ABSTRACT
CHEN, ZEYUAN. High Resolution and Fast Face Completion with Multiple Controllable Attributes via Progressively Attentive Generative Adversarial Networks. (Under the direction of Dr. Christopher G. Healey).
We propose a deep learning approach for high-resolution and fast face completion with multiple
controllable attributes under arbitrary masks. Face completion entails understanding both structural meaningfulness and appearance consistency, both locally and globally, to fill in “holes" whose
content do not appear elsewhere in an input image. It is a challenging task with the difficulty level
increasing significantly with respect to resolution, the complexity of “holes", and the controllable attributes of filled-in fragments. Our system addresses the challenges by learning a fully end-to-end
framework that trains generative adversarial networks (GANs) progressively from low resolution
to high resolution with conditional vectors encoding controllable attributes. We design a novel coarse-to-fine attentive module network architecture. Our model is encouraged to attend to finer
details while the network is growing to a higher resolution, thus being capable of showing progressive
attention to different frequency components in a coarse-to-fine way. We term the module Frequency-Oriented Attentive Module (FAM).
The novel contributions of this work are: (1) Design of network architectures to exploit
infor-mation across multiple scales effectively and efficiently including a progressively attentive GAN architecture that incorporates a novel frequency-oriented attention mechanism; (2) The ability to
produce high-resolution images up to 1024×1024 in size; (3) Design of an attribute controller to
manipulate multiple attributes of the synthesized content; (4) Introduction of new loss functions encouraging sharp completion; (5) A system that can complete faces with large structural and
appearance variations using a single feed-forward computation pass with improved efficiency over
existing approaches.
Both qualitative and quantitative comparisons with state-of-the-art approaches show that our
model synthesizes images with better quality. We also ran a user study that shows our approach
performs significantly better than state-of-the-art methods, based on which images appear most realistic. Additionally, in a Turing-test-like session to judge whether an image is real or generated,
© Copyright 2019 by Zeyuan Chen
High Resolution and Fast Face Completion with Multiple Controllable Attributes via Progressively Attentive Generative Adversarial Networks
by Zeyuan Chen
A dissertation submitted to the Graduate Faculty of North Carolina State University
in partial fulfillment of the requirements for the Degree of
Doctor of Philosophy
Computer Science
Raleigh, North Carolina
2019
APPROVED BY:
Dr. Susan Simmons Dr. Munindar P. Singh
Dr. Tianfu Wu Dr. Christopher G. Healey
DEDICATION
To Caiping, my beloved wife,
without whom none of my success would be possible,
and to my parents, Fujun and Junxia,
BIOGRAPHY
The author, Zeyuan Chen, was born on September 28, 1989 in a small town Huaiyang and raised in Wuhan, China. Now his family is in Beijing.
Zeyuan completed his Ph.D. in computer science, under the supervision of Dr. Christopher G.
Healey, at North Carolina State University and will graduate in May 2019. His research interests lie in the area of compter vision, human-computer interaction, and visualization.
Zeyuan received his master’s degree from Cornell University in 2013 and bachelor’s degree from Huazhong University of Science and Technology in 2008.
Zeyuan lives happily with his wife, a sociologist, in Chapel Hill, NC and they are enjoying their
TABLE OF CONTENTS
LIST OF TABLES . . . vi
LIST OF FIGURES. . . vii
Chapter 1 INTRODUCTION . . . 1
Chapter 2 Related Work . . . 6
2.1 Neural Networks and Deep Learning . . . 7
2.2 Image Generation . . . 8
2.3 Image Completion . . . 11
2.4 Generative Models with Controllable Attributes . . . 14
2.5 Image-to-Image Translation . . . 15
2.6 Face Swapping and Facial Puppetry . . . 18
Chapter 3 Approach . . . 21
3.1 Generative Models . . . 22
3.2 Conditional GANs . . . 25
3.3 Information GANs . . . 27
3.4 Progressive Training of GANs . . . 29
3.5 Problem Formulation . . . 32
3.6 The Proposed Method . . . 33
3.6.1 Pipeline . . . 33
3.6.2 The Proposed Progressively Attentive GAN . . . 37
3.6.3 Attribute Controller . . . 42
3.6.4 GeneratingIobsandAobs. . . 43
3.6.5 Loss Functions . . . 44
3.6.6 Network Architectures . . . 47
Chapter 4 Implementation . . . 48
4.1 Autoencoder Versus UNet . . . 48
4.2 Transposed Convolution Versus Up-Sampling Convolution . . . 52
4.3 Network Structure and Trainning Details . . . 52
Chapter 5 Experiments. . . 58
5.1 Datasets and Experiment Settings . . . 58
5.2 Ablation Study . . . 60
5.3 Quality Comparison With the Context Encoder . . . 61
5.4 Quantitative Comparison with State-of-the-art Methods . . . 62
5.5 Semantic Completion . . . 62
5.6 Attribute Controller . . . 62
5.7 Computation Time . . . 70
5.8 User Study . . . 70
Chapter 6 Conclusion. . . 75
LIST OF TABLES
Table 4.1 The encoder structure . . . 54
Table 4.2 The latent layer structure . . . 54
Table 4.3 The completion component of generatorGcompl . . . 55
Table 4.4 TheToRGBlayers . . . 56
Table 4.5 TheToFilterlayers . . . 56
