© 2017, IRJET | Impact Factor value: 5.181 | ISO 9001:2008 Certified Journal | Page 1405
EVASION ATTACK DETECTION USING ADABOOST LEARNING
CLASSIFIER
Mrs.Ashvinee N. Kharat
1,Prof Mr.(Dr.).B.D.Phulpagar
21
Student, Department of Computer Engineering, P.E.S Modern College of Engineering, Pune, India.
2Assistant Professor, Department of Computer Engineering, P.E.S Modern College of Engineering, Pune, India.
---***---Abstract
-Pattern attention and computing devicelearning approaches have been progressively received in antagonistic settings, for example, spam, interruption, and malware identification, in spite of the fact that their security against great created strikes that mean to avoid location with the aid of manipulating information at test time has now not yet been altogether surveyed. While past work has been most likely energized by conceiving foe mindful order calculations to counter avoidance makes an attempt, best few authors have considered the have an effect on of utilizing lowered feature units on classifier safety in opposition to the same assaults. A fascinating, preliminary influence is that classifier wellbeing to evasion might be even exacerbated by means of the use of capacity choice. In this paper, we give a more particular examination of this aspect, shedding some mellow on the security living arrangements of highlight decision against evasion attacks. Empowered by means of earlier work on enemy mindful classifiers, we propose a novel adversary mindful characteristic resolution mannequin that can reinforce classifier safety in opposition to evasion assaults, with the aid of incorporating distinctive assumptions on the adversary’s information manipulation approach. They focal point on an effective, wrapper depends execution of our technique, and experimentally validate its soundness on one of a kind software examples, together with unsolicited mail and malware detection. In this project AdaBoost classifier will be used. The basic concept behind AdaBoost is to engender a vigorous classifier by the conjuncture of many impuissant classifiers (hit rate barely better than 50). AdaBoost works on the training phase, seeing how some classifier who failed during the classification should be played greater attention because it takes care of special cases of classification.
Key Words: feature selection, classifier security,
Adversarial learning, evasion attacks, malware detection, spam filtering
1. INTRODUCTION
During the last decade, IDS systems have matured and took place of important segment of network defense. These systems are today common in large networks which are connected to Internet. On the other hand, some of the attacks are more sophisticated than in years before. This
paper discusses one such type of attacks, namely evasion attacks. This class of attacks has the following characteristic: attacker is aware of the existence of the IDS system in the target network, and is trying to evade IDS detection. There are several means attacker can use to achieve evasion. Here we summarize them as: - lack of knowledge regarding network topology - lack of knowledge regarding configuration of protected communications protocol stack - lack of knowledge regarding version of protected communications protocol stack Another important class of evasion attacks is related to the application level processing of received packet. In that case we talk about lack of knowledge about applied rules to packet processing at the application level. When talking about lack of knowledge regarding network topology, if IDS cannot determine distance in hops of protected host, it cannot decide if the processed packet will reach the host, having in mind TTL value of packet. When talking about lack of knowledge regarding configuration of protected communications protocol stack, there is possibility that due to the configured rules at lower levels, processed packet will not reach application level at the protected host at all. One example for that is that common practice applied by some Internet administrators is to drop source-routed packets.
