International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 7, Issue 9, September 2017)
366
Preserving Privacy of Utility Mining with Laplace Approach
Lavi Bandil
1, Rishi Soni
21,2
Dept. of C.S.E, ITM Group of Institute, Gwalior, India
Abstract—Privacy preservation of high utility item set is the crucial task in data mining. This algorithm primarily uses the concept of Two Phase algorithm. In this paper firstly transactional database is used to mine out high utility itemset. Then, Utility of item is calculated as the product of profit of an itemset and no. of itemset in a transaction. Itemset with high utility value are selected with the help of predefined threshold value. We will try to reduce the value of itemsets greater then threshold using Differential privacy. There are several mechanism for achieving differential but in our work we will use Laplace. Masking of itemset is done with noise in this approach. Now, the sensitive itemset will be hiding using HHUIF and database is updated .This algorithm can be applied to single and multiple databases. Example has been taken to clearly understand the working of proposed work.
Keywords- Privacy preservation, Utility mining, Differential privacy, Laplace mechanism and Two phase algorithm.
I. INTRODUCTION
In real world scenario data sharing between the organizations plays a vital role. When a client updates his information on the server, the client data can be used for analysis purpose .Analysis should be done in a manner that it only gives out useful result but many times it happens that the individual data is accessed by the intruder and it results in privacy threat .Privacy became a latest topic in data mining as individual security is the main concern in the data sharing world. To maintain the right balance between the useful results obtain from database and to secure one’s individuality is the main goal of privacy preserving data mining. Several data mining techniques have been introduced to preserve the user’s data from intruders. Privacy preserving data mining techniques are measured in terms of data utility, performance or level of uncertainty etc [1]. There are also certain criteria on which PPDM techniques performance is depended, they are-
1.Privacy level defines that the hiding sensitive information can be evaluated.
2.Hiding failure is the part of sensitive data which is not hidden by privacy techniques.
3.Another important factor is Data quality which means after mining the information must be up to the mark. 4.Complexity means the execution of algorithm along
with available resources should be better in terms of performance.
There is no such algorithm that gives out better result on the each criterion, different algorithms may perform differently i.e. result of one algorithm on a particular criteria is better than the other. In this condition user can use algorithm according to their information [2]. Outcomes of frequent pattern mining are not suitable for real world problems because the item set obtained is frequent only, they does not provide high profit rate.
Due to this a new term Utility mining is introduced. The item set which are least frequent in database but can increase the profit rate of any organization is termed as High Utility Item set mining. Utility mining can better deal with realistic decision problem. Now days, Utility mining is widely used in decision making business like retail, inventory, online e- commerce management etc [3]. There are certain measures of Privacy-
1. Control access to the information. 2. Control the flow of information.
3. Control the purpose for which information is used.
A. Utility Mining
In earlier ARM approaches utility of item was calculated by its occurrence in transaction database. Item set frequency and weighted association rule mining both are not able to find the original utility of an item set. By means of cost, profit or other user choices utility can be calculated [4]. To discover the utility item set above than threshold value from transaction database is the primary aim of utility mining. Generally utility of item set is dependent on two aspects i.e. Internal Utility and External Utility. Terms that are used in calculating high utility item sets are as follows [5]:
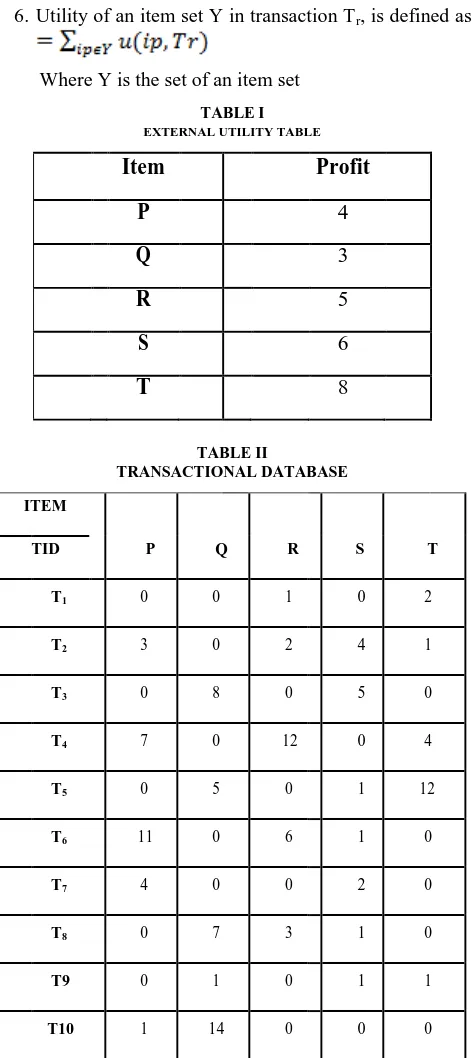
1. Set of items is denoted by I = {i1, i2 , … , in}.
2. Transaction database is denoted by D = {T1, T2… Tm} where each transaction Ti∈ D is a subset of I.
3. Local transaction utility value represents the quantity of item ip in transaction Tr, and it is denoted by o(ip, Tr). For example- o(P, T2) is 3 from above transaction table.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 7, Issue 9, September 2017)
367 5.Utility for an item is calculated by-
.
