A u t o m a t i c
D i s c o v e r y o f N o n - C o m p o s i t i o n a l
C o m p o u n d s
i n P a r a l l e l D a t a *
I. Dan
Melamed
Dept. of Computer and Information Science
University of Pennsylvania
Philadelphia, PA, 19104, U.S.A.
melamed~unagi, c i s . upenn, edu
http ://www. c i s . upenn, edu/"melamed
Abstract
Automatic segmentation of text into min- imal content-bearing units is an unsolved problem even for languages like English. Spaces between words offer an easy first ap- proximation, but this approximation is not good enough for machine translation (MT), where many word sequences are not trans- lated word-for-word. This paper presents an efficient automatic method for discover- ing sequences of words that are translated as a unit. The method proceeds by com- paring pairs of statistical translation mod- els induced from parallel texts in two lan- guages. It can discover hundreds of non- compositional compounds on each itera- tion, and constructs longer compounds out of shorter ones. Objective evaluation on a simple machine translation task has shown the method's potential to improve the qual- ity of M T output. The method makes few assumptions about the data, so it can be applied to parallel data other than parallel texts, such as word spellings and pronunci- ations.
1
Introduction
T h e optimal way t o analyze linguistic data into its primitive elements is rarely obvious but often crucial. Identifying phones and words in speech has been a major focus of research. Automati- cally finding words in text, the problem addressed here, is largely unsolved for languages such as Chi- nese and Thai, which are written without spaces * Many thanks to Mike Collins, Jason Eisner, Mitch Marcus and two anonymous reviewers for their feedback on earlier drafts of this paper. This research was sup- ported by an equipment grant from Sun MicroSystems a n d by ARPA Contract #N66001-94C-6043.
(but see Fung & Wu, 1994; Sproat et al., 1996). Spaces in texts of languages like English offer an easy first approximation to minimal content-bearing units. However, this approximation mis-analyzes n o n - c o m p o s i t i o n a l c o m p o u n d s ( N C C s ) such as "kick the bucket" and "hot dog." N C C s are com- pound words whose meanings are a m a t t e r of con- vention and cannot be synthesized from the mean- ings of their space-delimited components. Treating NCCs as multiple words degrades the performance of machine translation (MT), information retrieval, natural language generation, and most other NLP applications.
NCCs are usually not translated literally to other languages. Therefore, one way to discover NCCs is to induce and analyze a translation model between two languages. This paper is about an information- theoretic approach to this kind of ontological dis- covery. The method is based on the insight that treatment of NCCs as multiple words reduces the predictive power of translation models. W h e t h e r a given sequence of words is an NCC can be de- termined by comparing the predictive power of two translation models that differ on whether they t r e a t the word sequence as an NCC. Searching a space of data models in this manner has been proposed be- fore, e.g. by Brown et al. (1992) and Wang et al. (1996), but their particular methods have been lim- ited by the computational expense of inducing d a t a models and the typically vast number of potential NCCs that need to be tested. T h e m e t h o d presented here overcomes this limitation by making indepen- dence assumptions t h a t allow hundreds of NCCs to be discovered from each pair of induced translation models. It is further accelerated by heuristics for gauging the a priori likelihood of validation for each candidate NCC.
lation models, and their corresponding objective functions. The different objective functions lead to different mathematical formulations of predictive power, different heuristics for estimating predictive power, and different classifications of word sequences with respect to compositionality. Monolingual prop- erties of NCCs are not considered by either ob- jective function. So, the m e t h o d will not detect phrases t h a t are translated word-for-word despite non-compositional semantics, such as the English metaphors "ivory tower" and "banana republic," which translate literally into French. On the other hand, the m e t h o d will detect word sequences that are often paraphrased in translation, but have per- fectly compositional meanings in the monolingual sense. For example, "tax system" is most often translated into French as "r6gime fiscale." Each new batch of validated NCCs raises the value of the ob- jective function for the given application, as demon- strated in Section 8. You can skip ahead to Table 4 for a r a n d o m sample of the NCCs t h a t the method validated for use in a machine translation task.
The NCC detection m e t h o d m a k e s some assump- tions a b o u t the properties of statistical translation models, but no assumptions about the d a t a from which the models are constructed. Therefore, the m e t h o d is applicable to parallel d a t a other t h a n parallel texts. For example, Section 8 applies the m e t h o d to orthographic and phonetic representa- tions of English words to discover the NCCs of English orthography.
2 T r a n s l a t i o n M o d e l s
A translation model can be constructed auto- matically from texts t h a t exist in two languages ( b i t e x t s ) (Brown et al., 1993; Melamed, 1997). The more accurate algorithms used for construct- ing translation models, including the EM algorithm, alternate between two phases. In the first phase, the algorithm finds and counts the most likely links between word tokens in the two halves of the bi- text. L i n k s connect words that are hypothesized to be mutual translations. In the second phase, the algorithm estimates translation probabilities by di- viding the link counts by the total number of links. Let S and 7- represent the distributions of linked words in the source and target 1 texts. A simple t r a n s l a t i o n m o d e l is just a joint probability dis- tribution P r ( s , t ) , which indicates the probability that a randomly selected link in the bitext links
1In the context of symmetric translation models, the words "source" and "target" are merely labels.
s E S w i t h t E 7-. 2 A d i r e c t e d t r a n s l a t i o n
m o d e l can be derived in the standard way:
Pr(tls ) = Pr(s, t)/Pr(s).
