A PARSING ALGORITHM FOR UNIFICATION GRAMMAR
Andrew Haas
D e p a r t m e n t of C o m p u t e r S c i e n c e State U n i v e r s i t y o f N e w Y o r k at A l b a n y
A l b a n y , N e w Y o r k 12222
We describe a table-driven parser for unification grammar that combines bottom-up construction of phrases with top-down filtering. This algorithm works on a class of grammars called depth-bounded grammars, and it is guaranteed to halt for any input string. Unlike many unification parsers, our algorithm works directly on a unification grammar--it does not require that we divide the grammar into a context-free "backbone" and a set of feature agreement constraints. We give a detailed proof of correctness. For the case of a pure bottom-up parser, our proof does not rely on the details of unification - - i t works for any pattern-matching technique that satisfies certain simple conditions.
1 INTRODUCTION
U n r e s t r i c t e d unification g r a m m a r s h a v e the formal p o w e r o f a Turing machine. T h u s there is no algorithm that finds all p a r s e s o f a given s e n t e n c e in a n y unifica- tion g r a m m a r and a l w a y s halts. S o m e unification gram- m a r s y s t e m s j u s t live with this p r o b l e m . A n y general parsing m e t h o d for definite clause g r a m m a r will enter an infinite loop in s o m e cases, and it is the task o f the g r a m m a r writer to avoid this. G e n e r a l i z e d phrase struc- ture g r a m m a r avoids the p r o b l e m b e c a u s e it has only the f o r m a l p o w e r o f c o n t e x t - f r e e g r a m m a r ( G a z d a r et al. 1985), but according to Shieber (1985a) this is not a d e q u a t e for describing h u m a n language.
Lexical functional g r a m m a r e m p l o y s a better solu- tion. A lexical functional g r a m m a r m u s t include a finitely a m b i g u o u s c o n t e x t - f r e e g r a m m a r , which we will call the c o n t e x t - f r e e b a c k b o n e (Barton 1987). A p a r s e r for lexical functional g r a m m a r first builds the finite set o f c o n t e x t - f r e e p a r s e s o f the input and then eliminates those that d o n ' t m e e t the other r e q u i r e m e n t s of the grammar. This method guarantees that the parser will halt. This solution m a y be a d e q u a t e for lexical functional g r a m m a r s , but for o t h e r unification g r a m m a r s finding a finitely a m b i g u o u s c o n t e x t - f r e e b a c k b o n e is a problem. In a definite clause g r a m m a r , an o b v i o u s w a y to build a c o n t e x t - f r e e b a c k b o n e is to k e e p only the t o p m o s t function letters in e a c h rule. T h u s the rule
s ----> n p ( P , N ) v p ( P , N ) b e c o m e s
s - - > n p v p
(In this e x a m p l e we use the notation o f Pereira and W a r r e n 1980, e x c e p t that we do not put square b r a c k e t s around terminals, b e c a u s e this conflicts with standard notation for c o n t e x t - f r e e g r a m m a r s . ) S u p p o s e we use a simple X - b a r theory. L e t m a j o r - c a t e g o r y (Type, Bar- level) denote a p h r a s e in a m a j o r category. A noun phrase m a y consist o f a single noun, for instance, J o h n . This suggests a rule like this:
m a j o r - c a t e g o r y (n,2) --~ m a j o r - c a t e g o r y (n, 1) In the context-free b a c k b o n e this b e c o m e s
m a j o r - c a t e g o r y --* m a j o r - c a t e g o r y
so the c o n t e x t - f r e e b a c k b o n e is infinitely ambiguous. One could devise m o r e elaborate e x a m p l e s , but this one suffices to m a k e the point: not e v e r y natural unification g r a m m a r has an o b v i o u s c o n t e x t - f r e e b a c k b o n e . There- fore it is useful to h a v e a p a r s e r that does not require us to find a c o n t e x t - f r e e b a c k b o n e , but w o r k s directly on a unification g r a m m a r (Shieber 1985b).
We p r o p o s e to g u a r a n t e e that the parsing p r o b l e m is solvable by restricting o u r s e l v e s to d e p t h - b o u n d e d g r a m m a r s . A unification g r a m m a r is d e p t h - b o u n d e d if for e v e r y L > 0 there is a D > 0 such that e v e r y parse tree for a sentential f o r m o f L s y m b o l s has depth less than D. In other words, the d e p t h o f a tree is b o u n d e d by the length of the string it derives. A c o n t e x t - f r e e g r a m m a r is d e p t h - b o u n d e d if and only if e v e r y string of s y m b o l s is finitely ambiguous. W e will generalize the notion of finite ambiguity to unification g r a m m a r s and show that for unification g r a m m a r s , d e p t h - b o u n d e d n e s s is a stronger p r o p e r t y than finite ambiguity.
Copyright 1989 by the Association for Computational Linguistics. Permission to copy without fee all or part of this material is granted provided that the copies are not made for direct commercial advantage and the CL reference and this copyright notice are included on the first page. To copy otherwise, or to republish, requires a fee and/or specific permission.
0362-613X/89/010219-232503.00
Andrew Haas A Parsing Algorithm for Unification Grammar
D e p t h - b o u n d e d unification g r a m m a r s h a v e m o r e for- mal p o w e r than c o n t e x t - f r e e g r a m m a r s . As an e x a m p l e we give a d e p t h - b o u n d e d g r a m m a r for the language x x , which is not context-free. S u p p o s e the terminal s y m b o l s are a through z. W e introduce function letters a ' through z' to r e p r e s e n t the terminals. T h e rules of the g r a m m a r are as follows, with e denoting the e m p t y string.
s ~ x ( L ) x ( L )
x ( c o n s ( A , L ) ) ~ pre-terminal(A) x(L) x(nil) ~ e
p r e - t e r m i n a l ( a ' ) ~ a
p r e - t e r m i n a l ( z ' ) ~ z
T h e r e a s o n i n g behind the g r a m m a r should be c l e a r - - x ( c o n s ( a ' , c o n s ( b ' , n i l ) ) ) derives a b , and the first rule g u a r a n t e e s that e v e r y s e n t e n c e has the f o r m x x . T h e g r a m m a r is d e p t h - b o u n d e d b e c a u s e the depth o f a tree is a linear function o f the length o f the string it derives. A similar g r a m m a r c a n derive the c r o s s e d serial dependen- cies o f Swiss G e r m a n , which according to Shieber (1985a) no c o n t e x t - f r e e g r a m m a r can derive. It is clear w h e r e the e x t r a f o r m a l p o w e r c o m e s from: a context- free g r a m m a r has a finite set o f nonterminals, but a unification g r a m m a r can build arbitrarily large nonter- minal s y m b o l s .
It r e m a i n s to s h o w that there is a parsing algorithm for d e p t h - b o u n d e d unification g r a m m a r s . We h a v e de- v e l o p e d such an algorithm, b a s e d on the c o n t e x t - f r e e p a r s e r of G r a h a m et al. 1980, which is a table-driven parser. I f we generalize the table-building algorithm to a unification g r a m m a r in an o b v i o u s w a y , we get an algorithm that is g u a r a n t e e d to halt for all depth- b o u n d e d g r a m m a r s (not for all unification g r a m m a r s ) . G i v e n that the tables c a n be built, it is e a s y to show that the p a r s e r halts on e v e r y input. This is not a special p r o p e r t y o f o u r p a r s e r - - a straightforward b o t t o m - u p p a r s e r will also halt on all d e p t h - b o u n d e d g r a m m a r s , b e c a u s e it builds partial p a r s e trees in o r d e r o f their depth. O u r contribution is to show that a simple algo- rithm will verify d e p t h - b o u n d e d n e s s w h e n in fact it holds. I f the g r a m m a r is not d e p t h - b o u n d e d , the table- building algorithm will enter an infinite loop, and it is up to the g r a m m a r writer to fix this. In practice we h a v e not found this t r o u b l e s o m e , but it is still an unpleasant p r o p e r t y o f o u r m e t h o d . Section 7 will describe a possible solution for this p r o b l e m .