Table 4.6 The feature network structure . . . 56
Table 4.7 The head classifier structure . . . 57
Table 4.8 The attribute network structure . . . 57
LIST OF FIGURES
Figure 1.1 (a) Face completion results of our method on CelebA-HQ . . . 4
Figure 1.1 (b) Examples of controlling multiple attributes with attribute vectors . . . 5
Figure 1.1 (c) Examples of controlling appearances and transferring facial expressions at the same time . . . 5
Figure 3.1 The structure of Generative Adversarial Networks (GANs) . . . 23
Figure 3.2 An example of the DCGAN[Rad15]generator . . . 25
Figure 3.3 The Conditional GAN (CGAN) [MO14]model . . . 26
Figure 3.4 The information GAN (InfoGAN)[Che16]model . . . 28
Figure 3.5 The progressive training of GANs . . . 30
Figure 3.6 The overall architecture and training process of our approach . . . 32
Figure 3.7 The pipeline of our approach. . . 34
Figure 3.8 An example of predicting landmarks from contextual information. . . 35
Figure 3.9 The progressive growing of GANs . . . 36
Figure 3.10 Comparison between the all-pass filter and the filter learned by FAM. . . 38
Figure 3.11 Linear combination and all-pass filters. . . 39
Figure 3.12 The Frequency-Oriented Attentive Module . . . 40
Figure 3.13 An example of filters learned by FAM . . . 40
Figure 3.14 The value ranges ofF and ˆF . . . 42
Figure 3.15 The facial transfer pipeline . . . 44
Figure 4.1 The structures of autoencoders and UNet . . . 49
Figure 4.2 The results of using UNet naively in a completion model . . . 50
Figure 4.3 Illustrations of a single layer of our architecture . . . 51
Figure 5.1 The ablation study . . . 59
Figure 5.2 More examples of the attentivereadandwritefilters . . . 60
Figure 5.3 Comparison with Context Encoder on high-resolution face completion . . . 61
Figure 5.4 (a1) Examples of high-resolution face completion results from our approach . 63 Figure 5.4 (a2) More examples of high-resolution face completion results from our ap-proach . . . 64
Figure 5.4 (b1) High-resolution face completion results with arbitrary hand-drawn masks 65 Figure 5.4 (b2) More examples of completion results with hand-drawn and random masks 66 Figure 5.5 Examples of controlling multiple attributes with attribute vectors . . . 67
Figure 5.6 (a) Examples of controlling appearance and transferring facial expressions at the same time . . . 68
Figure 5.6 (b) More examples of controlling appearance and transferring facial expres-sions at the same time . . . 69
Figure 5.7 Examples of images used in the user study . . . 71
Figure 5.8 Comparisons on the naturalness: ours and CTX . . . 73
CHAPTER
1
INTRODUCTION
This thesis investigates the problem of constructing completion models for facial images, both
efficiently and effectively, and at high resolutions. Given samples drawn from an unknown data generation process, the goal of completion models is to learn the underlying data distribution so
that when some samples are corrupted, a trained model can recover the missing data and generate
completed samples that are indistinguishable from real ones. Completion models can be applied to various areas, such as dialogue analysis, audio reconstruction, etc. Image completion, in particular,
is an important field of completion models, not only because it has many practical applications,
but also because it is a challenging task due to the high-dimensional data distribution of images. With the rapid development of social media and smart phones, it has become increasingly
popular for people to capture, edit, and share photos and videos. Sometimes, data is “missing” in
the pictures or video frames, and we need a system that is able to learn ways to generate the missing content and complete images with user-chosen constraints from an initial set of exemplar images.
For instance, faces can be occluded by dirty spots on a camera lens, or important components
can be unclear due to overexposure or underexposure. Users may want to remove unwanted parts from images, such as whelk or dark eye circles. Finally, before sharing images, many users prefer
to replace parts of their faces (e.g. eyes or mouths) with more aesthetic components so that the modified images look more attractive, or have more natural expressions.
Image completion is a technique to replace target regions, either missing or unwanted, of images
capability of seeing the unseen has broad applications in visual content editing. Image
comple-tion can be divided in two categories: generic scene image complecomple-tion and specific object image completion (e.g. human faces). Due to the well-known compositionality and reusability of visual
patterns[Gem02], target regions in the former usually have a high chance of containing similar
patterns in either the surrounding context of the same image or images in an external image dataset. Target regions in the latter are more specific, especially when large portions of essential parts of
an object are missing (e.g. facial parts in Figure 1.1). So, the completion entails fine-grained
under-standing of the semantics, structures, and appearance of images, and thus is a more challenging task. Face images have become one of the most popular sources of images collected in peoples’
daily lives and transmitted on social networks. We focus on human face completion in this work.
