Volume 2 Issue 4, April -2015
22
PRIVACY PRESERVATION IN HORIZONTALLY
DISTRIBUTED DATABASE USING LOGARITHMIC
AND EXPONENTIAL TECHNIQUES
Ms. T. BHARATHI
PG scholar
Department of Computer Science and Engineering Velalar College of Engineering and Technology
ANNA UNIVERSITY, CHENNAI [email protected]
Mr. T. SATHISH KUMAR, M.E.,
Assistant Professor
Department of Computer Science and Engineering Velalar College of Engineering and Technology
ANNA UNIVERSITY, CHENNAI [email protected]
Abstract—Data mining is the analysis of data and the use of software techniques for finding patterns and regularities in sets of data. A protocol is proposed for privacy preservation in horizontally distributed databases using an association rule mining algorithm. This is based on the Fast Distributed Mining (FDM) algorithm of Cheung et al. [13]. In addition to this protocol, sensitive rules are hidden using Logarithmic and Exponential based Sensitive Data Hiding Technique (LESDT) by increasing and decreasing the support and confidence values of the association rules generated, which modifies the original data. The error correction code is implemented to protect the original private data present in the database. It is simpler and is significantly more efficient in terms of communication rounds, communication and computational cost.
Keywords—Association rules, frequent itemsets, logarithmic and exponential, privacy preserving data mining.
I.INTRODUCTION
Data mining discovers actionable information from large sets of data. Mathematical analysis is used in Data mining to derive patterns and trends that exist in the data. It is the practice of automatically searching large stores of data to discover patterns and trends that go beyond simple analysis. It uses mathematical algorithms to segment the data and evaluate the probability of future events. The problem of secure mining of association rules in horizontally distributed database is overseen here. Association rules uncover relationships between seemingly unrelated data in a relational database or other information repository. The goal is to find all association rules with support at least s and confidence at least c, for some given minimal support size and confidence level, while minimizing the information disclosed about the private databases held by those users.
This goal defines a problem of secure multi-party computation. For example, there are X users that hold private inputs, a1, . . . , aX, and they wish to securely compute b = F(a1, . . . , aX) for some public function F. If there is a trusted third party, the users could surrender the inputs to that user to perform the function evaluation and send the resulting output. In the absence of trusted third party, a protocol should be devised so the users can run it on their own to arrive at the required output b. Such protocol is a perfectly secured one if no user can learn the information more than the user is intended to know when a computation is done by trusted third party. There are two novel secure multi-party algorithms – one computes the union of private subsets that each of the users hold, and
other tests the inclusion of an element held by one user in a subset held by another user.
II.RELATED WORK
Kantarcioglu and Clifton [14] suggested a method that incorporates cryptographic techniques to minimize the information shared while adding little overhead to the mining task. The goal is to produce association rules that hold globally, while limiting the information shared about each site. There are two phases for discovering candidate itemsets and determining which of the candidate itemsets meet the global support/confidence thresholds. The 1st phase uses commutative encryption. Each party encrypts its own itemsets, then the (already encrypted) itemsets of every other party. These are passed around, with each site decrypting, to obtain the complete set. In the 2nd phase, an initiating party passes its support count, plus a random value, to its neighbor. The neighbor adds its support count and passes it on. The final party then engages in a secure comparison with the initiating party to determine if the final result is greater than the threshold plus the random value.
Volume 2 Issue 4, April -2015
23
to learn information of other users beyond what is implied by the final output and their own inputs, even if they are computationally unbounded. Such a computation is computationally private if it achieves the same goal when the users are polynomially-bounded. If the solution is still not perfectly secure, it leaks excess information only to a small number (three) of possible coalitions, unlike the protocol that discloses information even to some single users.
III.METHODOLOGIES
A.Association Rule Mining
Association rule mining uncovers the frequent patterns among the itemsets. It aims to extract fascinating associations, frequent patterns, and correlations among sets of items in the data repositories. Let I = {i1, i2, …, im} be the
set of items with Transaction t : t I, where transaction Database T = {t1, t2, …, tn} and n be the number of
transactions. A transaction t contains X, a set of items (itemset) in I, if X t. An association rule is an implication of the form:
X Y, where X, Y I, and X Y =
Support: The rule holds with support sup in T (the transaction data set) if sup% of transactions contain X Y.
