in Graph Databases
Tomonobu Ozaki1and Takenao Ohkawa2
1 Organization of Advanced Science and Technology, Kobe University 2 Graduate School of Engineering, Kobe University
1-1 Rokkodai-cho, Nada, Kobe, 657-8501, Japan
{tozaki@cs., ohkawa@}kobe-u.ac.jp http://www25.cs.kobe-u.ac.jp/
Abstract. In this paper, we bring the concept of hyperclique pattern in transaction databases into the graph mining and consider the discovery of sets of highly-correlated subgraphs in graph-structured databases. To discover frequent hyperclique patterns in graph databases efficiently, a novel algorithm named HSG is proposed. By considering the generality ordering of subgraphs, HSG employs the depth-first/breadth-first search strategy with powerful pruning techniques based on the upper bound of h-confidence measure. The effectiveness of HSG is assessed through the experiments with real world datasets.
1
Introduction
Recently, the research area ofcorrelation mining, that extracts the underlying dependency among objects, attracts a big attention and extensive studies have been reported [25,23,7,15,12]. Among these researches on correlation mining, we focus on thehyperclique pattern discovery[26,27] in this paper.
While the most of researches aim at finding mutually dependent ‘pairs’ of ob-jects efficiently, a hyperclique pattern is a ‘set’ of highly-correlated items that has high value of an objective measure namedh-confidence[26,27]. The h-confidence measure of an itemset P = {i1,· · ·, im} is designed for capturing the strong
affinity relationship and is defined as follows. hconf(P) = min
l=1,···,m{conf(il→P\ {il})}=sup(P)/l=1max,···m{sup({il})}
where sup andconf are the conventional definitions of support and confidence in association rules[1], respectively. A hyperclique pattern P states that the occurrence of an itemil∈P in a transaction implies the occurrence of all other
items P \ {il} in the same transaction with probability at least hconf(P). In
addition, the cosine similarity between any pair of items in P is greater than or equals tohconf(P)[27]. By these features, hyperclique pattern discovery has been applied successfully to some real world problems [9,18,24].
While hyperclique pattern discovery aims at finding valuable patterns in trans-action databases,structured datais becoming increasingly abundant in many ap-plication domains recently. Although we can easily expect to get a more powerful T. Washio et al. (Eds.): PAKDD 2008, LNAI 5012, pp. 272–283, 2008.
c
tool for structured data by introducing correlation mining, the most of current research on correlation mining are designed for transaction databases and lit-tle attention is paid to mining correlations from structured data. Motivated by these background, in this paper, we tackle the problem of hyperclique pattern discovery in the context of graph mining[21,22] and discuss the effectiveness of the correlation mining in structured domains.
The basic idea of hyperclique patterns in graph databases is simple: Instead of items, we employ subgraphs (i.e.patterns) as building blocks of hyperclique patterns. While this simple replacement might seem to be trivial, it gives us new expectations and difficulties. On one hand, the proposed framework extracts sets of mutually dependent or affinitive patterns in graph databases. Because each pattern gives another view to other patterns in the same set, we can expect to obtain new findings and precise insights. On the other hand, as easily imagined, hyperclique pattern discovery in graph databases is much harder than the tradi-tional tasks because there are exponentially many subgraphs in graph databases and any combinations of those subgraphs are to be potentially candidates. In order to alleviate this combinatorial explosion and to discover hyperclique pat-terns efficiently, in this paper, we propose a novel algorithm named HSG. HSG reduces the search space effectively by taking into account thegenerality ordering
of hyperclique patterns.
The main contributions of this paper are briefly summarized as follows. First, we formulate the new problem of hyperclique pattern discovery in graph databases. Second, we propose a novel algorithm named HSG for solving this problem effi-ciently. Third, through the experiments with real world datasets, we assess the effectiveness of our proposal.
This paper is organized as follows. In section2, after introducing basic no-tations, we formulate the problem of hyperclique pattern discovery in graph databases. In section3, the proposed algorithm HSG is explained in detail. After mentioned related work in section4, we show the results of the experiments in section5. Finally, we conclude the paper and describe future work in section6.
2
Preliminaries
LetL be a finite set of labels. Alabeled graph g = (Vg, Eg, lg) on L consists of
a vertex setVg, an edge set Eg and a labeling function lg :Vg∪Eg → Lthat
maps each vertex or edge to a label inL. Hereafter, we refer labeled graph as graph simply.