3 O b j e c t i v e F u n c t i o n s
The decision whether a given sequence of words should count as an NCC can be made automatically, if it can be expressed in terms of an explicit objective function for the given application. T h e first appli- cation I will consider is statistical machine trans- lation involving a directed translation model and a target language model, of the sort advocated by Brown et al. (1993). If only the translation model may be varied, then the objective function for this application should be based on how well the transla- tion model predicts the distribution of words in the target language. In information theory, one such ob- jective function is called mutual information. M u - t u a l i n f o r m a t i o n measures how well one r a n d o m variable predicts another3:
P r ( s , t )
I(S; T ) = ~ ~ Pr(s, t)
log
Pr(s) P r ( t ) (1)sES t E T
When Pr(s, t) is a text translation model, mutual information indicates how well the model can predict the distribution of words in the target text given the distribution of words in the source text, and vice versa. This objective function may also be used for optimizing cross-language information retrieval, where translational distributions must be estimated either for queries or for documents before queries and documents can be compared (Oard & Dorr, 1996).
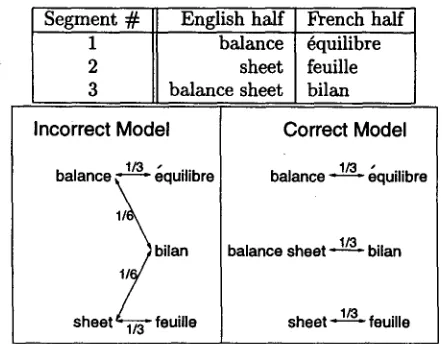
Figure 1 shows a simple example of how recognition of NCCs increases the mutual infor- mation of translation models. T h e English word "balance" is most often translated into French as "6quilibre" and "sheet" usually becomes "feuille." However, a "balance sheet" is a "bilan." A trans- lation model that doesn't recognize "balance sheet" as an NCC would distribute the translation prob- abilities of "bilan" over multiple English words, as shown in the Incorrect Model. T h e Incorrect Model is uncertain about how "bilan" should be trans- lated. On the other hand, the Correct Model, which recognizes "balance sheet" as an NCC is com- pletely certain about its translation. As a result, the mutual information of the Incorrect Model is 2 . 71 log ~_._ + 2 • gx log ~_._ =~2 log 2, whereas the
2 3 2 3
mutual information of the Correct Model is log 3. 2s E S means that Prs(s) > 0.
Segment # 1 2 3
English half balance sheet balance sheet
French half ~quilibre feuille bilan
Incorrect Model
1/3 -
balance
~-~ equUibre
1/6~ bilan
sheet
~ feuille
Correct Model
balance " 1/3, ~quilibre
balance sheet - 1/3 bilan
sheet, 1/3. feuille
Figure 1: Two translation models that my be induced from the trivial bitext at the top of the figure. Trans- lation models that know about NCCs have higher mu- tual information than those that do not.
4
P r e d i c t i v e V a l u e F u n c t i o n s
An explicit objective function immediately leads to a simple test of whether a given sequence of words should be treated as an NCC: Induce two transla- tion models, a t r i a l t r a n s l a t i o n m o d e l that in- volves the candidate NCC and a b a s e t r a n s l a t i o n m o d e l t h a t does not. If the value of the objective function is higher in the trial model than in the base model, then the NCC is valid; otherwise it is not. In theory, this test can be repeated for each sequence of words in the text. In practice, texts contain an enormous number of word sequences (Brown et al., 1992), only a tiny fraction of which are NCCs, and it takes considerable computational effort to induce each translation model. Therefore, it is necessary to test many NCCs on each pair of translation models. Suppose we induce a trial translation model from texts E and F involving a number of NCCs in the language ,5 of E , and compare it to a base transla- tion model without any of those NCCs. We would like to keep the N C C s that caused a net increase in the objective function I and discard those t h a t caused a net decrease. We need some method of assigning credit for the difference in the value of I between the two models. More precisely, we need a function iT(s) over the words s E ,5 such that
I(S; 7-) = ~ iT(s).
(2)
sE8
Fortunately, the objective function in Equations 1 is already a summation over source words. So, its
value can be distributed as follows:
iT(S) Z PrCs, "'" Pr(s, t)
= ~) l o g Pr(s) Pr(t) (3)
t E T
The p r e d i c t i v e v a l u e f u n c t i o n iT(s) represents the contribution of s to the objective function of the whole translation model. I will write simply i(s) when T is clear from the context.
Comparison of predictive value functions across translation models can only be done under
A s s u m p t i o n 1 Treating the bigram < x, y > as an N C C will not affect the predictive value function of any s E ,5 other than x, y, and the N C C xy. Let i and i' be the predictive value functions for source words in the base translation model and in the trial translation model, respectively. Under As- sumption 1, the net change in the objective function effected by each candidate NCC x y is
zx=, = i'(x) + i'(y) + i ' ( x y ) - - i ( u ) . (4)
If A=u > 0, then x y is a valid NCC for the given application.
