A Novel Distributed Variant of Stochastic Gradient
Descent and Its Optimization
Yi-qi WANG, Ya-wei ZHAO, Zhan SHI and Jian-ping YIN
College of Computer, National University of Defense Technology, ChangSha, P.R. China E-mail:[email protected], [email protected],
[email protected], [email protected]
Keywords: SGD; variance reduction; large-scale machine learning.
Abstract. In the age of big data, large-scale learning problems become increasingly significant. Distributed machine learning algorithms thus draw a lot of interest, particularly those based on Stochastic Gradient Descent (SGD) with variance reduction technique. In this paper, we propose and implement a distributed programming strategy for a newly developed variance-reducing SGD-based algorithm, and analyze its performance with various parameter. Moreover, a new SGD-SGD-based algorithm named BATCHVR is introduced, which computes the full-gradients required by SGD in each stage using batches in an incremental manner. Experiments on the HPC cluster, i.e. TH-1A demonstrate the effectiveness of the distributed strategy and the excellent performance of the proposed algorithm.
Introduction
In many machine learning tasks, we need to the solve the following optimization problem shown in equation (1)
min , : 1 ∑ (1) where represents the loss value on sample i, and w denotes parameter in this machine learning problem and n is the size of training set. Gradient Decent(GD) is a common method to solve this optimization problem. However, it requires to compute gradients for all the samples, causing large computational expense. Thus, Stochastic Gradient Decent is proposed, which only uses one random sample to compute an estimated value. But here comes a new challenge. SGD brings variation to the algorithm due to randomness, which impacts the convergence of the objective value. In order to alleviate this negative effect, many SGD-based algorithms with variation reduction are proposed, like SAG(Roux, Schmidt, and Bach 2012), SVRG(Johnson and Zhang 2013), SDCA (Shalev-Shwartz and Zhang 2013) and SAGA (Defazio, Bach, and Lacoste-Julien 2014). SVRG is the most popular one among them because of its simplicity and promising performance. There are many studies[4],[5],[6],[7] aiming to parallel SVRG with multiple threads in a node. In 2016, Ruiliang Zhang proposed a distributed hybrid SGD-based algorithm, which improves the algorithm scalability. However, the specific implementation is not provided. Moreover, its performance extremely relies on an extra parameter, i.e., θ, and it lacks the thorough analysis. In our work, we propose a specific programming strategy based on the newly proposed algorithm and implement it on the HPC cluster TH-1A, and we analyze how the key parameter θ in this algorithm affects the convergence performance. Furthermore, another weakness of SVRG is that it requires gradient calculations for the entire training set in every stage, which is time-consuming. In this paper, we propose an advanced SVRG-based algorithm, BATCHVR, which uses an incremental number of samples to compute an estimate of the whole gradients. In our experiments, BATCHVR outperforms the new algorithm.
Related Work
[image:2.612.133.481.215.315.2]With the proliferation of large-scale learning problem, there exist incremental interests in the paralleling machine learning algorithms, especially those SGD-based algorithms. Recently, Ruiliang Zhang, Shuai Zheng and James T.Kwok have proposed a hybrid distributed variance-reducing SGD-based algorithm, which combines the merits of Delayed Proximal Gradient(DPG) and Stochastic Variance Reduced Gradient(SVRG). The algorithm details are demonstrated in the following table. However, a specific programming strategy has not been provided and the effect of the key parameter θ in the algorithm, which tunes the proportion of SVRG and DPG, remains to be explored.
Table 1. the hybrid SGD-based algorithm proposed by Ruiliang Zhang et al.
Lately, Shah et al. (2016) have proposed CHEAPSVRG which uses a random part of samples, instead of the whole training set, to compute an estimate value of the full-gradients in every stage of SVRG. However, since the size of the random part used is fixed, the variation between the estimate and the real value remains unchanged, which might impair the convergence of the objective value in some cases.
Distributed Programming Strategy with MPI
There are three kinds of processes, namely scheduler, server and worker. In our implementation, scheduler and server have only one instance, while worker have P instances. The scheduler process functions as a global task-issuer, which records time and issues various tasks to different processes according to the current time. We divide the whole training set into P disjoints, each of which read by a worker process. worker processes compute gradients and local objective values with different training disjoint, and push the results to server process.
Scheduler
The scheduler process functions as task issuer and global clock by sending the current timestamp periodically to other process per unit time. There are two kinds of tasks, update task and evaluation task. The scheduler process runs in stages. It first issues m update tasks sequentially to worker process one by one, and then issue an evaluation task to all the worker processes to compute the current objective value and the global gradients. If the current objective value is less than the threshold we set in advance, the scheduler process will stop itself, otherwise it will keep issuing tasks.
