2017 3rd International Conference on Computer Science and Mechanical Automation (CSMA 2017) ISBN: 978-1-60595-506-3
An Improved Anonymous Privacy Protection Model
Hui YU
1,aand Ming-Gao SHE
2,b1
School of Computer Science and Technology, Wuhan University of Technology, Hubei, China
2
School of Computer Science and Technology, Wuhan University of Technology, Hubei, China
a
[email protected], [email protected]
Keywords: Privacy protection, K-anonymous, Data publishing.
Abstract. Aiming at the privacy protection problem in the current data release, the classical K-Anonymity model and the improved L-Diversity model are analyzed. Combining the advantages of the two models, an enhanced privacy protection model is proposed and the algorithm is implemented. The new model enhances the validity of data distribution by introducing clustering method. At the same time in the clustering process using a new information loss measurement standards to enhance the security and flexibility of data release. The experimental results show that the model can reduce the risk of privacy leakage, and has a small loss of information.
Introduction
With the rapid development of information technology and intelligent technology, information resources and information sharing for people's lives and work to provide a great convenience, but also brought great risks and risks. Extracted from the data implicit, unknown of the potential value of information and knowledge more and more easy, which for privacy protection is a great challenge. How to prevent the sharing of data resources at the same time, but also to prevent the potential disclosure of privacy information is the researchers are facing an important research topic.
In this paper, from the basic concept of anonymous technology, analyzing the classical K-anonymous model[1,2] and other models based on K-anonymous[4-8] improvement, and fully combines the characteristics of various models, We propose an enhanced privacy protection model and algorithm design to be realized. This paper compares the difference in the privacy risk and the loss of information between the new model and the common privacy protection model, and validates the advantages of the new model. Finally, summarizes the paper and puts forward the further research direction of data privacy protection.
Basic Concept
In this section, we will use the relational data table as an example to introduce and discuss the basic knowledge of anonymous privacy data release. In relational data, the table is a collection of column attributes and row tuples of a series of data elements. These data attributes can be divided into the following four categories [3] according to their role and the characteristics shown.
(1)Identifier (ID): A set of attributes or attributes used to uniquely identify an individual's identity, called an identifier, such as a student number, a name, an ID number, and so on.
(2)Quasi-Identifier (QID/QI): A combination of attributes or attributes used to link other external datasets to identify individual identities, known as quasi-identifiers, such as gender, date of birth, postal code, and so on.
(3)Sensitive Attributes (SA): Data attributes that involve individual privacy are called sensitive attributes that need to be protected when data is released, such as individual pay, health status, credit rating, grade, and so on.
Enhanced Anonymous Privacy Protection Mode
K-Anonymity Model
Assuming that we can access the original data source or build a data set from the public data source that has the same attributes as the user information Table 1, the identity of the individual can be easily identified by {gender, age, zip code}, for example, Link data table T2 to get Chen Yanli attribute value of {female, 35,410097}, then we can determine that Chen Yanli table T1 is the first 5 records, know that the results with 48, this attack we call the link attack[1].
Table 1. Original data. Table 2. External link data.
ID Age Gender Zip code Results Name Gender Age Zip code
1 18 male 410075 85 Wang lei male 18 410075
2 19 female 410076 85 Zhang min female 19 410076
3 24 male 410088 92 Liu Jianhua male 24 410088
4 24 male 410088 73 Zhang wei male 24 410088
5 35 female 410097 48 Chenyanli female 35 410097
6 31 male 410097 67 Chen Yong male 31 410097
In order to prevent link attacks, Sweeney et al. proposed the K-Anonymity model[1]. This method makes it possible for each record to be indistinguishable from at least the other k-1 records in the data set by generalizing or hiding the quasi-identity attributes. The greater the value of k, the better the protection effect. For example, Table 3 is the result of the 2-Anonymity of the Table 1, and even if we get the three attribute values of Chen Yanli from the external data source as {female, 35,410097}, we cannot accurately judge Chen Yanli’s record is5 or 6.
Table 3. 2-Anonymous processed information.
ID Age Gender Zip code Results
1 [15,20] * 410075 85
2 [15,20] * 410076 85
3 24 male 410088 92
4 24 male 410088 73
5 [30,35] * 410097 48
6 [30,35] * 410097 67
The K-Anonymity model reduces the risk of identity disclosure to no more than 1/k, but it cannot provide sufficient diversity for sensitive attribute values in each equivalence group. Assuming that the attacker learned that Wang Lei was 18 years old, Wang Lei should be judged as record 1 or record 2. As the two records of the same results, so the attacker is easy to know the results of Wang Lei, this privacy attack known as homogeneous attacks[4].