Assumption 1 would likely be false if either x or y was a part of any candidate NCC other than xy. Therefore, NCCs that are tested at the same time must satisfy the m u t u a l e x c l u s i o n c o n d i t i o n : No word s E ,5 may participate in more than one candi- date NCC at the same time. Assumption 1 may not be completely safe even with this restriction, due to the imprecise nature of translation model construc- tion algorithms.
5
I t e r a t i o n
The mutual exclusion condition implies t h a t mul- tiple tests must be performed to find the majority of NCCs in a given text. Furthermore, Equation 4 allows testing of only two-word NCCs. Certainly, longer NCCs exist. Given parallel texts E and F , the following algorithm runs multiple NCC tests and allows for recognition of progressively longer NCCs:
1. Initialize the stop-list and the NCC list to be empty.
. In E, find all occurrences of all NCCs on the NCC list, and replace them with single "fused" tokens, which the translation model construc- tion algorithm will t r e a t as single words.
[image:3.612.69.290.72.244.2]4. For all adjacent bigrams < x , y > in E that are not on the stop-list and whose frequency is at least ¢4, compute ~xu, the estimate of A~y, using the equations in Section 6.
5. Make a list of candidate NCCs, containing all the bigrams for which A~u > 0, sorted by A~u"
6. Remove from the list all candidates x y where either x or y is part of another bigram higher in the list. This step implements the mutual exclusion condition described in Section 4.
7. C o p y E t o E ' . For e a c h b i g r a m < x , y > re- maining on the candidate NCC list, fuse each instance of < x, y > in E ' into a single token x y .
8. Induce a trial translation model between E ' and F .
9. Compute the actual Axu values for all candidate NCCs, using Equation 4.
10. For each candidate NCC x y , if A~y > 0, then add x y to the NCC list; otherwise add x y to the stop-list.
11. Repeat from Step 2.
T h e algorithm can also be run in "two-sided" mode, so t h a t it looks for NCCs in E and in F on alternate iterations. This mode enables the translation model to link NCCs in one language to NCCs in the other. In its simplest form, the algorithm only considers adjacent words as candidate NCCs. However, func- tion words are translated very inconsistently, and it is difficult to model their translational distributions accurately. To make discovery of NCCs involving function words more likely, I consider content words t h a t are separated by one or two functions words to be adjacent. Thus, NCCs like "blow ... whistle" and
"icing ... cake" may contain gaps.
Fusing NCCs with gaps may fuse some words in- correctly, when the NCC is a frozen expression. For example, we would want to recognize t h a t "icing . . . cake" is an NCC when we see it in new text, but not if it occurs in a sentence like "Mary ate the icing off the cake." It is necessary to deter- mine whether the gap in a given NCC is fixed or not. Thus, the price for this flexibility provided by NCC gaps is that, before Step 7, the algorithm fills gaps in proposed NCCs by looking through the text.
4The threshold ¢ reduces errors due to noise in the data and in the translation model. It should be opti- mized empirically for each kind of parallel data. For parallel texts, I use ¢ = 2.
Sometimes, NCCs have multiple possible gap fillers, for example "make up {my, your,his,their} mind." When the gap filling procedure finds two or three possible fillers, the most frequent filler is used, and the rest are ignored in the hope t h a t they will be discovered on the next iteration. When there are more than three possible fillers, the NCC retains the gap. The token fuser (in Steps 2 and 7) knows to shift all words in the NCC to the location of the leftmost word. E.g. an instance of the previous ex- ample in the text might be fused as "make_up_< G A P >_mind his."
In principl~ the NCC discovery algorithm could iterate until Axy < 0 for all bigrams. This would be a classic case of over-fitting the model to the training data. NCC discovery is more useful if it is stopped at the point where the NCCs discovered so far would maximize the application's objective func- tion on new data. A domain-independent m e t h o d to find this point is to use held-out d a t a or, more gen- erally, to cross-validate between different subsets of the training data. Alternatively, when the applica- tions involves human inspection, e.g. for bilingual lexicography, a suitable stopping point can be found by manually inspecting validated NCCs.
6 C r e d i t E s t i m a t i o n
Sections 3 and 4 describe how to carry out NCC validity tests, but not how to choose which NCCs to test. Making this choice at random would make the discovery process too slow, because the vast majority of word sequences are not valid NCCs. T h e discovery process can be greatly accelerated by testing only candidate NCCs for which Equation 4 is likely to be positive. This section presents a way to guess whether Axy > 0 for a candidate NCC x y be]ore inducing a translation model t h a t involves this NCC. To do so, it is necessary to estimate i ' ( x ) , i ' ( y ) , and i ' ( x y ) , using only the base translation model.
First, a bit of notation. Let LC and Rc denote word contexts to the left and to the right. Let (x : RC = y) be the set of tokens of x whose right context is y, and vice versa for (y : LC = x). Now, i'(x) and i ' ( y ) , can be estimated under
A s s u m p t i o n 2 W h e n x occurs without y in its context, it will be linked to the s a m e target words by the trial translation model as by the base translation model, and likewise ]or y without x.