Each graph can be represented in so calledcode word [3,28], that is a unique string which consists of a series of edges associated with connection information. Especially, we employ canonical code word[3,28] which is minimal code word among isomorphic graphs to represent each graph. The lexicographic order on code word gives a total order on graphs. Given two graphsg and g, g <lex g denotes that the code word ofgislexicographically earlierthan that ofg. If the code word ofg is a prefix of that ofg, we denote it as g <pfxg. Examples of graphs and those code words are shown in Fig.1.
g0 g1 g2 g3 g4 g5 A B A B A B C A B C A B D A B D A B C D A B C D B C B C B C C D B C C D
(0,1,A,–,B) (0,1,A,–,B) (0,1,A,–,B) (0,1,A,–,B) (0,1,B,–,C) (0,1,B,–,C) (0,2,A,–,C) (1,2,B,–,D) (1,2,B,–,D) (1,2,B,–,C) (2,3,D,–,C) (2,3,C,–,D) (3,0,C,–,A)
(All edge labels are assumed to be ‘–’)
For example, the re-lations below hold.
⎧ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎨ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎩ g0<lexg4 g1<lexg2 g3<lexg5 g0<pfxg1 g2<pfxg3 g4<pfxg5 ⎫ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎬ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎭
Fig. 1.Examples of Labeled Graphs and those Code Words
A graphg= (Vg, Eg, lg) is called asubgraphof another graphg= (Vg, Eg, lg),
denoted asg g, if there exists an injective function f : Vg → Vg such that
∀u ∈ Vg lg(u) = lg(f(u)) and∀(u, v) ∈ Eg (f(u), f(v)) ∈ Eg ∧ lg(u, v) =
lg(f(u), f(v)). Ifgg, then we say thatgis more general thang. Note that, if
g <pfxg holds, thenggalso holds[3,28].
Based on the relationship of subgraphs, we consider thejoint occurrenceof a set of subgraphs in a graph. The most intuitive definition is as follows: Given a set of subgraphsGand a graphg, if∀gi∈G gig holds, thenGis considered
as to be occurred in g. However, this simple definition might not be suitable for the hyperclique patterns of subgraphs because large number of uninteresting combinations of subgraphs having large overlaps in a graph will be obtained. Therefore, we introduce another definition in consideration ofedge-disjointness
to suppress the redundancy. Given a set ofmsubgraphsG={g1,· · ·, gm}and a
graphg,Gis called a set ofk-edge disjoint subgraphsofg, denoted asG≤kg, if
there exists the following set of injective functions{fi:Vgi →Vg|i= 1,· · ·, m}:
(1)∀gi∈G gig
(2) mi=1 |Egi| − |
i=1,···,m{(fi(u), fi(v))|(u, v)∈Egi} | ≤k
The second condition gives the constraint on the edge overlaps. By this con-straint, the redundant combinations can be expected to be controlled. For ex-ample in Fig.1, while both g1 g3 and g2 ≺g3 hold, ifk is set to be 0, then {g1, g2} ≤0g3does not hold because of an overlap of edge ‘A-B’ ing3.
We introduce the definitions ofsupportandh-confidencefor a set of subgraphs. LetD={d1,· · ·, dN} be a database ofN graphs. Thesupportandh-confidence
of a set of subgraphG={g1,· · ·, gm} inD are defined as follows:
supD(G) = d∈Dσ(G, d)/N where σ(G, d) =
1 (G≤k d)
0 (otherwise) hconfD(G) =supD(G)/ max
i=1,···,m{supD({gi})}
Based on the above preparation, we formulate the problem of “mining frequent hyperclique patterns in graph databases” (HSG miningin short) below. Given a databaseD of labeled graphs, a positive number calledminimum supportσ(0<
σ ≤ 1) and a positive number called minimum h-confidence hc(0 ≤ hc ≤ 1),
then the problem of HSG mining is to find allfrequent hyperclique patterns of subgraphsGinDsuch thatsupD(G)≥σ,hconfD(G)≥hcand the cardinality of
Gis more than one. Note that, because we are interested in the sets of mutually dependent subgraphs, the hyperclique patterns of cardinality one are excluded.
3
Mining Hyperclique Patterns of Subgraphs
In this section, we propose an algorithm named HSG for mining frequent hy-perclique patterns in graph databases. Before describing the concrete algorithm, we show some properties of hyperclique patterns and a data structure calleda conditional prefix tree of hyperclique patterns, that are utilized for the effective pruning based on thegenerality orderingof hyperclique patterns.