© 2017, IRJET | Impact Factor value: 5.181 | ISO 9001:2008 Certified Journal | Page 1406 consolidating categorical presumptions on the adversaries
data manipulation strategy. We fixate on an efficient, wrapper-predicated complement approve its soundness on various application illustrations, including good words and bad words detection. In the previous case, we think about the customary forward element separate wrapping algorithm with the relating implementation of our approach, utilizing a linear SVM as the relegation algorithm. In the last case, rather, we consider conventional and adversarial rearward feature elimination approaches, and a SVM classifier with the Adaboost classifier kernel as the wrapped classifier. Unfortunately, the real draw-back of SVMs is that they can be woefully inefficient to train. So, they would not recommend them for any problem where you have many training examples. They would actually go even further and say that they would not recommend SVMs [7], [9] for most ”industry scale” applications. Anything past a toy/lab issue may be better drawn closer with a different algorithm. Bad words i.e. spam separating is a standout amongst the most predominant application cases considered in evasion-adversarial machine learning. In this task, the intent is often to design a direct classifier that discriminates amongst authentic and spam messages/emails by investigating their textual content, exploiting the soi-disant bag of-words highlight representation, in which every feature signifies the nearness (1) or nonappearance (0) of a given word in an email. Disdain its simplicity, this sort of classifier has appeared to be exceptionally precise, while additionally giving interpretable choices. It has been, in this way, broadly embraced in past work. Instead of SVM Classifier here Adaboost classifier is utilized. AdaBoost is a popular boosting technique which avails you amalgamates various”weak classifiers” into a solitary ”strong classifier”. A weak classifier is basically a classifier that performs ineffectively, however performs superior to arbitrary conjecturing. A straightforward case may consign a man as male or female in view of their tallness. You could state anybody more than 5’ 9” is a male and anybody under that is a female. You’ll misclassify a plethora of people that way, but your precision will still be greater than 50.AdaBoost can be applied to any classification algorithm, so its genuinely a technique that builds on top of other classifiers as opposed to being a classifier itself. You could just train a bunch of weak classifiers on your own and combine the results, So there are two important features of AdaBoost: 1. It helps you pick the preparation/ training set for each new classifier that you prepare in view of the consequences of the previous classifier. 2. It decides how much weight ought to be given to each classifiers proposed response when cumulating the results. In one applicable attack situation, referred to as evasion attack.
An implicit assumption behind customary machine learning and pattern recognition algorithm is that preparation and test information are derived from identically tantamount, possibly unknown, distribution.
This already assumed is, however, likely to be violated in adversarial settings, since attackers may conscientiously manipulate the input data to downgrade the systems performance. It orders categorizes attacks as indicated by three axes: the assault impact, the sort of security infringement, and the assailment specificity. The assailment impact can be either causative or exploratory. Depending upon the sort of security infringement, an assault may trade off a systems accessibility, integrity, or protection: accessibility assaults plan to downgrade the overall systems precision, bringing about a disavowal of administration; honesty assaults, rather, just expect to have malicious examples misclassified as legitimate/ goodness; and security assaults plan to recover some bulwarked or touchy data from the framework.
2. REVIEW OF LITERATURE
© 2017, IRJET | Impact Factor value: 5.181 | ISO 9001:2008 Certified Journal | Page 1407 framework predicated on face and dactyl gram biometrics
[3]. From one viewpoint, there results affirm that multimodal frameworks are powerless attacks against assaults against a solitary biometric quality. They demonstrate that the ”worst-case” situation can be unreasonably cynical. This can prompt to excessively moderate decisions, if the ”thinking pessimistically” hypothesis is used for planning a hearty multimodal framework. Subsequently, creating tech-niques for assessing the power [3] of multimodal frameworks against caricaturing assaults [2], and for outlining powerful ones [3], remains an exceptionally pertinent open issue. In this paper [3], they address the security of multimodal biometric frameworks when one of the modes is effectively satirize. They propose two novel combination conspires that can expand the security of multimodal biometric frameworks. The first is an expansion of the probability proportion based combinations conspires and alternate uses fluffy rationale. Other than the coordinating score and test quality score, our proposed combination conspires likewise consider the natural security of each biometric framework being intertwined. Exploratory outcomes have demonstrated that the proposed techniques are more hearty against parody assaults when contrasted and conventional combination strategies.
For fending a server against Internet worms and for battling a client’s email inbox against spam [4], [6] bear certain like-nesses. In both cases, a surge of tests arrives, and a classifier should consequently figure out if every example falls into a malicious target class [4] (e.g., worm network traffic or spam email). A searcher typically generates a classifier automatically by analyzing two labeled education pools: one of harmless examples, and one of tests that fall in the vindictive target class. Learning methods have already discovered accomplish-ment in settings where the substance of the marked specimens used in preparing is either irregular, or even built by an accommodating educator, who intends to speed learning of a precise classifier. On account of learning classifiers for worms and spam [4], in any case, an adversary controls the substance of the labeled samples all things considered. In this paper [4], we portray pragmatic assaults against learning, in which a adversary links marked examples that, when used to prepare a learner, avert or seriously postpone era of an exact classifier. They demonstrate that even a fraudulent adversary, whose examples are all correctly labeled, can impede learning. They reproduce and actualize exceptionally compelling examples of these assaults against the Polygraph programmed polymorphic worm signature generation algorithms [4].
