ReginaBarzilay
Kathleen R. McKeown y
MassachusettsInstitute ofTechnology ColumbiaUniversity
A system that can produce informative summaries, highlighting common
informa-tion found in many onlinedocuments, will help webusers topinpointinformation that
they needwithoutextensivereading. Inthis paper,weintroducesentencefusion,anovel
text-to-textgenerationtechniqueforsynthesizingcommoninformationacrossdocuments.
Sentencefusioninvolvesbottom-uplocalmultisequencealignmenttoidentifyphrases
con-veyingsimilarinformation; andstatistical generationtocombinecommonphrasesintoa
sentence.Sentencefusionmovesthesummarizationeldfromtheuseofpurelyextractive
methodsto the generation of abstracts, which containsentencesnot found inany of the
input documentsandwhich cansynthesize informationacrosssources.
1. Introduction
Redundancy inlarge text collections, such asthe web, creates bothproblemsand
op-portunities for natural languagesystems. On the one hand, the presence of numerous
sourcesconveyingthesameinformationcausesdiÆcultiesforendusersofsearchengines
and newsproviders;theymustread thesameinformationoverand overagain.On the
otherhand,redundancycanbeexploitedtoidentifyimportantandaccurateinformation
for applications such as summarization and question answering (Mani and Bloedorn,
1997; Radev and McKeown, 1998; Radev, Prager, and Samn, 2000; Clarke, Cormack,
and Lynam, 2001; Dumais et al., 2002; Chu-Carrollet al., 2003). Clearly, it would be
highly desirable to have a mechanism that could identifycommon informationamong
multiplerelateddocumentsandfuse itinto acoherenttext.Inthispaper,wepresenta
methodforsentencefusionthatexploitsredundancytoachievethistask inthecontext
of multidocumentsummarization.
Astraightforwardapproachforapproximatingsentencefusioncanbefoundintheuse
ofsentenceextractionformultidocumentsummarization(CarbonellandGoldstein,1998;
Radev,Jing,andBudzikowska,2000;MarcuandGerber,2001;LinandHovy,2002).Once
a system nds a set of sentences that conveysimilar information(e.g., by clustering),
one of these sentences is selected to representthe set. This is arobust approach that
is always guaranteed to output a grammatical sentence. However, extraction is only
acoarse approximationoffusion.An extractedsentencemayincludenotonly common
information,butadditionalinformationspecictothearticlefromwhichitcame,leading
to sourcebiasandaggravatinguencyproblemsintheextracted summary.Attempting
tosolvethisproblembyincludingmoresentencesmightleadtoaverboseandrepetitive
summary.
ComputerScienceandArticialIntelligenceLaboratory,MassachusettsInstituteofTechnology,
Cambridge,MA02458
tencesthatarecommon.Languagegenerationoersanappealingapproachtothe
prob-lem,buttheuseofgenerationinthiscontextraisessignicantresearchchallenges.In
par-ticular,generationforsentencefusionmustbeabletooperateinadomain-independent
fashion,scalabletohandlealargevarietyofinputdocumentswithvariousdegreesof
over-lap. Inthepast,generationsystemswere developedforlimiteddomainsandrequireda
rich semanticrepresentation as input. In contrast, for this task we require text-to-text
generation, the abilityto produce anew text given a set of related texts as input. If
language generationcan be scaled to take fully formedtext asinput withoutsemantic
interpretation,selectingcontentandproducingwell-formedEnglishsentencesasoutput,
then generationhasalargepotentialpayo.
Inthispaper,wepresenttheconceptofsentencefusion,anoveltext-to-text
genera-tiontechniquewhich,givenasetofsimilarsentences,producesanewsentencecontaining
theinformationcommontomostsentencesintheset.Theresearchchallengesin
develop-ingsuchanalgorithmlieintwoareas:identicationofthefragmentsconveyingcommon
informationand combinationof thefragmentsinto asentence. Toidentifycommon
in-formation, we havedevelopedamethod for aligningsyntactictrees ofinput sentences,
incorporatingparaphrasinginformation.Ouralignmentproblemposesuniquechallenges:
weonlywantto matchasubsetof thesubtrees ineachsentenceandaregivenfew
con-straintsonpermissiblealignments(e.g., arisingfromconstituentordering,startorend
points). Our algorithmmeets these challengesthrough bottom-up localmultisequence
alignment, using words and paraphrases as anchors. Combination of fragments is
ad-dressedthroughconstructionofafusiontreeencompassingtheresultingalignmentand
linearizationofthetreeintoasentenceusingalanguagemodel.Ourapproachtosentence
fusionthusfeaturestheintegrationofrobuststatisticaltechniques,suchaslocal,
multi-sequencealignmentandlanguagemodeling,withlinguisticrepresentationsautomatically
derivedfrominputdocuments.
Sentencefusionisasignicantrststeptowardsthegenerationofabstracts,as
op-posed toextracts(BorkoandBernier,1975),formulti-documentsummarization.While
therehasbeenresearchonsentencereductionforsingledocumentsummarization
(Grefen-stette,1998;Mani,Gates,andBloedorn,1999;KnightandMarcu,2001;Jingand
McK-eown, 2000;Reizleretal., 2003),analysisof human-writtenmulti-documentsummaries
showsthatmostsentencescontaininformationdrawnfrommultipledocuments(Banko
andVanderwende,2004).Unlikeextractionmethods(usedbythevastmajorityof
sum-marizationresearchers),sentencefusionallowsforthetruesynthesisofinformationfrom
asetofinputdocuments.Itgeneratessummarysentencesbyreusingandalteringphrases
frominputsentences,combiningcommoninformationfromseveralsources.Consequently,
onesummarysentencemayincludeinformationconveyedinseveralinputsentences.Our
evaluation shows that our approach is promising, with sentence fusion outperforming
sentenceextractionforthetaskofcontentselection.
This paperdescribesthe implementationof thesentencefusion methodwithin the
multidocumentsummarizationsystemMultiGen,whichdailysummarizesmultiplenews
articles onthe sameeventaspart 1
of Columbia'snewsbrowsingsystemNewsblaster. 2
Analysis ofthesystem'soutputreveals thecapabilitiesandtheweaknessesofour
text-to-text generation method and identies interesting challenges that will require new
insights.
In the next section, we provide an overview of the multidocumentsummarization
1InadditiontoMultiGen,NewsblasterutilizesanothersummarizerDEMS(Schiman,Nenkova,and
McKeown,2002)tosummarizeheterogeneoussetsofarticles.
system MultiGen focusing on components that produce input or operate overoutput
of sentence fusion. In Section 3, we provide an overview of our fusion algorithm and
detailonitsmainsteps:identicationofcommoninformation(Section3.1),fusionlattice
computation(Section3.2),andlatticelinearization(Section3.3).Evaluationresultsand
theiranalysisarepresentedinSection4.An overviewofrelatedwork anddiscussionof
future directionsconcludethepaper.
2. Frameworkfor SentenceFusion: MultiGen
SentencefusionisthecentraltechniqueusedwithintheMultiGensummarizationsystem.
MultiGen takes as input a cluster of news stories on the same event and produces a
summarywhich synthesizescommoninformationacrossinput stories.An exampleof a
MultiGensummaryisshowninFigure1.Theinputclustersareautomaticallyproduced
from alarge quantity of newsarticles that are retrievedby Newsblaster from30 news
siteseach day.
Figure1
AnexampleofMultiGensummaryasshownintheColumbiaNewsblasterInterface.Summary
phrasesarefollowedbyparenthesizednumbersindicatingtheir sourcearticles.Thelast
sentenceisextractedsinceitwasrepeatedverbatiminseveralinputarticles.
Inordertounderstandtheroleofsentencefusionwithinsummarization,weoverview
theMultiGenarchitecture,providingdetailsontheprocessesthatprecedesentencefusion
and thus,theinputthatthefusioncomponentrequires.Fusion itselfisdiscussedinthe
followingsectionsof thepaper.
MultiGenfollowsapipelinearchitecture,showninFigure2.Theanalysiscomponent
of thesystem,Simnder(Hatzivassiloglou,Klavans,andEskin,1999)clusterssentences
beincludedinthesummary,dependingonthedesiredcompressionlength(Section2.2).
Theselectedgroupsarepassedtotheorderingcomponent,whichselectsacompleteorder
amongthemes(Section 2.3).
2.1 Theme Construction
The analysiscomponentof MultiGen, Simnder,identies themes,groupsof sentences
from dierent documents that each say roughly the samething. Each theme will
ulti-mately correspond to at most one sentence in the output summary, generated by the
fusioncomponent,andtheremaybemanythemesforasetofarticles.An exampleofa
themeisshowninTable1.Asthissetillustrates,sentenceswithinathemearenotexact
repetitionsofeachother;theyusuallyincludephrasesexpressinginformationthatisnot
common to allsentencesinthe theme.Informationthat is common acrosssentencesis
shown inbold; other portions of the sentence are specic to individualarticles. If one
of these sentences were used asis to representthe theme, thesummarywould contain
extraneousinformation.Also,errorsinclusteringmayresultintheinclusionofsome
un-related sentences. Evaluationinvolvinghumanjudgesrevealedthat Simnderidenties
similar sentences with 49.3% precision at 52.9% recall (Hatzivassiloglou,Klavans,and
Eskin,1999).Wewilldiscusslaterhowthiserrorrateinuencessentencefusion.