3.1 Properties of Hyperclique Patterns
Given two sets G1 and G2 of subgraphs, if there exists an injective function φ :G1 →G2 which satisfies ∀g ∈ G1 g φ(g) ∈G2, then we say that G1 is
more general than G2 and denote it asG1G2.
As shown formally below, given a set of subgraphsG1, there are two kinds ofspecializations to obtain a more specific set of subgraphs G2 from G1. Note that, while only first kind of specialization is considered in item set mining, the second one also plays the key role in HSG mining.
(1) Specialization by addition G2 is obtained by adding a new subgraphg toG1,i.e. G2=G1∪ {g}
(2) Specialization by replacement G2 is obtained by replacing a subgraph g∈G1to a more specific subgraphg (g),i.e.G2= (G1\ {g})∪ {g}. The following two lemmas hold in hyperclique patterns of subgraphs based on the generality ordering introduced above.
Lemma 1 (Anti-monotone property of support value). Given two sets
G1 andG2 of subgraphs, if G1G2, thensupD(G1)≥supD(G2)holds.
Proof. Obvious from the definition of support value.
By this lemma, if a set of subgraphsG1 does not satisfy the minimum support, then all sets of subgraphsG2 s.t. G1 G2 can be eliminated safely from the candidate of frequent hyperclique patterns.
Lemma 2 (Upper bound of h-confidence). Given two sets of subgraphs
G1=GA∪GB s.t.GA=∅, GA∩GB =∅andG2=GA∪GB s.t. GA∩GB =∅,
ifGBGB, then the following inequality holds.
up(G1, GA) =supD(G1)/max
Proof. SinceGA⊆G2, max
g∈GA{
supD({g})} ≤max g∈G2{
supD({g})}holds. By lemma1,
supD(G1) ≥ supD(G2) also holds. Therefore, supD(G1)/max
g∈GA{
supD({g})} ≥
supD(G2)/max
g∈G2{supD({g
})} =hconfD(G2) holds.
This lemma gives the upper bound of h-confidence. Ifup(G1, GA) does not satisfy
the minimum h-confidence hc, then any set of subgraphs G2 = GA∪GB s.t.
GB GB must not satisfy hc. Furthermore, this lemma also shows the
anti-monotone property of h-confidence with respect to the specialization by addition. By definition,hconfD(G1) =up(G1, G1) holds. Thus, ifhconfD(G1)< hc, then
no set of subgraphs obtained by adding some subgraphs toG1 can satisfyhc.
3.2 A Conditional Prefix Tree of Hyperclique Patterns
Here, we consider the enumeration of hyperclique patterns in graph databases. According to the reverse search[2], the repeated enumeration of the same pattern can be avoided by generating each pattern from its unique parent. In case of hyperclique patterns of subgraphs, the parent can be uniquely defined by using the total order of graphs formed by code word. The parent of a set of subgraphsG, denoted asp(G), is a set obtained by removing the smallest element with respect to<lexfrom G,i.e.p(G) =G\ {g∈G| ∃g∈G g<lex g}.
Because of the anti-monotone property of hyperclique patterns with respect to the specialization by addition shown in lemma1 and 2, all subsets of a frequent hyperclique pattern must be also frequent hyperclique patterns. Furthermore, a hyperclique pattern should be enumerated via its parent to avoid the repeated enumerations. Therefore, in our strategy, a new hyperclique patternG will be generated by joining two hyperclique patternsG1=G∪{g1}andG2=G∪{g2} asG =G∪ {g1} ∪ {g2}=G1∪ {g2}. Note that “the enumeration via parent” can be naturally realized through the join operation.
Since a hyperclique pattern will be generated by joining two hyperclique pat-terns having the same parent, it is convenient to treat all hyperclique patpat-terns which have the same parent as an unit. Furthermore, in order to effectively uti-lize the pruning based on the generality ordering, hyperclique patterns in this unit should be organized in consideration of the generality ordering. Motivated by these backgrounds, we propose a tree-shaped data structure called condi-tional prefix tree of hyperclique patterns, on which our algorithm HSG works, for storing hyperclique patterns which have the same parent in common.
A conditional prefix tree of hyperclique patternsCP TG= (VG, EG, BG, root)
is an ordered tree and it stores hyperclique patterns which have a hyperclique patternGas those parent. The root noderootis a dummy node. Each nodevin VG, except forroot, corresponds to a hyperclique patternG∪ {g(v)}and has an
graphg(v).EG⊆VG×VG andBG⊆VG×VG represent the set of parent-child
and sibling relationships, respectively. These are formally defined as follows.