Parameters: learning rate 0, update frequency m 0Initialize:
For s 1,2, …
, ∑ ,
For t 1,2, …,m, choose randomly,
, update
1
Table 2. the scheduler process.
Server
[image:3.612.148.467.317.700.2]The server process is supposed to finish four assignments, receiving parameter-request from worker processes, deciding whether the parameter-replying requirement is met and sending parameters to the corresponding process, receiving the gradients computed by worker processes and update the global gradients, and receiving objective value to decide whether to stop. In order to execute the four assignments simultaneously, the server process gives rise to four threads dealing with the corresponding assignment.
Table 3. Request-receiver thread of the server.
Table 4. Update-computing thread of the server.
Table 5. Objective value-receiver thread of the server.
Table 6. Request-handler thread of the server.
While objective value > threshold if parameter request list is not empty
for each request with timestamp t in the list if (t%(m+1)!=0) //update task
if all update tasks with timestamp less than t τ have finished
MPI_Send(parameters, worker ) remove request from list
else //evaluation task
if all update tasks with timestamp less than t have finished MPI_Send(parameters, worker )
remove request from list
else sleep for a while
While objective value > threshold
MPI_Receive(objective value, worker 1)
While objective value > threshold wait for update task
if MPI_Receive(timestamp_t, worker ) MPI_Receive( , and ,, worker )
update parameters with w 1 , ,
While objective value > threshold MPI_Receive(timestamp_t, worker )
add the parameter request with timestamp t from worker to
the request list
Scheduler
While objective value > threshold get timestamp
if timestamp% (m+1)!=0
choose worker from worker processes MPI_Send(timestamp, worker ) else
for 1,2, … ,
MPI_Send(timestamp, worker ) MPI_Receive(timestamp, worker 1)
Worker
[image:4.612.141.466.199.338.2]There are P worker processes in total, each reading a disjoint of the whole training set. When a worker process receives a task, it sends a parameter request to the server process. Once receiving the responding parameters, if the received task is an update task, it will select a batch of local samples to compute , and , , and then send them to the server process, otherwise it will compute the local gradients and objective values based on all the local samples, and then aggregate the local results via MPI_Allreduce() to get the global gradients and objective value. Moreover, the worker process one is charge to send the global objective value to the scheduler process and the server process.
Table 7. the worker process.
BATCHVR
In SVRG, the full gradients are required to computed in each evaluation task at every stage, which is quite computationally expensive. In this paper, we propose an accelerated algorithm, BATCHVR, which use an incremental batch of samples, instead of the whole training set, to estimate the full gradients required in every evaluation task. The number of samples used to compute the estimating full gradients is proportional to the current stage number, thus the variation between the estimated value and the real one becomes smaller with the stage processing, which helps to achieve a better convergence.
Table 8. The algorithm BATCHVR.
We also implement the parallel BATCHVR based on the proposed distributed programming strategy. In other words, we make a revision on the previous worker process, altering the
computation of ∑∈ into that of ∑ .
Experiments
Performance evaluation is done on the YearPredictionMSD data from LibSVM, which has 463,715 samples in total, each having 90 features. We use the TH-1A as computing platform. The distributed algorithm is implemented in C++, with the MPI and Pthreads package for
Parameters: learning rate 0, update frequency m 0, 0
Initialize: For s 1,2, …
, k ∗ ∑ ,
For t 1,2, …,m, choose at random from samples,
,
update 1
Output: option Ⅰ
option Ⅱ , 0, … , 1
While objective value > threshold MPI_Send(timestamp, server)
if task t is an update task
pick a mini-batch subset randomly from the local data set compute mini-batch gradient , and , ,
MPI_Send( , and ,, server)
else
compute local subset gradient ∑∈ and local objective
value ∑∈
[image:4.612.172.445.468.603.2]Varying the Number of Worker Processes
[image:5.612.97.517.191.329.2]In this section, we did experiments in four cases, where there are 1 scheduler process, 1 server process and 1, 2, 5, 10 worker processes respectively, and different processes run in various nodes. We recorded objective values and time at every stage in different cases, and compare their performance on convergence and accelerate rate. The results demonstrate that our distributed implementation with MPI and Pthreads programming has a satisfying performance, that the convergence speed improves greatly with the count of processes. Accelerate rates of our parallel algorithm are 0.72, 0.653, and 0.363 respectively, which are also favorable due to the effective communication methods.
Figure 1. convergence with different number of processes. Figure 2. accelerate rate with different number of processes.