Sentence
Fusion
Theme
Selection
Computation
Theme
Ordering
Theme
Article
Article
Summary
. . .
1
n
Figure2
MultiGenArchitecture
1.IDFSpokeswomandidnotconrmthis,butsaidthePalestiniansredan
anti-tankmissileat a bulldozer.
2.TheclasheruptedwhenPalestinian militants red machine-guns and
anti-tank missilesat a bulldozer that wasbuildinganembankmentinthe
areatobetterprotectIsraeliforces.
3.The armyexpressed \regretat thelossof innocentlives"but asenior
com-mandersaidtroopshadshotinself-defenseafter beingredat whileusing
bulldozersto buildanewembankmentat anarmybaseinthearea.
fusion sentence:Palestiniansredananti-tankmissileatabulldozer.
Table 1
Athemewiththecorrespondingfusionsentence.
Toidentifythemes,Simnderextractslinguisticallymotivatedfeaturesforeach
sen-tence,includingWordNetsynsets(Milleretal.,1990)andsyntacticdependencies,suchas
subject-verbandverb-objectrelations.Alog-linearregressionmodelisused tocombine
theevidencefromthevariousfeaturestoasinglesimilarityvalue.Themodelwastrained
modelisalistingofreal-valuedsimilarityvaluesonsentencepairs.Thesesimilarity
val-ues arefed into aclusteringalgorithmthatpartitionsthesentences intoclosely related
groups.
2.2 Theme Selection
Togenerateasummaryofpredeterminedlength,weinducearankingonthethemesand
selectthenhighest. 3
Thisrankingisbasedonthreefeaturesofthetheme:sizemeasured
as thenumberof sentences, similarityof sentencesinatheme, and saliencescore. The
rst twoof thesescoresareproducedbySimnder,andthesalience scoreof thetheme
is computed using lexical chains (Morris andHirst, 1991; Barzilayand Elhadad,1997)
asdescribedbelow.Sinceeachofthesescoreshasadierentrangeofvalues,weperform
rankingbasedoneachscoreseparately,andthen,inducetotalrankingbysummingranks
fromindividualcategories:
Rank(theme) =Rank(Numberof sentencesintheme)+
Rank(Similarityofsentencesintheme)+
Rank(Sumoflexicalchainscoresintheme)
Lexicalchains|sequencesofsemanticallyrelatedwords|aretightlyconnectedtothe
lexicalcohesivestructureofthetext andhavebeenshown tobeusefulfordetermining
whichsentencesareimportantforsingledocumentsummarization(BarzilayandElhadad,
1997; Silber and McCoy, 2002). In the multidocument scenario, lexical chains can be
adaptedforthemerankingbasedonthesalienceofthemesentenceswithintheiroriginal
documents.Specically,athemethat hasmanysentencesrankedhighbylexicalchains
as importantfor asingle document summary, is, inturn, givena highersalience score
for themultidocumentsummary.Inourimplementation,asaliencescoreforathemeis
computedasthesumoflexicalchainscoresofeachsentenceinatheme.
2.3 Theme Ordering
Oncewelteroutthethemesthathavealowrank,thenexttaskistoordertheselected
themes into coherent text. Our ordering strategy aims to capture chronologicalorder
of the mainevents and ensurecoherence.Toimplement thisstrategy in MultiGen,we
select for each theme thesentencewhich hasthe earliestpublicationtime(theme time
stamp). To increase the coherence of the output text, we identify blocks of
topically-related themesand then applychronologicalorderingonblocksofthemes using theme
timestamps(Barzilay,Elhadad,andMcKeown,2002).Thesestagesthusproduceasorted
set ofthemeswhichare passedasinputtothesentencefusioncomponent,describedin
thenextsection.
3. Sentence Fusion
Given a group of similar sentences|a theme|the problem is to create a concise and
uentfusionofinformationwiththistheme,reectingfactscommontoallsentences.An
exampleofafusionsentenceisshowninTable1.Toachievethisgoalweneedtoidentify
phrasescommontomostthemesentences,andthencombinethemintoanewsentence.
Atoneextreme,wemightconsiderashallowapproachtothefusionproblem,
adapt-ingthe\bagofwords"approach.However,sentenceintersectioninaset-theoreticsense
3Typically,Simnderproducesatleast20themesgivenanaverageNewsblasterclusterofnine
theme shown in Table 1 is (the, red, anti-tank, at, a, bulldozer). Besides being
un-grammatical,itisimpossibleto understand whateventthis intersectiondescribes.The
inadequacy of the \bag of words" method to the fusion task demonstrates the need
foramorelinguisticallymotivatedapproach.Attheotherextreme,previousapproaches
(RadevandMcKeown,1998)havedemonstratedthatthistaskisfeasiblewhenadetailed
semantic representationof the input sentences is available. However,these approaches
operateinalimiteddomain(e.g.,terroristevents),whereinformationextractionsystems
canbeusedtointerpretthesourcetext.Thetaskofmappinginputtextintoasemantic
representation inadomain-independentsetting extends well beyondthe abilityof
cur-rentanalysismethods.Theseconsiderationssuggestthatweneedanewmethodforthe
sentencefusiontask.Ideally,suchamethodwouldnotrequireafullsemantic
representa-tion.Rather,itwouldrelyoninputtextsandshallowlinguisticknowledge(suchasparse
trees)that canbeautomaticallyderivedfromacorpustogenerateafusionsentence.
In our approach, sentence fusion is modeled after the typical generationpipeline:
content selection (what to say) and surfacerealization (how to say it). In contrast to
traditionalgenerationsystemswhereacontentselectioncomponentchoosescontentfrom
semanticunits,ourtaskiscomplicatedbythelackofsemanticsinthetextualinput.At
thesametime,wecanbenetfromthetextualinformationgivenintheinputsentences
for thetasks ofsyntacticrealization,phrasing,and ordering;inmanycases,constraints
ontext realizationarealreadypresentintheinput.
Thealgorithmoperatesinthree phases:
Identication ofcommon information (Section3.1)
Fusionlatticecomputation (Section3.2)
Latticelinearization (Section 3.3)
Contentselection occursprimarilyinthe rstphase, inwhich ouralgorithmuseslocal
alignment across pairs of parsed sentences, from which we select fragments to be
in-cluded inthe fusionsentence. Insteadof examining allpossibleways to combinethese
fragments,weselect asentence intheinput which containsmost ofthe fragmentsand
transformitsparsedtreeintothefusionlatticebyeliminatingnon-essentialinformation
andaugmentingitwithinformationfromotherinputsentences.Thisconstructionofthe
fusionlatticetargetscontentselectionbut,intheprocess,alternativeverbalizationsare
selectedandthus,someaspectsofrealizationarealsocarriedoutinthisphase.Finally,
wegenerateasentencefromthisrepresentationbasedonalanguagemodelderivedfrom
alargebodyoftexts.Thisapproachgeneratesafusionsentencebyreusingandaltering
phrasesfromtheinputsentences,performingtext-to-textgeneration.
3.1 Identication ofCommon Information
Our task is to identify informationshared between sentences. We do this by aligning
constituentsinthesyntacticparsetreesfor theinputsentences. Ouralignmentprocess
diers considerably from alignment for other NL tasks, such as machine translation,
because we cannot expect a complete alignment. Rather, a subset of the subtrees in
one sentence will match dierent subsets of the subtrees in the others. Furthermore,
order acrosstreesisnotpreserved;there isnonaturalstartingpointforalignment;and
there are no constraintson crosses. Forthese reasonswe havedeveloped abottom-up
local multisequence alignment algorithm that uses words and phrases as anchors for
matching.Thisalgorithmoperatesonthedependencytreesforpairsofinputsentences.
for comparison such as constituent ordering. In the paragraphs that follow, we rst
describehowthisrepresentationiscomputed,thendescribehowdependencysubtreesare
aligned,andnallydescribehowwechoosebetweenconstituentsconveyingoverlapping
information.
In this section werst describe an algorithmwhich, given apair of sentences,
de-termines which sentence constituents conveyinformationappearing inboth sentences.
This algorithmwillbeappliedtopairwisecombinationsofsentencesintheinputsetof
relatedsentences.