EG={(v1, v2)|g(v1)<pfxg(v2), ∃v∈VG[g(v1)<pfxg(v)∧g(v)<pfxg(v2) ]}
∪ {(root, v3)| ∃v∈VG[g(v)<pfxg(v3) ]}
G∪ {g0} G∪ {g1} C D C C D C AA BB C D C C D C A B C A B C G∪ {g2} G∪ {g3} C D C C D C A B D A B D C D C C D C A B C D A B C D G∪ {g4} G∪ {g5} C D C C D C BB CC C D C C D C B C C D B C C D =⇒ A B A B C A B D B C A B C D B C C D g0 g1 g2 g3 g4 g5 C D C parent (condition) G A B A B A B C A B C A B D A B D B C B C A B C D A B C D B C C D B C C D g0 g1 g2 g3 g4 g5 C D C C D C parent (condition) G
Fig. 2.An Example of Conditional Prefix Tree
Intuitively speaking,v1is the parent ofv2if the code word ofg(v1) is the longest prefix of that ofg(v2). Ifv3has no such parent, thenrootis assigned as the parent ofv3. Note that,∀(g1, g2)∈EGg1g2holds. The children of a node are ordered in the lexicographic order<lex. An example of conditional prefix tree is shown in Fig.2. This tree is constructed from six hyperclique patterns that have{G} as parent in common.
3.3 HSG: A Hyperclique Pattern Miner in Graph Databases
In this subsection, we propose an algorithm HSG and explain it in detail. The algorithm HSG for mining frequent hyperclique patterns in graph data-bases is shown in Fig.3. In the following explanation, we use the notations below for the sake of simplicity: Gx = G∪ {g(gx)}, Gx = G∪ {g(gx)} and Gx,y =
G∪ {g(gx), g(gy)}where we assumeg(gx)≺g(gx).
As an input, HSG takes an unconditional prefix tree CP T∅ of hyperclique patterns that stores frequent hyperclique patterns of cardinality one,i.e.frequent subgraphs potentially obtained by the conventional graph miners[28,11,10,16]. Then, HSG calls a procedure LoopV withTa =Tb=CP T∅ (line1 in HSG).
HSG consists of two main procedures LoopV and LoopH which realize the join of elements in a conditional prefix tree mutually while considering the generality ordering. LoopV traverses a treeTa in preorder by using recursive call (line5 in
LoopV). By using the preorder traversal, elements inTa will be considered in the
order of<lex. During the traversal, LoopV calls LoopH withG,ga andTb(line3
in LoopV). LoopH also traverses a treeTbin preorder (line16 in LoopH). SinceTa
andTb refer to the same tree at the beginning, if no pruning is applied, all pairs
of elements in a conditional prefix tree will be considered. Note that, no repeated enumeration occurs due to the check ofg(ga)≤lexg(gb) (line2 in LoopH).
During the recursive calls, LoopH constructs two new conditional prefix trees N TaandN Tbwhich form the search spaces afterwards.N Tais a prefix tree under
the conditionGa and it is used as an input for discovering hyperclique patterns
whose parent isGa,b (line4 in LoopV).N Ta will be constructed by adding a new
Algorithm HSG(CP T∅) 1: LoopV(∅,CP T∅,CP T∅) Procedure LoopV(G,Ta,Tb)
1:for eachga∈Ta’s children //G∪ {g(ga)}is a frequent hyperclique pattern 2: NTa:= new root node,NTb := new root node
3: LoopH(G,ga,Tb,NTa,NTb) //specializeG∪ {g(ga)}by addition 4: LoopV(G∪ {g(ga)},NTa,NTa) //search on new conditional prefix tree 5: LoopV(G,ga,NTb) //preorder traversal inTa
//specializeG∪ {g(ga)}by replacement Procedure LoopH(G,ga,Tb,NTa,NTb)
1:for eachgb∈Tb’s children //checkG∪ {g(ga), g(gb)}and prune by it 2: if(g(ga)≤lexg(gb))then
3: addgbto the last ofNTb’s children 4: continue
5: if(supD(G∪ {g(ga), g(gb)})< σ)then continue //pruning (1)
6: if(G=∅ ∧up(G∪ {g(ga), g(gb)}, G)< hc)then continue //pruning (2) 7: Na:=NTa
8: if(hconfD(G∪ {g(ga), g(gb)})≥hc)then //pruning (3)
9: ouput(G∪ {g(ga), g(gb)}) //output of a frequent hyperclique pattern 10: C := new node, g(C) :=g(gb), addC to the last ofNa’s children 11: Na :=C //replacement ofNa
12: Nb:= new node, g(Nb) :=g(gb), addNbto the last ofNTb’s children 13: if(up(G∪ {g(ga), g(gb)}, G∪ {g(ga)})< hc)then //pruning (4) 14: for eachgc∈gb’s children addgcto the last ofNb’s children 15: else
16: LoopH(G,ga,gb,Na,Nb) //preorder traversal inTb
// specializeG∪ {g(ga), g(gb)}by replacement
Fig. 3.An algorithm HSG of mining hyperclique patterns in graph databases
prefix tree under the conditionG, on which hyperclique patterns havingGa as
parents will be mined (line5 in LoopV). Conceptually,N Tb will be obtained by
pruning some branches inTb.