Sections 2 and 3 o f this p a p e r define the basic c o n c e p t s o f o u r formalism. Section 4 p r o v e s the sound- ness and c o m p l e t e n e s s o f o u r simplest parser, which is purely b o t t o m - u p and e x c l u d e s rules with e m p t y right-hand sides. Section 5 admits rules with e m p t y right sides, and section 6 adds t o p - d o w n filtering. Sec- tion 7 discusses the i m p l e m e n t a t i o n and possible exten- sions.
2 BASIC CONCEPTS
T h e following definitions are f r o m Gallier 1986. L e t S be a finite, n o n e m p t y set o f sorts. An S-ranked alphabet is a pair (E,r) consisting o f a set E t o g e t h e r with a function r :E ~ S* x S assigning a r a n k (u,s) to e a c h s y m b o l f i n ~'~. The string u in S* is the arity o f f and s is the type of
J;
T h e S-ranked alphabets used in this p a p e r h a v e the following p r o p e r t y . F o r e v e r y sort s E S there is a countably infinite set V s of s y m b o l s o f sort s called variables. T h e r a n k o f e a c h variable in V S is ( e , s ) , w h e r e e is the e m p t y string. Variables are written as strings beginning with capitals for instance X, Y, Z. S y m b o l s that are not variables are called function letters, and function letters w h o s e arity is e are called constants. T h e r e can be only a finite n u m b e r of function letters in a n y sort.
T h e set of t e r m s is defined r e c u r s i v e l y as follows. F o r e v e r y s y m b o l f of r a n k (Ul ...Un, S) and a n y t e r m s t~...tn, with e a c h ti o f sort ui, f(t~ .... tn) is a t e r m o f sort s. Since e v e r y sort in S includes variables, w h o s e arity is e, it is clear that there are t e r m s o f e v e r y sort.
A t e r m is called a ground t e r m if it contains no variables. W e m a k e one f u r t h e r r e q u i r e m e n t on o u r r a n k e d alphabets: that e v e r y sort contains a ground term. This can be g u a r a n t e e d b y j u s t requiring at least one c o n s t a n t o f e v e r y sort. It is not clear, h o w e v e r , that this solution is linguistically a c c e p t a b l e - - w e do not wisla to include c o n s t a n t s without linguistic significance j u s t to m a k e sure that e v e r y sort includes a ground term. T h e r e f o r e , we give a simple algorithm for checking that e v e r y sort in S includes a ground term.
L e t T 1 be the set o f sorts in S that include a constant. L e t T i + i be the union o f T i and the set of all s in S such that for s o m e function l e t t e r f o f sort s, the arity o f f is U l . . . u n and the sorts u~,...,Un are in T i. E v e r y sort in T~ includes a ground term, and if e v e r y sort in T~ includes a ground t e r m then e v e r y sort in T i + l includes a ground term. T h e n for all n, e v e r y sort in T n includes a ground terra. The algorithm will c o m p u t e T , for s u c c e s s i v e values o f n until it finds an N such that T N = T N + 1 (this N m u s t exist, b e c a u s e S is finite). I f TN = S, then e v e r y sort in S includes a ground term, o t h e r w i s e not.
As an illustration, let S = {phrase, p e r s o n , number}. L e t the function letters of E be {np, vp, s, 1st, 2nd, 3rd, singular, plural}. L e t r a n k s be assigned to the function letters as follows, omitting the variables.
r(np) = ([person, n u m b e r ] , phrase) r(vp) = ([person, n u m b e r ] , phrase) r(s) = (e, phrase)
r(lst) = (e, n u m b e r ) r(2nd) = (e, n u m b e r ) r(3rd) = (e, n u m b e r ) r [(singular) = (e, person) r(plural) = (e,person)
We h a v e used the notation [a,b,c] for the string o f a, b, and c. Typical t e r m s o f this r a n k e d a l p h a b e t are n p ( l s t ,
Andrew Haas A Parsing Algorithm for Unification Grammar
singular) and vp(2nd, plural). The reader can verify, using the a b o v e algorithm, that e v e r y sort includes a ground term. In this case, T 1 = {person, number}, T2 = {person, number, phrase}, and T a = T 2.
T o summarize: we define ranked alphabets in a standard way, adding the requirements that e v e r y sort includes a countable infinity o f variables, a finite num- ber of function letters, and at least one ground term. We then define the set o f terms in a standard way. All unification in this p a p e r is unification of terms, as in Robinson 1965--not graphs or o t h e r structures, as in much recent work (Shieber 1985b).
A unification grammar is a five-tuple G = (S, (~,r) T, P, Z) where S is a set o f sorts, (~,r) an S-ranked alphabet, T a finite set o f terminal symbols, and Z a function letter o f arity e in (~,r). Z is called the start symbol o f the grammar (the standard notation is S not Z, but by bad luck that conflicts with standard notation for the set o f sorts). P is a finite set o f rules; each rule has the form (A ~ a), where A is a term o f the ranked alphabet and a is a sequence of terms o f the ranked alphabet and symbols from T.
We define substitution and substitution instances of terms in the standard way (Gallier 1986). We also define instances o f rules: if s is a substitution and (A ---> B l ...B n) is a rule, then ( s ( A ) ---> s ( B I ) . . . s ( B , ) ) is an instance o f the rule (A --~ B1...B,). A ground instance o f a term or rule is an instance that contains no variables.
H e r e is an example, using the set o f sorts S from the previous example. L e t the variables o f sort p e r s o n be P 1 , P2 .... and the variables o f sort n u m b e r be N, ,N2... etc. T h e n the rule ( s t a r t ---> n p ( P 1 , N l ) v p ( P , , N , ) has six ground instances, since there are three possible substi- tutions for the variable Pj and two possible substitu- tions for N~ .
We c o m e now to the key definition o f this paper. L e t G = (S, (E,r) T, P, Z) be a unification grammar. The ground grammar for G is the four-tuple (N, T, P ' , Z), where N is the set o f all ground terms o f (E,r), T is the set of terminals o f G, P ' is the set of all ground instances o f rules in P, and Z is the start symbol of G. If N and P ' are finite, the ground grammar is a context-free gram- mar. If N or P ' is infinite, the ground grammar is not a context-free grammar, and it may generate a language that is not context-free. Nonetheless we can define derivation trees just as in a cfg. Following H o p c r o f t and Ullman (1969), we allow derivation trees with nonter- minals at their leaves. Thus a derivation tree may represent a partial derivation. We differ from H o p c r o f t and Ullman by allowing nonterminals other than the start symbol to label the root o f the tree. A derivation tree is an A-tree if the non-terminal A labels its root. The yield o f a derivation tree is the string formed by reading the symbols at its leaves from left to right. As in a cfg, A ~ a iff there is an A-tree with yield a. The language generated by a ground grammar is the set of terminal strings derived from the start symbol. The
language generated by a unification grammar is the language generated by its gl:ound grammar.
The central idea o f this a p p r o a c h is to regard a unification grammar as an abbreviation for its ground grammar. G r o u n d grammars are not always cfgs, but they share m a n y properties of cfgs. T h e r e f o r e if we regard unification grammars as abbreviations for ground grammars, our understanding of cfgs will help us to understand unification grammars. This is of course inspired by Robinson's work on resolution, in which he showed how to " l i f t " a p r o o f p r o c e d u r e for proposi- tional logic up to a p r o o f p r o c e d u r e for general first- order logic (Robinson 1965).