Two broad frameworks have been discussed in the literature of image completion: data similarity driven methods and data distribution based generative methods. In the first paradigm, texture
synthesis or patch matching are usually used[EL99; Kwa03; Cri03; Wil05; Kom06; Bar09; Dar12;
Hua14; Wex07]. Textures or patches are generated by finding similar exemplars in the known contexts (i.e. the parts of the image we’re completing that are available to us) and then stitched together to
fill in the “holes.” Another is a data-driven method[HE07]that searches a large image database
for plausible patches based on context similarity. These methods are often used for generic scene image completion and their limitations are obvious. They fail when no similar exemplars can be
found in either the context or the external dataset, and thus are not applicable to face completion (as well as other objects) as pointed out in [Iiz17; Yeh17].
Instead of seeking similar exemplars, the second paradigm learns the underlying distribution
governing the data generation with respect to the context. Much progress[Li17b; Yeh17; Yan16; Iiz17; Den16; Pat16; Liu18; Yu18]has been made since the recent resurgence of deep convolutonal neural
networks (CNNs)[LeC89; Kri12a], especially the generative adversarial network (GAN)[Goo14]. We
adopt the data distribution based generative method in our model and address three important issues.First, previous methods are only able to complete faces at low resolutions (e.g. 128×128[Li17b],
176×216[Iiz17]and 256×256[Yu18]).Second, most approaches cannot control the attributes of
the synthesized content. Previous work focuses on generating realistic content. However, users may want to complete the missing parts with certain properties (e.g. facial expressions).Third,
most existing approaches require post processing or complex inference processes. Generally, these
methods[Iiz17; Li17b; Yeh17]synthesize relatively low quality images from which the corresponding content is cut and blended (e.g. with Poisson Blending[Pér03]) with the original context. In order
to complete one image, other approaches[Yeh17; Yan16]need to run thousands of optimization
iterations or feed an incomplete image to CNNs repeatedly at multiple scales.
To overcome the above limitations, we propose a novel progressively attentive GAN to complete
face images at high resolution with multiple controllable attributes (see Figure 1.1). Our network
pro-cessing. It consists of two sub-networks: a completion network and a discriminator. Given face
images with missing content, the completion network tries to synthesize completed images that are indistinguishable from uncorrupted real faces, while keeping their contexts unchanged. The
discriminator is trained simultaneously with the completion network to distinguish completed
“synthesized” faces from real ones.
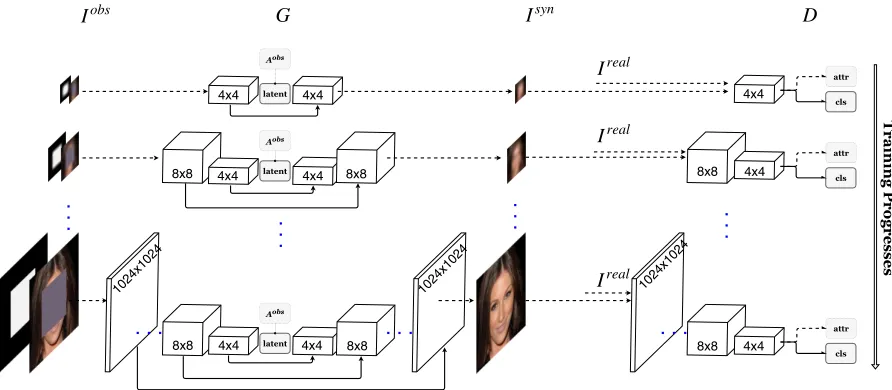
The training methodology of growing GANs progressively[Kar17]is adopted to generate
high-resolution images. Starting from a low high-resolution (i.e. 4×4) network, layers that process
higher-resolution images are incrementally added to the current generator and discriminator simultane-ously. In training, there are two stages at each resolution: growing and stabilizing. At the growing
stage, new layers are faded into the current network smoothly. At the stabilizing stage, the merged
network is trained with more images while keeping the network structures unchanged in order to tune parameters. To avoid distorting the learned parameters at the growing stage, we design a novel
Frequency-Oriented Attentive Module (FAM) to encourage the model to learn face structures in a
coarse-to-fine manner. The filters predicted by FAM are shown in Figure 1.1. With the help of FAM, the model focuses on learning coarse structures (i.e. low-frequency information) in lower resolutions
and switches its attention to finer details (i.e. high-frequency signals) as the resolution increases.
That being said, FAM partially performs as a band-pass filter. Additionally, since the attentive filters are predicted from the semantics of faces, FAM is also location sensitive. For instance, it pays more
attention to regions with richer details (e.g. hair and eyes). Moreover, we design new loss functions inducing the network to blend the synthesized content with the context in a realistic way.