They [5] seek to answer a simple question: How avoid the denial-of-accommodation (denial-of-service) attacks in the Internet in this era? Our goal is to comprehend the way of the present danger and additionally to empower longer-term investigations of
patterns and repeating examples of assaults. They present a new technique, called backscatter analysis, that provides an estimate of ecumenical denial-of accommodation activity. They utilize this approach on three week-long datasets to survey the number, span and center of assaults, and to characterize their demeanor. During this period, they watch more than 12,000 assaults against more than 5,000 unmistakable targets, extending from surely understood web based business organizations, for example, Amazon and Hotmail to little outside ISPs and dial-up associations. They trust that our work is the main publically accessible information measuring fore swearing of-administration movement [5] in the Internet.
3. PROBLEM STATEMENT AND MOTIVATION
3.1 Problem Statement
Feature choice may be considered a valuable step in security-associated applications, comparable to junk mail and malware detection, when small subsets of facets need to be chosen to slash computational complexity, or to beef up classification performance by means of tackling the path of dimensionality. However, considering the fact that common function choice ways implicitly count on that training and scan samples comply with the same underlying knowledge distribution, their performance could also be drastically affected underneath adversarial assaults that violate this assumption. Even worse, performing feature resolution in adversarial settings may enable an attacker to evade the classifier at experiment time with a cut back number of changes to the malicious samples. To our competencies, besides the above studies, the challenge of picking feature units suitable for adversarial settings has neither been experimentally nor theoretically investigated more in depth.
3.2 Motivation
© 2017, IRJET | Impact Factor value: 5.181 | ISO 9001:2008 Certified Journal | Page 1408 lower computational complexity and allow for a greater
data working out. Consequently, working out whether these advantages can also be exploited without compromising method safety in security-sensitive duties(the place decreasing computational complexity is of exact curiosity as a result of the huge quantity of information to be processed in actual time) can be viewed a significant, open study quandary.
3.3 Existing System
An implicit assumption behind traditional machine learning and pattern recognition algorithms is that training and test data are drawn from the same, possibly not known, distribution. This supposition is, however, likely to be destroyed in adversarial settings, since attackers may carefully manipulate the input data to downgrade the system’s performance. It categorizes attacks according to three axes: the attack influence, the kind of security violation, and the attack specificity. The attack influence can be either causative or exploratory. Depending on the kind of security violation, an attack may compromise a system’s its availability, its integrity or privacy or security: availability attacks aim to downgrade the overall system’s accuracy, causing a denial of service; integrity attacks, instead, only aim to have malicious samples misclassified as legitimate; and privacy attacks aim to retrieve some protected or sensitive information from the system.
3.4 Proposed System
Efficiency of Proposed adaboost Classifier:
AdaBoost combines a set of weak learners in order to form a strong classifier in a “greedy fashion,” i.e., it always selects the weak classifier with the minimum error, ignoring all others.
Adaboost algorithm for improving efficiency of sentiment classification as well does comparative analysis of existing approaches.
Adaboost can capture very complex decision boundaries whilst avoiding (in many cases) over-fitting.
Adaboost is to learn not only polarity, but also the weights of the words by applying machine learning techniques and it will select small set of discriminative words.
We can directly use the same AdaBoost algorithm for multi-class classification.
How it is better?
We use AdaBoost to choose the features that most rightly span the classification problem, and SVMs to fuse those features together to form the final classifier.
AdaBoost may select that features more than once when constructing, forming weak learners; however, having the same feature appear twice in an SVM formulation does not make sense.