The case o f a finite ground grammar is important, since it is adequate for describing m a n y syntactic phe- nomena. A simple condition will guarantee that the ground grammar is finite. Suppose s I and s 2 are sorts, and there is a function letter o f sort Sl that has an argument of sort s2. Then we say that Sl > s2. L e t > * be the transitive closure o f this relation. If > * is irreflex- ive, and D is the n u m b e r o f sorts, e v e r y term of the ground grammar has depth -< D. T o see this, think o f a ground term as a labeled tree. A path from the root to a leaf generates a sequence o f sorts: the sorts o f the variables and functions letters e n c o u n t e r e d on that path. It is a strictly decreasing sequence according to >*. T h e r e f o r e , no sort occurs twice; therefore, the length of the sequence is at most D. Since there are only a finite n u m b e r of function letters in the ranked alpha- bet, each taking a fixed n u m b e r o f arguments, the n u m b e r of possible ground terms of depth D is finite. Then the ground grammar is finite.
A ground grammar G' is d e p t h - b o u n d e d if for e v e r y integer n there exists an integer d such that e v e r y derivation tree in G' with a yield o f length n has a depth less than d. In o t h e r words, a d e p t h - b o u n d e d grammar cannot build an u n b o u n d e d a m o u n t o f tree structure from a b o u n d e d n u m b e r o f symbols. R e m e m b e r that these symbols may be either terminals or nonterminals, because we allow nonterminals at the leaves of a derivation tree. A unification grammar G is depth- bounded if its ground grammar is depth-bounded.
We say that a unification grammar is finitely ambig- uous if its ground grammar is finitely ambiguous. We can now p r o v e the result claimed above: that a unifica- tion grammar can be finitely ambiguous but not depth- bounded. In fact, the following grammar is completely unambiguous but still not depth-bounded. It has just one terminal symbol, b, and its start symbol is s t a r t .
s t a r t ~ p(O) p(N) ~ p(succ(N)) p ( N ) ---, q ( N )
q (succ(N)) ~ b q ( N ) q(0) ~ e
The function letter " s u c c " represents the successor function on the integers, and the terms 0, succ(0), succ(succ(0)).., represent the integers 0, 1, 2... etc. F o r c o n v e n i e n c e , we identify these terms with the integers
Andrew Haas A Parsing Algorithm for Unification Grammar
they represent. A string o f N o c c u r r e n c e s o f b has just one parse tree. In this tree the start symbol derives p(0), which derives p(N) by N applications of the second rule. p(N) derives q(N), which derives N o c c u r r e n c e s of b by N applications o f the fourth rule and one applica- tion o f the last rule. The reader can verify that this derivation is the only possible one, so the grammar is unambiguous. Yet the start symbol derives p(N) by a tree o f depth N, for e v e r y N. Thus trees whose frontier has only one symbol can still be arbitrarily deep. Then the g r a m m a r c a n n o t be depth-bounded.
We have defined the semantics o f our grammar formalism without mentioning unification. This is delib- erate; for us unification is a computational tool, not a part of the formalism. It might be better to call the formalism " s u b s t i t u t i o n g r a m m a r , " but the other name is already established.
Notation: The letters A, B, and C d e n o t e symbols of a ground grammar, including terminals and nontermi- nals. L o w e r c a s e G r e e k letters d e n o t e strings o f sym- bols. a [i k] is the substring o f a from space i to space k, w h e r e the space before the first symbol is space zero. e is always the e m p t y string. We write x tO y or U(x,y) for the union o f sets x and y, and also (U i < j < k f l j ) ) for the union o f the sets flj) for all j such that i < j < k.
If a is the yield o f a tree t, then to e v e r y o c c u r r e n c e o f a symbol A in ~ there c o r r e s p o n d s a leaf o f t labeled with A. T o e v e r y node in t there c o r r e s p o n d s an o c c u r r e n c e o f a substring in ~----the substring dominated by that node. H e r e is a l e m m a about trees and their yields that will be useful when we consider top-down filtering.
L e m m a 2.1. S u p p o s e t is a tree with yield ~fla' and n is the node o f t corresponding to the o c c u r r e n c e o f / 3 after a in ot/3a'. L e t A be the label of n. If t' is the tree f o r m e d by deleting all descendants o f n from t, the yield o f t' is a A a ' .
Proof: This is intuitively clear, but the careful reader may p r o v e it by induction on the depth of t.
3 OPERATIONS ON SETS OF RULES AND TERMS
T h e parser must find the set o f ground terms that derive the input string and c h e c k w h e t h e r the start symbol is one o f them. We have taken the rules of a unification g r a m m a r as an abbreviation for the set of all their ground instances. In the same way, the parser will use sets o f terms and rules containing variables as a repre- sentation for sets o f ground terms and ground rules. In this section we show how various functions needed for parsing can be c o m p u t e d using this representation.
A grammatical expression, or g-expression, is either a term of L, the special symbol nil, or a pair o f g-expressions. T h e letters u, v, w, x, y, and z denote g-expressions, and X, Y, and Z denote sets o f g- expressions. We use the usual L I S P functions and predicates to describe g-expressions. [x y] is another notation for cons (x,y). F o r any substitution s, s (cons
(x,y)) = cons (s(x),s(y)) and s(Nil) = Nil. A selector is a fianction from g-expressions to g-expressions formed by composition from the functions car, cdr, and identity. Thus a selector picks out a subexpression from a g-expression. A c o n s t r u c t o r is a function that maps two g-expressions to a g-expression, f o r m e d by composition firom the functions cons, car, cdr, nil, (A x y. x), and (A x y. y). A c o n s t r u c t o r builds a new g-expression from parts of two given g-expressions. A g-predicate is a function from g-expressions to Booleans f o r m e d by composition from the basic functions car, cdr, (A x. x), consP, and null.
Let ground(X) be the set of ground instances o f g- expressions in X. I f f is a selector function, let fiX) be the set o f all fix) such that x E X. If p is a g-predicate, let separate ( p , x ) be the set o f all x E X such that p(x). The following lemmas are easily established from the definition of s(x) for a g-expression x.
L e m m a 2.2. I f f i s a selector f u n c t i o n , f (ground(X)) = ground (f(x)).
L e m m a 2.3. If p is a g-predicate, separate (p,ground (X)) = ground(separate (p,x)).
L e m m a 2.4. G r o u n d (X U I") = ground (X) U ground
(I1).
L e m m a 2.5. I f x is a ground term, x E ground(X) i f f x is an instance of some y E X.
L e m m a 2.6. G r o u n d (X) is e m p t y iff X is empty. Proof. A n o n e m p t y set o f terms must have a non- e m p t y set of ground instances, b e c a u s e e v e r y variable belongs to a sort and e v e r y sort includes at least one grotmd term.
T h e s e lemmas tell us that if we u s e sets X and Y o f terms to represent the sets ground(X) and ground(Y) of grotmd terms, we can easily construct representations for ./(ground(x)), separate(p,ground (X)), and ground (X) U ground (Y). Also we can decide w h e t h e r a given ground term is contained in ground(X) and w h e t h e r ground(X) is empty. All these operations will be n e e d e d in the parser.
The parser requires one more type o f operation, defined as follows.
Definition. L e t f l a n d f 2 be selectors and g a construc- tor, and suppose g(x,y) is well defined w h e n e v e r fl(x) andJ2(y) are well defined. The s y m b o l i c p r o d u c t defined by j~, f2, and g is the function
( A X Y. { g(x,y) I x E X A y E Y A f,(x) = f2(Y) }) where X and Y range o v e r sets of ground g-expressions. Note thatfl(x) = f2(Y) is c o n s i d e r e d false if either side o f the equation is undefined.