An attribute controller (Figure 1.1) that incorporates the information GAN[Che16]and
condi-tional GAN[MO14]frameworks is designed to control multiple attributes of synthesized images. We use attribute vectors to define whether certain properties (e.g. “male” and “smiling”) exist or not in
the generated images. Additionally, our model can transfer facial expressions of source actors to
synthesized faces with the help of our novel pipeline (Figure 3.7) that integrates facial landmarks as backbone guidance for image completion.
In experiments, we compared our method with state-of-the-art approaches on a high-resolution
face dataset CelebA-HQ[Kar17]. Both qualitative and quantitative evaluation showed that images synthesized by our model had better perceived quality than those generated by existing methods.
The results of a user study showed that our approach completed face images significantly more
naturally than state-of-the-art methods. Moreover, there was a high probability (up to approximately p=0.4) that images generated by our methods could successfully fool human observers when the participants were asked to judge which images were real.
The main contributions of the proposed work are:
frequency-Figure 1.1(a) Face completion results of our method on CelebA-HQ[Kar17]. Our model directly generates completed images based on the input contextual information, instead of searching for similar exemplars in a database to fill in the “holes” (e.g.[Bar09; HE07]).Top:our approach can complete face images at high resolution (1024×1024). The left and right are corrupted and synthesized images respectively in each group.
Middle and Bottom:the frequency-attention filters of readers and writers of the top left image. While the resolution increases from 8×8 to 1024×1024, the model attends on higher frequency information. Regions with rich details (e.g. eyes) get more attention, especially at high resolutions. Best viewed in magnification.
oriented attention mechanism.
• Our model can produce images with a much higher resolution than state-of-the-art algorithms
and handle arbitrary shaped masks.
• We design an attribute controller to manipulate multiple properties of the synthesized content.
• We introduce new loss functions that encourage sharp image completion.
• Our framework is able to complete images in a single forward pass, without any post-processing,
Figure 1.1(b) Examples of controlling multiple attributes with attribute vectors. All images are at 512×512 resolution. Two attributes[“Male”, “Smiling”]are used in this example. The two-dimensional conditional vectors of column two to five are[0, 0],[1, 0],[0, 1], and[1, 1]in which “1” denotes the generated images have the particular attribute while “0” denotes they do not.
CHAPTER
2
RELATED WORK
In this chapter, we discuss existing approaches that are closely related to our proposed work. First,
we give a basic overview of neural networks and deep learning. Second, we review recent deep learning methods for image generation. In recent years, researchers have been actively designing
new neural network architectures, training methodology and loss functions to generate high quality
images. These image generative models are the cornerstones to build other learning-based image editing methods, such as image-to-image translation, image completion, etc. Third, we introduce the
development of image completion approaches which can be divided into two categories: learning
based and non-learning based. Following the comparisons between these methods, we explain why we choose learning based approaches for the face completion problem. Fourth, methods of
controlling the attributes of generated images are introduced, including conditional and information
models. Fifth, image-to-image translation networks are discussed. These methods learn the mapping from one image domain to another, and are effective at various applications, such as image coloring,
reconstructing images from sketches or labels, style transfer, etc. Image translation networks are
often trained in an end-to-end manner and have similar architectures with image completion models. Additionally, many are combined with conditional models to control the properties of
transformed images. Finally, we examine recent face manipulation techniques including face re-targeting, face reenactment, and face swapping, which are important problems in the movie and
video game industry. Our proposed work has the potential for improved performance in these fields,
2.1
Neural Networks and Deep Learning
Inspired by the biological nervous systems, the artificial neural network (orneural networkfor
simplicity) is a framework that integrates a set of machine learning algorithms to enable a computer
to learn from input data. Neural networks can perform various challenging tasks, such as speech processing, object recognition, machine translation, medical diagnosis, etc. Traditionally, machine
learning algorithms need to explicitly define rules for specific tasks. For instance, in order to detect
cars in images, a regular algorithm has to define the essential features of cars, such as the patterns of wheels, license plates, doors, etc. In contrast, neural networks can automatically extract features
by examining a large amount of data, without knowledge pre-defined by human experts.
Neural networks consist of several layers of artificial neurons[Ros61]. Each neuron receives signals from multiple neurons of the previous layer, calculates their weighted sum, and optionally
passes the sum to non-linear functions (i.e. theactivation functions, such as Sigmoid, Softmax,
Rectified Linear Units[NH10], etc.) to produce an output (oractivation). Each neuron can be seen as a device that makes a decision by weighting up signals from the previous layer. Early neural
networks are shallow, composed of only one input, one hidden, and one output layers. Networks that have more than one hidden layer are called deep neural networks (DNNs).
