173
Data Integration of Distributed Data Using Secure
Two Party Algorithm
Mr.K.Thambi Prbhakaran,
Ms.P.Mallika, ME
M.E.,(CSE),
Assistant Professor/CSE,
Jay Shriram Group of Institutions, Tiruppur.
Jay Shriram Group of Institutions, Tiruppur.
[email protected]
[email protected]
Abstract-To propose a method to securely integrate person-specific sensitive data from two data providers, whereby the integrated data still retains the essential information for supporting data mining tasks. The more real-life scenarios are in need for simultaneous data sharing and privacy preservation of person-specific sensitive data. In this project, we adopt differential privacy, a recently proposed privacy model that provides a provable privacy guarantee. Differential privacy is a rigorous privacy model that makes no assumption about an adversary’s background knowledge. A differentially-private mechanism ensures that the probability of any output (released data) is equally likely from all nearly identical input data sets and thus guarantees that all outputs are insensitive to any individual’s data. In other words, an individual’s privacy is not at risk because of the participation in the data set. In particular, we present an algorithm for differentially private data release for vertically-partitioned data between two parties in the semi-honest adversary model. To achieve this, we first present a two-party protocol for the exponential mechanism. This protocol can be used as a sub protocol by any other algorithm that requires the exponential mechanism in a distributed setting. Furthermore, we propose a two-party algorithm that releases differentially-private data in a secure way according to the definition of secure multiparty computation.
Index Terms—Essential information, Two-party algorithm, vertically-partitioned
I.INTRODUCTION
Data mining is the process of analyzing data from different perspectives and summarizing it into useful information - information that can be used to increase revenue, cuts costs, or both. Data mining software is one of a number of analytical tools for analyzing data. It allows users to analyze data from many different dimensions or angles, categorize it, and summarize the relationships identified. Technically, data mining is the process of finding correlations or patterns among dozens of fields in large relational databases.
Medical data mining
In 2011, the case of Sorrell v. IMS Health, Inc., decided by the Supreme Court of the United States, ruled that pharmacies may share information with outside companies. This practice was authorized under the 1st Amendment of the Constitution, protecting the "freedom of speech".
Spatial data mining
Spatial data mining is the application of data mining methods to spatial data. The end objective of spatial data mining is to find patterns in data with respect to geography. So far, data mining and Geographic Information Systems (GIS) have existed as two separate technologies, each with its own methods, traditions, and
approaches to visualization and data analysis.
Particularly, most contemporary GIS have only very basic spatial analysis functionality. The immense explosion in geographically referenced data occasioned by developments in IT, digital mapping, remote sensing, and the global diffusion of GIS emphasizes the
importance of developing data-driven inductive
approaches to geographical analysis and modeling.
Data mining offers great potential benefits for GIS-based applied decision-making. Recently, the task of integrating these two technologies has become of critical importance, especially as various public and private sector organizations possessing huge databases with thematic and geographically referenced data begin to realize the huge potential of the information contained therein. Among those organizations are:
offices requiring analysis or dissemination
of geo-referenced statistical data
public health services searching for
explanations of disease clustering
environmental agencies assessing the
impact of changing land-use patterns on climate change
There are several critical research challenges in geographic knowledge discovery and data mining. Miller and Han offer the following list of emerging research topics in the field:
Developing and supporting geographic data warehouses (GDW's): Spatial properties are often reduced to simple a spatial attributes in mainstream data warehouses. Creating an integrated GDW requires
solving issues of spatial and temporal data
interoperability – including differences in semantics, referencing systems, geometry, accuracy, and position.
174
the time dimension needs to be more fully integrated into these geographic representations and relationships.Geographic knowledge discovery using
diverse data types: GKD methods should be developed that can handle diverse data types beyond the traditional raster and vector models, including imagery and geo-referenced multimedia, as well as dynamic data types (video streams, animation).
Knowledge grid
Knowledge discovery "On the Grid" generally refers to conducting knowledge discovery in an open environment
using grid computing concepts, allowing users to
integrate data from various online data sources, as well make use of remote resources, for executing their data
mining tasks. The earliest example was
the DiscoveryNet, developed at Imperial College London, which won the "Most Innovative Data-Intensive Application Award" at the ACM SC02 (Supercomputing
2002) conference and exhibition, based on a
demonstration of a fully interactive distributed
knowledge discovery application for a bioinformatics application. Other examples include work conducted by researchers at the University of Calabria, who developed a Knowledge Grid architecture for distributed knowledge discovery, based on grid computing.