For example- u (P, T4) = 7 x 4= 286.Utility of an item set Y in transaction Tr, is defined as
[image:2.612.52.289.180.709.2]Where Y is the set of an item set
TABLE I EXTERNAL UTILITY TABLE
Item
Profit
P
4
Q
3
R
5
S
6
T
8
TABLE II
TRANSACTIONAL DATABASE
ITEM
TID P Q R S T
T1 0 0 1 0 2
T2 3 0 2 4 1
T3 0 8 0 5 0
T4 7 0 12 0 4
T5 0 5 0 1 12
T6 11 0 6 1 0
T7 4 0 0 2 0
T8 0 7 3 1 0
T9 0 1 0 1 1
T10 1 14 0 0 0
B. Differential Privacy
Cynthia Dwork first proposed the concept of Differential privacy. In his work he introduced a new way of preserving privacy by applying mathematical mechanism over it [6]. When a bank customer shift his bank account from one location to the another at that particular time if an intruder gain access to both the bank balances then he will be able to calculate the current balance of the customer. In this way individual privacy can be violated, to breach privacy noise is added to the actual data. Differential privacy can be achieved by different mechanism like Gaussian, Exponential and Laplace. Here we are using Laplace mechanism in our work.
Definition-1: A randomized function N provides
𝞊
– differential privacy if for any datasets P and Q with symmetric variation P-Q=1(where P and Q are multi sets) and S is the superset of Range (N).Pr[N(P)ϵS] ≤ Pr[N(Q)ϵS]Xeϵ
𝞊
is used to control the level of privacy. Lower the value𝞊
of stronger the privacy [7].The rest of the paper is organized is as follows Section 2 presents the Literature survey and back ground. Section 3 describes the proposed work and methodology, Section 4 discusses the result analysis and Last Section 5 provides the conclusion.
II. LITERATURE SURVEY
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 7, Issue 9, September 2017)
368 It also modifies the sensitive item with highest utility in the dataset so they cannot be easily accessed by any fraud adversaries’. MSICF is to limit the number of modified items from the original database. Item with the maximum conflict count among the sensitive item set is choose by MSCIF.
On different data mining approaches differential privacy is evaluated to mask the outcome of query by noise. It has two useful advantages in mining that-
1) To perform the data mining task without exposing the original data to the third party.
2) Give permission to data providers to sell data access to the other party with limitation of privacy risk [10]. A fast high utility mining algorithm has two phases [5].
Phase 1 - It defines transaction- weighted utilization and proposes a model. The sum of all transaction also consists of downward closure property which states that any subset of high transaction weighted utilization should also be high. Phase 2 - The transaction database is scanned only once to compute high utility item set. The extra scan cost more. Genetic algorithm is applied to the utility mining in order to preserve privacy [11].
III. PROPOSED WORK
Here we define the process which are involved in proposed algorithm .It is an algorithm that work on utility mining along with differential privacy .There are the following steps that shows how algorithm work.
a)The very first step is to collect the database.
b)Collected database is mined by high utility mining algorithm to get utility itemset.
c)In this step predefined threshold value is used. The items set whose value is greater than the threshold value are selected for next step and items below threshold are discarded. Here threshold value can be defined by user itself.
d)The collected high utility item set are masked by noise using differential privacy. Laplace Mechanism is used for this purpose. The mechanism is applied until we get the desired output.
[image:3.612.328.561.138.342.2]e)The values obtained are stored in new database. The new database is called the sanitized database. Before adding value to it the value must be brought below the threshold.
Figure 1 Example of Transactional Database with utility value greater than threshold.
A. Example for Transactional Database
To better understand the working of proposed algorithm we are giving an example.
The tables defined above are used in this example.
Step 1:-
Firstly calculate the utility value of each item set pair in the database. Choose the highest utility from it. To calculate the net utility of item set following formula is used-
For 1- item set pairs: u(S) = 15 * 6 = 90, so on.
For 2-itemset: u(P,T) = u({P,T},Tr2) + u({P,T},Tr4)
= {( 3*4 +1*8) + (7*4 + 4*8)}= 80
Similarly, we will find for all the item set pair. The highest value is on the item set pair: - u(PR) = 184.
Step 2:-
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 7, Issue 9, September 2017)
369 Step 3:-.
Find the utility value of each item set greater than threshold value from the paired item set.For example- u(T)= 160, U(QT)=122 etc.
Step 4:-
Here, the item set of highest length and high utility value among the pair is u({P,R,T}) = 150.
Step 5:-
Values greater than threshold are changed in this step. The utility values for P,R,T pair are as follows-
P R T
T2 12 10 1
T4 28 60 32
It is seen clearly that R in transaction T4 has the highest value.