The symbolic p r o d u c t matches e v e r y x in X against e v e r y y in Y. If fl(x) equals f2(Y), it builds a new structure from x and y using the function g. As an example, suppose X and Y are sets of pairs o f ground terms, and we need to find all pairs [A C] such that for some B, [A B] is in X and [B C] is in Y. We can do this by finding the symbolic p r o d u c t w i t h f l = cdr, f2 = car, and g = (A x y. cons(car(x), cdr(y))). T o see that this is correct, notice that if [A B] is in X and [B C] is in Y, then
Andrew Haas A Parsing Algorithm for Unification Grammar
f~([A B]) = f 2 ([B C]), so the p a i r g ([A B],[B C]) = [A C] m u s t be in the a n s w e r set.
A second e x a m p l e : we can find the intersection of t w o sets of t e r m s b y using a symbolic p r o d u c t w i t h f l = (A X . X), f2 = ()t X . X), and g = (A x y. x).
I f X is a set o f g - e x p r e s s i o n s and n an integer, rename(X,n) is an alphabetic variant o f X. F o r all X, Y, m, and n, if m # n then rename(X,n) and rename(Y,m) h a v e no variables in c o m m o n . The following t h e o r e m tells us that if we use sets o f t e r m s X and Y to r e p r e s e n t the sets ground(X) and ground(Y) o f ground terms, we can use unification to c o m p u t e a n y symbolic p r o d u c t of ground(X) and ground(Y). We a s s u m e the basic facts a b o u t unification as in R o b i n s o n (1965).
T h e o r e m 2.1. I f h is the s y m b o l i c p r o d u c t defined by f~, f2 and g, and X and Y are sets o f g - e x p r e s s i o n s , then
h (ground(X),ground(Y)) =
g r o u n d ( { s ( g ( u , v ) ) l u E rename(X,1) /~ v E r e n a m e ( Y , 2 )
/~ s is the m.g.u, o f fl(u) and fz(v)})
Proof. T h e first step is to show that if Z and W share no variables
(1) {g(z,w) I z E g r o u n d ( Z ) / k w E g r o u n d ( W ) / ~ fl(z) = t"2 (w)} = ground({s(g(u,v)) I u E Z / ~ v ~ W / ~ s is the m.g.u, o f fl(u) and f2(v) })
C o n s i d e r a n y e l e m e n t o f the right side o f equation (1). It must be a ground instance o f s(g(u,v)), where u E Z, v E W, and s is the m.g.u, o f f l ( u ) a n d f z ( v ). A n y ground instance o f s(g(u,v)) can be written as s'(s(g(u,v))), w h e r e s' is c h o s e n so that s'(s(u)) and s'(s(v)) are ground terms. T h e n s'(s(g(u,v))) = g(s'(s(u)),s'(s(v))) and fl(s'(s(u))) = s'(sOCl(U))) = s'(s(f2 (v))) =
f2(s'(s(v))).
T h e r e f o r e s'(s(g(u,v))) belongs to the set on the left side o f equation (1).
N e x t consider a n y e l e m e n t o f the left side of (I). It m u s t h a v e the f o r m g(z,w), where z E ground(Z), w E ground(W), and f l (z) = fz (w). T h e n for s o m e u E Z and v E W, z is a ground instance of u and w is a ground instance o f v. Since u and v share no variables, there is a substitution s' such that s'(u) = z and s'(v) = w. T h e n s ' ( f l (u)) = f l (s'(u)) = f2 (s'(v)) = s'0C2 (V)), SO there exists a m o s t general unifier s f o r f l (u) a n d f z (v), and s ' is the c o m p o s i t i o n o f s and s o m e substitution s". T h e n
g ( z , w ) = g ( s ( s ( u ) ) s(s(v))) = s ( s ( g ( u , v ) ) ) , g ( z , w ) is a ground t e r m b e c a u s e z and w are ground terms, so g(z,w) is a ground instance o f s(g(u,v)) and therefore belongs to the set on the right side o f equation (1).
We h a v e p r o v e d that if Z and W share no variables, (2) h(ground(Z),ground(W)) = ground({s(g(u,v)) I u E Z / ~ v E W / ~ s is the m.g.u, of fl(u) and f2(v)}) F o r a n y X and Y, rename(X, I) and rename(Y,2) share no variables. T h e n we c a n let Z = rename(X,1) and W = rename(Y,2) in f o r m u l a (2). Since h(ground(X), ground(Y)) = h(ground(rename(X, 1)), g r o u n d ( r e n a m e (Y,2))), the t h e o r e m follows by transitivity o f equality. This c o m p l e t e s the proof.Fq
As an e x a m p l e , s u p p o s e X = {[a(F) b(F)]} and Y = {[b(G) c(G)]}. S u p p o s e the variables F and G belong to
a sort s that includes j u s t t w o ground t e r m s , m and n. We wish to c o m p u t e the symbolic p r o d u c t o f ground(X) and ground(Y), u s i n g f l = cdr, f2 = car, and g = (A x y.
cons(car(x), cdr(y))) (as in o u r previous example).
ground(X) equals {[a(m) b(m)],[a(n) b(n)]} and ground(Y) equals {[b(m) c(m)],[b(n) c(n)]}, so the sym- bolic p r o d u c t is {[a(m) c(m)],[a(n) c(n)]}. We will verify that the unification m e t h o d gets the s a m e result. Since X and Y share no variables, we c a n skip the renaming step. L e t x = [a(F) b(F)] and y = [b(G) c(G)]. T h e n f 1 (x) = b(PO, f2 (Y) = b(G), and the m o s t general unifier is the substitution s that replaces F with G. T h e n g(x,y) = [a(F) c(G)] and s(g(x,y)) = [A(G) C(G)]. T h e set of ground instances o f this g-expression is {[A(m) C(m)], [A(n)C(n)]}, as desired.
Definition. L e t f be a function f r o m sets of g- e x p r e s s i o n s to sets o f g - e x p r e s s i o n s , and s u p p o s e that when X C_ X ' and Y C_ Y ' , f ( X , Y ) C_ f ( X ' , Y ' ) . T h e n f i s m o n o t o n i c .
All symbolic p r o d u c t s are m o n o t o n i c functions, as the r e a d e r can easily show f r o m the definition of s y m - bolic products. Indeed, e v e r y function in the p a r s e r that returns a set o f g-expressions is m o n o t o n i c .
4 THE PARSER WITHOUT EMPTY S Y M B O L S
O u r first p a r s e r does not allow rules with e m p t y right sides, since these create complications that o b s c u r e the main ideas. T h e r e f o r e , throughout this section let G be a ground g r a m m a r in which no rule has an e m p t y side. W h e n we say that a d e r i v e s / 3 we m e a n that ~ derives/3 in G. Thus a ~ e iff a = e.
A dotted rule in G is a rule o f G with the right side divided into two parts by a dot. T h e s y m b o l s to the left o f the dot are said to be before the dot, those to the right are after the dot. D R is the set of all dotted rules in G. A dotted rule (A --> a./3) derives a string if a derives that string. To c o m p u t e symbolic p r o d u c t s on sets of rules or dotted rules, we m u s t r e p r e s e n t t h e m as g-expressions. We r e p r e s e n t the rule (A --~ B C) as the list (A B C), and the dotted rule (A --> B.C) as the pair [(A B C) (C) ].