The intuition behind the algorithmis to compare all constituents of one sentence
to those of another, and to select the most similarones. Of course, how this
compar-ison is done depends on the particularsentence representation used. A good sentence
representationwouldemphasizesentencefeaturesthatarerelevantforcomparison,such
as dependencies betweensentence constituents,while ignoringirrelevantfeatures, such
as constituentordering.Arepresentationwhichtstheserequirementsisa
dependency-basedrepresentation(Melcuk,1988).Werstdetailhowthisrepresentationiscomputed,
then describeamethod foraligningdependencysubtrees,andnallypresentamethod
for selectingcomponentsconveyingoverlappinginformation.
3.1.1 Sentence Representation. Inmany NLPapplications,the structure ofa
sen-tence is representedusing phrasestructuretrees. An alternativerepresentationis a
de-pendency tree,whichdescribesthesentencestructure intermsofdependenciesbetween
words.The similarityof the dependency tree to apredicate-argumentstructure makes
it anaturalrepresentationforourcomparison. 4
This representationcanbeconstructed
from the output of atraditional parser. In fact, we have developeda rule-based
com-ponent that transforms the phrase-structure output of Collins' parser (Collins, 1997)
into a representation where a node has a directlink to its dependents. We also mark
verb-subjectandverb-nodedependenciesinthetree.
The process ofcomparingtrees canbefurther facilitatedifthe dependency treeis
abstracted to acanonical formwhich eliminates features irrelevantto thecomparison.
Wehypothesizethatthedierenceingrammaticalfeaturessuchasauxiliaries,number,
and tense have a secondary eect when comparing the meaning of sentences.
There-fore,werepresentinthedependencytreeonlynon-auxiliarywordswiththeirassociated
grammatical features. Fornouns, werecord their number,articles, and class (common
orproper).Forverbs,werecordtense,mood(indicative,conditionalorinnitive),voice,
polarity,aspect(simpleorcontinuous),andtaxis(perfectornone).Theeliminated
aux-iliary words canbe recreated using these recorded features. We also transform all the
passivevoicesentencestotheactivevoice,changingtheorderofaected children.
WhilethealignmentalgorithmdescribedinSection3.1.2producesone-to-one
map-pings,inpracticesomeparaphrasesarenotdecomposabletowords,formingone-to-many
ormany-to-manyparaphrases.Ourmanualanalysisofparaphrasedsentences(Barzilay,
2003)revealedthatsuchalignmentsmostfrequentlyoccurinpairsofnounphrases(e.g.,
\facultymember"and\professor")andpairsincludingverbswithparticles(e.g.,\stand
up",\rise").Tocorrectlyalignsuchphrases,weattensubtreescontainingnounphrases
andverbswithparticlesintoonenode.Wesubsequentlydeterminematchesbetween
at-tenedsentencesusingstatisticalmetrics.
Anexampleofasentenceanditsdependencytreewithassociatedfeaturesisshownin
4Twoparaphrasingsentenceswhichdierinwordordermayhavesignicantlydierenttreesin
phrase-basedformat.Forinstance,thisphenomenon occurswhenanadverbialismovedfroma
positioninthemiddleofasentencetothebeginningofasentence.Incontrast,dependency
confirm
[tense:past mood:ind pol:neg ...]
IDF spokeswoman
[number:singular definite:yes class:common]
this
but
say
[tense:past mood:ind pol:pos ...]
fire
[tense:past mood:ind pos:pos ...]
Palestinian
[number:plural definite:yes class:common]
anti-tank missile
[number:singular definite:no class:common]
at
bulldozer
[number:singular definite:no class:common]
Figure3
Dependencytreeofthesentence\TheIDFspokeswomandid notconrmthis,butsaidthe
Palestinians redananti-tankmissileatabulldozeronthesite."Thefeaturesofthenode
\conrm"areexplicitlymarkedinthegraph.
Figure3.(Inguresofdependencytreeshereafter,nodefeaturesareomittedforclarity.)
3.1.2Alignment. Ouralignmentofdependencytreesisdrivenbytwosourcesof
infor-mation:thesimilaritybetweenthestructureofthedependencytrees,andthesimilarity
betweentwogivenwords.Indeterminingthestructuralsimilaritybetweentwotrees,we
takeintoaccountthetypesofedges(whichindicatetherelationshipsbetweennodes).An
edgeislabeledbythesyntacticfunctionofthetwonodesitconnects(e.g.,subject-verb).
It is unlikelythat anedge connectingasubjectand verbinonesentence,for example,
correspondstoanedgeconnectingaverbandanadjectiveinanothersentence.
Thewordsimilaritymeasurestakeintoaccountmorethanwordidentity:theyalso
identify pairs of paraphrases,using WordNet and aparaphrasing dictionary. We
auto-maticallyconstructedtheparaphrasingdictionaryfromalargecomparablenewscorpus
usingtheco-trainingmethoddescribedin(BarzilayandMcKeown,2001).Thedictionary
containspairsofword-levelparaphrasesaswellasphrase-levelparaphrases. 5
Several
ex-amples of automaticallyextracted paraphrasesare giveninTable2.Duringalignment,
eachpairofnon-identicalwordsthat donotcompriseasynsetinWordNet islookedup
5Thecomparablecorpusandthederiveddictionaryareavailableat
http://www.cs.cornell. edu/ ~re gina /th esis -da ta/c omp /inp ut/ proc esse d.t bz2 and
http://www.cs.cornell. edu/ ~re gina /th esis -da ta/c omp /out put /com p2-A LL. txt. Fordetailson
in the paraphrasingdictionary; in the case of a match, the pair is considered to be a
paraphrase.
(auto, automobile), (closing, settling), (rejected, does not accept), (military,
army),(IWC,InternationalWhalingCommission),(Japan,country),
(research-ing, examining), (harvesting, killing), (mission-controloÆce, controlcenters),
(father,pastor),(past50years,fourdecades),(Wangler,Wanger),(teacher,
pas-tor), (fondling,groping),(Kalkilya,Qalqilya),(accused,suspected),(language,
terms), (head, president), (U.N., United Nations), (Islamabad, Kabul), (goes,
travels), (said, testied), (article, report), (chaos, upheaval), (Gore,
Lieber-man), (revolt, uprising), (more restrictive local measures, stronger local
reg-ulations)(countries,nations),(barred,suspended), (alert,warning),(declined,
refused),(anthrax,infection),(expelled,removed),(WhiteHouse,WhiteHouse
spokesmanAriFleischer),(gunmen,militants)
Table 2
Lexicalparaphrasesextractedbythealgorithmfromthecomparablenewscorpus.
Wenowgiveanintuitiveexplanationofhowourtreesimilarityfunction,denotedby
Sim,iscomputed.Iftheoptimalalignmentoftwotreesisknown,thenthevalueofthe
similarityfunctionisthesumofthesimilarityscoresofalignednodesandalignededges.
Sincethebestalignmentofgiventreesisnotknownapriori,weselectthemaximalscore
amongplausiblealignmentsofthetrees.Insteadof exhaustivelytraversingthespaceof
all possible alignments, we recursively construct the best alignment for trees of given
depths, assuming that we know how to nd an optimalalignmentfor trees of shorter
depths. Morespecically,at each pointofthetraversalweconsidertwocases,shownin
Figure4.Intherstcase,twotopnodesarealignedtoeachotherandtheirchildrenare
alignedinanoptimalwaybyapplyingthealgorithmtoshortertrees.Inthesecondcase,
one treeis alignedwithoneof thechildrenofthe topnode ofthe othertree; againwe
canapplyouralgorithmforthiscomputation,sincewedecreasetheheightofoneofthe
trees.
Beforegivingtheprecise denitionofSim, weintroducesomenotation.WhenT is
atreewithrootnodev,weletc(T)denotethesetcontainingallchildrenofv.Foratree
T containinganodes,thesubtreeofT whichhassasitsrootnodeisdenoted byT
s .
Given two trees T and T 0
with root nodes v and v 0
, respectively, the similarity
Sim(T;T 0
) between the trees is dened to be the maximum of the three expressions
NodeCompare(T;T 0 ), maxfSim(T s ;T 0 )s2 c(T)g, and maxfSim(T;T 0 s 0) : s 0 2 c(T 0 )g.
TheupperpartofFigure4depictsthecomputationofNodeCompare(T;T 0
),wheretwo
top nodes are aligned to each other. The remainingexpressions, maxfSim(T
s ;T 0 )s 2 c(T)g,andmaxfSim(T;T 0 s 0):s 0 2c(T 0
)g,capturemappingsinwhichthetopofonetree
is alignedwithoneof thechildrenofthetopnodeoftheother tree(the bottomof the
Figure 4).
ThemaximizationintheNodeCompareformulasearchesforthebestpossible
align-mentforthechildnodesofthegivenpairofnodesandisdenedby
NodeCompare(T;T 0 )= NodeSim(v;v 0 )+ max m2M(c(T);c(T 0 )) 2 4 X (s;s 0 )2m (EdgeSim((v;s);(v 0 ;s 0 ))+Sim(T s ;T 0 s 0)) 3 5 where M(A;A 0
) istheset ofall possiblematchings betweenAand A 0 , andamatching (between A and A 0 ) is a subset m of AA 0
First case
Second case
Figure4
Treealignmentcomputation.Intherstcasetwotopsarealigned,whileinthesecondcase
thetopofonetreeisalignedtoachildofanothertree.