Assumption 2 says that
i'(x) = i ( x : Rc # y)
i'(y) = i(y : LC ~ x)
i'(xy)
(by Eq. 8)
(by Eq. 9)
(by Eq. 10)
Pr(xy, t)
= E Pr(xy, t) log Pr(xy) Pr(t)
fEW
= E [ P r ( x : RC = y , t ) + P r ( y : LC = x , t ) l l o g [Pr(x: RC = y , t ) + P r ( y : LC = x,t)]
teT Pr(y : LC = x) Pr(t)
Pr(x : Rc = y, t)
= E P r ( x : a c = Y ' t ) l ° g P r ~ a c ~ - ~ r ( t )
t E T
Pr(y : LC = x, t) + E P r ( Y : LC = x , t ) ! o g P r ( y : LC = x) Pr(t)
t E T
(5)
Figure 2: Estimation of i'(xy). Note that, by definition, Pr(x : R C = y) = Pr(y : LC = X) ---- Pr(xy).
Estimating i'(xy) is more difficult because it re- quires knowledge of the entire translational distribu- tions of both x and y, conditioned on all the contexts of x and y. Since we wish to consider hundreds of candidate NCCs simultaneously, and contexts from many megabytes of text, all this information would not fit on disk, let alone in memory. The best we can do is approximate with lower-order distributions that are easier to compute.
The approximation begins with
A s s u m p t i o n 3 I f xy is a valid NCC, then at most one of x and y will be linked to a target word when- ever x and y co-occur.
Assumption 3 implies that for all t E T
Pr(xy, t) = P r ( x : a c = y , t ) + P r ( y : LC = x,t) (8)
The approximation continues with
A s s u m p t i o n 4 I f xy is a valid NCC, then for all
t E T , either Pr(x, t) = 0 or Pr(y, t) = 0.
Assumption 4 also implies that for all t E T, either
Pr(x : Re = y , t ) = 0 (9)
o r
P r ( y : LC = x , t ) = 0. (10)
Under Assumptions 3 and 4, we can estimate i'(xy)
as shown in Figure 2.
The final form of Equation 5 (in Figure 2) allows us to partition all the terms in Equation 4 into two sets, one for each of the components of the candidate NCC:
Amy = £m~y + £me-y (11)
where
+
+
- i ( x ) (12)
Pr(x : RC ~ y, t) E Pr(x : aC ~ y, t) log Pr(x, a c ~ y) Pr(t)
t E T
Pr(x : a c = y, t)
E P r ( x : ac = Y ' t ) l ° g p r ~ ; RC ~_ y i ~ r ( t )
t E T
£xe-y = -iCy) (13)
Pr(y : LC ~ x, t) + E P r ( y : LC ¢ X, t) log F r ~ , LC" ~ x) Pr(t)
t E T
Pr(y : LC = x, t) + E P r ( y : LC = x, t) log P r ~ .: I]C ~-- "x)¥~(t)
t ~ T
All the terms in Equation 12 depend only on the probability distributions Pr(x, t), Pr(x : a c = y, t) and Pr(x : RC ¢ y, t). All the terms in Equation 13 depend only on Pr(y,t), Pr(y : LC = x , t )
and Pr(y : LC ¢ x, t). These distributions can be computed efficiently b y memory-external sorting and streamed accumulation.
7 B a g - o f - W o r d s T r a n s l a t i o n
In bag-of-words translation, each word in the source text is simply replaced with its most likely transla- tion. No target language model is involved. For this application, it is sufficient to predict only the maxi- mum likelihood translation of each source word. The rest of the translational distribution can be ignored.
Let m T ( s ) be the most likely translation of each
source word s, according to the translation model:
roT(s) = arg ma2¢ Pr(s, t) (14)
t E r
[image:5.612.66.545.78.222.2]plication follows by analogy with the mutual infor- mation function I in Equation 1:
Pr(s,t)
V(S; T) = ~ E ~(t, re(s)) Pr(s, t)log Pr(s) Pr(t)
8E~ t E T
Pr(s,m(s)) (15)
= ~ Pr(s, re(s)) log Pr(s) Pr(m(s))
s E 8
The Kronecker ~ function is equal to one when its arguments are identical and zero otherwise.
The form of the objective function again permits easy distribution of its value over the s E S:
Pr(s,m(s)) (16)
vT"(s) = Pr(s, re(s))log Pr(s) Pr(m(s))"
The formula for estimating the net change in the objective function due to each candidate NCC re- mains the same:
= ¢ ( = ) + ¢ ( y ) + v ' ( x y ) - v ( x ) - v ( y ) . (17)
It is easier to estimate the values of v' using only the base translation model, than to estimate the values of i', since only the most likely translations need to be considered, instead of entire translational distri- butions, v'(x) and v'(y) are again estimated under Assumption 2:
v'(x) = v(x : Rc # y) (18)
v'(y) = v(y: LC # x) (19)
v~(xy) can be estimated without making the strong
assumptions 3 and 4. Instead, I use the weaker A s s u m p t i o n 5 Let t= and ty be the most frequent translations of x and y in each other's presence, in the base translation model. The most likely transla- tion of xy in the trial translation model will be the more frequent of t= and ty.