Components of Data Mining Algorithms
Each data mining method can be characterized in terms of four aspects:
• The models or patterns that are used to describe what is searched for in the data set. Typical models are dependency rules, clusters and decision trees.
• The scoring functions that are used to determine how well a given dataset fits the model. This is comparable to the similarity functions used in information retrieval.
• The method that is applied in order to find data in the dataset that scores well with respect to the scoring function. Normally this requires efficient search algorithms that allow to identify those models that fit the data well according to the scoring functions.
• Finally the scalable implementation of the method for large datasets. Here indexing techniques and efficient secondary storage management are applied.
II.OBJECTIVE
Objective of the project is to propose a method that releases differentially-private data in a secure way with the participation of multiparty computation. Two-party protocol as a sub protocol of our main algorithm, and it can also be used by any other algorithm that uses the exponential mechanism in a distributed setting. The first two-party data publishing algorithm for vertically-partitioned data that generates an integrated data table satisfying differential privacy.
III. EXISTING SYSTEM
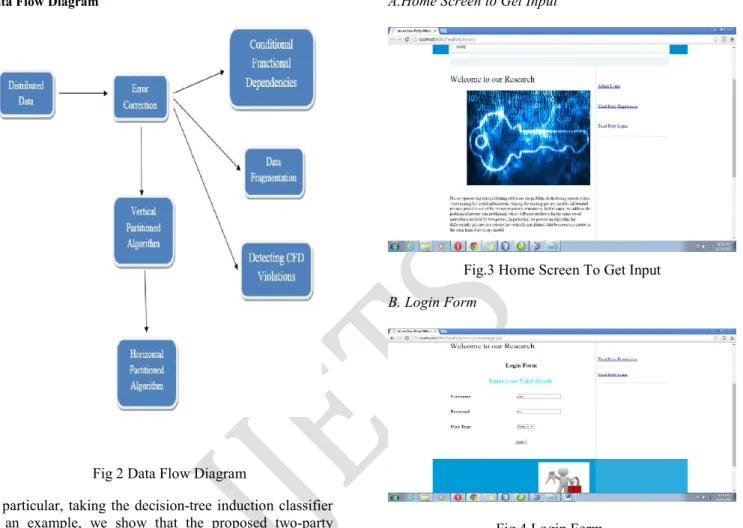
This method establishes the complexity bounds and provides efficient algorithms for incrementally detecting the violations of CFDs in fragmented and distributed data, either vertically or horizontally.
1) It formulate incremental detection as an optimization problem, and establish its complexity bounds. We show that the problem is NP-complete even when both D and CFDs are fixed, i.e., when only the size of updates varies. Nevertheless, we show that the problem is bounded: there exist algorithms for incremental detection such that their communication costs and computational costs are functions in the size of the changes in the input and output, independent of the size of database D. This tells us that incremental detection can be carried out efficiently, since in practice, D and V are typically small.
2) This method develop an algorithm for incrementally detecting violations of CFDs for vertical partitions. We show that the algorithm is optimal: both its communication costs and computational costs are linear in D and V. Indeed, D and V characterize the amount of work that is absolutely necessary to perform for incremental detection.
3) This method develops optimization methods to further reduce data shipment for error detection in vertical partitions. The idea is to identify and maximally share indices among CFDs such that when multiple CFDs demand the shipment of the same tuples, only a single copy of the data is shipped. We show that the problem for building optimal indices is NP-complete, but provide an efficient heuristic algorithm.
4) We also provide an incremental detection algorithm for horizontal partitions. We show that the algorithm is also optimal, as for its vertical counterpart.
5) Using TPCH for large scale data and DBLP for real-life data, we conduct experiments on Amazon EC2. We find that our incremental algorithms outperform their batch counterpart’s by two orders of magnitude, for large updates (up to 10GB for TPCH). Moreover, our methods scale well with both the size of data and the number of CFDs. We also find the optimization strategies effective. This work provides fundamental results and a practical solution for error detection in distributed data. We focus on CFDs because they carry constant patterns and are difficult to handle, and moreover, they capture inconsistencies that traditional dependencies fail to catch. The techniques developed here, nonetheless, can be readily used to incrementally detect violations of other dependencies used in data cleaning, such as functional dependencies and denial constraints.