We write A ~ B if A derives B b y a tree with m o r e than one node. T h e p a r s e r relies on a chain t a b l e - - a table o f all pairs [A B] such that A :~, B. L e t C O be the set of all [A B] such that A ~ B b y a derivation tree of depth d. Clearly C1 is the set o f all [A B] such that (A B) is a rule of G. I f S l and $2 are sets o f pairs o f terms, define
link(S~,S 2) = {[A C] [ (3 B. [A B] E $1/~ [B C] E $2) } The function link is equal to the s y m b o l i c p r o d u c t defined by f l = cdr, f2 = car, and g = (h x y . cons(car(x), cdr(y))). T h e r e f o r e we can c o m p u t e link ($1, $2) by applying T h e o r e m 2.1. Clearly C O ÷ i = link(Cd,C0. Since the g r a m m a r is d e p t h - b o u n d e d , there exists a n u m b e r D such that e v e r y derivation tree w h o s e yield contains exactly one s y m b o l has depth less than D. T h e n C D is e m p t y . T h e algorithm for building the chain table is this: c o m p u t e C , for increasing values of
Andrew Haas A Parsing Algorithm for Unification Grammar
n until C n is empty• Then the union of all the C , ' s is the
chain table.
We give an example from a finite ground grammar. Suppose the rules are
(a ~ b) (b -'-> c)
(c--, d)
(d----> k f )
(k ~ g)
(f"-~ h)
The terminal symbols are g and h . Then Cl = {[a b], [b c], [c d]}, C 2 : {[a
c],[b
d]}, and C 3 = {[a d]}. C 4 is empty.Definitions. ChainTable is the set of all [A B] such that A ~ B. If S is a set of dotted pairs of symbols and S' a set of symbols, ChainUp(S,S') is the set of symbols A such that [A B] ~ S for some B ~ S'. " C h a i n U p " is clearly a symbolic product. If S is a set of symbols, close(S) is the union of S and ChainUp(ChainTable,S). By the definition of ChainTable, close(S) is the set of symbols that derive a symbol of S.
In the example grammar, ChainTable is the union of C l , C2, and C3--that is, the set {[
a b],[b c],[c d],[a c],
[b d],[a d]}. ChainUp({ a}) = {}, but ChainUp({ d}) =
{ a,b,c},
close({ a}) = { a}, while close({ at}) = {a,b,c,d}.
L e t a be an input string of length L > 0. For each
a[i
k] the parser will construct the set of dotted rules that derive
a[i k].
The start symbol appears on the left side of one of these rules iffa[i k]
is a sentence of G. By lemma 2.5 this can be tested, so we have a recognizer for the language generated by G. With a small modifi- cation the algorithm can find the set of derivation trees of a. We omit details and speak of the algorithm as aparser
when strictly speaking it is a recognizer only. The dotted rules that derive a[i k] can be partitioned into two sets: rules with m a n y symbols before the dot and rules with exactly one. For each a[i k], the algo- rithm will carry out three steps. First it collects all dotted rules that derivea[i k]
and have m a n y symbols before the dot. F r o m this set it constructs the set of all symbols that derive a[i k], and from these symbols it constructs the set of all dotted rules that derivea[i k]
with one symbol before the dot. The union of the two sets of dotted rules is the set of all dotted rules that derive a[i k]. Note that a dotted rule derives
a[i k]
with more than one symbol before the dot iff it can be written in the form (A ~ fiB./3') where/3~ a[ij], B ~ a[j k],
and i < j < k (this follows because a nonempty string/3 can never derive the empty string in G).If (A --* B . (7) derives
a[ij]
and B derives a[j k], then (A ~ B C .) derivesa[i k].
This observation motivates the following.Definition. If S is a set of dotted rules and S' a set of symbols, AdvanceDot(S,S') is the set of rules (A aB./3) such that
(A ~ a.Bfl) ~ S
and B E S'. ClearlyAdvanceDot
is a symbolic product.F o r example, AdvanceDot({( d ~ k . fi},{ ao'}) equals {(
d----> k f
.)}.Suppose that for each proper substring of a[i k] we have already found the dotted rules and symbols that derive that substring. The following lemma tells us that we can then find the set of dotted rules that derive
a[i k]
with many symbols before the dot.
Lemma 3.1. For i < j < k, let
S(ij)
be the set of dotted rules that derivea[i j],
andS'(j,k)
the set of symbols that derive a[j k]. The set of dotted rules that derivea[i k]
with many symbols before the dot isU AdvanceDot(S(ij),S'(j,k)) i < j < k
Proof. We have
U AdvanceDot({(B ~ / 3 . / 3 s) ~ DR I /3 ~ a[i j]}, i < j < k
{A I A ~ a[j k]})
U {(B ___> /3A. /32) E DR i /3 ~ a[i j ] / \ A ~ a[j k] } i < : j < k
by definition of AdvanceDot
{ ( ] 3 ~ f l A . & ) E D R I ( 3 j . i < j < k / X / 3 ~ a [ i j ] / X A ~ a[j k])}[~
As noted above, this is the set of dotted rules that derive
a[i k]
with more than one symbol before the dot. Definition. If S is a set of dotted rules, finished(S) = { A I ( a - - , / 3 . ) ~ S }.When the dot reaches the end of the right side of a rule, the parser has finished building the symbol on the left side--hence the name
finished.
F o r example, finislaed({( d ~ k f .),(a ~ . b)}) is the set { d}.The next lemma tells us that if we have the set of dotted rules that derive
a[i k]
with m a n y symbols before the dot, we can construct the set of symbols that derive a[i k].Lemma 3.2. Suppose length(a) > 1 and S is the set of dotted rules that derive a with more than one symbol before the dot. The set of symbols that derive a is close(finished(S)).
Proof. Suppose first that A ~ close(finished(S)). Then for some B, A ~ B , (B ~ / 3 . ) is a dotted rule, and /3 ~ a. Then A ~ a. Suppose next that A derives a. We show by induction that if t is a derivation tree in G and A ~ a by t, then A E close(finished (S)). t contains more than one node because length(a) > 1, so there is a rule (A -* A l ... A n) that admits the root of t. If n > 1, (A
At....An.) E S
and A is in close(finished(S)). I f n = 1 then A n -"~ a and by induction hypothesis A n ~ close(fin-ished(S)). Since A ~ A 1, A ~ close(finished(S)). In our example grammar, the set of dotted rules deriving a[0 2] =
gh
with more than one symbol before the dot is {(d ~kf.)},
finished({(d ~ kf.)} )
is { d}, and close({ d} ) = {a,b,c,d}.
It is easy to check that these are all the symbols that derivegh.[3
Definitions. RuleTable is the set of dotted rules (A .a) such that (A ~ a) is a rule of G. If S is a set of symbols, NewRules(S) is AdvanceDot(RuleTable, S).
In our example grammar, NewRules ({k}) = {( d ~ k
• JS},
Lemma 3.3. If S is the set of symbols that derive a,
Andrew Haas A Parsing Algorithm for Unification Grammar
the set o f dotted rules that derive a with one symbol before the dot is NewRules(S).
Proof. Expanding the definitions gives A d v a n c e Dot({( A ---> ./3l (A ---> /3)EP}, { C [ C ~ a}) = {(A --> C./3') (A --> C/3') E P / ~ C ~ a } . This is the set o f dotted rules that derive a with one symbol before the dot.
L e t terminals(i,k) be the set of terminals that derive a[i k]; that is, i f / + 1 = k then terminals(i,k) = {a[i k]}, and otherwise terminals(i,k) = f~. L e t a be a string o f length L > 0. F o r 0 < i < k -< L, define
dr(i,k) = if i + 1 = k
then NewRules(close({ a[i i + 1]}))
U A d v a n c e D o t ( d r ( i j ) , else (let rules 1 = i <j < k
[finished(dr(j,k)) U terminals (j ,k)])
(let rules 2 = NewRules(close(finished(rules0) ) ruleSl U rules2))
Theorem 3.1. F o r 0 <- i < k <- L, dr(i,k) is the set o f dotted rules that derive a[i k].