Deep learning is a subset of machine learning algorithms that uses deep neural networks to
learn data representations at multiple levels. Each layer of a DNN combines features from the previous layer to build a more abstract representation. For instance, in image recognition, a DNN
may learn to extract edges in the first two layers, encode object components (e.g. wheels and doors)
in the third layer, and recognize a car in the fourth layer. In additional to the basic DNNs, there are other types of deep learning architectures, such as Convolutional Neural Networks (CNNs) and
Recurrent Neural Networks (RNNs)[Rum86]. For instance, instead of assuming that all the inputs
are independent like a DNN, an RNN makes use of sequential information (e.g. the order of words in a sentence) and performs the same task to each element recurrently in a sequence, with a hidden
state to “memorize” calculations as the recurrence progresses. RNNs have great performance in
tasks like natural language processing where sequential information is important in the input data. In our work, we focus on CNNs.
A Convolutional Neural Network is most often used for image analysis. A regular DNN is restricted
to fully-connected (FC) layers, in which each neuron is connected to all neurons of the previous layer. This structure has poor scalability for images. For instance, to process small images of size
3×32×32 (3 color channels, 32 wide, 32 high), a single FC neuron in the first hidden layer has 3,072
weight parameters. For images of medium size 3×256×256, the number of parameters for each FC neuron will increase quickly to 196,608. This makes a network inefficient or impractical to train.
CNNs make use of the spatially local correlations among pixels. Each neuron is only connected to a
are composed of a set of learnable filters (orkernels), each of which is convolved with pixels in the
receptive field to produce a two-dimensional activation map. A neuron is activated when some particular types of features learned by the model are detected at specific locations in the input. The
convolution operation reduces the number of parameters significantly, since each kernel is shared
by multiple neurons. CNNs have achieved great performance in various computer vision tasks, such as image recognition[Kri12b; ZF14; SZ14; Sze15; He16], image generation[Goo14], etc.
2.2
Image Generation
Given samples drawn from an unknown data generation processpdata, the goal of generative models is to estimate a data distributionpmodelso that examples generated frompmodelare similar to or indistinguishable from the real samples[Goo16]. Generative models can be applied to various areas, such as planning future actions for agents[Fin16], dialogue generation[Li17a], etc. Image generation,
in particular, is an important field of generative models, not only because there are various practical
applications requiring the generation of realistic pictures (or video frames), but also because images are high-dimensional data with spatial correlations among dimensions (i.e. pixels) and thus image
generation is essentially an excellent area for studying the capability of neural networks to learn
high-dimensional data distribution.
Generative models have been studied extensively to synthesize realistic and novel images.
Cur-rent work falls into three groups: variational autoencoders (VAE)[KW13; Kin16], fully visible belief
nets (FVBNs)[Oor16b; Oor16a]and Generative Adversarial Networks (GANs)[Goo14].
An autoencoder is a neural network that learns to transform input data to output, which consists
of an encoder and an decoder component[Goo16]. Given an observed imageIobsin the training set, the encoder learns a mappingz=f(Iobs)to encodeIobsto some latent variablesz. The decoder synthesizes a reconstructed imageIsynby learning another functionIsyn=g(z). Iff are deterministic functions to encode imagesIobsto some latent variables, andIsynare encouraged to be the same as Iobsin training, the autoencoder will easily learn to copy the input data to outputIobs=g(f(Iobs)). In other words, the network is only able to “memorize” images, rather than generating any novel
examples. Therefore, autoencoders are always designed to be unable to copy input data perfectly so
that the autoencoders will capture the most important properties of the inputs. Ideally,zcontains all necessary information to generate samples. For instance, if a model learns to synthesize handwritten
digits in MNIST[LeC98],z should provide relevant information like the class (i.e. which number),
width, and angle of each digit. These properties are related to each other and it is often complex to define them by hand. VAEs solve this problem by assuming thatz could be drawn from a normal
distributionz ∼ N(0,I), in whichI is an identity matrix. This assumption is reasonable because any distribution in multi-dimensions can be generated by taking multi-dimensional
theoretically neural networks can be used to approximate any functions. Therefore, the goal of a
VAE model is to encodeIobsto parameters of a normal distribution so that any latent variablez drawn from this normal distribution can be decoded to an imageIsynthat is similar to samples in the training set. Note that once the model is trained, a VAE does not need an input sampleIobs to generate images sincez can be drawn directly from a normal distribution. With a sequence of VAEs, the Deep Recurrent Attentive Writer (DRAW) architecture[Gre15]includes a spatial attention
mechanism, and generates images iteratively by learning to read and write parts of images at each
time-step. VAEs[KW13; Sal15; Kin14]are able to generate a variety of images, such as digits, faces, house numbers, etc. They are easy to train, but the generated images are often blurry and limited to
low resolutions.
Most generative models (e.g. VAEs and GANs) learn to synthesize images from latent variables in “one shot”[Gre15]. In other words, all image pixels are conditioned on the latent representations
and images are usually generated with a single forward pass. Alternatively, FVBNs learn to generate
images pixel by pixel. An essential problem of generating images is how to model the joint distri-bution of all pixels[Oor16b], which could be considered the product of conditional distributions.