Four prunings will be applied in LoopH. They are achieved partially by “not adding new vertices toN Ta and N Tb”. The first pruning is based on the
anti-monotone property of support value in lemma1 (line5 in LoopH). If the support of Ga,b is less than the minimum support, then all patterns which are more specific
thanGa,b must not satisfy the minimum support. Thus, we ignore the following
specializations of Ga,b by skipping the loop of line1 in LoopH: (1) Ga,b by not calling LoopH (line16 in LoopH), (2) patterns obtained by “specialization of Ga,bby addition” by not updatingN Ta, and (3)Ga,bandGa,b by not updating
N Tb. The second pruning is derived from the upper bound of h-confidence in
lemma2 (line6 in LoopH). As similar to the first pruning, all specializations ofGa,b will be ignored in the same way. The third pruning is by anti-monotone
(line8 in LoopH). IfGa,b dose not satisfy minimum h-confidence, the search for
patterns havingGa,bas parent will be avoided by not addingGa,b toN Ta. The
fourth pruning is based on the upper bound of h-confidence in lemma2 (line13 in LoopH). The search forGa,b can be avoided by not calling LoopH. Note that,
Ga,b as well as Ga,b must be considered. Therefore,N Tb has to be updated.
This is achieved through the update ofNb.
As shown above, HSG makes the best use of the pruning based on the special-izations by using the conditional prefix trees. For HSG, the following theorem holds.
Theorem 1. Given an unconditional prefix tree having all frequent subgraphs, HSG discovers all frequent hyperclique patterns without any duplication.
Proof. Derived from the complete enumeration procedure by the double preorder traversals and the safety prunings guaranteed by lemma1 and 2. Although HSG can discover all frequent hyperclique patterns, the obtained set of hyperclique patterns may contain some redundancy. Since each frequent subgraph in the unconditional prefix tree is treated as an item, if some sub-graphs which are equivalent in some senses are contained in the tree, they cause the redundancy. To eliminate obviously redundant patterns, we believe that the frequent subgraphs included in the unconditional prefix tree should be limited to the representatives such as closed subgraphs (a graph gc s.t.
∃ggc g ∧supD(gc) = supD(g)) or minimal subgraphs (a graph gm s.t.
∃gg gm∧supD(gm) =supD(g)). In particular, minimal subgraphs might
be more suitable if the edge-disjointness is considered in the joint occurrence. Although, to the best of our knowledge, the method which finds minimal sub-graphs directly has not been proposed yet, those subsub-graphs can be obtained by some post-processing of the conventional graph miners[28,11,10,16].
4
Related Work
The concept of HSG mining is inspired by the hyperclique pattern discovery in transaction databases [26,27].
The methods of mining correlated pairs of items have been proposed[25,23,7]. Furthermore, correlated pattern mining based on a pattern-growth methodology in transaction databases has been proposed[15]. Compared with these methods, HSG is different in the point of finding sets of affinitive structured patterns.
On the correlation mining in graph databases, a new problem named Corre-lated Graph Search has been proposed recently[12]. In this problem, Pearson’s correlation coefficient[20] is employed as correlation measure and all correlated subgraphs with a query graph will be discovered. This framework is greatly dif-ferent from our proposal because the different measure is employed and only subgraphs correlated with agivenquery are considered.