L-Diversity Model
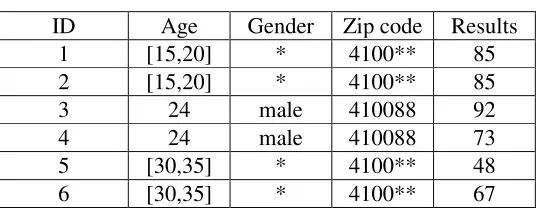
Table 4. 2-Diversity processed information.
ID Age Gender Zip code Results
1 [15,20] * 4100** 85
2 [15,20] * 4100** 85
3 24 male 410088 92
4 24 male 410088 73
5 [30,35] * 4100** 48
6 [30,35] * 4100** 67
The L-Diversity model can reduce the risk of privacy disclosure by improving the diversity of sensitive attributes in the equivalence group. However, there is no good way to set the appropriate diversity parameters for the uncertainty of background knowledge attacks[5]. Only if the distribution of the sensitive attribute value is equal, the diversity value of the data table reaches the maximum value, which is equal to the number of different sensitive values in the table. For example, there are only two kinds of sensitive attributes in the data table. Then, the L-Diversity model can only be satisfied if the condition of satisfying l is less than 2. Thus, the size of an equivalence group that satisfies the 2-Diversity anonymous table may be 2, and such a small number of records cannot provide sufficient privacy protection because the attacker may already know the sensitive attribute value of another person in the two individuals. He can easily infer the value of the remaining people. If we ask that the L-Diversity model above must also satisfy the K-Anonymity, by setting the appropriate k value, the attacker must first obtain at least k/2 individual values to get the target attribute value[6].
(K, L) -Diversity Model
The study of two common privacy protection models shows that the classical K-Anonymity model cannot provide sufficient diversity for the sensitive attribute values in each equivalence class and therefore cannot resist homogeneous attacks and background knowledge attacks. However, the improved L-Diversity model implements the diversity constraint of the sensitive value in the equivalence class, but does not realize the constraint on the number of its tuples. Considering the complexity of background knowledge attack, the risk of privacy disclosure is still high, Need to combine these two models, put forward an enhanced privacy protection model. The new model improves the ability to resist various privacy attacks by defining new (K, L) - Diversity constraints. At the same time, the model introduces the clustering method and improves the usefulness and validity of the data release.
(1) Equivalent group. In the data Table, there are n records, and the equivalent group C = {ti1, ti2……tin} is composed of multiple records. For any attribute QIp in QI there exists ti[QIp] = tj [QIp] .i,j ∈ n and i ≠ j. That is, all records in the same equivalent group have the same quasi-identity attribute values.
(2) Variety. Given the equivalence group C in the data table T, the corresponding sensitive attribute values are S, assuming that f is the most frequent number of sensitive attribute values, then the equivalence group Div(C)=|C|/f, where |C| is the number recorded in the equivalence group.
For example, Table 3, t1 and t2 on the quasi-identifier QI{age, gender,} constitute an equivalent group C1, the corresponding sensitive attribute value for the composition of S={85,85}, so f=|C1|Div(C1)=1 is defined by the multivariate value.
(3) (k , l)-Diversity. Given data table T = {C1, C2 ..., CP}, Let|Ci | ≥k, |Cj| ≥k (i, j [1, P] and i ≠ j), ∈
If any of Ci in T satisfies Div (Ci)> l, then the data table is called the data table (K, l)-Diversity, where
k ≥ 2,1 <l ≤ k, k, l are positive integers.
For example, in Table 1, the zip code attribute range D={410075,410088,410097}, AD (410075←41007 *) = 1,AD(410075←4100**)=2.With the definition of anonymity, we can determine the value of the generalized relationship of the specific privacy attack probability. For example, 410075←41007*after the probability of privacy attacks 1/AD(410075←41007*)=1.
(5) Anonymous conversion. The anonymity of the generalized relation (vi←vj) of a certain value in the quasi-identity attribute range D in the data table T is equal to the ratio of the anonymity of this value to the magnitude of the range D.