Step 6:-
When the item set values are less then threshold they will directly updated in to the new database otherwise Laplace mechanism is used to lower the utility values of item set.
Step 7:-
Adding Laplace noise is an iterative function it continues till the value below the threshold is achieved. The table below shows that the utility value of R is reduced from 12 to 0 to make it value lesser than threshold.
Step 8:-
The value of R is now updated in to every pair where it is used.
Step 9:-
By this algorithm we can also preserve the privacy for multiple databases. It performs well with multiple databases. The time to execute the algorithm is less than the base algorithm.
In this way privacy is preserve using the Laplace mechanism with differential privacy.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 7, Issue 9, September 2017)
370
IV. RESULT ANALYSIS
The experimental analysis is carried out for algorithm on privacy preserving using Genetic algorithm and on our proposed work. For achieving the great result we here used MATLAB for simulation purpose. Database has been taken from UCI (University of California – Center Machine Learning and Intelligent System). It is a type of synthetic dataset with 3000 transaction that have been performed on 5 item set.
A. Evaluation Matrices
Oliveira and Zaine (2002) introduced many factors on which effectiveness of an algorithm can be measured.
CPU Usage time: Time taken by ‘m’ no. of records to execute and finish the transaction .It is calculated
[image:5.612.320.566.225.405.2]
Figure 2: Comparison of Proposed and Base algorithm over CPU Utilization..
Figure shows the comparison between the proposed algorithm and earlier algorithm
This graph clearly shows that the CPU time decreases in proposed algorithm.
Eventually it will take less time in execution and provide higher productivity.
Hiding failure (HF)
:
This parameter is evaluated by the information that is exposed after and before the sanitizing process. To achieve zero hiding failure many algorithms have been developed. It is the ratio of sensitive item sets that are disclosed before and after the sanitizing process. Its formula-Here U(TD’) and U(TD) are the sensitive item sets obtained from the sanitized database and the original database respectively.
TABLE III
HIDING FAILURE WITH 5- ITEMSET
V. CONCLUSION
In this paper we proposed a differential privacy algorithm on utility mining. It’s a type of mathematical method which provides high accuracy. As to satisfy differential privacy Laplace mechanism is used. Comparison is made between the proposed algorithm and the genetic algorithm. We have found that it performs better than the base algorithm. We can conclude that the use of differential privacy leads to high accuracy but it require lot of knowledge for its execution.
REFERENCES
[1] Elisa Bertino, Dan Lin, and Wei Jiang. A Survey of Quantification
of Privacy Preserving Data Mining Algorithms. In Purdue University, 305 N. University St., West Lafayette, IN, USA
[2] Samir Patel, Gargi Shah and Aniket Patel.2014. Techniques of Data
Perturbation for Privacy Preserving Data Mining. In International Journal of Advent Research in Computer & Electronics (IJARCE). Vol.1, No.2.
[3] Divvela. Srinivasa Rao and Dr.V.Sucharita. 2016. Techniques for
Mining High Utility Itemsets from Transactional Databases. In International Journal of Advanced Research in Computer Science and Software Engineering. ISSN: 2277 128X. Volume 6, Issue 3.
[4] Smita R. Londhe, Rupali A. Mahajan and Bhagyashree J. Bhoyar.
2013. Overview on Methods for Mining High Utility Itemset from Transactional Database. In International Journal of Scientific Engineering and Research (IJSER). ISSN (Online): 2347-3878. Volume 1 Issue 4.
[5] Ying Liu, Wei-keng Liao and Alok Choudhary. 2005. A Fast High
Utility Item sets Mining Algorithm. In UBDM '0, Chicago, Illinois, USA.
Min. Utility Threshold
Effective Hiding Failure
Base Algorithm Hiding Failure
Resulting Hiding Failure
500 0.0 0.0 0.0
1000 0.0 0.30 0.0
2000 0.0 0.41 0.25
[image:5.612.56.295.325.564.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 7, Issue 9, September 2017)
371 [6] Cynthia Dwork. The Promise of Differential Privacy A Tutorial on
Algorithmic Techniques Microsoft Research, Silicon Valley, Mountain View, CA 94043.
[7] Arik Friedman and Assaf Schuster. 2010. Data Mining with
Differential Privacy. In KDD’10, Washington, DC, USA.
[8] Jyothi Pillai and O.P.Vyas. 2010. Overview of Item set Utility
Mining and its Applications. In International Journal of Computer Applications (0975 – 8887), Volume 5 – No.11.
[9] Chun-Wei Lin, Guo-Cheng Lan and Tzung-Pei Hong. 2012. An
incremental mining algorithm for high utility item sets. In Expert system with Application (39).
[10] Jieh-Shan Yeh and Po-Chiang Hsu. 2010. HHUIF and MSICF:
Novel algorithms for privacy preserving utility mining. In Expert system with Application (37).
[11] Sugandha Rathi, Rishi Soni and Virendra Singh Kushwah. 2016. A