Pattern teamproposed in [13] is a set of patterns that optimizes some quality measure. The discovery of pattern team may look similar to the HSG mining
Table 1.Statistics of Datasets
|D| Va Ea |V| |E|Description
D1 1000 11.6 20.5 20 20 A synthetic dataset generated by graph generator[5]
PTE 340 27.0 27.4 66 4 The Predictive Toxicology Evaluation Challenge[8]
DTP CM 877 29.1 31.5 12 4 The DTP AIDS Antiviral Screen dataset[4]
|D|: # of graphs in datasets. Va, Ea: average number of vertices and edges per graph. |V|,|E|: # of distinct labels of vertices and edges.
because both find the set or combination of patterns. However, pattern team discovery is done by selecting patterns from the given set. In addition, pattern team usually consists of a set of mutually dissimilar and independent patterns for optimizing the quality measure. Similar to the pattern team in some senses, the concept of α-orthogonal patterns in graph databases has been proposed recently[6]. In this framework, a set of frequent maximal subgraphs that are mutually dissimilar with each other will be obtained by employing a randomized search. While treating a set of subgraphs, this framework is also different from the HSG mining because HSG discovers the complete sets of affinitive subgraphs. From the aspect of finding similar patterns,redescription mining[19,17,29] is closely related to the HSG mining. In redescription mining, patterns consist of any combinations of conjunction, disjunction and negation of items and pairs of patterns that occur in almost the same transactions will be discovered. While this framework is very general, neither the application to the structured data nor precise algorithms which use the generality ordering have been proposed yet.
5
Experimental Evaluation
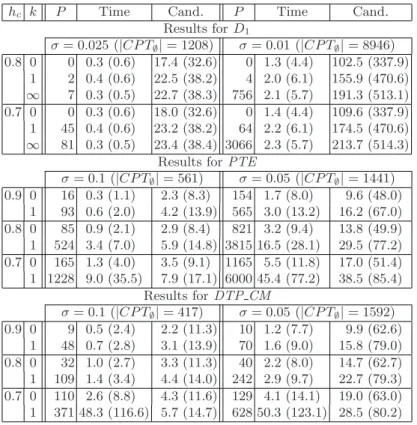
To assess the effectiveness of the proposed algorithm, we implement HSG in Java and conduct some experiments with the datasets shown in Table1 on a PC (CPU: Intel(R) Core2Quad 2.4GHz) with 4Gbytes of main memory running Windows XP. Furthermore, another miner pHSG, that is “HSG without pruning (2) and (4)”, is also prepared to demonstrate the effects of pruning related to the “specialization by replacement”. In the experiments, we construct the un-conditional prefix treesCP T∅ by using minimal subgraphs only. Experimental results are shown in Table2.
The obtained number of hyperclique patterns decreases when the value ofk is reduced. Furthermore, though not shown in Table2, about 231 million and 17 thousand of hyperclique patterns were obtained if we setσ= 0.1, hc = 0.9 and
k=∞inPTEandDTP CM, respectively. This means that the consideration of edge-disjointness succeeds in suppressing the generation of redundant patterns. In all cases, pHSG discovers all frequent hyperclique patterns in a reasonable time though at leastO(|CP T∅|2) of candidates will be generated if no pruning applied. Thus, it is understood that the pruning by minimum support is effective enough. Note that, this pruning eliminates the patterns obtained by the “special-ization by addition” as well as the “special“special-ization by replacement”. Compared
Table 2.Experimental Results
hc k P Time Cand. P Time Cand.
Results forD1 σ= 0.025 (|CP T∅|= 1208) σ= 0.01 (|CP T∅|= 8946) 0.8 0 0 0.3 (0.6) 17.4 (32.6) 0 1.3 (4.4) 102.5 (337.9) 1 2 0.4 (0.6) 22.5 (38.2) 4 2.0 (6.1) 155.9 (470.6) ∞ 7 0.3 (0.5) 22.7 (38.3) 756 2.1 (5.7) 191.3 (513.1) 0.7 0 0 0.3 (0.6) 18.0 (32.6) 0 1.4 (4.4) 109.6 (337.9) 1 45 0.4 (0.6) 23.2 (38.2) 64 2.2 (6.1) 174.5 (470.6) ∞ 81 0.3 (0.5) 23.4 (38.4) 3066 2.3 (5.7) 213.7 (514.3) Results forPTE
σ= 0.1 (|CP T∅|= 561) σ= 0.05 (|CP T∅|= 1441) 0.9 0 16 0.3 (1.1) 2.3 (8.3) 154 1.7 (8.0) 9.6 (48.0) 1 93 0.6 (2.0) 4.2 (13.9) 565 3.0 (13.2) 16.2 (67.0) 0.8 0 85 0.9 (2.1) 2.9 (8.4) 821 3.2 (9.4) 13.8 (49.9) 1 524 3.4 (7.0) 5.9 (14.8) 3815 16.5 (28.1) 29.5 (77.2) 0.7 0 165 1.3 (4.0) 3.5 (9.1) 1165 5.5 (11.8) 17.0 (51.4) 1 1228 9.0 (35.5) 7.9 (17.1) 6000 45.4 (77.2) 38.5 (85.4) Results forDTP CM σ= 0.1 (|CP T∅|= 417) σ= 0.05 (|CP T∅|= 1592) 0.9 0 9 0.5 (2.4) 2.2 (11.3) 10 1.2 (7.7) 9.9 (62.6) 1 48 0.7 (2.8) 3.1 (13.9) 70 1.6 (9.0) 15.8 (79.0) 0.8 0 32 1.0 (2.7) 3.3 (11.3) 40 2.2 (8.0) 14.7 (62.7) 1 109 1.4 (3.4) 4.4 (14.0) 242 2.9 (9.7) 22.7 (79.3) 0.7 0 110 2.6 (8.8) 4.3 (11.6) 129 4.1 (14.1) 19.0 (63.0) 1 371 48.3 (116.6) 5.7 (14.7) 628 50.3 (123.1) 28.5 (80.2)
k: # of the edge overlaps permitted in the joint occurrence (∞means no restriction).