D )/ j v i AD(v ) j v i
ACR(v ← = ← (1)
(6) Information loss of tuples. The loss of information Cost (i) after the generalization of the i-th tuple in the data table T is equal to the weighted sum of the anonymous conversion of all quasi-identity attribute values.
j D ij AD ij ACR j C QI
j ACRij i
t
Cost , /
1 )
( ∑ × =
=
= … (2)
(7) Information loss of the table. The information loss Cost (T) is equal to the sum of the n tuple information loss in the table.
j c n i QI j ij ACR n i i t Cost T
Cost ∑ ×
= ∑ = = ∑ = = 1 1 ) 1 ( )
( (3)
(8) Represents tuples. Let the data table T cluster after the formation of the equivalent class G, G all the tuples for generalization, so that the formation of the equivalent group C. In C, all the tuples of the equivalence group or equivalence class satisfy tg [QI] = QIs and tg [S] = null (if all tuples in C have the same attribute value QIs on the quasi-identifier).
The representative group of the equivalence group is only a conceptual virtual tuple and does not require it to appear in the data set. In Table 2, t1 and t2 for the quasi-identifier QI{age, gender, zip code} form an equivalent group C1, the QIs = {[15,20], *, 410075}, then the representative group tg = {[15,20], *, 410075, null}.
(9) Tuple distance. Let any two tuples ti and tj in the data table T, Where i, j ∈ [1, n] and i ≠ j, If t * = δ (ti, tj) is the equivalent group formed by ti and tj generalization, then the distance between ti and tj is: ) * , ( ) * , ( ) , ( is t j t Cost t i t Cost j t i t
D = + (4)
For example, in Table 2, t1 and t2 are generalized to form an equivalent group C1,which represents the tuple t * = {[15,20], *, 410075, null}.Assuming that the weights of the three quasi-identity attributes are all 1, then Cost (t1, t *) = ACR (18 ← [15,20]) + ACR (male ← *) = 7/5, , T *) = 7/5, so the distance between two tuples Dis (t1, t2) = 14/5.
(10) The distance from the tuple to the class. Let the tuple t ∈ G in the data table T, tg is the representative tuple of the equivalence class G, Then the distance from t to class G is
) * , ( ) * , ( ) , ( t g t Cost G t t Cost G t
Dis = + (5)
|G|is the number of tuples in G, t*= δ(t, tg)is the equivalent group representing tuples formed by t and tg generalization.
Algorithm Implementation
Algorithm: (k,l)-diversity algorithm based on clustering
Output: PT which satisfies (k,l)-diversity of data sets Procedure:
/ * Determine the parameter value and initialize * / Compare the value of input k, l , if k <l, then return;
Calculate the number of different sensitive attribute values in data Table, denoted as NS, if NS<l for return;
Calculate the number of tuples contained in data set T, denoted as |T|, if |T|<k returns; Q, G={};
/ * Form satisfies (k, l) - diversity class * /
Loop execution when |T| not less than k or NS is not less than l; Selected a tuple t from the T randomly , T = T- {t};
Generate class G = {t}; tg [QI] = t [QI], tg [SA] = Null;
When the number of tuples in G is less than 1, the loop is executed: a. Select the smallest tuple t' of Dis (t', G) from T
b. If Div (t', G) < Div (G), Return (a) re-select Dis (t', t") the smallest tuple t"; c. Otherwise add t' to class G and remove t' from data set T
d. tg= δ(tg,t') ;
If k = 1, then the next step;
Get the temporary class Q= Q∪{G};
Recalculate the number of different sensitive attribute values NS in the data Table; / * Processing the remaining tuples in T * /
Randomly selecting tuple t' from T, removing t' from data set T;
Adding t' to the nearest class in Q and the number of tuples contained in the class is less than 2K-1; / * Generalization of equivalence classes Q* /
Processing each class in Q, and replacing the attribute values of each tuple in the quasi-identifier with the corresponding value of the class in which the tuple is located, then return the result data PT.
Experimental Environment and Results
Experimental Environment
The data used in the experiment comes from the Adult Database [9] of the University of Owen, USA. The database is a common database for studying privacy protection models and algorithms. In order to make the experimental data closer to the actual data, we will {Age, Sex, Job, Address, Marriage} as QI attribute, while adding a column {Disease} as a sensitive attribute, the value of the column is any one of{HIV, Cancer, Bronchitis, pneumonia, Gastric Ulcer, Gastritis, Indigestion, Flu}.
The experimental environment is Intel (R) Core (TM) i5cpu.M520 processor, 4GB ram, Windows 7 operating system; experimental language for the C++, and MATLAB simulation, and the experimental operation 10 times, take the average, the experimental steps are as follows:
(1)Remove the incomplete data in the Adult data set, randomly select 500 records for the experiment, and give each record "Disease" random assignment;
(2)The K-anonymous model and the l-diversity model and the(K,L)-Diversity model proposed in this paper are used to deal with the experimental data set, and the differences in the risk of privacy leakage and loss of information.