Assumption 5 implies that
¢ ( z y ) = max[v( : Rc = y ) , v C y : Lc = x)]. (20)
This quantity can be computed exactly at a reason- able computational expense.
8 E x p e r i m e n t s
To demonstrate the method's applicability to data other than parallel texts, and to illustrate some of its interesting properties, I describe my last exper- iment first. I applied the mutual information ob- jective function and its associated predictive value function to a data set consisting of spellings and pro- nunciations of 17381 English words. Table 1 shows
Iteration Validated NCCs Example
1 er father, her
ng hang
ch chat, school
ou court, could
es files
au august
gh laugh
th this, thin
ough though, through
(none)
sh share
io tension
ph graph
7 tio nation
ow know, how
ck stack
ea near
oo book, tool
ess dress
9 ia partial, facial
10 (none)
Table 1: The NCCs of English orthography discov- ered by the algorithm.
the NCCs of English spelling that the algorithm dis- covered on the first 10 iterations. The table reveals some interesting behavior of the algorithm. The NCCs "er," "ng" and "ow" were validated because this data set represents the sounds usually produced by these letter combinations with one phoneme. The NCC "es" most often appears in word-final posi- tion, where the "e" is silent. However, when "es" is not word-final, the "e" is usually not silent, and the most frequent following letter is "s", which is w h y the NCC "ess" was validated. NCCs like "tio" and
"ough" are built up over multiple iterations, some- times out of pairs of previously discovered NCCs.
[image:6.612.316.534.74.340.2]Iteration Bitext Vocabulary II Number of Number of Validation Number Side Size I] Proposed NCCs Accepted NCCs Rate
English 29617 French 31664 English 29691 French 31768 English 29739 French 31809
647 618 253 245 161 205
105 121 49
41 38 33
16% 20% 19% 17% 24% 16%
Table 2: NCCs proposed and accepted, using the mutual information objective function I.
Iteration Number
1 2 3 4 5
Bitext Side English
French English French English
Vocabulary Size 29617 31664 30333 32384 30711
Number of Proposed NCCs
776 758 399 355 300
Number of Accepted NCCs
758 748 388 340 286
Validation Rate 98% 99% 97% 96% 95%
Table 3: NCCs proposed and accepted, using the simpler objective function V.
approximately 78 hours on a 167MHz UltraSPARC processor, running unoptimized Perl code.
Tables 2 and 3 chart the NCC discovery process. The NCCs proposed for the V objective function were much more likely to be validated than those proposed for I, because the predictive value func- tion v ~ is much easier to estimate a priori than the predictive value function iq In 3 iterations on the English side of the bitext, 192 NCCs were validated for I and 1432 were validated for V. Of the 1432 NCCs validated for V, 84 NCCs consisted of 3 words, 3 consisted of 4 words and 2 consisted of 5 words. The French NCCs were longer on average, due to the frequent "N de N" construction for noun com- pounds.
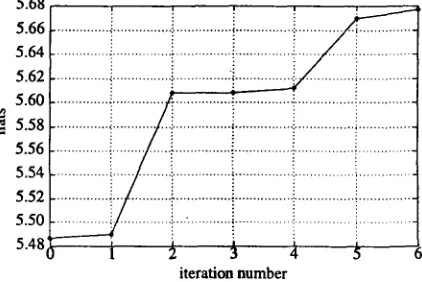
The first experiment on the Hansards involved the mutual information objective function I and its asso- ciated predictive value function in Equation 3. The first step in the experiment was the construction of 5 new versions of the test data, in addition to the original version. Version k of the test data was con- structed by fusing all NCCs validated up to iteration k on the training data. The second step was to in- duce a translation model from each version of the test data. There was no opportunity to measure the impact of NCC recognition under the objective func- tion I on any real application, but Figure 3 shows that the mutual information of successive test trans- lation models rose as desired.
The second experiment was based on the simpler objective function V and its associated predictive value function in Equation 16. The impact of NCC
5.68 5.66 5.64 5.62 5.60
5.58 5.56 5.54 5.52 5.50 5.481
iteration number
Figure 3: Mutual information of successive trans- lation models induced on held-out test data. Nats are a measure of information like bits, but based on the natural logarithm. Translation models that know about NCCs have higher mutual information than those that do not.
[image:7.612.57.474.72.172.2] [image:7.612.302.513.328.469.2]0.536 ... ~ ... : ...
0.534 . . .
0.552 0.554 0.556 0.558 0.560 0.562 0.564
P r e c i s i o n
Figure 4: English ~ French B I B L E scores for 6 translation models. Labels 0 to 5 indicate iteration number.
0 . 5 6 0
0.556
0.558 ... : ...
... i ... ~ ~ 2 ... .i ... i ...
! 5
0.554 ... ~ ~ , ...
0.552 ...
0
5500. 24 0.526 0.528 0.530 0.532 0.534
P r e c i s i o n
Figure 5: French ~ English B I B L E scores for 6 translation models. Labels 0 to 5 indicate iteration number.
lation m e t h o d was always bag-of-words translation, but using different translation models. The simi- larity of two texts was measured in terms of word precision and word recall in aligned sentence pairs, ignoring word order.