Confidence: The rule holds in T with confidence conf if conf% of transactions that contain X also contain Y.
B.Rapid Thin Mining algorithm
The Rapid Thin Mining (RTM) algorithm, is based on the Fast Distributed Mining (FDM) of Cheung et al., which is an unsecured distributed version of the Apriori algorithm. Its main idea is that any s-frequent itemset must be also locally s-frequent in at least one of the places. So, in order to find all globally s-frequent itemsets, each user reveals his locally s-frequent itemsets and then the users check each of them to see if they are s-frequent globally too.
IV.SECURE COMPUTATION
A.User Initialization
User initialization in privacy preserving data mining has considered two important settings. One, in which the data owner and the data miner are two different entities, and in another, the data is distributed among several parties who aim to jointly perform data mining on the unified corpus of data that they hold. This provides a scheme so that more than one client/user can login at the same time. It also gives the client/user their freedom to enter the information on their own for registration. The Rapid Thin Mining (RTM) algorithm proceeds as follows:
STEP 1: It is assumed that the users have already jointly calculated Fsy - 1. The goal is to proceed and
calculate Fsy.
STEP 2: Each user Pm computes the set of all (y - 1)
itemsets that are locally frequent in his site and also globally frequent; namely, Pm computes the
set Fsy -1,m ∩ Fsy - 1. He then applies on that set the
Apriori algorithm in order to generate the set Bsy,m
of candidate y-itemsets.
STEP 3: For each X ϵ Bsy,m, Pm computes suppm(X). He then
retains only those itemsets that are locally s-frequent. We denote this collection of itemsets by Csy,m.
STEP 4: Each user broadcasts his Cs y,m
and then all users compute: Csy := UMm =1 Csy,m.
STEP 5: All users compute the local supports of all itemsets in Csy .
STEP 6: Each user broadcasts the local supports that he computed. From that, everyone can compute the global support of every itemset in Csy. Finally, Fsy
is the subset of Csy that consists of all globally
s-frequent y-itemsets.
In the first iteration, when y = 1, the set Cs 1,m
that the mth user computes Steps 2 to 3which is just Fs1,m, namely, the
set of single items that are s-frequent in Dm. The complete
RTM algorithm starts by finding all single items that are globally s-frequent. It then proceeds to find all 2-itemsets that are globally s-frequent, and so forth, until it finds the longest globally s-frequent itemsets. If the length of such itemsets is Y, then in the (Y+1) th iteration of the RTM,it will find no (Y + 1)-itemsets that are globally s-frequent, in which case it terminates.
B.Frequent Itemset Identification
We describe here the solution that was proposed by Kantarcioglu and Clifton [14]. They considered two possible settings. If the required output includes all globally s-frequent itemsets, as well as the sizes of their supports, then the values of Δ(x) can be revealed for all x
∈
Ck s . In such a case, those values may be computed using a secure summation protocol where the private addend of Pm is suppm(x) − sNm. The more interesting setting, however, is the one where the support sizes are not part of the required output. We proceed to discuss it.count
X
count
Y
X
confidence
.
).
(
n
count
Y
X
support
(
).
Initialization
Local Pruning Candidate Sets production
Unifying the candidate itemsets
Volume 2 Issue 4, April -2015
24
Frequent itemset identification leads to separating sensitive rules from non sensitive rules using the support and confidence count. A threshold is set based on minsupp value, if the itemset exceeds the minsupp value it is considered sensitive and otherwise non sensitive.
Protocol (THRESHOLD) Secure computation of the t-threshold function
C.UNIFI
We compared the performance of two secure implementations of the RTM algorithm. In the first implementation (denoted FDM-KC), we executed the unification step using Protocol UNIFI-KC, where the commutative cipher was 1024-bit RSA in the second implementation (denoted RTM) we used our Protocol UNIFI, where the keyed-hash function was HMAC . In both implementations, we implemented Step 5 of the RTM algorithm in the secure manner that was described in later. We tested the two implementations with respect to three measures:
1) Total computation time of the complete protocols (FDM-KC and RTM) over all users. That measure includes the Apriori computation time, and the time to identify the globally s-frequent itemsets, as described in later.
2) Total computation time of the unification protocols only (UNIFI-KC and UNIFI) over all users.
