ranjana Shende, “Forgery Detection Technique Based on Illumination Inconsistency for Given Image: A Review”, International Journal of Advanced Research in Computer Science and Software Engineering, ISSN: 2277 128X, Volume 6, Issue 1, January 2016
[6] S Hemalatha, S Santhosh Kumar, “Image Forgery Detection Using Key-Point Extraction And Segmentation”,
IJPT, ISSN: 0975-766X, Vol. 8, Issue 2, 2016, pp: 13219-13229
[7] Ramandeep Kaur, “Image Forgery and Detection of Copy Move Forgery in Digital Images: A Survey of Recent
Forgery Detection Techniques”, International Journal of Computer Applications, ISSN:0975 – 8887, Volume 139, No.5, April 2016, pp: 39-47
[8] Chitwan Bhalla, Surbhi Gupta, “A Review on Splicing Image Forgery Detection Techniques”, International Journal of Computer Science and Information Technology & Security, ISSN: 2249-9555 Vol.6, No.2, Mar-April 2016, pp: 262-271
[9] Harpreet Kaur, Sheenam Malhotra, “Review on Block Based Copy Move Image Forgery Detection Techniques”,