I compared the 6 base translation models induced in 6 iterations of the algorithm in Section 5. 5 The first model is numbered 0, to indicate t h a t it did not recognize any NCCs. The 6 translation models were evaluated on the test bitext (E, F ) using the following BIBLE algorithm:
1. Fuse all word sequences in E that correspond to NCCs recognized by the translation model.
2. Initialize the counters a and c to zero.
3. Let b be the number of words in F .
5The entire algorithm was only run six times, but Steps 2 and 3 were run a seventh time.
0 . 5 5 0
Englisl~ -> French i -.-
0.548 French ::-> English :: . . . . . . _ . _ ~ f ~ w ~ V 7 7 ~
~ 0.544 ....* ...
0 . 5 4 2 ... : ... .,~ ... ...~-.,..':::. ... : ...
0.540 :i ...
: i
I
0.538 1 2 3 4 5
Iteration
Figure 6: F-measures f o r B I B L E tests on successive translation models.
4. For each pair of aligned sentences
(e, f ) E (E, F ) ,
(a) For each word s in e, add the most likely translation of s to the trial target sentence
^
f . If t h e m o s t likely translation is an NCC, then break it up into its components. If s is not in the translation model (an unknown word), then add s itself to f .
( b ) a = a +
I]1
(c) For each word in f , check whether it occurs in f . If so, increment the counter c and remove the word from f.6
5. Precision := c/a. Recall : = c/b.
The BIBLE algorithm compared the 6 models in both directions of translation. The results are de- tailed in Figures 4 and 5. Figure 6 shows F-measures t h a t are standard in the information retrieval liter- ature:
2 * precision * recall
F = (21)
precision + recall
The absolute recall and precision values in these fig- ures are quite low, but this is not a reflection of the quality of the translation models. Rather, it is an ex- pected outcome of BIBLE evaluation, which is quite harsh. Many translations are not word for word in real bitexts and BIBLE does not even give credit for synonyms. The best possible performance on this
[image:8.612.328.546.62.212.2] [image:8.612.79.303.65.205.2] [image:8.612.86.304.266.405.2]kind of BIBLE evaluation has been estimated at 62% precision and 60% recall (Melamed, 1995).
The purpose of BIBLE is internally valid compari- son, rather t h a n externally valid benchmarking. On a sufficiently large test bitext, BIBLE can expose the slightest differences in translation quality. The num- ber of NCCs validated on each iteration was never more t h a n 2.5% of the vocabulary size. Thus, the curves in Figures 4 and 5 have a very small range, but the trends are clear.
A qualitative assessment of the NCC discovery m e t h o d can be made by looking at Table 4. It con- tains a r a n d o m sample of 50 of the English NCCs accumulated in the first five iterations of the al- gorithm in Section 5, using the simpler objective function V. All of the NCCs in the table are non- compositional with respect to the objective function V. Many of the NCCs, like "red tape" and "blaze the trail," are true idioms. Some NCCs are incom- plete. E.g. "flow-" has not yet been recognized as a non-compositional part of "flow-through share," and likewise for "head" in "rear its ugly head." These NCCs would likely be completed if the algorithm were allowed to run for more iterations. Some of the other entries deserve more explanation.
First, "Della Noce" is the last name of a Cana- dian Member of Parliament. Every occurrence of this name in the French training text was tok- enized as "Della noce" with a lowercase "n," because "noce" is a common noun in French meaning "mar- riage," and the tokenization algorithm lowercases all capitalized words that are found in the lexicon. When this word occurs in the French text without "Della," its English translation is "marriage," but when it occurs as part of the name, its translation is "Noce." So, the French bigram "Della Noce" is non- compositional with respect to the objective function V. It was validated as an NCC. On a subsequent iteration, the algorithm found t h a t the English bi- gram "Della Noce" was always linked to one French word, the NCC "Dellamoce," so it decided that the English "Della Noce" must also be an NCC. This is one of the few non-compositional personal names in the Hansards.
Another interesting entry in the table is the last one. The capitalized English words "Generic" and "Association" are translated with perfect consis- tency to "Generic" and "association," respectively, in the training text. The translation of the middle two words, however, is non-compositional. When "Pharmaceutical" and "Industry" occur together, they are rendered in the French text without trans- lation as "Pharmaceutical Industry." When they occur separately, they are translated into "pharma-
ceutique" and "industrie." Thus, the English bi- gram "Pharmaceutical Industry" is an NCC, but the words that always occur around it are not part of the NCC.
Similar reasoning applies to "ship unprocessedura-
nium." The bigram < ship, unprocessed > is an NCC because its components are translated non- compositionally whenever they co-occur. However, "uranium" is always translated as "uranium," so it is not a part of the NCC. This NCC demonstrates that valid NCCs may cross the boundaries of gram- matical constituents.