Therefore, FVBNs turn this joint modeling problem into a sequence problem where the probability
distribution of a to-be-predicted pixel value is conditioned on the values of all scanned pixels in the context. Recent FVBN approaches (e.g. PixelRNN and PixelCNN[Oor16b; Oor16a]) design particular
structures with long short-term memory (LSTM) units, masked or gated convolutional layers, etc., in order to preserve the complicated long-range dependencies among pixels and across color channels.
FVBN models can synthesize sharp images, but they lack latent representations, which makes it
more difficult to control the attributes of generated images versus VAEs or GANs. Additionally, it is difficult for FVBNs to model the distribution of pixels at high resolution and thus current methods
can only generate low-resolution images (e.g. 64×64[Oor16b; Oor16a]). Moreover, inference in
FVBN models is slow since the images are generated pixel by pixel.
VAEs and FVBNs tend to generate blurry and/or low-resolution images mainly because they
lack accurate loss functions to represent errors. For instance, the mean squared error (MSE) of
pixel values between the generated images and ground true data is often used. However, for each pixel, there are many possible “correct” values which are slightly different from each other. With
losses like MSE, a neural network is encouraged to output the average value of all possible answers,
resulting in blurriness in the synthesized images. Goodfelow et al.[Goo14]model this problem as a minimax game. There are two players. One is a generator whose target is synthesizing realistic images
that are indistinguishable from real images. Another is a discriminator that learns to differentiate
ground-truth images from generated ones. Both the generator and discriminator are supposed to be differentiable functions and thus they are implemented using multi-layer neural networks.
The generator outputs a “fake” image while the discriminator outputs a scalar that represents the
this probability while the generator tries to maximize it. The generator and discriminator are trained
simultaneously, and thus the training process is usually unstable. Once a GAN model is trained, it is able to generate sharp images from latent variables (e.g. a 100-dimensional noise vector[Rad15]).
Many methods try to stabilize GAN and generate high quality images by designing new
archi-tectures, objective functions, and training methodologies. The original GAN[Goo14]consists of fully connected layers and is able to generate low-resolution images (e.g. 28×28 hand-written digits
in MNIST). The Deep Convolutional GAN (DCGAN)[Rad15]uses a novel architecture of a set of
fractional-strided convolutional layers and produces sharp images, such as faces and bedrooms at 64×64 resolution. Most GANs use gradient descent in training. However, there is no guarantee that
this process will converge. Additionally, many approaches suffer the model collapse problem where
the trained model always generates the same image whatever the input is. Salimans et al.[Sal16] propose several methods to improve the performance of GANs. For instance, instead of merely
maximizing the output of the discriminator, the generator is also encouraged to synthesize images
so that their intermediate activations (i.e. feature maps) in the discriminator network are similar to features of real images as well. Additionally, minibatch discrimination is introduced so that the
discriminator can look at a batch of samples to avoid model collapse. Moreover, if image labels (e.g.
class labels) annotated by observers are available in the dataset, the quality of generated images can be improved by including these labels because the discriminator is encouraged to focus on features
that are important to humans.
Unfortunately, these techniques are unable to synthesize high-resolution images.The main
challenge is that, in high resolutions, the discriminator can tell the differences between real and
fake images more easily, which causes a vanishing gradient problem where both the generator and discriminator stop learning at some point during training. Instead of generating high-resolution
images directly from scratch, many approaches synthesize images progressively in a coarse-to-fine
manner over resolutions increasing from low to high. The Laplacian GAN[Den15]uses a Laplacian pyramid representation of images where each image is made up of a set of band-pass images plus
a low-frequency residual. Therefore, Laplacian GAN consists of a sequence of GANs at different
frequency levels and the task of each GAN is to generate a band-pass image at a particular frequency. Starting from a noise vector, a low-frequency GAN generates a blurry low-resolution image on
which a GAN at the next level is conditioned and then predicts a higher-frequency image that is
added to the blurry image (i.e. the residual). By iteratively adding higher-frequency information, finer details are generated until the model reaches a desired resolution. StackGAN[Zha17]solves
this problem with two-stage stacked GANs. It first synthesizes a coarse low-resolution image (e.g.
64×64), which is used as parts of the inputs of a second generator to synthesize higher-resolution images (e.g. 256×256). Karras et al.[Kar17]put forward a progressive training methodology to
grow both the generator and discriminator from low to high resolution, and are able to generate
to handle information across all image scales at the same time, and instead can learn the holistic
image structures first and then focus on producing finer details progressively.
However, the generative models discussed in this section cannot be applied to the image
comple-tion task directly because they aim to generate random natural images that are not constrained by
the image context. Image completion requires inferring missing data from the available contextual information where the generated content should be consistent with the context both locally and
globally.
