The Replace Operator
Full text
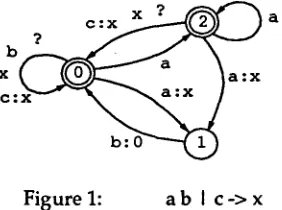
Figure
Related documents
‘Delivering Change in the Higher Education Sector’, Higher Education Leadership Conference, Dublin.. This Presentation is brought to you for free and open access by the Centre
Network Reconfiguration DER Management Load Forecasting Volt VAR Optimization Intelligent Alarm Processing Relay Study Capability Adaptive Protection Closed
were by right the emperors whom Christ and St Peter had commanded that all Christians should obey. The exalted nature of the emperor’s position was reflected in his
In case of accumulators supplied without pre-loading pressure, or after repair work, it is necessary to precharge the accumulator with nitrogen using equipment type-PC following
Sheet metal used for aircraft construction and repair is formed from ingots of aluminum alloy that are passed through a series of rollers until the metal is reduced to a
Our dedicated Employee Fleet Solutions team work closely with our Garage Services and Vehicle Transport Logistics divisions to ensure clients receive a fast and efficient service.
With regard to the importance of the social context of graffiti writing (Lachmann, 1988), some graffiti writers may be unwill- ing to write the kinds of things they write in
Three groups of explanatory factors were explored for the structural value-added and output growth of BS industry compared to the rest of the market sector: (i) different growth
