2017 2nd International Conference on Artificial Intelligence: Techniques and Applications (AITA 2017) ISBN: 978-1-60595-491-2
Adaptive Collaborative Filtering Recommendation Algorithm
Based on User Attributes
Yang SU, Wang-gen LI and Cheng-cheng LI
School of Mathematics & Computer Science, Anhui Normal University, Wuhu Anhui, 241000, China
Keywords: Data sparsity, Attribute similarity, Preference matrix, Dynamic adaptive.
Abstract. The rapid development of the Internet brings the convenience but also results in “information trek” problem, which is solved by personalized recommendation algorithms. Traditional collaborative filtering algorithms face data sparsity problem. In order to solve those problems, this paper proposes a dynamic adaptive collaborative filtering recommendation algorithm based on user attributes. The algorithm first uses the item properties to build the user preference matrix, and then establishes the user rating preference matrix according to different behavior habits of users. Finally, based on these two matrixes, it prefills and dynamically adjusts the rating matrix. Experimental results show that the algorithm is more accurate in terms of the recommendation accuracy compared with traditional algorithms.
Introduction
With the rapid development of Internet technology, people have entered the era of rapid growth of information, it brings the convenience but also results in “information trek” problem[1]. To solve this problem, there are mainly two kinds of traditional solutions, one way is to use classified websites, mainly represented by Yahoo, and the other is based on search engines, like Google, Baidu and so on. However, facing the rapid growth of user's personalized needs, the above two methods cannot be well met, personalized recommendation algorithms come into being.
Traditional recommendation algorithms can be divided into three categories include content-based recommendation, collaborative filtering recommendation and hybrid recommendation. Due to collaborative filtering recommendation algorithm uses the user's score information to predict the non scoring information, it does not need to obtain other domain information, so it has become the most widely used recommendation algorithm. Collaborative filtering technology has some problems such as data sparsity and cold start[2]. Data sparsity mainly cause by those two reasons, the first is when users mark the project they also pay the price, such as privacy leaks and time waste; the second is the rate of growth is often faster than the speed of user experience. The cold start problem has two main forms: cold start of new project and cold start of new user[3]. Data sparsity and cold start problem are the important reasons that lead to loss of recommendation accuracy.
To solve the serious error caused by data sparsity, experts and scholars at home and abroad have launched a series of studies. Proposed a lot of new recommended algorithm, like pre filling algorithm. A relatively simple way of filling is to place an item as a fixed value[4], cluster first and then fill[5]. Besides those two methods, Literature [6] proposed a new collaborative filtering algorithm based on kernel density estimation; literature [7] proposed a new method by setting the scaling parameter to liner combined the user based and item based collaborative filtering recommendation; literature [8] proposed a new collaborative filtering algorithm based on non-negative matrix factorization; literature [9] proposed a new collaborative filtering algorithm based on SVD decomposition; literature [10] proposed a pre filling algorithm based on probabilistic knowledge; literature [11] proposed a pre filling algorithm based on cloud model; literature [12] proposed a recommendation algorithm based on user project clustering.
filtering recommendation algorithm based on user attributes. Experimental evaluation of accuracy of recommendation and robustness is made on the methods.
Problem Definition
User based collaborative filtering algorithm distinguish users by using similarity, users with high similarity would have more similar interests and preferences. The algorithm flow is to compute the similarity between users to find the nearest neighbor set and get the recommendations through the nearest neighbor set.
Define user set asU={U U U1, 2, 3,...,Un} , item set as I={ ,I I I1 2, ,...,3 Im}, Ri j, was the rating from Ui to Ij,
[image:2.612.181.432.234.312.2]The rating matrix was consist of all the user's rating information, listed in Table 1.
Table 1. User-rating matrix.
User I1 I2 I3 I4 I5
1
U 0 2 5 4 2
2
U 0 3 4 3 0
3
U 5 0 0 0 0
4
U 3 2 0 0 3
Common recommendation systems use 1-5 to indicate the level of preference, 1 represents the least, 5 represents the most.
There are three commonly used methods to calculate the calculate similarity: cosine similarity, Pearson similarity, adjusted cosine similarity.
ACFUA
According to the user's preferences and preferences on rating habit, set up user interest preference matrix and user rating preference matrix, then use the dynamic adaptive algorithm to pre fill the rating matrix, finally, collaborative filtering is recommended on the rating matrix after filling.
User Interest Preference Matrix
For a single item, it may contain multiple attributes. For the attribute class that the project has, define asA={ , , ,a a a1 2 3, }an , for specific item, its characteristic attributes can be represented by matricesM ,if
( , ) 1
M i j = means itemi has characteristicj, if M i j( , )=0means item inot has characteristic j.
For different users, their interest preference tends to be different, resulting in different ratings for the item. This paper takes into account the difference and constructs the user interest preference matrix.