Random forest to perform well, it generally require deep trees (level >=7). While Boosting typical work better with shallow trees (5-15 leaves). Boosting has very well speed advantage here.
Proposed System Architecture
To provide the efficient solution to mine the attack, recently SVM methods presented with propose two algorithms as well as a compact data structure for efficiently discovering high accuracy. In the previous case, we look at the customary forward component choice wrapping calculation with the comparing usage of our approach, utilizing a straight SVM as the relegation algorithm. In the last case, rather, we consider conventional and ill-disposed in reverse element end approaches, and with SVM [7], [9] and the Adaboost classifier.
Fig- 1: Block Diagram
© 2017, IRJET | Impact Factor value: 5.181 | ISO 9001:2008 Certified Journal | Page 1409
4. Mathematical Model
Input: training data set {d1, d2,…dn} Process:
1. Adversarial Feature Selection, Wrapper-Based. As in traditional wrapper methods, cross-validation is exploited to estimate the classifier’s generalization capability G(θ),
G(θ) = Ex,y_p(X,Y) u(y, g(xθ )) E = expectation operator
xθ = the projection of x onto the set of selected features
g(x) = the classifier’s discriminant function
p(X, Y) = distribution with X and Y being two random variables defined in the corresponding sets X and Y
2. Evasion from Evaluating Classifier Security Input:
x= the malicious sample;
x (0)= the initial location of the attack sample; t=the gradient step size
ɛ= a small positive constant
m= the maximum number of iterations.
AdaBoost classifier: Final classification based on weighted vote of weak classifiers.
…is the output of weak classifier
…is “strong” or final classifier
The first classifier (t = 1) is trained with equal probability given to all examples in training. After it’s trained, we compute the outcome weight (alpha) for that classifier.
The output weight, alpha_t, is fairly clear. It is based on the classifier’s error rate, ‘e_t’. e_t is just the number of wrong classifications over the training set divided by the training set size. Output:
X’= the nearest evasion point to x found.
FinalOutput: attack found {atk1, atk2..atk n}
5. SYSTEM ANALYSIS
For these examinations, we considered the benchmark TREC 2007 email corpus, which comprises of 25 220 legit-imate to goodness and 50 199 genuine spam messages [1]. We spoke to every email as an element vector utilizing the tokenization strategy.
5.1 Accuracy Graph
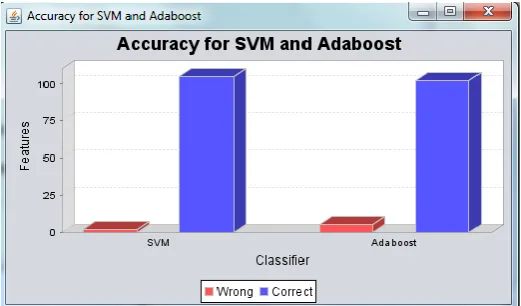
As we can see in Fig. 2 which shows accuracy between existing and proposed system. Our results prove that Adaboost works more efficiently than SVM classification algorithm. This graph shows the accuracy level of wrong and correct predictions by both classifiers.
Chart-1: Accuracy Graph.
[image:5.595.308.569.314.467.2]5.2 Classification Accuracy
Figure 3 shows the graph of classification accuracy G( ) for SVM algorithm.
X-axis shows the features and Y-axis shows the accuracy.
© 2017, IRJET | Impact Factor value: 5.181 | ISO 9001:2008 Certified Journal | Page 1410
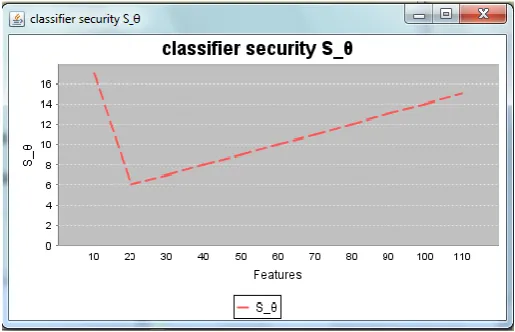
5.3 Classifier Security Graph
Figure 4 represents the security level graph. Here parameter S_ is used for performance measure. This graph represents as the no. of features increases from X-axis varies security level in increasing order.