(a;a 0 );(b;b 0 )2m, both a6=b and a 0 6=b 0
. Inthebase case,when oneof thetrees has
depthone,NodeCompare(T;T 0
)isdened tobeNodeSim(v;v 0
).
ThesimilarityscoreNodeSim(v;v 0
) of atomic nodes depends on whether the
cor-respondingwordsareidentical,paraphrasesorunrelated.Thesimilarityscoresforpairs
of identicalwords,pairs of synonyms,pairs of paraphrasesoredges (given inTable3)
aremanuallyderivedusingasmalldevelopmentcorpus.Whilelearningofthesimilarity
scoresautomaticallyis anappealingalternative,its applicationinthe fusioncontextis
challengingdue to theabsence ofa largetrainingcorpusand thelack ofan automatic
evaluationfunction. 6
Thesimilarityofnodescontainingattenedsubtrees, 7
suchasnoun
phrases, is computedas thescore oftheir intersectionnormalizedby thelength of the
longestphrase.Forinstance,thesimilarityscoreofthenounphrases\anti-tankmissile"
and \machine gun and anti-tank missile" is computed asa ratiobetween the scoreof
theirintersection\anti-tankmissile" (2), dividedbythelengthofthelatterphrase(4).
The computationofthe similarityfunctionSim isperformed usingbottom-up
dy-namicprogramming,wheretheshortestsubtreesareprocessedrst.Thealignment
algo-rithmreturnsthesimilarityscoreofthetreesaswellastheoptimalmappingbetweenthe
subtreesofinputtrees.Intheresultingtreemapping,thepairsofnodeswhoseNodeSim
6Ourpreliminaryexperimentswithn-gram-basedoverlapmeasures,suchasBLEU(Papinenietal.,
2002)andROUGE(LinandHovy,2003),showthatthesemetricsdonotcorrelatewithhuman
judgmentsonthefusiontask,whentestedagainsttworeferencesoutputs.Thisistobeexpected:as
lexical variabilityacrossinputsentencesgrows,thenumberofpossiblewaystofusethemby
machineaswellbyhumanalsogrows.Theaccuracyofmatchbetweenthesystemoutputandthe
referencesentencesislargelydependsonthefeaturesoftheinputsentences,ratherthanonthe
underlyingfusionmethod.
7Pairsofphrasesthatformanentryintheparaphrasingdictionaryarecomparedaspairsofatomic
Category NodeSim Category NodeSim
Identicalwords 1 Edgesaresubject-verb 0.03
Synonyms 1 Edgesareverb-object 0.03
Paraphrases 0.5 Edgesaresametype 0.02
Other -0.1 Other 0
Table 3
confirm
IDF
spokeswoman
this
but
said
fire
Palestinian
anti-tank
missile
at
bulldozer
erupt
clash
when
fire
Palestinian
militant
machine gun
and anti-tank
missile
at
bulldozer
that
build
embarkment
in
protect
area
better
israeli
force
erupt
when
clash
fire
fire
Palestinian
Palestinian
militant
anti-tank
missile
machine gun
and anti-tank
missile
at
at
confirm
IDF
spokeswoman
this
but
said
bulldozer
bulldozer
that
build
embarkment
in
protect
area
better
israeli
force
Figure5
Twodependencytreesandtheiralignmenttree.Solidlinesrepresent alignededges.Dotted
anddashededgesrepresentunalignededgesofthethemesentences.
positivelycontributedtothealignmentareconsideredasparallel.
Figure 5showstwodependencytreesand theiralignment.
As it is evident fromthe Sim denition, we are only consideringone-to-one node
\matchings": everynode in one tree is mapped to at most one node in another tree.
This restrictionis necessary, sincethe problemof optimizingmany-to-manyalignment
is NP-hard. 8
Thesubtreeattening,performed duringthepreprocessingstage,aimsto
minimizethenegativeeect oftherestrictiononalignmentgranularity.
Anotherimportantpropertyofouralgorithmis thatit producesalocalalignment.
Localalignmentmapslocalregionswithhighsimilaritytoeachotherratherthancreating
an overalloptimalglobalalignmentoftheentiretree. Thisstrategyismoremeaningful
whenonlypartialmeaningoverlapisexpectedbetweeninputsentences,asintypical
sen-8Thecomplexityofouralgorithmispolynomialinthenumberofnodes.
Letn1denotethenumberofnodesinthersttree,andn2 denotethenumberofnodesinthe
secondtree.Weassumethatthebranchingfactorofaparsetreeisboundedabovebyaconstant.
ThefunctionNodeCompareisevaluatedonlyonceoneachnodepair.Therefore,itisevaluated
n
1 n
2
timestotally.Eachevaluationiscomputedinconstanttime,assumingthatvaluesofthe
functionfornodechildrenareknown.Sinceweusememoization,thetotaltimeoftheprocedureis
O(n
1 n
2 ).
tencefusioninput.Onlythesehighsimilarityregions,whichwecallintersectionsubtrees,
are includedinthefusionsentence.
3.2 Fusion Lattice Computation
The nextquestionweaddressis howto put together intersectionsubtrees.Duringthis
process,thesystemwillremovephrasesfromaselectedsentence,addphrasesfromother
sentences,and replacewordswiththeparaphrasesthatannotate each node.Obviously,
among the many possible combinations, we are interested only in those combinations
which yieldsemanticallysound sentences and donotdistortthe informationpresented
intheinput sentences. Wecannotexploreeverypossiblecombination,sincethelackof
semanticinformationinthetreesprohibitsusfromassessingthequalityoftheresulting
sentences. Instead,weselectacombinationalreadypresentintheinput sentencesasa
basis, and transformit into afusionsentence byremovingextraneousinformationand
augmentingthe fusionsentence with informationfromother sentences. The advantage
of this strategy is that, when the initial sentence is semantically correct and the
ap-plied transformations aim to preserve semanticcorrectness, the resultingsentence is a
semanticallycorrectone.Infact,earlyexperimentationwithgenerationfromconstituent
phrases(e.g., NPs,VPs,etc.)demonstrated that it wasdiÆcultto ensure that
seman-tically anomalousor ungrammaticalsentences would notbe generated.Our generation
strategy isreminiscentof earlierworkonrevisionforsummarization (Robinand
McK-eown, 1996),although Robin and McKeown used athree-tiered representation of each
sentence, including its semantics, deep, and surface syntax, all of which were used as
triggersforrevision.
The three steps of the fusion lattice computationare ordered asfollows: selection
of the basis tree, augmentationof the treewith alternativeverbalizations,and pruning
of theextraneoussubtrees.Alignmentis essentialforallthesteps.Theselectionof the
basis treeisguided bythenumberofintersectionsubtreesitincludes;inthebest case,
it contains all such subtrees. The basis tree is the centroid of the input sentences |
a sentence which is the most similar to the other sentences in the input. Using the
alignment-basedsimilarity score described in Section 3.1.2, we identify a centroid by
computing for each sentence the average similarityscorebetweenthe sentence and the
rest oftheinputsentences,andthenselectingasentencewithamaximalscore.
Next, we augment the basis tree with informationpresent inthe other input
sen-tences. More specically, we add alternativeverbalizations for the nodes in the basis
tree and theintersectionsubtrees which arenot partof thebasistree. The alternative
verbalizationsare readilyavailablefromthepairwise alignmentsof the basis treewith
othertreesintheinputcomputedintheprevioussection.Foreachnodeofthebasistree
werecordallverbalizationsfromthenodesoftheotherinputtreesalignedwithagiven
node.Averbalizationcanbeasingleword,oritcanbeaphrase,ifanoderepresentsa
nouncompoundoraverbwithaparticle.Anexampleofafusionlattice,augmentedwith
alternativeverbalizations,isgiveninFigure6.Evenafterthis augmentation,thefusion
latticemaynotincludealloftheintersectionsubtrees.ThemaindiÆcultyinsubtree
in-sertion isndingitsacceptableplacement,whichisoftendeterminedbyvarioussources
of knowledge: syntactic, semanticand idiosyncratic.Therefore, we only insertsubtrees
whose topnode aligns with oneof the nodes ina basis tree. Wefurther constrain the
insertion procedure byonlyinsertingtreesthat appearinat leasthalfof thesentences
erupt
clash
when
fire
Palestinian
militant
machine gun
and anti-tank
missile
at
bulldozer
that
build
embarkment
in
protect
area
better
israeli
force
erupt
when
clash
fire
fire
fire
Palestinial
Palestinian
militant
anti-tank
missile
machine gun
and anti-tank
missile
at
at
bulldozer
bulldozer
bulldozer
while
that
to
build
embarkment
new
embarkment
in
in
protect
area
area
better
israeli
force
using
Figure6Abasislattice beforeandaftertheaugmentation.Solidlinesrepresentalignededgesofthe
basis tree.Dashededgesrepresentunalignededgesofthebasistree,anddottededges
representinsertionsfromotherthemesentences.
unreadablesentences. 9
Finally,subtreeswhicharenotpartoftheintersectionareprunedothebasistree.