P: # of obtained hyperclique patterns. Time: execution time afterCP T∅ is given (in second). Cand.: # of candidates enumerated during the search (in thousand). Numbers in parentheses in Time and Cand. are for pHSG.
with pHSG, the execution time of HSG for real world problems decreases to 16.0% in the maximum and to 33.9% on the average. The number of candidate patterns is also reduced to 15.9% in the maximum and to 30.8% on the average. It is also observed that HSG runs about two times faster than pHSG in the synthetic dataset on the average. These reductions are the strong evidences to show the effectiveness of the pruning based on the generality ordering, especially on the “specialization by replacement”.
6
Conclusion
In this paper, we formulate the problem of hyperclique pattern discovery in graph databases. To solve this problem efficiently, a novel algorithm named HSG is pro-posed that utilizes the depth-first/breadth-first search with the effective pruning based on the generality ordering. We believe that HSG can mine hyperclique
patterns efficiently not only in other types of structured data but also in trans-action databases with the conceptual hierarchy because the conditional prefix trees, on which HSG works, can be constructed naturally from these kinds of datasets.
For future work, the theoretical analysis of the proposed algorithm and fur-ther experiments with large-scale datasets are necessary. In addition, some more efficient mechanism is required for computing support value of a set of edge dis-joint subgraphs. For this objective, we plan to employ the idea of support value computation of edge disjoint subgraphs in a large graph[14]. We also plan to apply the proposed algorithm to top-k correlated pattern discovery as well as to redescription mining in structured databases.
References
1. Agrawal, R., Srikant, R.: Fast algorithms for mining association rules in large databases. In: Proc. of 20th International Conference on Very Large Data Bases (VLDB 1994), pp. 487–499 (1994)
2. Avis, D., Fukuda, K.: Reverse search for enumeration. Discrete Applied Mathe-matics 65(1-3), 21–46 (1996)
3. Borgelt, C.: On canonical forms for frequent graph mining. In: Working Notes of the 3rd International ECML/PKDD- Workshop on Mining Graphs, Trees and Sequences (MGTS 2005), pp. 1–12 (2005)
4. Borgelt, C., Berthold, M.R.: Mining molecular fragments: Finding relevant sub-structures of molecules. In: Proc. of the 2002 IEEE International Conference on Data Mining (ICDM 2002), pp. 51–58 (2002)
5. Cheng, J., Ke, Y., Ng, W.: Graphgen: A graph synthetic generator (2006), http://www.cse.ust.hk/graphgen/
6. Hasan, M., Chaoji, V., Salem, S., Besson, J., Zaki, M.: ORIGAMI: Mining represen-tative orthogonal grap patterns. In: Proc. of the 7th IEEE International Conference on Data Mining (2007)
7. He, Z., Xu, X., Deng, S.: Mining top-k strongly correlated item pairs without minimum correlation threshold. International Journal of Knowledge-based and In-telligent Engineering Systems 10(2), 105–112 (2006)
8. Helma, C., King, R.D., Kramer, S., Srinivasan, A.: The predictive toxicology chal-lenge 2000-2001. Bioinformatics 17(1), 107–108 (2001)
9. Hu, T., Xiong, H., Sung, S.Y.: Co-preserving patterns in bipartite partitioning for topic identification. In: Proc. of the 7th SIAM International Conference on Data Mining, pp. 509–514 (2007)
10. Huan, J., Wang, W., Prins, J.: Efficient mining of frequent subgraphs in the pres-ence of isomorphism. In: Proc. of the 3rd IEEE International Conferpres-ence on Data Mining, pp. 549–552 (2003)