The Experimental Results
Privacy Disclosure Risk Comparison
Figure 1. Privacy risk probability.
As can be seen from Figure.1, the new model of the data sheet of the sensitive attribute value of the privacy disclosure probability is relatively small. This is because in the process of model design, the attacker has the background knowledge of each attribute and the background knowledge of the corresponding generalized hierarchy, and the distribution of the sensitive attribute value by the equivalence group diversity value and the anonymity constraint Control, enhance the model to protect the privacy of information, reduce the risk of model privacy disclosure.
Information Loss Analysis
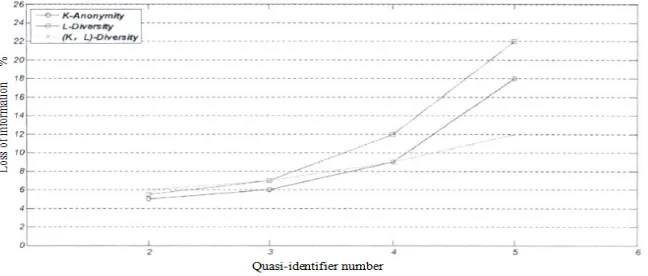
We assume that the attacker has considerable background knowledge, and can get the range of each attribute and the corresponding generalization level. Our goal of clustering the tuple is to satisfy the equivalent class of (k, l)-diverse, so we calculate the cost function is measured by the amount of data that is distorted by the generalization process. The calculation of the loss of information is given in Section 3.3. Figure 3 shows the loss of information after the experimental data set has been processed by the three models in the case of a change in the QI value. The abscissa is expressed as the value of the quasi-sign, and the ordinate indicates the loss of information. Where the weight of the quasi-identity attribute is set to 1, k or l = 6.
Figure 2. Comparison of Model Information Loss.
[image:6.612.152.476.527.665.2]increase of QI, the loss of the three models increases gradually. At this time, the k-Anonymous model and l-diversity model information loss growth rate is obviously higher than that of the new model, which is due to the increase of QI the degree of dissimilarity between groups increases rapidly, and the corresponding generalization hierarchy becomes complicated, if the direct generalization tuple will produce unnecessary information loss. Meanwhile, the new model is based on the clustering method to ensure that the tuples in the class are highly similar, thus reducing the generalization of the process of forming the equivalent group Times, thus reducing the amount of information loss.
Summary
Data anonymity is the research hotspot in the field of privacy protection. Applying anonymization to data in electronic data can reduce the risk of disclosure of privacy information on the one hand. On the other hand, it can reduce the high usefulness of information loss guarantee data, Sex and usefulness achieved a good balance between. In this paper, the privacy of data release method is only for static data processing, the next step, the dynamic data set will be studied.
References
[1] Sweeney L. k-anonymity: A model for protecting privacy[J].International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems, 2002, 10(5): 557-570
[2] Sweeney L. Achieving k-anonymity privacy protection using generalization and suppression[J]. International Jour-nal of Uncertainty, Fuzziness and Knowledge-Based Systems, 2002, 10(5): 571-588
[3] Lefevre K, Dewittd J, Ramakrishnan R. Incognito: efficient full-domain k-anonymity[C]//Proc of the 2005 ACM SIGMOD Int' 1 Conf on Management of Data. New York: ACM Press, 2005:49-60.
[4] Machanavajjhala A, Kifer D, Gehrke J, et al. l-diversity: Privacy beyond k-anonymity [J]. ACM Transactions on Knowledge Discovery from Data (TKDD), 2007, 1(1): 3.
[5] Byun J W, Kamra A, Bertino E, et al. Efficient k-anonymization using clustering techniques. Proceedings of the 12th International Conference on Database Systems for Advanced Applications, Springer-Verlag Berlin Heidelberg, Lecture Notes in Computer Science Volume 4443, 2007:188200.
[6] Zhang Jianpei, Xie Jing, Yang Jing, et al. A t-closeness Privacy Model Based on Sensitive Attribute Values Semantics Bucketization[J].Computer Research and Development,2014,51 (1):126-137
[7] Cheng Liang, Jiang Fan. a-diversity and k-anonymous Big Data Privacy Protection Based on Micro-aggregation[J]. Information Network Security, 2015(3):19-22.
[8] Wang Qian, Zhang Gangjing. A Micro-aggregation Algorithm for Monosensitive Attribute Diversity[J].Computer Engineering and Applications,2015(11):72-75.