However, removing all such subtrees may result in an ungrammatical or semantically
awed sentence; for example,wemightcreatea sentence withoutasubject. This
over-pruningmayhappenifeithertheinputtothefusionalgorithmisnoisy,orthealignment
hasfailedtoidentify thesimilaritybetweensomesubtrees.Therefore,weperformmore
conservativepruning,deletingself-containedcomponentswhichcanberemovedwithout
leavingungrammaticalsentences.Aspreviouslyobservedintheliterature(Mani,Gates,
andBloedorn,1999;JingandMcKeown,2000),suchcomponentsincludeaclauseinthe
clause conjunction,relativeclauses,andsomeelementswithinaclause(suchasadverbs
and prepositions). For example, this procedure transforms the latticein Figure 6 into
theprunedbasislatticeshowninFigure7bydeletingtheclause\theclasherupted"and
the verbphrase\to better protectIsraeli forces." These phrasesareeliminatedbecause
they donot appear inother sentencesof atheme, and at thesametime their removal
9Thepreferenceforshorterfusionsentencesisfurtherenforcedduringthelinearizationstagebecause
fire
fire
fire
Palestinial
Palestinian
militant
anti-tank
missile
machine gun
and anti-tank
missile
at
at
bulldozer
bulldozer
bulldozer
while
that
to
build
embarkment
new
embarkment
in
in
area
area
using
Figure7Aprunedbasislattice.
doesnotinterfere with thewell-formednessofthe fusionsentence.Once these subtrees
are removed,thefusionlatticeconstructioniscompleted.
3.3 Generation
Thenalstageinsentencefusionislinearizationofthefusionlattice.Sentencegeneration
includesselectionofatreetraversalorder,lexicalchoiceamongavailablealternativesand
placementof auxiliaries,such as determiners. Ourgenerationmethod utilizes
informa-tion givenin the input sentences to restrictthe search space and then chooses among
remainingalternativesbasedusingalanguagemodelderivedfromalargetextcollection.
Werstmotivatetheneedinreorderingandrephrasing,andthendiscussour
implemen-tation.
Forthe word orderingtask, we donot haveto considerallthe possibletraversals,
since the number of valid traversals is limited by ordering constraints encoded in the
fusion lattice.However,the basislatticedoesnotuniquelydeterminethe ordering:the
placement of treesinserted in thebasis lattice fromother theme sentencesare not
re-stricted by theoriginalbasistree. While theorderingofmanysentence constituentsis
determinedbytheirsyntacticroles,someconstituents,suchastime,locationandmanner
Theprocesssofarproducesasentencethatcanbequitedierentfromtheextracted
sentence; while the basis sentences provides guidance for the generationprocess,
con-stituentsmayberemoved,addedin,orreordered.Wordingcanalsobemodiedduring
thisprocess.Althoughtheselectionofwordsandphraseswhichappearinthebasistree
is asafechoice,enrichingthefusionsentencewithalternativeverbalizationshasseveral
benets. Inapplicationssuch as summarization,wherethe lengthof theproduced
sen-tenceisafactor,ashorteralternativeisdesirable.Thisgoalcanbeachievedbyselecting
theshortestparaphraseamongavailablealternatives.Alternateverbalizationscanalsobe
used toreplaceanaphoricexpressions,forinstance,whenthebasistreecontainsanoun
phrasewithanaphoricexpressions(e.g.,\hisvisit")andoneoftheotherverbalizationsis
anaphora-free. Substitutionof thelatterfor theanaphoric expressionmayincrease the
clarityoftheproducedsentence,sincefrequentlytheantecedentoftheanaphoric
expres-sion is not presentin asummary.In additionto caseswhere substitution is preferable
but notmandatory,therearecaseswhereitisarequiredstepforgenerationofauent
sentence.Asaresultofsubtreeinsertionsanddeletions,thewordsusedinthebasistree
maynotbeagoodchoiceafterthetransformationsandthebestverbalizationwouldbe
achievedbyusingtheirparaphrasefromanotherthemesentence.Asanexample,consider
thecaseoftwoparaphrasingverbswithdierentsubcategorizationframes,suchas\tell"
and\say".Ifthephrase\ourcorrespondent"isremovedfromthesentence\Sharontold
our correspondent thatthe electionsweredelayed...",areplacementoftheverb\told"
with \said"yieldsamorereadablesentence.
The task of auxiliary placementis alleviated by the presence of features stored in
the input nodes. Inmost cases, aligned wordsstored inthe samenode havethe same
feature values,which uniquely determine anauxiliary selectionand conjugation.
How-ever,insomecases,alignedwordshavedierentgrammaticalfeatures,inwhichcasethe
linearizationalgorithmneedstoselectamongavailablealternatives.
Linearizationof thefusionsentenceinvolvesthe selectionof thebest phrasingand
placementofauxiliariesaswellasthedeterminationofoptimalordering.Sincewedonot
havesuÆcientsemanticinformationtoperformsuchselection,ouralgorithmisdrivenby
corpus-derivedknowledge.Wegenerateallpossiblesentences 10
fromthevalidtraversalsof
thefusionlattice,andscoretheirlikelihoodaccordingtostatisticsderivedfromacorpus.
This approach, originally proposed by (Knight and Hatzivassiloglou, 1995; Langkilde
and Knight, 1998), is a standard method used in statistical generation. We trained a
trigrammodelwithGood-Turingsmoothingover60Megabyteofnewsarticlescollected
byNewsblasterusingthesecondversionCMU-CambridgeStatisticalLanguageModeling
toolkit(ClarksonandRosenfeld,1997).Thesentencewiththelowestlength-normalized
entropy (the best score) is selected as the verbalization of the fusion lattice. Table 4
showsseveralverbalizationsproducedbyouralgorithmfromthecentraltreeinTable7.
Here,wecansee thatthelowestscoringsentenceisbothgrammaticalandconcise.
This tablealsoillustratesthatentropy-basedscoringdoesnotalwayscorrelatewith
the quality of the generated sentence. For example, the fth sentence in Table 4 |
\Palestinians red anti-tank missile at a bulldozer to build a new embankment in the
area." | is not awell-formedsentence; however,our language model gaveit a better
scorethanitswell-formedalternatives,thesecondandthethirdsentences(SeeSection4
for further discussion.) Despitethese shortcomings,we preferredentropy-basedscoring
to symboliclinearization.Inthenextsection,wemotivateourchoice.
10DuetotheeÆciencyconstraintsimposedbyNewsblaster,wesampleonlyasubsetof20,000paths.
Sentence Entropy
Palestiniansredananti-tankmissileatabulldozer. 4.25
Palestinianmilitantsredmachine-gunsandanti-tankmissiles
atabulldozer.
5.86
Palestinianmilitantsredmachine-gunsandanti-tankmissiles
atabulldozerthatwasbuildinganembankmentinthearea.
6.22
Palestiniansredanti-tankmissilesatwhileusingabulldozer. 7.04
Palestiniansred anti-tank missile at a bulldozer to build a
newembankmentinthearea.
5.46
Table 4
tem(Barzilay, McKeown, and Elhadad, 1999), we performed linearization of a fusion
dependencystructureusing thelanguagegeneratorFUF/SURGE(Elhadad andRobin,
1996). As alarge-scale linearizerused in many traditionalsemantic-to-text generation
systems,FUF/SURGEcouldbeanappealingsolutionto thetaskofsurfacerealization.
Because the input structure and the requirementson the linearizerare quite dierent
in text-to-text generation, we had to design rules for mapping between dependency
structures produced by the fusion component and FUF/SURGE input. For instance,
FUF/SURGErequiresthattheinput containasemanticroleforprepositionalphrases,
such as manner, purpose orlocation, which is notpresentinourdependency
represen-tation;thuswehadtoaugmentthedependencyrepresentationwiththisinformation.In
the case of inaccurate predictionor thelackof relevant semanticinformation,the
lin-earizerscramblestheorder ofsentenceconstituents, selectswrongprepositionsoreven
failstogenerateanoutput.AnotherfeatureoftheFUF/SURGEsystemthatnegatively
inuences systemperformanceisits limitedabilityto reuse phrasesreadilyavailablein
the input, instead of generatingevery phrasefromscratch. This makes thegeneration
processmorecomplexand,thus, proneto error.
While the initial experiments conducted on a set of manually constructed themes
seemedpromising,thesystemperformancedeterioratedsignicantlywhenitwasapplied
to automaticallyconstructedthemes. Ourexperienceledus tobelievethat
transforma-tion of an arbitrary sentence into FUF/SURGE input representation is similar in its
complexity to semantic parsing, a challenging problem on its own right. Rather than
reningthemappingmechanism,wemodiedMultiGentouseastatisticallinearization
component,whichhandlesuncertaintyandnoiseintheinputinamorerobustway.