2.3
Image Completion
There is a large body of image completion literature. Early non-learning based algorithms[EL99;
Ber00; Ber03; Kwa03; Kom06]complete missing content by propagating information from known neighborhoods, based on low level cues or global statistics[Lev03]. For instance, starting from an
initial seed, Efros et al.[EL99]use a non-parametric model to predict the conditional distribution of
a pixel value based on all of its neighbors, and generate one pixel at a time. The randomness of the generated textures is controlled by defined parameters to synthesize a variety of samples. However,
this texture synthesis approach assumes that the textures around a hole are similar, otherwise
incoherent content textures will be synthesized since they are propagated from dissimilar neighbors. Bertalmio et al.[Ber00]propose an algorithm to estimate the direction of the isophotes so that for
each pixel, the model will decide which contextual information it should propagate from, and thus
it is able to fill in “holes” smoothly even when the surrounding areas contain disparate textures. Instead of using only local neighbors, other methods[Wex07; Sim08]compute the missing content
by integrating information at multiple scales so that both global and local features can contribute
to the prediction of pixels in the target regions. These methods are good at filling image “holes” or object removal, and they are mainly based on global or local structures of images.
Since texture synthesis approaches generate images pixel by pixel, the computation time is
usually high, which limits their application to mostly small images. One of the main reasons these approaches are slow is that for each missing pixel, they repeatedly and independently search all the
patches in the context, which is not necessary for natural scene and object images that often have
strong correlations among pixels. For instance, missing data that are spatially close to each other often depend on contiguous pixels in the context[Ash01]. Patch matching based approaches[Cri03;
Wil05; Bar09; Dar12; Hua14; Wex07]formulate the image completion task as a nearest neighbor
searching problem. For image patches containing missing data, the goal is to find similar structures from the context and paste them to fill in the holes. Many algorithms have been proposed to improve
the accuracy and efficiency of patch searching. For instance, by making use of the sparsity of image data, semantics of natural images, and random sampling, the PatchMatch method[Bar09], which
enough to be applied to interactive image editing tools. Huang et al.[Hua14]propose a method to
capture the semantics of missing regions based on extracted mid-level constraints (e.g. regularity and perspective) from the context, which works well for planar structures, such as building facades
and railways. The patch match methods often complete the holes with patches from the same input
image. In contrast, Hays et al.[HE07]search patches from millions of images collected from the Web. Instead of searching patches, they use a fast image-to-image matching algorithm (i.e. the
gist[Tor03; OT06]) to extract images with the smallest visual distances from the querying image in a
huge database. Then the corresponding regions in the extracted neighbor images are copied and blended with the input photo to synthesize plausible and realistic results. These traditional methods
assume that similar textures or patches of the missing content can be found in the known regions of
the same image or from an external database. However, this assumption does not hold when large or semantic parts (e.g. both eyes) are occluded. Recent work[Pat16; Iiz17; Yeh17]has compared
learning based methods with aforementioned approaches to produce large missing content. The
results show that non-learning based approaches often synthesize content that is inconsistent with the global structures (e.g. usingmouthsto fill in holes ateyelocations) while the learning based
models can produce reasonable results.
Many researchers focus on solving the face completion problem with traditional matching based algorithms. The Graph Laplace method[Den11]defines sparse representations (SR) for occluded
faces and group images in a large database into clusters based on their SRs. Given a corrupted face, this approach finds its nearest neighbors in the database and the most similar facial parts are used
by a spectral-graph-based algorithm to repair occluded face images. The Visio-lization[Moh09]
completes faces with realistic and variant characteristics using a combination of global and local models. The local non-parametric model is an improved version of image quilting[EF01], which
first builds a “patch library” that is made of all possible patches of certain sizes in a database and
then generates novel patches at target locations while preserving consistency with their neighbors. The global parametric model is able to maintain the coarse structures of faces but the synthesized
images lack detailed textures. By combining the local and global models, the Visio-lization approach
is able to generate natural faces with both globally realistic structures and locally consistent textures. Moreover, Visio-lization can be applied to image editing and inpainting. For instance, it is able to
remove flaws of a corrupted image, or change facial expressions of a target face. However, these
approaches can handle only low-resolution images with limited shapes of masks.
Recent learning based methods have shown the capability of CNNs to complete large missing
content. The completion models are different from the generative models (e.g. GANs): the former
need to complete corrupted images with plausible content while the latter focus on generating completely fake, yet realistic images from latent vectors. To explore whether CNNs are able to infer
the missing content conditioned on the known contexts, Pathak et al. propose a neural network
the auto-encoders encode complete images to hidden representations and then decode them to
reconstructed images with variations, CE encodes the contexts of masked images to latent variables, and then decodes them to natural content images, which are pasted into the original contexts
for completion. Similar to Visio-lization[Moh09], CE decomposes the image completion task to
the generation of global structure and local details by defining reconstruction and adversarial loss respectively, which agrees with the experiments of Dosovitskiy et al.[DB16]that reconstruction losses,
such as the pixel-by-pixelL1loss and squared Euclidean loss, help generative models reconstruct the
global structures from abstract feature representations while the adversarial loss helps synthesize sharp images. However, CE is good at generating only rectangular content since the shapes of
outputs of CNNs have to be regular. Additionally, the images generated by CE are often blurry and
have inconsistent boundaries along the seams between content and context.