Due to users was different to the degree of project preference, design preference weight calculation formula. In the case of the five-point film rating data, when the user scored 3 ~ 5, the score was positive, and 1 ~ 2 was negative. The calculation formula is as follows:
1 .4 5
1 .2 4 ( , ) 1 3
1 2
1 2 1
ij ij ij ij ij r r
w i j r
- r - . r
= = = = = = (1)
r
is the user rating for a movie.( , )
i j i j
i
w i j j I A N ∈ =
∑
(2) ijI has evaluated the collection of items owned by user
i
on attribute j, and Nirepresents thenumber of items that user i has scored.
Through formula 1, formula 2 can construct a complete user interest preference matrix:
11 12 1 1
21 22 2 2
31 32 3 3
1 2
i n
i n
i n
n n ni nn
A A A A
A A A A
A A A A
A A A A
ni
A represents the preference value of user
n
for project attribute i.User Rating Preference Matrix
For users with similar interests, the ratings of the same films tend to vary, depending on the user's ratings. To this end, by using the average score of a single user, the average score of all users is compared to that of the whole user, so as to obtain the weight of each user's score preference. The calculation formula is as follows:
i i
r
u
R
=
(3)Among them,
r
iindicates the average score of useri
, and R is the average score for all users. Through the above work, the user rating preference matrix can be obtained:[
u1 u2 ui]
Dynamic Adaptive Algorithm
Based on the above formula, this paper constructs a pre rating algorithm based on user preference. The weight value of the attribute of the item is calculated first, then multiplied by the average rating of the item, finally multiplied by the user weight. Its calculation formula is:
1
( , )
j(1
ij)
ig i j
=
i
×
+
A
×
u
(4)Among them, ijrepresents the average rating of item j, Aij represents the preference of user i for
attribute j,
u
i is the rating preference value of user i.Through the above steps, the preliminary evaluation of the ungraded item is pre rated, but there will still have some errors. Therefore, this paper has using dynamic adaptive adjustment on this basis[13]. Each user's pre-rating value is dynamically corrected by using the mean of the user's real rating data and the pre rating value ratio.
Definition 1. Operator
η
:1
( ( , )) ( , ) ij
ij j I
i
TR g i j
i j N ∈ ÷ η =
∑
Among them, g i j1( , )is the pre-scoring value of user i for item j, Ii is the collection of items
reviewed by user
i
. Ni is the number of items in the collection, TRij is the true score of useri
foritem j .
2
( , )
1( , )
,
g i j
=
g i j
×η(
i j
)
(5)ACFUA
In this paper, we propose one algorithm called adaptive collaborative filtering recommendation algorithm based on user attributes to solve the problem of data sparsity. The algorithm process is as follows:
Input: UserSet:U, ItemSet: I, RatingMatrix:R. Output: PreaditRating:Pu,j .
Begin
1. for each i∈U do 2. ri ← a v e r a g e R( i) 3. ij ← a v e r a g e R( j) 4. R ← a v e r a g e R( ) 5. end for
6. for each i∈U and j∈I do 7. Aij ← calculateWeight i(,j)
8.
u
i←
calculate
(
i
)
9. g1( ,i j) ← ij× (1+ Ai j)×ui
10. preMat ←
η
×g i j1( , )11.
end for
12. for each u∈U′ do
13. simSet(u)←similarity u p( , reMat)
14. Pu j, ← predict simSet u I( ( ), )j
15. end for 16. return Pu j,
End
The algorithm mainly consists of three stages: first stage is row 1 ~ 5, mainly to solve user and project scoring average; In the second stage, the scoring matrix is pre-filled with user and project information. The third stage is line 12 ~ 16, personalized recommendation on the graded matrix after filling.
Experiment Results
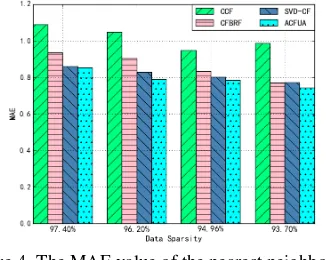
In this paper, we compare the different kinds of neighbor Numbers and data sparsity, and compare the proposed algorithm with Classic Collaborative Filtering (CCF), Collaborative Filtering on Rating Filling (CFBRF) and Collaborative Filtering based on SVD decomposition (SVD-CF). Use MAE to calculate accuracy[14-15].
The classic test data set Movielens is selected in this paper. The data set was collected by the Grouplens team. It contains 943 users, 100000 rating data for 1682 movies .
To test different sparsity, were collected in one hundred thousand in eighty thousand, sixty thousand and forty thousand rating data to form four experimental data sets to test the performance of the algorithm in different sparsity of. By calculating the sparsity formula:
1 r
u i
N s
N N
= −
× (6)
r
The sparse degrees of the four data sets can be calculated as 93.7%, 94.96%, 96.2% and 97.4% respectively.
Result Analysis
Due to the SVD-CF algorithm first needs to determine the dimension of reduction, the best results are compared. In the experiment, the information retained in the process of decomposition of singular value was taken from 100% to 10%, and the change of MAE value was observed at every 10% reduction, and 20 neighbors were selected in the whole process. The result is shown in figure 1.