Proof. By induction on the length of a[i k]. If the length is 1, then i + 1 = k. The algorithm returns NewRules(close({a[i i + 1]})). close({ a[i i + 1]} ) is the set o f symbols that derive a[ i i + 1] (by the definition of ChainTable), and NewRules(close({a[i i + 1]})) is the set o f dotted rules that derive a[i i + 1] with one symbol before the dot (by lemma 3.3). N o rule can derive a[i i + 1] with m a n y symbols before the dot, because
a[i i + 1] has only one symbol. Then NewRules(close
({a[i k]})) is the set of all dotted rules that derive a[i k]. Suppose a[i k] has a length greater than 1. If i < j < k ,
dr(Q) contains the dotted rules that derive a[i j] and
dr(j,k) contains the dotted rules that derive o~[j k], by induction hypothesis. T h e n finished(drfj, k)) is the set of nonterminals that derive a[j k], and terminals(j,k) is the set o f terminals that derive a[j k], so the union o f these two sets is the set of all symbols that derive a[j k]. By lemma 3.1, rules~ is the set of dotted rules that derive a[i k] with m a n y symbols before the dot. By lemma 3.2, close(finished(rules1)) is the set o f symbols that derive a[i k], so by l e m m a 3.3 rules2 is the set o f dotted rules that derive a[i k] with one symbol before the dot. The union o f rulesl and rules2 is the set o f dotted rules that derive a[i k], and this completes the proof.[]
Suppose we are parsing the string gh with our exam- ple grammar. We have
dr(O, 1) = {(k ---> g .),(d ----> k . j")} dr(l,2) = {(f---> h .)}
dr(0,2) = {(d----> k f .),(c---> d . ),(b ~ c . ),(a----> b . )}
5 ThE PARSER WITH EMPTY SYMBOLS
T h r o u g h o u t this section, G is an arbitrary depth- b o u n d e d unification grammar, which may contain rules w h o s e right side is empty. If there are e m p t y rules in the grammar, the parser will require a table o f symbols that derive the e m p t y string, which we also call the table of e m p t y symbols. L e t E d be the set o f symbols that derive
the e m p t y string by a derivation o f depth d, and let E'd be the set o f symbols that derive the e m p t y string by a derivation o f depth d or less. Since the grammar is depth-bounded, it suffices to construct E d for succes- sive values of d until a D > 0 is found such that E D is the empty set.
E I is the set of symbols that immediately derive the empty string; that is, the set of all A such that (A ---> e) is a rule. A ~ E d ÷ 1 i f f t h e r e is a rule (A ---> B 1 ...Bn) such that for each i, B~ ~ e at depth di, and d is the maximum of the di's. In other words: A E Ed ÷ i iff there is a rule (A ~ aB/3) such that B E Ed and e v e r y symbol of a and /3 is in E' d.
L e t D R be a set of dotted rules and S a set o f symbols. Define
AdvanceDot*(DR,S) = if DR = O then Q
else (DR U A d v a n c e D o t * ( A d v a n c e D o t ( D R , S ) , S ) ) If D R is the set o f ground instances o f a finite set of rules with variables, there is a finite bound on the length of the right sides o f rules in D R (because the right side o f a ground instance o f a rule r has the same length as the right side of r). If L is'the length o f the right side o f the longest rule in D R , then A d v a n c e D o t * ( D R , S ) is well defined because the recursion stops at depth L or before. Clearly A d v a n c e D o t * ( D R , S ) is the set of rules (A --> a/3.y) such that (A --> a. /33') E D R and e v e r y symbol of/3 is in S.
L e t S 1 = $2 = $ 3 =
AdvanceDot*(RuleTable, E'd) A d v a n c e D o t ( S l, E'd)
AdvanceDot*(S2, E'o) S 4 = finished(S3)
S~ is the set o f dotted rules (A ---> a./30) such that e v e r y symbol of a is in E'd. $2 is then the set o f dotted rules (A ---> aB./3 0 such that B ~ Ed and e v e r y symbol o f a is in E'd. T h e r e f o r e $3 is the set of dotted rules (A ---> aB/3./32) such that B E Ed and e v e r y symbol o f a and/3 is in E'd. Finally $4 is the set of symbols A such that for some rule (A ---> aBfl), B E E d and e v e r y symbol o f a and/3 is in E' d. Then $4 is E d + i- In this way we can construct Ed for increasing values o f d until the table o f e m p t y symbols is complete.
Here is an example grammar with symbols that derive the empty string:
(a ---> e) (b ---> e) (c ---> ab) (k ---> cfcgc) Oc---> r) (g ~ s)
The terminal symbols are r and s. In this grammar, E l = {a,b}, E2 = {c}, and E 3 = Q.
Definitions L e t E m p t y T a b l e be the set o f symbols that derive the e m p t y string. If S is a set o f dotted rules, let SkipEmpty(S) be AdvanceDot*(S, EmptyTable).
Andrew Haas A Parsing Algorithm for Unification Grammar
Note that SkipEmpty(S) is the set of dotted rules (A ---> a/3!./32) such that (A ~ a./31/32) E S and/3! ~ e.
SkipEmpty(S) contains every dotted rule that can be formed from a rule in S by moving the dot past zero or more symbols that derive the empty string. In the example grammar EmptyTable = {a,b,c}, so SkipEmpty({( k --.-> . cfcgc)}) = {( k ---> . cfcgc), (k ----> c . f c g c ) } . If the dotted rules in S all derive a, then the
dotted rules in SkipEmpty(S) also derive a.
L e t Ca be the set of pairs [A B] such that A ~ B by a derivation tree in which the unique leaf labelled B is at depth d (note: this does not imply that the tree is of depth d). C~ is the set of pairs [A B] such that (A ---> aB/3) is a rule and every symbol of a and/3 derives the empty string. CI is easily computed using SkipEmpty. Also Ca + i = link(Ca,C0, so we can construct the chain table as before.
In the example grammar there are no A and B such that A ~ B , but if we added the rule (k ~ cfc), we would have k ~ f . Note that k d e r i v e s f b y a tree of depth 3, but the path from the root of this tree to the leaf l a b e l e d f i s of length one. Therefore the pair [k]] is in C~.
The parser of Section 4 relied on the distinction between dotted rules with one and many symbols before the dot. If empty symbols are present, we need a slightly more complex distinction. We say that the string a derives /3 using one symbol if there is a derivation of/3 from a in which exactly one symbol of a derives a non-empty string. We say that a derives 13 using m a n y symbols if there is a derivation of/3 from a in which more than one symbol of a derives a nonempty string. If a string a derives a string/3, then a derives/3 using one symbol, or a derives/3 using many symbols, or both. In the example grammar, c f c derives r using one symbol, and c f c g derives rs using many symbols.
We say that a dotted rule derives /3 using one (or many) symbols if the string before the dot derives /3 using one (or many) symbols. Note that a dotted rule derives a[i k] using m a n y symbols iff it can be written as (A --~ /3B/3'./30 w h e r e / 3 ~ a [ i j ] , B ~ a[j k], /3' ~ e, and i < j < k. This is true because whenever a dotted rule derives a string using m a n y symbols, there must be a last symbol before the dot that derives a nonempty string. L e t B be that symbol; it is followed by a/3' that derives the empty string, and preceded by a/3 that must contain at least one more symbol deriving a non-empty string.