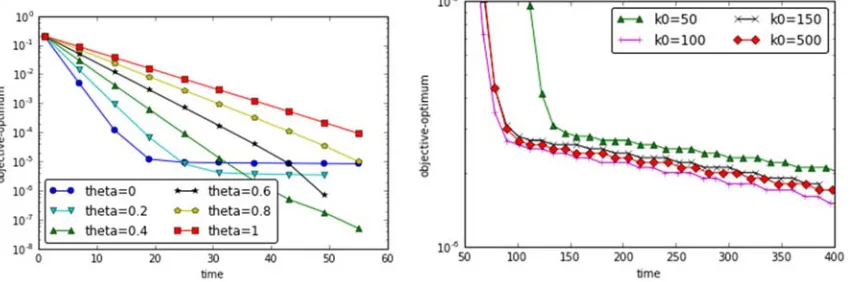
Varying the Value of
[image:5.612.96.522.471.612.2]The proposed newly SGD-based algorithm with variation reduction combines SVRG and DPG linearly with the parameter θ. The algorithm is closer to SVRG with θ decreasing. When θ 0, DPG makes no effect, and the algorithm is essentially an asynchronous SVRG. We did experiments in six cases, where θ was 0, 0.2, 0.4, 0.6, 0.8, and 1 respectively, and compared their convergence to find the effect of the parameter θ for the algorithm. According to our experiments results, we find that when θ equals 0.4, the convergence performance is the best, which shows the hybrid algorithm can outperform SVRG and DPG.
Figure 3. convergence with various theta. Figure 4. convergence with various .
BATCHVR
Discussion
The distributed implementation using MPI and Pthreads programming accelerates the convergence process of the objective value greatly with appropriate scaling of computational resources. However, the accelerate rate falls with the number of processes, due to the incrementally intense communication pressure. Also, the limited ability of the scheduler process and the server process could be the bottlenecks of the whole performance with the worker processes increasing. We can further improve the algorithm’s scalability by messages compression between processes and a reduced programming strategy with none or more scheduler and server. In BATCHVR, we select k samples to compute an estimate of the average gradients of the whole training set. When k is much less than the set size, although the computing complexity reduces, the variation between the estimate and the real value increases, which does harm to the convergence. Therefore, there is a tradeoff between the computing complexity and the variation. An appropriate k is very essential for the performance of BATCHVR, which can be obtained by grid search with a subset of the entire samples.
Conclusion
To conclude, our distributed implementation of the SGD-based algorithm with variation reduction has a satisfying performance. It can accelerate the convergence of the algorithm by increasing processes count, which improves the algorithm scalability greatly. Also, in our experiments, we found that the algorithm can achieve significant advantage of performance in general settings. Last but not least, the proposed algorithm---BATCHVR, converges faster than the current algorithm when we select an appropriate .
Acknowledgement
This research was financially supported by the National Natural Science Foundation of China under Grant NO.61232016.
References
[1] Roux, Nicolas Le, Mark Schmidt, and Francis Bach. "A stochastic gradient method with an exponential convergence rate for finite training sets." In Proceedings of the 25th International Conference on Neural Information Processing Systems, pp. 2663-2671. Curran Associates Inc., 2012.
[2] Johnson, Rie, and Tong Zhang. "Accelerating stochastic gradient descent using predictive variance reduction." In Advances in Neural Information Processing Systems, pp. 315-323. 2013. [3] Shalev-Shwartz, Shai. "SDCA without Duality, Regularization, and Individual Convexity." arXiv preprint arXiv:1602.01582 (2016).
[4] Defazio, Aaron, Francis Bach, and Simon Lacoste-Julien. "Saga: A fast incremental gradient method with support for non-strongly convex composite objectives." In Advances in Neural Information Processing Systems, pp. 1646-1654. 2014.
[5] Reddi, Sashank J., Ahmed Hefny, Suvrit Sra, Barnabas Poczos, and Alex J. Smola. "On variance reduction in stochastic gradient descent and its asynchronous variants." In Advances in Neural Information Processing Systems, pp. 2647-2655. 2015.
[7] Mania, Horia, Xinghao Pan, Dimitris Papailiopoulos, Benjamin Recht, Kannan Ramchandran, and Michael I. Jordan. "Perturbed Iterate Analysis for Asynchronous Stochastic Optimization." arXiv preprint arXiv:1507.06970(2015).
[8] RuiliangZhang, ShuaiZheng, and JamesT Kwok. "Asynchronous Distributed Semi-Stochastic Gradient Optimization." (2016).