4. Sentence Fusion Evaluation
In our previous work, we evaluated the overall summarization strategy of MultiGen
in multipleexperiments,including comparisons with human-written summaries in the
DUC 11
evaluation(McKeownetal.,2001;McKeownetal.,2002)andqualityassessment
inthecontextofaparticularinformationaccesstaskintheNewsblasterframework
(McK-eownet al.,2002).
In this paper, we aim to evaluate the sentence fusion algorithm in isolationfrom
other system components; we analyze the algorithmperformance in terms of content
selection and the grammaticalityof the produced sentences. We will rst present our
evaluationmethodology(Section4.1),thenwedescribeourdata(Section4.2),theresults
(Section 4.3)andtheiranalysis(Section4.4).
4.1 Methods
Construction of a referencesentenceWeevaluatedcontentselectionbycomparing
an automatically generated sentence with a reference sentence. The reference sentence
wasproduced by ahuman (hereafterRFA) who wasinstructed to generate asentence
conveyinginformationcommontomanysentencesinatheme.TheRFAwasnotfamiliar
with thefusionalgorithm.TheRFAwasprovidedwith thelistof thethemesentences;
the originaldocumentswere notincluded. Theinstructionsgivento the RFA included
severalexamplesofthemeswithfusionsentencesgeneratedbytheauthors.Eventhough
theRFAwasnotinstructedtousephrasesfrominputsentences,thesentencespresented
11DUC(DocumentUnderstandingConference)isacommunity-basedevaluationofsummarization
asexamplesreusedmanyphrasesfromtheinputsentences.Webelievethatphrasereuse
elucidates the connectionbetween input sentences and a resultingfusion sentence. An
exampleofatheme,areferencesentenceandasystemoutputareshowninTable5.
#1 Theforest isabout70mileswestofPortland.
#2 Theirbodieswere foundSaturdayinaremote partof Tillamook
StateForest,about40mileswest ofPortland.
#3 Elk hunters found their bodies Saturday in the Tillamook State
Forest,about60mileswestofthefamily'shometownofPortland.
#4 Theareawhere thebodies were foundis inamountainousforest
about70mileswestofPortland.
Reference ThebodieswerefoundSaturdayintheforestareawestofPortland.
System The bodies
4 were found 2 Saturday 2 in 3 the Tillamook 3 State 3 Forest 3 west 2 of 2 Portland 2 .
#1 FourpeopleincludinganIslamicclerichavebeendetainedin
Pak-istanafter afatalattackonachurchonChristmasDay.
#2 Police detained six people on Thursday following a grenade
at-tackonachurchthatkilledthree girlsandwounded 13peopleon
ChristmasDay.
#3 A grenadeattackona ProtestantchurchinIslamabadkilledve
people,includingaU.S.Embassyemployeeandher17-year-old
daughter.
Reference Agrenadeattackonachurchkilledseveralpeople.
System A 3 grenade 3 attack 3 on 3 a protestant 3 church 3 in 3 Islamabad 3 killed 3 six 2 people 2 . Table 5
Examplesfromthetestset.Eachexamplecontainsatheme,areference sentencegeneratedby
theRFAandasentencegeneratedbythesystem.Subscriptsinthesystem-generatedsentence
representathemesentencefromwhichawordwasextracted.
Data Selection We wanted to test the performance of the fusion component on
automatically computed inputs which reect the accuracy of the existing
preprocess-ing tools.Forthis reason, thetest data wasselectedrandomly frommaterialcollected
by Newsblaster. To removethemes irrelevantfor fusion evaluation,weintroduced two
additional lters. First, we excluded themes that contain identicalor nearly identical
sentences(withcosine similarityhigherthan 0.8).Whenprocessingsuchsentences,our
algorithmreducestosentenceextractionwhichdoesnotallowustoevaluategeneration
abilitiesofouralgorithm.Second,themesforwhichtheRFAwasunabletocreatea
ref-erencesentencewere alsoremovedfromthetestset.As wementionedabove,Simnder
doesnotalwaysproduceaccuratethemes, 12
andtherefore,theRFAcouldchoosenotto
generate areferencesentence ifthethemesentenceshad littleincommon.An example
of athemeforwhich nosentencewasgenerated isshowninTable6.As aresultofthis
ltering,34%ofthesentenceswereremoved.
Baselines In addition to the system-generated sentence, we also included in the
evaluationa fusionsentencegenerated byanother human(hereafter, RFA2) and three
baselines. (Following the DUC terminology, we refer to the baselines, our system and
theRFA2peers.)Therstbaselineistheshortestsentenceamongthethemesentences,
whichisobviouslygrammatical,andalsoithasagoodchanceofbeingrepresentativeof
12TomitigatetheeectsofSimndernoiseinMultiGen,weinducedasimilaritythresholdoninput
Theshareshavefallen60percentthisyear.
TheysaidQwestwasforcingthemtoexchangetheirbondsatafractionofface
value |between52.5 percentand 82.5percent,depending onthebond |or
elsefalllowerinthepeckingorderforrepaymentincaseQwestwentbroke.
Qwesthadoeredtoexchangeupto$12.9billionoftheoldbonds,whichcarried
interestratesbetween5.875percentand 7.9percent.
Thenewdebtcarriesratesbetween13percentand14percent.
Theiryieldfelltoabout15.22percentfrom15.98percent.
Table 6
commontopicsconveyedintheinput.Thesecondbaselineisproducedbyasimplication
ofouralgorithm,whereparaphraseinformationisomittedduringthealignmentprocess.
This baselineis included to capture the contribution of paraphraseinformationto the
performance of the fusion algorithm.Thethird baselineconsists of the basis sentence.
Thecomparisonwiththisbaselinerevealsthecontributionoftheinsertionanddeletion
stages inthe fusionalgorithm. Thecomparisonagainst an RFA2sentence provides an
upperboundaryonthesystemand baselinesperformance.Inaddition,thiscomparison
willshedlightonthehumanagreementonthistask.
Comparison against a reference sentence Thejudge is given apeer sentence
along withthecorrespondingreferencesentence. Thejudge alsohasaccesstothe
origi-nal theme fromwhich these sentences were generated. Theorder ofthe presentationis
randomized acrossthemes andpeer systems. Referenceand peer sentences are divided
into clauses by theauthors. Thejudges assess overlapon theclause-level between
ref-erence and peer sentences. The wording of the instructions wasinspired by the DUC
instructions forclause comparison.For eachclause inthereference sentence, thejudge
decideswhetherthemeaningofacorrespondingclauseisconveyedinapeersentence.In
additionto0scorefor\NoOverlap"and1for\FullOverlap,"thisframeworkallowsfor
\PartialOverlap"withascoreof0.5.Fromtheoverlapdata,wecomputeweightedrecall
and precisionbasedonfractional counts(HatzivassiloglouandMcKeown,1993).Recall
is aratio of weightedclause overlapbetween apeer and areference sentence, and the
numberofclausesinareferencesentence. Precisionisaratioofweightedclause overlap
betweenapeer andareferencesentence,and thenumberofclausesinapeersentence.
GrammaticalityassessmentGrammaticalityisratedinthreecategories:
\Gram-matical"(3),\PartiallyGrammatical"(2),and \NotGrammatical"(1). Thejudges were
instructed to rate a sentence in the \Grammatical"category if it didn't contain any
grammaticalmistakes.The\PartiallyGrammatical"includedsentencesthatcontainat
mostonemistakeinagreement,articlesandtenserealization.The\NonGrammatical"
categoryincludessentencesthatare corruptedbymultiplemistakesof theformertype,
order sentence components in erroneous fashion or miss important components (e.g.,
subject).
Punctuationisoneissueinassessinggrammaticality.Properplacementof
punctua-tionisalimitationspecic 13
toourimplementationofthesentencefusionalgorithmthat
we are well aware of. Therefore, inour grammaticalityevaluation(followingthe DUC
procedure),thejudgewas askedto ignorepunctuation.
4.2 Data
Toevaluateoursentencefusionalgorithm,weselected100themesfollowingtheprocedure
describedintheprevioussection.Eachsetvariedfromtwotosevensentences,with3.82
sentencesonaverage.Thegeneratedfusionsentencesconsistedof1.91clausesonaverage.
Noneofthesentencesinthetestsetwerefullyextracted;onaverage,eachsentencefused
fragments from 2.14 theme sentences. Out of 100 sentence, 57 sentences produced by
the algorithmcombinedphrases fromseveralsentences, whilethe rest of thesentences
comprisedsubsequencesofoneofthethemesentences.Notethatcompressionisdierent
from sentence extraction.Weincluded these sentences in theevaluation,because they
reectbothcontentselectionandrealizationcapacitiesofthealgorithm.