Modules Description
175
In contrast to traditional functional dependencies (FDs) that were developed mainly for schema design, CFDs aim at capturing the consistency of data by incorporating bindings of semantically related values. For CFDs we provide an inference system analogous to Armstrong’s axioms for FDs, as well as consistency analysis. Since CFDs allow data bindings, a large number of individual constraints may hold on a table, complicating detection of constraint violations. We develop techniques for detecting CFD violations in SQL as well as novel techniques for checking multiple constraints in a single query.Data fragmentation
Data fragmentation occurs when a piece of data in memory is broken up into many pieces that are not close together. This is typically the result of attempting to insert a large object into storage that has already suffered external fragmentation. This article provides a brief introduction to fragmentation and its unique issues in a cloud environment. Fragmentation, (also referred to as sharding, or partitioning) involves splitting a data set into smaller fragments (or shards), and distributing them across a large number of machines. Sharding policies, which dictate how to shard the data, may vary with space
constraints and performance considerations.
Applications’ requests for operations on the data set are automatically sent to some or all servers hosting relevant shards, and the results are coalesced by the application. Sharding also helps availability, as it is much faster to retrieve small data fragments, rather than larger ones, which significantly improves response times. While the term “sharding” is typically applied to the fragmentation of databases, data which are not part of a structured database may also be split up into chunks or fragments for storage or operations.
Vertical Partitioned Algorithm
Vertical partitioning is applied in three contexts: a database stored on devices of a single type, a database stored in different memory levels, and a distributed database. In a two-level memory hierarchy, most transactions should be processed using the fragments in primary memory. In distributed databases, fragment allocation should maximize the amount of local transaction processing. Fragments may be non-overlapping or non-overlapping. A two-phase approach for the determination of fragments is proposed; in the first phase, the design is driven by empirical objective functions which do not require specific cost information. The second phase performs cost optimization by incorporating the knowledge of a specific application environment. It performs two operations
(a) The logical accesses of transactions to the object.
(b) The relevant design parameters, such as cost of storage, cost of accessing a record occurrence, cost of transmission.
Horizontal Partitioned Algorithm
Horizontal partitioning is based on predicate abstraction which maps the domain of a relation to be partitioned to an abstract domain following a finite set of arbitrary predicates chosen over the whole concrete domain. To address the above optimization problem, we first choose a set of predicates to horizontally partition some (or all) dimension relations of a DW with star scheme, and then split the fact relation by using the predicates specified on dimension relations. This creates a number of sub-star fragments of the data warehouse we consider, where each sub-star fragment consists of a partition of the fact table and corresponding to it partitions of dimension relations.
IV.PROPOSED SYSTEM
In this paper, to present an algorithm for differentially-private data release for vertically partitioned data between two parties. We take the single-party algorithm for differential privacy that has been recently proposed by Mohammed as a basis and extend it to the two-party setting. Additionally, the proposed algorithm satisfies the security definition of the semi-honest adversary model. In this model, parties follow the algorithm but may try to deduce additional information from the received messages. Therefore, at any time during the execution of the algorithm, no party should learn more information about the other party’s data than what is found in the final integrated table, which is differentially-private. The main contribution of our paper can be summarized as follows: We present a two-party protocol for the exponential mechanism. We use this protocol as a sub protocol of our main algorithm, and it can also be used by any other algorithm that uses the exponential mechanism in a distributed setting. We present the first two-party data publishing algorithm for vertically-partitioned data that generates an integrated data table satisfying differential privacy.
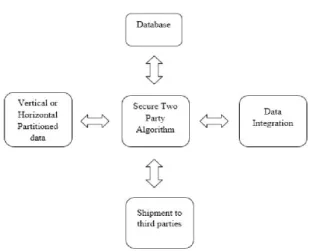
System Architecture
176
The algorithm also satisfies the security definition in the secure multiparty computation (SMC) literature. We experimentally show that the differentially private integrated data table preserves information for a data mining task.Data Flow Diagram
Fig 2 Data Flow Diagram
In particular, taking the decision-tree induction classifier as an example, we show that the proposed two-party algorithm provides similar data utility for classification analysis when compared to the single party algorithm, and it performs better than the recently proposed two-party algorithm.
V. MODULE DESCRIPTION
Two party data collection
This module is for collecting the data records with splitting of data for two parties. Both parties have a common primary key for identification and further integration. The data consists of sensitive information’s
and non-sensitive information’s. The sensitive
information should be kept privacy during maintaining and sharing of data to others.