9 R e l a t e d W o r k
In their seminal work on statistical machine trans- lation, Brown et al. (1993) implicitly accounted for NCCs in the target language by estimating "fertil- ity" distributions for words in the source language. A source word s with fertility n could generate a sequence of n target words, if each word in the se- quence was also in the translational distribution of s and the target language model assigned a suffi- ciently high probability to the sequence. However, Brown et al.'s models do not account for NCCs in the source language. Recognition of source-language NCCs would certainly improve the performance of their models, but Brown e~ al. warn t h a t
. . . one must be discriminating in choos- ing multi-word cepts. The caution t h a t we have displayed thus far in limiting ourselves to cepts with fewer than two words was mo- tivated primarily by our respect for the fea- tureless desert t h a t multi-word cepts offer a priori. (Brown et aL, 1993)
The heuristics in Section 6 are designed specifically to find the interesting features in t h a t featureless desert. Furthermore, translational equivalence re- lations involving explicit representations of target- language NCCs are more useful than fertility distri- butions for applications that do translation by table lookup.
"collocations." At least among West European languages, translations of the vast majority of personal names are perfectly compositional.
Several authors have used mutual information and similar statistics as an objective function for word clustering (Dagan et al., 1993; Brown et al., 1992; Pereira et al., 1993; Wang et al., 1996), for au- tomatic determination of phonemic baseforms (Lu- cassen & Mercer, 1984), and for language modeling for speech recognition (Ries ct al., 1996). Although the applications considered in this paper are differ- ent, the strategy is similar: search a space of data models for the one with maximum predictive power. Wang et al. (1996) also employ parallel texts and independence assumptions that are similar to those described in Section 6. Like Brown et al. (1992), they report a modest improvement in model per- plexity and encouraging qualitative results. Unfor- tunately, their estimation method cannot propose more than ten or so word-pair clusters before the translation model must be re-estimated. Also, the particular clustering method that they hoped to im- prove using parallel data is not very robust for low frequencies. So, like Smadja et al., they were forced to ignore all words that occur less than five times. If appropriate objective functions and predictive value functions can be found for these other tasks, then the method in this paper might be applied to them. There has been some research into matching compositional phrases across bitexts. For example, Kupiec (1993) presented a method for finding trans- lations of whole noun phrases. Wu (1995) showed how to use an existing translation lexicon to popu- late a database of "phrasal correspondences" for use in example-based MT. These compositional transla- tion patterns enable more sophisticated approaches to MT. However, they are only useful if they can be discovered reliably and efficiently. Their time may come when we have a better understanding of how to model the human translation process.
10
C o n c l u s i o n
It is well known that two languages are more informative than one (Dagan et al., 1991). I have argued that texts in two languages are not only preferable but necessary for discovery of non- compositional compounds for translation-related ap- plications. Given a method for constructing statis- tical translation models, NCCs can be discovered by maximizing the models' information-theoretic pre- dictive value over parallel data sets. This paper presented an efficient algorithm for such ontologi- cal discovery. Proper recognition of NCCs resulted in improved performance on a simple MT task.
Lists of NCCs derived from parallel data may be useful for NLP applications that do not involve par- allel data. Translation-oriented NCC lists can be used directly in applications that have a human in the loop, such as computer-assisted lexicography, computer-assisted language learning, and corpus lin- guistics. To the extent that translation-oriented definitions of compositionality overlap with other definitions, NCC lists derived from parallel data may benefit other applications where NCCs play a role, such as information retrieval (Evans & Zhai, 1996) and language modeling for speech recognition (Ries et al., 1996). To the extent that different appli- cations have different objective functions, optimizing these functions can benefit from an understanding of how they differ. The present work was a step towards such understanding, because "an explica- tion of a monolingual idiom might best be given af- ter bilingual idioms have been properly understood" (Bar-Hillel, 1964, p. 48).
Count 786 183 79 63 36 34 24 23 17 17 16 14 11 10 10 10
NCC (in italics) in typical context non-compositional translation in French text could have
flow-through shares I repeat
the case I just mentioned tax base
single parent family perform < G A P > duty
red tape
middle of the night Della Noce
heating oil proceeds of crime rat pack
urban dwellers
nuclear generating station Air India disaster
9 Ottawa River 8 I dare hope 8 Ottawa Valley 7 plea bargaining
7 manifestly unfounded claims 7 machine gun
7 a group called Rural Dignity 6 a slight bit
6 cry for help 5 video tape 5 sow the seed 5 arrange a meeting 4 shot-gun wedding 4 we lag behind
4 Great West Life Company
4 Canadian Forces Base and cease negotiations 3 severe sentence
3 rear its ugly head
3 inability to deal effectively with 3 en masse
3 create a disturbance 3 blaze the trail 2 wrongful conviction 2 weak sister
2 of both the users and providers of transportation 2 understand the motivation
2 swimming pool
2 ship unprocessed uranium 2 by reason of insanity
2 l'agence de Presse libre du QuEbec 2 do cold weather research
2 the bread basket of the nation
2 turn back the boatload of European Jews 2 Generic Pharmaceutical Industry Association
pourrait
actions accrgditives je tiens ~ dire
le c a s q u e je viens de mentionner assiette fiscale
famille monoparentale assumer . . . fonction la paperasserie en pleine nuit
Della noce (see text for explanation) mazout
les produits tirds du crime meute
citadins
centrale nucl~aire
dcrasement de l'avion indien Outaouais
j'ose croire
vall~e de l'Outaouais marchandage
avoir revendiqud ~i tort le s t a t u t mitrailleuse
une groupe appel~ Rural Dignity la moindre
appel au secour video
semer
organiser un entretien mariage force
nous trainions de la patte Great West Life Company
mettre fin et interrompre le n~gociation s~v~re sanction
manifests
ne sait pas traiter de mani~re efficace avec en bloc
suscite de perturbation ouvre la voie
erreur judiciaire parent pauvre
des utilisateurs et des transporteurs saisir le motif
piscine
exp~dier de l'uranium non raffin~ pour cause d'ali~nation mentale l'agence de Presse libre du Qudbec ~tudier l'effet du froid