13Wewereunabletodevelopasetofruleswhichworksinmostcases.Punctuationplacementis
determinedbyavarietyoffeatures;consideringallpossibleinteractionsofthesefeaturesishard.
Webelievethatcorpus-basedalgorithmsforautomaticrestorationofpunctuation developedfor
speechrecognitionapplications(Beeferman,Berger,andLaerty,1998;ShieberandTao,2003)
examplesarechosensoastoreectgoodandbadperformancecases.Notethattherst
exampleresultsininclusionoftheessentialinformation(thefactthatbodieswerefound,
alongwith timeandplace)andleavesoutdetails(that itwasaremotelocationorhow
manymileswestitwas,afactthat isindisputeinanycase).Theproblematicexample
incorrectly selects the number of people killedas six, even though this number is not
repeatedand dierentnumbersarereferredto inthetext. Thismistakeiscaused bya
noisyentryinourparaphrasingdictionarywhicherroneouslyidenties\ve"and \six"
as paraphrasesofeachother.
4.3 Results
Table 7 shows the compression rate, precision, recall, F-measure and grammaticality
scoreforeach algorithm.Thecompressionrateofasentencewascomputedastheratio
of itsoutputlengthtotheaveragelengthofthethemeinputsentences.
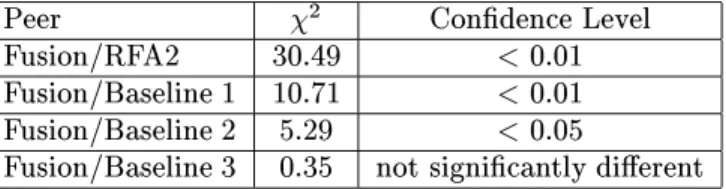
Weuse 2
tests to determine whether the performanceof our method in termsof
F-measure gainis signicantly dierent fromRFA2 and other baselines (see Table 8).
The presence of the diacritics and in Table 7 indicates signicantdierences (at
p<0:05andp<0:01,respectively).
Peer Compression Precision Recall F-measure Grammaticality
RFA2 54% 98% 94% 96% 2.9 System 78% 65% 72% 68% 2.3 Baseline1 69% 52% 38% 44% 3 Baseline2 111% 41% 67% 51% 3 Baseline3 73% 63% 64% 63% 2.4 Table 7
Evaluationresultsforahuman-craftedfusionsentence(RFA2), oursystemoutput,theshortest
sentenceinthetheme(baseline1),thebasissentence(baseline2)andasimpliedversionof
ouralgorithmwithoutparaphrasinginformation(baseline3).
Peer 2 Condence Level Fusion/RFA2 30.49 <0.01 Fusion/Baseline1 10.71 <0.01 Fusion/Baseline2 5.29 <0.05
Fusion/Baseline3 0.35 notsignicantlydierent
Table 8
2
testonF-measure.
4.4Discussion
The results in Table 7 demonstrate that sentences manually generated by the second
human participant(RFA2) are not only theshortest, but are alsoclosest to the
refer-encesentenceintermsofselectedinformation.Thetightconnection 14
betweensentences
generatedbyRFAsestablishesahighupperboundaryforthefusiontask.Whileneither
our systemnorthe baselineswere ableto reach thisperformance, thefusionalgorithm
clearly outperformsall thebaselinesinterms ofcontentselection,at areasonablelevel
14WecannotapplyKappastatistics(SiegelandCastellan,1988)formeasuringagreementinthe
contentselectiontasksinceaneventspaceisnotwell-dened.Thispreventsusfromcomputingthe
of compression. The performance of baseline 1 and baseline 2 demonstrates that
nei-thertheshortestsentencenorthebasissentenceareadequatesubstitutionsforfusionin
terms ofcontentselection; both precisionandrecall are signicantlylower,asmeasure
by 2
test (seeTable8). Thegap inrecallbetweenoursystemand baseline3conrms
ourhypothesisabouttheimportanceofparaphrasinginformationforthefusionprocess.
Omissionof paraphrases(baseline2) causesa8%drop inrecall dueto the inabilityto
matchequivalentphraseswithdierentwording.
Table 7 also reveals a downside of the fusion algorithm: automatically generated
sentences contain grammaticalerrors, unlikefully extracted, human-written sentences.
Giventhehighsensitivityofhumanstoprocessingungrammaticalsentences,onehasto
considerthebenetsofexible informationselectionagainstthedecreaseinreadability
of thegeneratedsentences.Sentencefusionmaynotbeaworthydirectionto pursue,if
low grammaticalityis intrinsic to the algorithm and its correction requiresknowledge
which cannotbeautomaticallyacquired.Intheremainderof thesection,weshowthat
thisisnotthecase.Ourmanualanalysisofgeneratedsentencesrevealedthatmostofthe
grammatical mistakesare caused bythe linearizationcomponent, or,morespecically,
by suboptimal scoring of the languagemodel. Language modeling is an active areaof
research, and we believe that advancement inthis directionwillbe ableto drastically
boostthelinearizationcapacityofouralgorithm.
4.4.1 ErrorAnalysis. Inthissection,wediscusstheresultsofourmanualanalysisof
mistakesin content selectionand surfacerealization.Note that insome casesmultiple
errors are entwined inone sentence, which makesit hard to distinguish betweena
se-quence of independentmistakesandacause-and-eectchains.Therefore,thepresented
countsshouldbeviewedasapproximations,ratherthanprecisenumbers.
Westartwiththeanalysisofthetestset,andcontinuewiththedescriptionofsome
interestingmistakesthatweencounteredduringsystemdevelopment.
Mistakesin Content SelectionMostofthemistakesincontentselectioncanbe
attributed to problemswith alignment.Inmost cases(17 cases),erroneousalignments
missed relevant wordmappings due to the lack of a corresponding entry inour
para-phrasingresources.Atthesametime,mappingofunrelatedwords(asshowninTable5)
is quiterare(twocases).Thisperformancelevelis quitepredictablegiventheaccuracy
of anautomatically constructed dictionaryand limitedcoverage of WordNet. Noisein
lexical resources was exacerbated by the simplicity of our weighting scheme supports
limitedformsofmappingtypology,andalsousesmanuallyassignedweights.Eveninthe
presenceofaccuratelexicalinformation,thealgorithmoccasionallyproducedsuboptimal
alignments(fourcases).
Anothersourceof errors(twocases)isthealgorithm'sinabilitytohandle
many-to-manyalignments.Namely,twotreesconveyingthesamemeaningmaynotbe
decompos-able into thenode levelmappingswhich ouralgorithmaims to compute.Forexample,
themappingbetweenthesentencesinTable9expressedbytherule\Xdeniedclaimsby
Y"$\Xsaidthat Y'sclaimwasuntrue"cannotbedecomposedintosmallermatching
units.Atleasttwomistakesresultedfromnoisypreprocessing(tokenizationandparsing).
SyriadeniedclaimsbyIsraeliPrimeMinisterArielSharon...
TheSyrianspokesmansaidthatSharon'sclaimwasuntrue...
Table 9
Apairofsentenceswhichcannotbefullydecomposed.
\Conservatives werecheeringlanguage."isanexampleofanincompletesentencederived
from the following input sentence: \Conservatives were cheering language in the nal
versionthatinsuresthatone-thirdofallfundsforpreventionprogramsbeusedtopromote
abstinence."Theomissionofarelativeclausewaspossiblebecausesomesentencesinthe
inputthemecontainanoun \language"withoutanyrelativeclauses.
MistakesinSurface RealizationGrammaticalmistakesincludedincorrect
selec-tionofdeterminers,erroneouswordordering,omissionofessentialsentenceconstituents,
incorrect realization of negation constructions and tense. These mistakes (42)
origi-nated duringlinearizationof the lattice, and were caused eitherby incompletenessof
the linearizer or by suboptimal scoring of language model. Mistakes of the rst type
are caused by missingrules for generatingauxiliariesgivennodefeatures. An example
of this phenomenon is the sentence \The coalition to have play a central role.", which
verbalizestheverbconstruction\willhave toplay"incorrectly.Ourlinearizerlacksthe
completenessofexistingapplication-independentlinearizers,suchastheunicationbased
FUF/SURGE(Elhadad and Robin,1996)and the probabilisticFergus(Bangaloreand
Rambow,2000). Unfortunately,wewereunable to reuse any of theexistinglarge-scale
linearizersdueto signicantstructural dierencesbetweeninputexpectedbythese
lin-earizersandtheformatofafusionlattice.WearecurrentlyworkingonadaptingFergus
for thesentencefusiontask.