3) Total message size. We ran three experiment sets, where each set tested the dependence of the above measures on a different parameter: • N — the number of transactions in the unified database. Steps of UNIFI-KC involve:
1.User selects commutative cipher and private key, selects hash function to apply on all itemsets prior to encryption.
2.User compute lookup table with hash values to find preimage of given hash values.
3.Performs all itemset encryption 4.Itemset Merging
a.Each odd user sends the encrypted set to user 1.
b.Each even user sends the encrypted set to user 2.
c.User 1 and 2 unifies all sets that were sent to them and removes duplicate.
d.User 2 sends his permuted list of itemsets to user 1.
e.User 1 unifies his list of itemsets and the list received from user 2 and then removes duplicates from the unified lists.
5.Decryption.
Protocol (UNIFI) Unifying lists of locally Frequent Itemsets
D.Logarithmic and Exponentiation
This process leads to hiding sensitive rules using logarithmic exponential private data modifier by increasing and decreasing the support and confidence values of the rules generated. The logarithmic exponential private data modifier [LEPDM] structural framework is efficiently designed for hiding sensitive rules which slightly modifies the private data in the database to enhance the privacy preservation scheme.
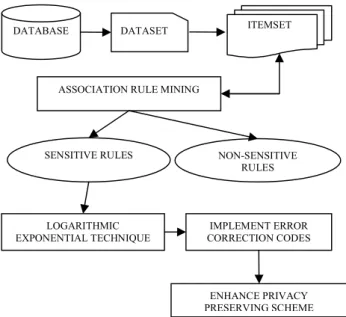
Fig. 1: System Architecture
From the fig.1, it is being observed that the dataset is derived from the database and the dataset holds several bank customer sensitive and non sensitive data. After deriving the input data, the association rule mining is applies to generate sensitive and non-sensitive rules. The
DATABASE DATASET
ITEMSET
ASSOCIATION RULE MINING
SENSITIVE RULES NON-SENSITIVE RULES
ENHANCE PRIVACY PRESERVING SCHEME LOGARITHMIC
EXPONENTIAL TECHNIQUE
IMPLEMENT ERROR CORRECTION CODES
INPUT: Each user Um has an input binary vector bm ϵ
Z2n, 1 ≤ m ≤ M.
OUTPUT: b := Ti(b1………..bM ).
1. Each Um selects M random share vectors bm,l ϵ
ZnM+1,
1 ≤ l ≤ M, such that ∑Ml=1 bm,l = bm mod ( M +1 ).
2. Each Um sends bm,l to Ul for all 1 ≤ l ≠ m ≤ M .
3. Each Ul computes Sl = (Sl (1),…….., Sl(n)) : = ∑Mm=1
bm,l mod ( M +1 ).
4. Users Ut , 2 ≤ l ≤ M -1, send St to U1 .
5. U1 computes S = (S(1),…….., S(n)) := ∑ M-1
l=1 St mod
( M +1 ).
6. for i = 1,……..,n do
7. If (S(i),…….., SM(i)) mod ( M +1 ) < t set b(i) = 0
otherwise set b(i) = 1. 8.end for
9. Output b = (b(1),…….,b(n)).
INPUT: Each user Um has an input subset Csy,m ⊆ Ap
(Fsy - 1), 1 ≤ m ≤ M.
OUTPUT: Csy= UMm =1 Csy,m .
1. Each user Um encodes his subset Csy,m as a binary
vector bm of length ny = |Ap (Fsy - 1)|, in accord with the
agreed ordering of Ap (Fsy - 1) .
2. The users invoke Protocol THRESHOLD to compute b = T1(b1,……..,bM) = VMm=1 b
Volume 2 Issue 4, April -2015
25
main objective of LESDHT - Logarithmic and exponential based Sensitive Data Hiding Technique is to hide sensitive rules which provide a same impact on non-sensitive rules.