11. Inokuchi, A., Washio, T., Motoda, H.: Complete mining of frequent patterns from graphs: Mining graph data. Machine Learning 50, 321–354 (2003)
12. Ke, Y., Cheng, J., Ng, W.: Correlation search in graph databases. In: Proc. of the 13th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD 2007), pp. 390–399 (2007)
13. Knobbe, A.J., Ho, E.K.Y.: Pattern teams. In: F¨urnkranz, J., Scheffer, T., Spiliopoulou, M. (eds.) PKDD 2006. LNCS (LNAI), vol. 4213, pp. 577–584. Springer, Heidelberg (2006)
14. Kuramochi, M., Karypis, G.: Finding Frequent Patterns in a Large Sparse Graph. Data Mining and Knowledge Discovery 11(3), 213–321 (2005)
15. Lee, Y.-K., Kim, W.-Y., Cai, Y.D., Han, J.: Comine: Efficient mining of correlated patterns. In: Proc. of the 3rd IEEE International Conference on Data Mining, pp. 581–584 (2003)
16. Nijssen, S., Kok, J.: A quickstart in frequent structure mining can make a differ-ence. In: Proc. of the 10th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD 2004), pp. 647–652 (2004)
17. Parida, L., Ramakrishnan, N.: Redescription mining: Structure theory and algo-rithms. In: Proc. of the 20th National Conference on Artificial Intelligence and the 17th Innovative Applications of Artificial Intelligence Conference, pp. 837–844 (2005)
18. Qian, T., Xiong, H., Wang, Y., Chen, E.: On the strength of hyperclique patterns for text categorization. Information Sciences 177(19), 4040–4058 (2007)
19. Ramakrishnan, N., Kumar, D., Mishra, B., Potts, M., Helm, R.F.: Turning cartwheels: an alternating algorithm for mining redescriptions. In: Proc. of the 10th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 266–275 (2004)
20. Tan, P.-N., Kumar, V., Srivastava, J.: Selecting the right interestingness measure for association patterns. In: Proc. of the 8th ACM SIGKDD International Confer-ence on Knowledge Discovery and Data Mining, pp. 32–41. ACM Press, New York (2002)
21. Washio, T., Motoda, H.: State of the art of graph-based data mining. SIGKDD Explorations 5(1), 59–68 (2003)
22. Washio, T., Kok, J.N., De Raedt, L. (eds.): Advances in Mining Graphs, Trees and Sequences. IOS Press, Amsterdam (2005)
23. Xiong, H., Brodie, M., Ma, S.: Top-cop: Mining top-k strongly correlated pairs in large databases. In: Proc. of the 6th International Conference on Data Mining, pp. 1162–1166 (2006)
24. Xiong, H., He, X., Ding, C., Zhang, Y., Kumar, V., Holbrook, S.R.: Identification of functional modules in protein complexes via hyperclique pattern discovery. In: Proc. of the Pacific Symposium on Biocomputing, pp. 221–232 (2005)
25. Xiong, H., Shekhar, S., Tan, P.-N., Kumar, V.: Exploiting a support-based up-per bound of pearson’s correlation coefficient for efficiently identifying strongly correlated pairs. In: Proc. of the 10th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 334–343. ACM Press, New York (2004)
26. Xiong, H., Tan, P.-N., Kumar, V.: Mining strong affinity association patterns in data sets with skewed support distribution. In: Proc. of the 3rd IEEE International Conference on Data Mining (ICDM 2003), pp. 387–394 (2003)
27. Xiong, H., Tan, P.-N., Kumar, V.: Hyperclique pattern discovery. Data Mining and Knowledge Discovery 13(2), 219–242 (2006)
28. Yan, X., Han, J.: gspan: Graph-based substructure pattern mining. In: Proc. of the 2002 IEEE International Conference on Data Mining (ICDM 2002), pp. 721–724 (2002)
29. Zaki, M.J., Ramakrishnan, N.: Reasoning about sets using redescription mining. In: Proceeding of the 11th ACM SIGKDD International Conference on Knowledge Discovery in Data Mining, pp. 364–373 (2005)