Mistakesrelated tosuboptimal scoringaremorecommon |33 outof 42;inthese
cases, alanguagemodel selectedill-formedsentences, assigningaworsescoreto a
bet-ter sentence.Thesentence\Thediplomats weregiven to leave the countryin 10 days."
illustratesasuboptimallinearizationof thefusionlattice. Thecorrect linearizations|
\The diplomats were given 10 days toleave the country."and \Thediplomats were
or-dered to leave the country in 10 days." | were present in the fusion lattice, but the
languagemodelpickedtheincorrectverbalization.Wefoundthatin27casestheoptimal
verbalizations(intheauthors'view)wererankedbelowthetoptensentencesrankedby
thelanguagemodel.Webelievethatmorepowerfullanguagemodels,whichincorporate
more linguistic knowledge (such as syntax-based models), can improve the quality of
generated sentences.
4.4.2FurtherAnalysis. Inadditiontoanalyzingerrorsfoundinthisparticularstudy,
wealso regularlytrackthequalityof generatedsummariesonNewsblaster's webpage.
We have noted anumber of interesting errors that crop up from time to time, which
seemto requireinformationaboutthefullsyntacticparse,semanticsorevendiscourse.
Consider, for example, the last sentence from asummary entitled \Estrogen-Progestin
Supplements NowLinkedtoDementia"isshowninTable10.Thissentencewascreated
bysentencefusionandclearly,there isaproblem.Certainly,therewasastudy \nding
the riskofdementia in womenwho took onetypeof combinedhormonepill"but itwas
notthegovernmentstudywhichwasabruptlyhaltedlastsummer.Inlookingatthetwo
sentencesfromwhichthissummarysentencewasdrawn,wecanseethatthereisagood
amountofoverlapbetweenthetwo,butthecomponentdoesnothaveenoughinformation
aboutthereferentsofthedierenttermstoknowthattwodierentstudiesareinvolved
andthatfusionshouldnottakeplace.Onetopicofourfuturework(Section6)isonthe
problemofreferenceandsummarization.
Another example is shown in Table 11. Here again, the problemis reference. The
rsterrorisinthereferencesto\thesegments".Thetwousesof\segments"intherst
source document sentence donotrefer tothe sameentityand thus, whenthe modier
is dropped,wegetananomaly.Thesecond,moreunusualproblemisintheequationof
#1 Lastsummer,agovernmentstudywasabruptlyhaltedafternding
an increased risk of breast cancer, heart attacks and strokes in
womenwhotook onetypeofcombinedhormonepill.
#2 Themostcommonformof hormonereplacementtherapy,already
linkedtobreastcancer,strokeandheartdisease,doesnotimprove
mentalfunctioningassomeearlier studiessuggestedand may
in-creasetheriskofdementia,researcherssaidonTuesday.
System Last 1 summer 1 a 1 government 1 study 1 abruptly 1 was 1 halted 1 after 1 nding 1 the 2 risk 2 of 2 dementia 2 in 1 women 1 who 1 took 1 one 1 type 1 of 1 combined 1 hormone 1 pill 1 . Table 10
Anexampleofwrongreferenceselection.Subscriptsinthegeneratedsentencerepresenta
themesentencefromwhichawordwasextracted.
#1 Thesegmentswillrevivethe\Point-Counterpoint"segments
pop-ular until they stopped airingin1979, but willinsteadbe called
\Clinton/Dole"oneweekand\Dole/Clinton"thenextweek.
#2 ClintonandDolehavesigneduptodothesegmentforthenext10
weeks,Hewitt said.
#3 The segments willbe called\ClintonDole" oneweek and \Dole
Clinton"thenext.
System The 1 segments 1 will 1 revive 1 the 3 segments 3 until 1 they 1 stopped 1 airing 1 in 1 1979 1 but 1 instead 1 will 1 be 1 called 1 Clinton 2 and 2 Dole 2 . Table 11
Anexampleofincorrectreferenceselection.Subscriptsinthegeneratedsentencerepresenta
themesentencefromwhichawordwasextracted.
5.RelatedWork
Text-to-text generationis anemergingareaof NLP. Unliketraditionalconcept-to-text
generationapproaches,text-to-textgenerationmethodstaketextasinput,andtransform
it intoanewtextsatisfyingsomeconstraints(e.g., lengthorlevelof sophistication).In
addition to sentence fusion, compressionalgorithms(Grefenstette, 1998; Mani, Gates,
and Bloedorn,1999;Knightand Marcu,2001; JingandMcKeown, 2000;Reizleret al.,
2003) and methods for expansionof amultiparallelcorpus (Pang,Knight,and Marcu,
2003)areotherexamplesofsuchmethods.
Compressionmethodsweredevelopedforsingle-documentsummarization,andthey
aim to reduce a sentence by eliminatingconstituentswhich are not crucial for its
un-derstandingnorsalientenoughtoincludeinthesummary.Theseapproachesare based
on theobservation that the\importance"ofasentenceconstituentcanoftenbe
deter-mined based on shallow features, such as its syntactic role and the wordsit contains.
Forexample, in manycases a relativeclause that is peripheral to the centralpointof
thedocumentcanberemovedfromasentencewithoutsignicantlydistortingits
mean-ing. While earlier approaches for text compression were based on symbolic reduction
rules(Grefenstette,1998;Mani,Gates,andBloedorn,1999),morerecentapproachesuse
analignedcorpusofdocumentsandtheirhumanwrittensummariestodeterminewhich
constituentscanbereduced (Knight and Marcu, 2001; Jingand McKeown, 2000;
Rei-zleret al.,2003).Alignmentismade betweenthesummarysentences,whichhavebeen
manuallycompressed,andtheoriginalsentencesfromwhichtheyweredrawn.
noisy-as asource and additions to this stringare consideredto be noise.The probabilityof
a source string s is computed by the combination of a standardprobabilistic
context-freegrammarscore,whichisderivedfromthegrammarrulesthatyieldedtrees, anda
word-bigramscore,computedovertheleavesofthetree. Thestochasticchannel model
creates alarge treet froma smallertree sby choosingan extensiontemplatefor each
nodebasedonthelabelsofthenodeanditschildren.Inthedecodingstage,thesystem
searchesfortheshortstringsthatmaximizesP(sjt),which(forxedt)isequivalentto
maximizingP(s)P(tjs).
Whilethisapproachexploitsonlysyntacticandlexicalinformation,(Jingand
McK-eown,2000)alsorelyoncohesioninformation,derivedfromworddistributioninatext:
phrases that are linked to a local context are kept, while phrases that have no such
linksaredropped.Anotherdierencebetweenthesetwomethodsistheextensiveuseof
domain-independentknowledge sources inthelatter. Forexample,alexiconis used to
identifywhich componentsof thesentenceareobligatoryto keepit grammatically
cor-rect. Thecorpusinthisapproachis usedto estimatethedegreeto whichthefragment
is extraneousandcanbeomittedfromasummary.Aphraseisremovedonlyifitisnot
grammaticallyobligatory,is notlinkedto alocalcontext, and hasareasonable
proba-bilityofbeingremovedbyhumans.Inadditionto reducingtheoriginalsentences,(Jing
and McKeown, 2000) use a number of manually compiled rules to aggregate reduced
sentences;forexample,reducedclausesmightbeconjoinedwith\and".
Sentencefusionexhibitssimilaritieswithcompressionalgorithmsinthewaysinwhich
it copes with the lack of semantic data in the generation process, relying on shallow
analysisof theinputand statisticsderivedfromacorpus.Clearly,thedierence inthe
natureofbothtasksandinthetypeofinputtheyexpect(singlesentenceversusmultiple
sentences)dictatestheuseofdierentmethods. Havingmultiplesentencesintheinput
posesnewchallenges|suchasaneedforsentencecomparison|butatthesametime
it opens up new possibilitiesfor generation. While theoutput of existingcompression
algorithmsisalwaysasubstringoftheoriginalsentence,sentencefusionmaygeneratea
newsentencewhichisnotasubstringofanyoftheinputsentences.Thisis achievedby
arrangingfragmentsofseveralinputsentencesintoonesentence.
Theonlyothertext-to-textgenerationapproachwithacapabilityofproducingnovel
utterances isthat ofPang,KnightandMarcu(2003).Theirmethodoperatesover
mul-tipleEnglishtranslationsofthesameforeignsentence,andisintendedtogeneratenovel
paraphrasesoftheinputsentences.Likesentencefusion,theirmethodalignsparsetrees
of the input sentences and then usesa languagemodel to linearizethederived lattice.
The main dierence betweenthe twomethods is inthe type of the alignment:our
al-gorithm performs local alignment, while the algorithm of (Pang, Knight, and Marcu,
2003)performsglobalalignment.Thedierencesinalignmentarecaused bydierences
in input: their method expects semanticallyequivalent sentences, while our algorithm
operates over sentences with only partial meaning overlap. The presence of deletions
and insertions ininput sentences makestheir alignmenta particularlynew signicant
challenge.
6. Conclusionsand FutureWork
In thispaper,wepresentedsentencefusion, anovelmethod fortext-to-textgeneration
which,givenasetofsimilarsentences,producesanewsentencecontainingthe
informa-tion commontomostsentences.Unliketraditionalgenerationmethods,sentencefusion
does not require an elaborate semantic representation of the input, but instead relies