We prove lemmas analogous to 3.1, 3.2, and 3.3. L e m m a 4.1. For i < j < k let S(id) be the set of dotted rules that derive a[ij] and S ' ( j , k ) the set of symbols that derive a[j k ]. The set of dotted rules that derive a[i k] using m a n y symbols is
SkipEmptY(i <?< k A d v a n c e D o t ( S ( i d ) , S ' ( j , k ) ) )
Proof. Expanding definitions and using the argument of lemma 3.3 we have
<~< k AdvanceDot({(B ---> /3./30 E SkipEmpty( i
J
D R I / 3 ~ a [ i j ] } , { A I A a[j k]})) =
SkipEmpty ({(B--->/3A./32) E DR I (3 j. i < j < k/X/3 3 a[i j] A A ~ a[j k])})
This in turn is equal to
{(B -~/3A/3'./3a) E DR [ (=1 j. i < j < k / k / 3 ~ a [ i j ] / k A ~ a[j k])
A/3'
~ e}This is the set of rules that derive a[i k] using many symbols, as noted above.
If we have a = rs, then the set of dotted rules that derive a[0 1] is
{ff--~ r .),(k--~ c f . c g c ) , ( k ~ cfc . gc)}
The set of symbols that derive a[1 2] is {g,s}. The set of dotted rules that derive a[0 2] using m a n y symbols is
{(k ~ c f c g . c),(k--> c f c g c .)}
L e m m a 4.1 tells us that to compute this set we must apply SkipEmpty to the output of AdvanceDot. If we failed to apply SkipEmpty we would omit the dotted rule (k ~ c f c g c .) from our answer.
L e m m a 4.2. Suppose length(a) > 1 and S is the set of dotted rules that derive a using m a n y symbols. The set of symbols that derive a is close(finished(S)).
Proof. By induction as in L e m m a 3.2.
Definitions. Let RuleTable' be SkipEmpty({( A --> .a) ( , 4 - ~ a ) E P } ) = {(A--~ a . a ' ) E D R [ a ~ e } . I f S i s a set of symbols let NewRules'(S) be SkipEmpty(Advance Dot(RuleTable' ,S)).
RuleTable' is like the RuleTable defined in Section 4, except that we apply SkipEmpty. In the example gram- mar, this means adding the following dotted rules:
(c ~ a . b) ( c --> ab .) (k ~ c . f c g c )
N e w R u l e s ' ( { f } ) is equal to {( k - - * c f . c g c ) , ( k ~ cfc .
gc)}.
The following lemma tells us that NewRules' will perform the task that NewRules performed in Section 4. L e m m a 4.3. If S is the set of symbols that derive a, the set of dotted rules that derive a using one symbol is N e w R u l e s ' ( S ) .
Proof. Expanding definitions gives
SkipEmpty(AdvanceDot({(A--->/3./31) E DR I /3 ~ e } ,
{ c I c
a}))
SkipEmpty({(A --> tiC.&) E DR [ fl ~ e A C ~ a})
{ ( A ~ /3C/3'./33) E D R I / 3 ~ e / X C ~ a / % / 3 ' ~ e } This is the set of dotted rules that derive a using one symbol, by definition.
Let a be a string of length L. F o r 0 -< i < k - L, define
dr(i,k) = if i + 1 = k
then NewRules'(close({ a[i k]})) else (let rules 1 =
Andrew Haas A Parsing Algorithm for Unification Grammar
SkipEmptY(i < 7< k A d v a n c e D o t ( d r ( i j ) ,
[finished(drfj,k)) U terminals (j,k)]))
(let rules 2 = N e w R u l e s ' ( c l o s e (finished(rules0)) rules I tO rules2))
T h e o r e m 4.1. dr(i,k) is the set o f dotted rules that derive a[i k].
Proof. By induction on the length o f a[i k] as in the p r o o f o f t h e o r e m 3.1, but with lemmas 4.1, 4.2, and 4.3 replacing 3.1, 3.2, and 3.3, r e s p e c t i v e l y . D
If a = rs we find that
dr(0,1) = {(f---~ r .),(k ~ c f . cgc),(k ~ cfc . gc)} dr(l,2) = {(g--* s.)}
dr(0,2) = {(k ~ c f c g . c),(k ~ cfcgc .)}
6 THE PARSER WITH ToP-DOWN FILTERING
We have described two parsers that set dr(i,k) to the set of dotted rules that derive a[i k]. We now consider a parser that uses t o p - d o w n filtering to eliminate some useless rules from dr(i, k). L e t us say that A follows/3 if the start symbol derives a string beginning with/3A. A dotted rule (A ~ X) follows/3 if A follows/3. The new algorithm will set dr(i,k) to the set o f dotted rules that derive a[i k] and follow a[0 i].
If A derives a string beginning with B, we say that A can begin with B. The new algorithm requires a predic- tion table, which contains all pairs [A B] such that A can begin with B. L e t P1 be the set o f pairs [A B] such that (A --~ /3B/3') is a rule and /3 ~ e• L e t P . + 1 be Pn tO L i n k ( P , , P1).
L e m m a 5.1. The set o f pairs [A B] such that A can begin with B is the union o f Pn for all n -> 1.
Proof. By induction on the tree by which A derives a string beginning with B. Details are left to the r e a d e r . I ]
Our problem is to construct a finite representation for the prediction table• T o see w h y this is difficult, con- sider a grammar containing the rule
(f(a,s(X)) --~ f(a,X) g)
Computing the P . s gives us the following pairs o f terms: [f(a,s(X)) f(a,X)]
[f(a,s(s(Y))) f(a,Y)] [f(a,s(s(s(Z)))) f(a,Z)]
Thus if we try to build the prediction table in the obvious way, we get an infinite set o f pairs of terms.
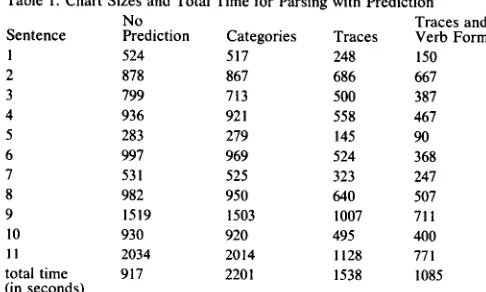
T h e k e y to this problem is to recognize that it is not n e c e s s a r y or e v e n useful to predict e v e r y possible feature o f the next input. It makes sense to predict the p r e s e n c e o f traces, but predicting the subcategorization frame o f a verb will cost more than it saves. T o avoid predicting certain features, we use a weak prediction table; that is, a set o f pairs o f symbols that properly contains the set o f all [A B] such that A ~ B. This weak prediction table is guaranteed to eliminate no more than what the ideal prediction table eliminates. It may leave some dotted rules in dr(i,k) that the ideal prediction table would r e m o v e , but it m a y also cost less to use.
Sato and Tamaki (1984) p r o p o s e d to analyze the behavior o f Prolog programs, including parsers, by using something much like a weak prediction table. T o guarantee that the table was finite, they restricted the depth o f terms occurring in the table• Shieber (1985b) offered a more selective a p p r o a c h - - h i s program pre- dicts only those features c h o s e n by the user as most useful for prediction. Pereira and Shieber (1987) discuss both approaches. We will present a variation o f Shie- b e r ' s ideas that depends on using a sorted language.
T o build a weak prediction table we begin with a set Q1 of terms such that Pi C g r o u n d ( Q 0 . Define
L P ( Q , Q ' ) = {(s [x z]) ] (3 y , y ' . [x y] E Q / ~ [y' z] E Q' A s = m.g.u, o f y and y')}
By T h e o r e m 2.1, ground(LP(Q,Q')) = Link(ground(Q), ground(Q')). L e t Oi + 1 equal Oi LI L P (Oi,Ol). T h e n by lemma 2.3 and induction,
i ~ l P i c_ ground(i >_to l ai)
That is, the union o f the Qi s represents a weak predic- tion table• Thus we have shown that if a weak prediction table is adequate, we are free to c h o o s e any Q1 such that Pt c ground(Q 0.