Chart-3: Classifier Security Graph
5.4 Time Complexity Graph
This graph proves that adaboost takes less time as compare to SVM classifier. Time is measured into milliseconds.
Chart-4: Time complexity Graph
5.5 HARDWARE INTERFACE
Processor: - P-IV 500 MHz to 3.0 GHz RAM: - 8 GB
Disk: - 1 TB
Monitor: - Any Color Display Standard Keyboard and Mouse
5.6 Software Interface
Operating System: - Windows 7/XP
[image:6.595.35.293.183.349.2]Development End (Programming Languages): - Java, jdk 1.8.
Table -1: Classification Accuracy
Algorithms Correct
Classification Wrong Classification SVM
Classification 105 0
Adaboost
Classification 101 4
6. Conclusion
In this project, we proposed a feature selection method that optimizes not only the generalization capability of the wrapped classifier, but also its security against evasion attacks at test time. Adaboost classifier is used in project which is one the powerful classification algorithms that has lot of practical success with applications in a wide variety of sectors, like biology, computer vision and speech processing. Not like other efficient classifiers techniques, such as SVM, Adaboost can achieve similar classification results with much low quantity of parameters. Our work provides a first, attempt toward understanding the potential vulnerabilities of feature selection methods, and toward developing more secure feature selection schemes against adversarial attacks.
7. REFERENCES
[1] G. V. Cormack, “TREC 2007 spam track overview” in
Proc. 16th Text Retrieval Conf. (TREC), 2007, pp. 123131.
[2] B. Biggio, Z. Akhtar, G. Fumera, G. L. Marcialis, and F.
Roli, “Secu-rity evaluation of biometric authentication systems under real spoofing attacks” IET Biometrics, vol. 1, no. 1, pp. 1124, 2012.
[3] R. N. Rodrigues, L. L. Ling, and V. Govindaraju,
“Robustness of multimodal biometric fusion methods against spoof attacks” J. Vis. Lang. Comput., vol. 20, no. 3, pp. 169179, 2009
[4] J. Newsome, B. Karp, and D. Song, “Paragraph:
Thwarting signature learning by training maliciously” in Recent Advances in Intrusion De-tection (Lecture Notes in Computer Science). Berlin, Germany: Springer, 2006, pp. 81105.
[5] D. Moore, C. Shannon, D. J. Brown, G. M. Voelker, and S.
[image:6.595.35.289.457.609.2]© 2017, IRJET | Impact Factor value: 5.181 | ISO 9001:2008 Certified Journal | Page 1411 ACM Trans. Comput. Syst., vol. 24, no. 2, pp. 115139,
2006.
[6] D. Lowd and C. Meek, “Good word attacks on statistical
spam filters” in Proc. 2nd Conf. Email Anti-Spam, Palo Alto, CA, USA, 2005.
[7] J. Neumann, C. Schnrr, and G. Steidl, “Combined
SVM-based feature selection and classification” Mach. Learn., vol. 61, nos. 13, pp. 129150, 2005.
[8] J. Weston, A. Elisseeff, B. Schlkopf, and M. Tipping,“Use
of the zero norm with linear models and kernel methods” J. Mach. Learn. Res., vol. 3, pp. 14391461, Mar. 2003.
[9] H. A. Le Thi, X. T. Vo, and T. P. Dinh, “Robust feature
selection for SVMs under uncertain data” in Advances in Data Mining, Apps, and Theoretical Aspects. Berlin, Germany: Springer, 2013, pp. 151165.
[10] B. Biggio, G. Fumera, and F. Roli, “Multiple classifier
systems under attack” in Multiple Classifier Systems (LNCS 5997), N. E. Gayar, J. Kittler, and F. Roli, Eds. Berlin, Germany: Springer, 2010, pp. 7483.
[11] M. Kolar and H. Liu, “Feature selection in