Table I: Sample Database Transaction
TID A B C D
T1 1 1 0 1
T2 0 1 0 0
T3 1 0 1 1
T4 1 1 0 0
T5 1 1 0 1
A sample record of transactions is shown in the Table I. The database comprises transactions whose attribute values are obtained from the set {A; B; C; D}. For this database, when we put the least amount support threshold to 50% and the least amount confidence threshold to 70%, the common (large) items are A, B, and D with s as 80%, 80%, and 60%, correspondingly. Frequent itemsets of AB and AD are support 60%. A two logarithmic exponential itemset modifier are used to evaluate the rule hiding process. Consider T be a sample transaction database consists of n number of records. If the number of values in the particular itemset has its maximum value contrast to other values, then it is necessary to decrease the value of that itemset by adding up the number of records with less value using the logarithmic exponential multiplication and expressed as,
)
(log
log
log
T
e
T
e
T
e
n
i
ni (1)For the minimum value of records in the database, we have to diminish the set of records in the database by implementing logarithmic exponential subtraction and expressed as follows,
T e T e
T
e n i
i n
log log
log
(2)
If an unauthorized user had a chance to view the database, the database shows only dummy values and not real values.
E.Error Correction and Hiding Sensitive Data
The proposed LESDHT framework hides the sensitive rules for privacy preservation and it alters the values of the itemset in the original dataset to enhance the privacy levels of the user with a slight error variance seems to be in the original transaction. To eradicate the error variance occurring in the original dataset, in this work, we are going to use an error correcting code. An error-correcting code (ECC) or forward error correction (FEC) code is a method of adding up redundant data, to a point, such that it can be improved by a recipient yet while a number were initiated, either through the process of transmission, or on storage.
FEC requires that itemset in the database first be encoded. The original user data to be maintained over the database is called information bits, while the data after the addition of error-correction information is termed as coded
bits. For y itemset in the database, the encoding procedure produces n coded bits where n > y. All n bits are broadcasted. An FEC decoder develops these n bit estimates, along with comprehension of how all n bits were formed, to produce estimates of the y itemset. The decoding process efficiently corrects errors in the database while recovering the original itemsets with its respective values.
The need for error protection becomes obvious when one considers that the number of errors in a transactional database that has been replicated r times is comparable to the number of errors in an unelected transactional database. For a given error rate, the proposed LESDHT undergoes abundant replication cycles. Hence, for an itemset to stay consistent within a transactional database with its original value, a strong error protection is introduced.
V.PERFORMANCE EVALUATION
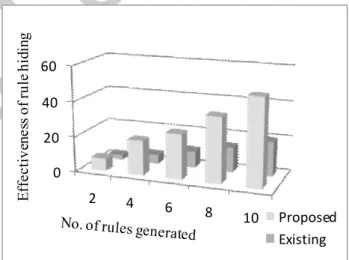
When we analyze the experimental results of the proposed Logarithmic and exponential based Sensitive Data Hiding Technique [LESDHT] with the existing work which is simple privacy preservation scheme using association rule hiding algorithm, it is observed that the total number of sensitive rules hidden for diverse values of support and confidence enhanced the user privacy levels by implementing the error correction codes too.
0 20 40 60
2 4
6 8
10 Proposed Existing
E
ff
e
c
ti
v
en
e
ss
o
f
ru
le
h
id
in
g
Fig. 2: No. of rules vs. Effectiveness of rule hiding
Volume 2 Issue 4, April -2015
26
010 20
25 50 75
100 125 Proposed Error
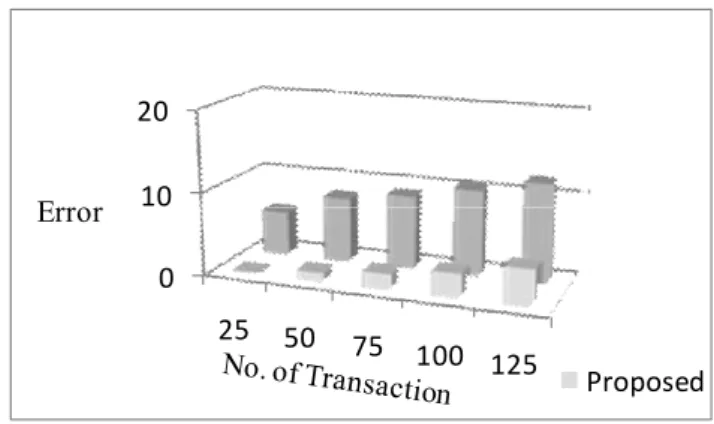
Fig. 3: No. of transaction vs. Error variance
Fig. 3, describes the process of identifying the occurrence of error variance based on number of transactions present in the database. The chances of error variance occurring in the original set of data are obtained only when the users are trying to hide a set of sensitive rules generated. Since we alter the records and its value in the database, there is a chance for error to occur in the values of the original database. To overcome this error, the proposed LESDHT used error correction codes to prevent the database from duplicate values. Comparatively the proposed logarithmic exponential itemset modifier for preserving sensitive rules outperforms the existing in correcting the error variance and the difference is 30-40% low in the proposed LESDHT.