Suppose that QD subsumes LP(QD,QO. T h e n ground(LP(Qo,QO) c_ ground(QD) and ground(QD + 1) = ground(QD) tO ground(LP(QD, Q0) = ground(QD). Since ground(Q i ÷ 1) is a function of ground(Qi) for all i, it follows that ground(Qi) = ground(Qo) for all i -> D, so ground(QD) = (tO i >-- 1 ground(Qi))• That is, QD is a finite representation o f a weak prediction table. Our problem is to c h o o s e QI so that QD subsumes Qo + i for some D.
L e t sl and s z be sorts. In section 2 we defined sl > s 2 if there is a function letter o f sort s~ that has an argument o f sort s 2. L e t > * be the transitive closure o f > ; a sort t is cyclic if t > * t , and a term is cyclic if its sort is cyclic• P~ is equal to
{[A B] ] (A ~ / 3 • B / 3 ' ) E RuleTable'}
so we can build a representation for P~. L e t us form Q~ from this representation by replacing all cyclic terms with new variables. More exactly, we apply the follow- ing recursive transformation to each term t in the representation of PI:
transformfflh...tn)) = if the sort of f is cyclic then new-variable0
else f l t r a n s f o r m (h)--.transform(tn))
whei-e new-variable is a function that returns a new variable each time it is called.
Then P1 C_ ground(Ql), and Q1 contains no function letters o f cyclic sorts. F o r example, if the function letter s belongs to a cyclic sort, we will turn
[ f(a,s(s(X))) f(a,X)] into
[ f ( a , Z ) f(a, Y)]
If Ql = {[f(a,Z)f(a, Y)]}, then Q2 = {[f(a,V)J(a,W)], so Qi subsumes Q2, and Q1 is already a finite representa- tion o f a weak prediction table. The following lemma
Andrew Haas A Parsing Algorithm for Unification Grammar
shows that in general, the Ql defined a b o v e allows us to build a finite representation o f a weak prediction table. Lemma 5.2. L e t Q~ be a set o f pairs o f terms that contains no function letters o f cyclic sorts, and let Qi be as defined a b o v e for all i > 1. T h e n for some D, QD subsumes LP(QD,Q O.
Proof. N o t e first that since unification n e v e r intro- duces a function letter that did not o c c u r in the input, Q~ contains no function letters o f cyclic sort for any i -> 1. L e t C be the n u m b e r o f noncyclic sorts in the language. T h e n the m a x i m u m depth of a term that contains no function letters o f cyclic sorts is C + 1. Consider a term as a labeled tree, and consider any path from the root o f such a tree to one o f its leaves. The path can contain at most one variable or function letter of each noncyclic sort, plus one variable o f a cyclic sort. T h e n its length is at most C + 1.
Consider the set S o f all pairs o f terms in L that contain no function letters o f cyclic sorts. L e t us partition this set into equivalence classes, counting two terms equivalent if they are alphabetic variants. We claim that the n u m b e r o f equivalence classes is finite. Since there is a finite b o u n d on the depths o f terms in S, and a finite b o u n d on the n u m b e r of arguments o f a function letter in S, there is a finite bound V on the n u m b e r o f variables in any term o f S. L e t v~...vK be a list o f variables containing V variables from each sort. T h e n there is a finite n u m b e r o f pairs in S that use only variables from v~...vK; let S' be the set o f all such pairs. N o w each pair p in S is an alphabetic variant o f a pair in S', for we can replace the variables of p one-for-one with variables from v~...vK. T h e r e f o r e the n u m b e r o f equivalence classes is no more than the n u m b e r o f elements in S'. We call this n u m b e r E. We claim that QD subsumes LP(QD,QI) for some D -< E.
T o see this, suppose that
Qi
does not subsumeLP(Qi,Q1) for all i < E. If Qi does not subsume
LP(Qi,Q1), then Qi÷~ intersects more equivalence
classes than Qi does. Since Q~ intersects at least one equivalence class, QE intersects all the equivalence classes. T h e r e f o r e QE subsumes LP(QE,QI), which was to be p r o v e d . I ]
This l e m m a tells us that we can build a weak predic- tion table for any g r a m m a r by throwing away all sub- terms o f cyclic sort. In the worst case, such a table might be too w e a k to be useful, but our e x p e r i e n c e suggests that for natural grammars a prediction table o f this kind is v e r y effective in reducing the size of the
dr(i,k) s. In the following discussion we will assume that
we have a c o m p l e t e prediction table; at the end of this section we will o n c e again consider weak prediction tables.
Definitions. If S is a set o f symbols, let first(S) = S U { B I (q A E S. [A B] ~ PredTable }. If PredTable is indeed a complete prediction table, first(S) is the set o f symbols B such that some symbol in S can begin with B. I f R is a set o f dotted rules let next(R) = {B ] (3 A,/3,/3'. (A --> /3.B/3') E R }.
Consider the following example grammar: starl ----> a
a-~, rg c --> rh g - - , s h-~, s
The terminal symbols are r and s. In this grammar first({start}) = {start, a,r}, and next({( a --> r . g)}) = { g}.> The following lemma shows that we can find the set o f symbols that follow a[0 j'] if we have a prediction table and the sets of dotted rules that derive a[ij] for all i < j.
Lemma 5.3. Let j satisfy 0 -< j -< length(a). Suppose that for 0 < i < j , S(/) is the set o f dotted rules that follow a[0 i] and derive a[ij] ( i f j = 0 this is vacuous). L e t start be the start symbol of the grammar. T h e n the set of symbols that follow a[0 j'] is
first(ifj = 0 {start}
U next(S(i))))
(o<_i_<<j
Proof. We show first that e v e r y m e m b e r o f the given set follows a[0 Jl. If j = 0, certainly e v e r y m e m b e r of first({start}) follows a[0 0] = e. I f j > 0, suppose that C follows a[0 i], (C --->/3B/3') is a rule, and/3 ~ a[ij]; then clearly B follows a[0 j].
N e x t we show that if A follows a[0 Jl, A is in the given set. We p r o v e by induction on d that if start ~ a[0 j l A a ' by a tree t, and the leaf corresponding to the occula'ence of A after a[0 ./1 is at depth d in t, then A belongs to the given set. If d = 0, then A = start, and j = 0. We must p r o v e that start E first({start}), which is
obvious.
If d > 0 there are two cases. Suppose first that the leaf n corresponding to the o c c u r r e n c e o f A after a[0 j] has younger brothers dominating a n o n e m p t y string (younger brothers o f n are children o f the same father occuJrring to the left of n). T h e n the father o f n is admitted by a rule o f the form (C-->/3A/3'). C is the label o f the father o f n, and /3 consists o f the labels o f the younger brothers o f n in order. T h e n / 3 ~ a[i j], where 0 --- i < j. Removing the descendants o f n's father from t giw~s a tree t' w h o s e yield is a[0 i]Ca'. T h e r e f o r e C follows a[0 i]. We have shown that (C --->/3A/3') is a rule, C follows a[0 i], a n d / 3 ~ a[i j]. T h e n (C ---> /3.A/3') E S(i), A E next(S(/)), and A E (U 0-- < i < j next(S(/))).
Finally suppose that the y o u n g e r brothers o f n dom- inate the e m p t y string in t. T h e n if C is the label of n's father, C can begin with A. Removing the d e s c e n d a n t s of' n's father from t gives a tree t' w h o s e yield begins with a[0 j]C. T h e n C belongs to the given set by induction hypothesis. If C E first(X) and C can begin with A, then A E first(X). T h e r e f o r e A belongs to the given set. This completes the proof.
As an example, let a = rs. T h e n the set o f dotted rules that derive a[0 1] and follow a[0 0] is {(a ---> r . g)}. The dotted rule (c ~ r . h) derives a[0 I], but it does not follow a[0 0] because c is not an element o f first({start}).