[image:5.612.221.404.236.359.2]As we can be seen from figure 1, with the increase of retained information, MAE values generally show a tendency to decrease first and then increase. Among them, the experimental data were 40, 000 and 60, 000, and the optimal retention information was 30 percent, 40 percent in 80, 000 and 50 percent in 100,000.
Figure 1. The relationship between retained information and MAE.
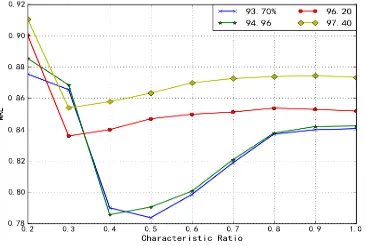
The best retention information to determine the SVD-CF method than after the same sparsity and different two types were verified, first under the same sparsity, we took MAE sparsity for various algorithms 93.7% and 97.4% under the figure 2, shown in figure 3
Figure 2. The MAE value of sparsity is 93.7%. Figure 3. The MAE value of sparsity is 97.4%.
As you can see from Figure 2 and figure 3, as the number of neighbors increases, each algorithm shows a trend of decreasing first and then steadily. CFBRF, SVD-CF and ACFUA compared with the CCF algorithm can improve the performance significantly, compared to the two figure, we can find that in the sparse degree under the condition of increasing performance of SVD-CF and ACFUA algorithm is more stable, and the ACFUA algorithm is superior to the SVD-CF algorithm.
[image:5.612.159.485.440.578.2]operation under harsh environmental conditions, can be recommended to maintain performance in a relatively small range, has more excellent robustness.
[image:6.612.110.273.108.238.2]
Figure 4. The MAE value of the nearest neighbor number is 8.
Figure 5. The MAE value of the nearest neighbor number is 20.
Conclusion
The data sparsity problem in traditional collaborative filtering algorithm, this paper proposes a new rating matrix pre filling algorithm, by constructing user preference matrix, and on the basis of preliminary score on dynamic adaptive correction to obtain more accurate pre assessment scores by using real data, then pre filled the rating matrix, finally, using collaborative filtering algorithm make recommendations. Experimental results show that the proposed algorithm has better performance than the traditional algorithm, especially in the case of more sparse data. The next step will be to improve the algorithm in order to alleviate the cold start problem to some extent.
References
[1]Liu jian-guo, Zhou tao, Wang bing-hong. Research Progress of Personalized Recommendation System[J]. Progress in Natural Science, 2009,19(1):1-15
[2]Moshfeghi Y, Piwowarski B, Jose J M. Handling data sparsity in collaborative filtering using emotion and semantic based features[C]//Proceeding of the, International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2011, Beijing, China, July. DBLP, 2011:625-634.
[3]Lam X N, Vu T, Le T D, et al. Addressing cold-start problem in recommendation systems[C]// International Conference on Ubiquitous Information Management and Communication, Icuimc 2008, Suwon, Korea, January 31 - February. 2008:208-211.
[4]Deng ai-lin, Zhu yang-yong, Shi bo-le. A Collaborative Filltering Recommendation Algorithm Based on Item Rating Prediction[J]. Journal of Software, 2003, 14(9).
[5]Vizine Pereira A L, Hruschka E R. Simultaneous co-clustering and learning to address the cold start problem in recommender systems [J]. Knowledge-Based Systems, 2015, 82(C):11-19.
[6]Wang peng, Wang jing-jing, Yu neng-hai. A Kernel and User-Based Collaborative Filltering Recommendation Algorithm[J]. Journal of Computer Research and Development, 2013, 50(7):1444-1451.
[7]Liang, Guohang, Song, et al. Personalized Recommendation Algorithm Based on Preference Features [J]. Journal of Tsinghua University(Science and Technology), 2014, 19(3):293-299.
[9]M Yan, W Shang, Z Li, Application of SVD technology in video recommendation system [J]. IEEE Computer Society, 2016
[10]Zhou jun-feng, Tang xian, Guo jing-feng. An Optimized Collaborative Filtering Recommendation Algorithm[J]. Journal of Computer Research and Development, 2004,41(10):1842-1847.
[11]Yu zhihu, Qi yu-feng. A Data Filling Algorithm Based on Cloud Model[J]. Computer Technology and Development, 2010,20(12):34-37.
[12]Kant S, Mahara T. Merging user and item based collaborative filtering to alleviate data sparsity[J]. International Journal of System Assurance Engineering & Management, 2016:1-7.
[13]Paz A, Arboleda H. A Model to Guide Dynamic Adaptation Planning in Self-Adaptive Systems [J]. Electronic Notes in Theoretical Computer Science, 2016, 321(C):67-88.
[14]Wang zheng, Li fang, Peng ruo-hong, et al. Forecast ModelAccuracy of Evaluation[J]. Statistics and Decision, 2008(9):76-77.