VI.CONCLUSION
A protocol for secure mining of association rules in horizontally distributed databases improves significantly the current leading protocol in terms of privacy and efficiency. One of the main ingredients in our proposed protocol is a novel secure multi-party protocol for computing the union (or intersection) of private subsets that each of the interacting users holds. Another ingredient is a protocol that tests the inclusion of an element held by one player in a subset held by another. The results of the secure mining of association rules in horizontally distributed databases can be effective in improving the privacy rate. In future, hiding sensitive rules using logarithmic exponential private data modifier by increasing and decreasing the support and confidence values of the rules generated. The second process is to implement error correction codes in order to protect the original private data present in the database. An error-correcting code is an algorithm for expressing a sequence of numbers such that any errors which are introduced is detected and corrected based on the remaining numbers.
REFERENCES
[1]Charu C., Aggarwal and Philip S. Yu, “A Condensation Approach to Privacy Preserving Data Mining,” Springer Journal, PP. 183-199, 2008.
[2] Cheng-Chi Lee, Pei-Shan Chung and Min-Shiang Hwang, “A Survey on Attribute-based Encryption Schemes of Access Control in Cloud Environments,” International Journal of Network Security, Vol.15, No.4, PP.231-240, July 2013.
[3] Dharmendra Thakur and Prof. Hitesh Gupta, “An Exemplary Study of Privacy Preserving Association Rule Mining Techniques,”
International Journal of Advanced Research in Computer Science and Software Engineering, Vol. 3, Issue 11, Nov 2013.
[4] Mareeswari G. and Anusuya V, “Accumulative Privacy Preserving Data Mining Using Gaussian Noise Data Perturbation at Multi Level Trust,” Proceedings of International Conference On Global Innovations In Computing Technology (ICGICT”14), Vol. 2, Issue 1,March 2014.
[5] Patil Amrut A. and Thakore D. M., “Privacy Preserving in Horizontal Aggregation Using Homomorphic Encryption,” International Journal of Computer Science and Information Technologies, Vol. 5 (2), 2014.
[6] Priyanka Dubey and Roshani Dubey, “Fully Homomorphic Encryption Based Multiparty Association Rule Mining,” International Journal of Computer Engineering & Science. ISSN:22316590, Jan 2014.
[7] Sankita Patel and Devesh C Jinwala, “Privacy Preserving Distributed K-Means Clustering in Malicious Model,” Springer, 2013.
[8] Smita D. Patel and Sanjay Tiwari, “Privacy Preserving Data Mining,” International Journal of Computer Science and Information Technologies, Vol. 4 (1), 2013
[9] Supriya S. Borhade and Bipin B. Shinde, “Privacy Preserving Data Mining Using Association Rule With Condensation Approach,” International Journal of Computer Science and Information Technologies, Vol. 5 (2) , (IJCSIT), 2014.
[10]Tamir Tassa, “Secure Mining of Association Rules in Horizontally Distributed Databases,” IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING, VOL. 26, NO. 4, April 2014.
[11]Vipul Goyal, Omkant Pandey, Amit Sahai and Brent Waters, “Attribute-Based Encryption for Fine-Grained Access Control of Encrypted Data, 2006.
[12]Ximeng Liu, Jianfeng Ma, Jinbo Xiong and Guangjun Liu1, “Ciphertext-Policy Hierarchical Attribute-based Encryption for Fine-Grained Access Control of Encryption Data,” International Journal of Network Security, Vol.16, No.4, PP.351-357, July 2014. [13]D.W.L. Cheung, J. Han, V.T.Y. Ng, A.W.C. Fu, and Y. Fu, “A Fast
Distributed Algorithm for Mining Association Rules,” Proc. Fourth Int” l Conf. Parallel and Distributed Information Systems (PDIS), pp. 31-42, 1996.