Candidate selection
This module takes the output of last module which discussed. This module is to find out the candidates from
the two party splitted data. The sensitive information’s are taken into account and used for further splitting, it is called candidate selection. The both party will have the candidate selection and the original data are grouped with the candidates.
VI.SCREENSHOTS
A.Home Screen to Get Input
Fig.3 Home Screen To Get Input
B. Login Form
Fig.4 Login Form
C. Data sets
177
D.Party Information’sFig.6 Party information’s
VII.CONCLUSION AND FUTURE WORK
The project deals with the incremental CFD violation detection for distributed data, from complexity to algorithms. It discussed that the problem is NP-complete.The project also developed optimal incremental violation detection algorithms for data partitioned vertically or horizontally, as well as optimization methods. The results have verified that these yield a promising solution to catching errors in distributed data.
The future work is the first two-party differentially-private data release algorithm for vertically-partitioned data. It will illustrate that the proposed algorithm is differentially-private and secure under the security definition of the semi-honest adversary model. The proposed algorithm can effectively retain essential information for classification analysis. It provides similar data utility compared to the recently proposed single party algorithm and better data utility than the distributed k-anonymity algorithm for classification analysis.
VIII.REFERENCES
[1] R. Agrawal, A. Evfimievski, and R. Srikant. Information sharing across private databases. In Proceedings of the ACM International Conference on Management of Data, 2003.
[2] B. Barak, K. Chaudhuri, C. Dwork, S. Kale, F. McSherry, and K. Talwar. Privacy, accuracy, and consistency too: A holistic solution to contingency table release. In Proceedings of the ACM Symposium on Principles of Database Systems (PODS), 2007.
[3] R. J. Bayardo and R. Agrawal. Data privacy through optimal k-anonymization. In Proceedings of the IEEE International Conference on Data Engineering (ICDE), 2005.
[4] R. Bhaskar, S. Laxman, A. Smith, and A. Thakurta. Discovering frequent patterns in sensitive data. In Proceedings of the ACM International Conference on Knowledge Discovery and Data Mining (SIGKDD), 2010.
[5] A. Blum, K. Ligett, and A. Roth. A learning theory approach to non-interactive database privacy. In Proceedings of the ACM Symposium on Theory of Computing (STOC), 2008.
[6] J. Brickell and V. Shmatikov. Privacy-preserving classifier learning. In Proceedings of the International Conference on Financial Cryptography and Data Security, 2009.
[7] P. Bunn and R. Ostrovsky. Secure two-party k-means clustering. In Proceedings of the ACM Conference on Computer and Communications Security (CCS), 2007.
[8] K. Chaudhuri, C. Monteleoni, and A. Sarwate. Differentially private empirical risk minimization.Journal of Machine Learning Research (JMLR), 12:1069–1109, July 2011.
[9] K. Chaudhuri, A. D. Sarwate, and K. Sinha. Near-optimal differentially private principal components. In Proceedings of the Conference on Neural Information Processing Systems, 2012.
[10] C. Clifton, M. Kantarcioglu, J. Vaidya, X. Lin, and M. Y. Zhu. Tools for privacy preserving distributed data mining. ACM International Conference on Knowledge Discovery and Data Mining (SIGKDD) Explorations Newsletter, 4(2):28–34, December 2002.
[11] K.R. Jackson, L. Ramakrishnan,K.Muriki, S. Canon, S. Cholia,J. Shalf, H.J.Wasserman, and N.J.Wright, ‘‘Performance Analysis of High Performance Computing Applications on the Amazon Web Services Cloud,’’ in Proc. 2nd Int’l Conf. CloudCom, 2010,pp. 159-168.
[12].J. Yu, R. Buyya, and K. Ramamohanarao,
‘‘Workflow Scheduling Algorithms for Grid
Computing,’’ in Metaheuristics for Scheduling in Distributed Computing Environments, F. Xhafa and A.Abraham, Eds. New York, NY, USA: Springer-Verlag, 2008.
AUTHORS BIOGRAPHY
K.ThambiPrabhakaran received his B.Tech
degreein Tamilnadu College of
Engineering,Coimbatore, India and currently pursuing M.E degree in Jay Shriram Group of Institutions, Tiruppur, India. His research interests include Data Mining, Advanced Database and Operating System .System