le grenier du Canada
renvoyer tout ces juifs europ~ens
Generic Pharmaceutical Industry Association
[image:11.612.67.547.72.680.2]R e f e r e n c e s
Y. Bar-Hillel. (1964) Language and Information. Addison-Wesley: Reading, MA.
P. Brown, V. J. Della Pietra, P. V. deSouza, J. C. Lai, R. L. Mercer. (1992) "Class-Based n- gram Models of Natural Language," Computa-
tional Linguistics •8(4).
P. F. Brown, V. J. Della Pietra, S. A. Della Pietra & R. L. Mercer. (1993) "The Mathematics of Sta- tistical Machine Translation: Parameter Estima- tion," Computational Linguistics 19(2).
K. W. Church & P. Hanks. (1989) "Word- Association Norms, Mutual Information and Lex- icography," Proceedings of the 27th Annual Meet- ing of the Association for Computational Linguis-
tics. Vancouver, BC.
T. M. Cover & J. A. Thomas. (1991) Elements of In-
formation Theory. John Wiley & Sons: New York,
NY.
I. Dagan, A. Itai & U. Schwall. (1991) "Two Lan- guages are More Informative than One," Proceed- ings of the 29th Annual Meeting of the Association
for Computational Linguistics. Berkeley, CA.
I. Dagan, S. Marcus & S. Markovitch. (1993) "Con- textual Word Similarity and Estimation from Sparse Data," Proceedings of the 31st Annual Meeting of the Association for Computational
Linguistics. Columbus, OH.
B. Daille, l~. Gaussier & J.-M. Lang@. (1994) "To- wards Automatic Extraction of Monolingual and Bilingual Terminology," Proceedings of the 15th International Conference on Computational Lin-
guistics. Kyoto, Japan.
D. A. Evans & C. Zhai. (1996) "Noun-Phrase Anal- ysis in Unrestricted Text for Information Re- trieval," Proceedings of the 34th Annual Meeting of the Association for Computational Linguistics. Santa Cruz, CA.
P. Fung & D. Wu. (1994) "Statistical Augmenta- tion of a Chinese Machine-Readable Dictionary," Proceedings of the 2nd Workshop on Very Large
Corpora. Columbus, OH.
W. Gale, & K. W. Church. (1991) "A Program for Aligning Sentences in Bilingual Corpora" Proceed- ings of the 29th Annual Meeting of the Association
for Computational Linguistics. Berkeley, CA.
J. Kupiec. (1993) "An Algorithm for Finding Noun Phrase Correspondences in Bilingual Corpora," Proceedings of the 31st Annual Meeting of the As-
sociation for Computational Linguistics. Colum-
bus, OH.
J. M. Lucassen & R. L. Mercer. (1984) "An Information-Theoretic Approach to the Auto- matic Determination of Phonemic Baseforms," Proceedings of the IEEE International Confer- ence on Acoustics, Speech and Signal Processing. San Diego, CA.
I. D. Melamed (1995) "Automatic Evaluation and Uniform Filter Cascades for Inducing N-best Translation Lexicons," Proceedings of the Third
Workshop on Very Large Corpora. Boston, MA.
I. D. Melamed. (1997) "A Word-to-Word Model of Translational Equivalence," Proceedings of the 35th Conference of the Association for Computa-
tional Linguistics. Madrid, Spain.
F. Pereira, N. Tishby & L. Lee. (1993) "Distribu- tional Clustering of English Words," Proceedings of the 31st Annual Meeting of the Association for
Computational Linguistics. Columbus, OH.
D. W. Oard & B. J. Dorr. (1996) "A Survey of Multi- lingual Text Retrieval," UMIACS TR-96-19. Uni- versity of Maryland: College Park, MD.
K. Ries, F. D. Buo & A. Waibel. (1996) "Class Phrase Models for Language Modeling," Proceed- ings of the Fourth International Conference on
Spoken Language Processing. Philadelphia, PA.
F. Smadja, K. R. McKeown & V. Hatzivassiloglou. (1996) "Translating Collocations for Bilingual Lexicons: A Statistical Approach," Computa-
tional Linguistics 22(1).
R. Sproat, C. Shih, W. Gale & N. Chang. (1996) "A Stochastic Finite-State Word-Segmentation Algo- rithm for Chinese," Computational Linguistics 22(3):377-404.
Y. Wang, J. Lafferty & A. Waibel. (1996) "Word Clustering with Parallel Spoken Language Corpora," Proceedings of the Fourth Interna- tional Conference on Spoken Language Processing. Philadelphia, PA.
D. Wu. (1995) "Grammarless Extraction of Phrasal Translation Examples from Parallel Texts," Pro- ceedings of the Sixth International Conference on Theoretical and Methodological Issues in Machine