In order to handle random masks and the problem of inconsistent boundaries, Yeh et al.
formu-late the completion task as a searching problem without using an encoder-decoder structure like
CE. Similar to the traditional matching-based approaches (e.g.[HE07]) that try to find appropriate samples from a large database to fill in the holes, Yeh et al. search the closet neighbor of a corrupted
image in the latent space. Ideally, a trained generative model is able to map latent vectors to plentiful
and various realistic samples. If a generative model is good enough, there is a higher chance to find a plausible image synthesized by the model than to extract a matching sample in a large database
(even with millions of images like[HE07]) to repair a corrupted image. Given an incomplete image, the objective is to find a latent vector such that its corresponding synthesized image blended with the
contexts minimizes local inconsistency along the mask boundaries and global reconstruction errors.
This method can handle arbitrary mask shapes. However, the completion time is high since it takes thousands of iterations to search for a plausible latent variable. Additionally, this work depends
heavily on the quality of the pre-trained generative models. Recently, Liu et al.[Liu18]propose
partial convolution layers so that the networks are conditioned on valid pixels in a forward pass, and achieve significant improvements when completing corrupted images with irregular holes.
Many approaches focus on improving the details of generated content. Rather than using a single
discriminator like CE, the Generative Face Completion model (GFC)[Li17b]and the Global and Local Consistent model (GL)[Iiz17]use both global and local discriminators. The global discriminator
helps preserve holistic structures while the local one differentiates whether the generated low-level
textures look natural or not. These methods are combined with post processing to complete images more coherently. Though GFC and GL models are trained with random rectangular masks, they can
handle arbitrary shaped masks as well. Unfortunately, these two approaches can only complete
face images in relatively low resolutions (e.g. 176 x 216[Iiz17]). Yang et al.[Yan16]combined a global content network and a texture network, and trained networks at multiple scales repeatedly to
complete high-resolution images (512×512). Like the patch matching based approaches, Yang et
improbable for the face completion task.
2.4
Generative Models with Controllable Attributes
The unconditional generative models introduced in section 2.2 can generate only random samples
that are similar to images in the dataset. For many applications, however, it is often necessary to
control the attributes of generated images. For instance, we may need to generate a particular class of images (say “bedrooms”) with a generative model trained on ImageNet[Rus15a], rather
than producing images from a random category. The synthesized images can be conditioned on a class label, an attribute vector etc. Note that the image inpainting networks can be seen as models
conditioned on valid pixels.
There are many researchers studying how to control the properties of images synthesized by generative models. The Conditional GAN (CGAN)[MO14]learns a multi-modal model conditioned
on attribute vectors (e.g. one-hot class labels) that are used to control properties of produced images
explicitly during evaluation. In the architecture of CGAN, both the generator and discriminator are conditioned on auxiliary information (e.g. class labels), which helps direct the generation process.
This straightforward extension of GANs achieves great performance. For instance, the trained
model of CGAN on MNIST[LeC98]can generate images of digits zero to nine depending on a label vector. There are many extensions of CGAN. Odena et al.[Ode16a]use a single trained model
to synthesize images of 1000 ImageNet classes conditioned on class labels. The Plug and Play
Generative Networks (PPGNs) are able to generate images of a variety of classes with a single trained model. Apart from being controlled by class labels, the attributes of this model are replaceable
for various applications, such as being conditioned on hidden network neurons for Multifaceted
Feature Visualization, contextual pixels for image inpainting, etc. Kaneko et al.[Kan17]extend CGAN and design multi-dimensional controllers to manipulate the properties (e.g. young or old) of face
images. The StackGAN[Zha17]is able to synthesize photo-realistic images conditioned on text
descriptions. Olszewski et al.[Ols17]generate dynamic textures for a target face by referencing a source video sequence.
Unlike the CGANs whose generators or discriminators are conditioned on the attribute code
directly, the information model (InfoGAN)[Che16]is built on information theory. In order to control the attributes of GANs, an obvious way is to attach some attribute code to the input noise vector.
However, the generator may ignore the attribute code since there are no constraints that the
at-tributes should be preserved. A straightforward solution is to maximize the mutual information between the input latent code and the observations (i.e. the synthesized images or features). In
other words, the latent code should not be lost during the generation process and we should be able to predict the latent vectors correctly from the outputs of the generator. This method performs
and width of digits). This model is capable of learning the disentangled representations of images.
For instance, when both discrete and continuous latent code are attached to the input noise vector and the model is trained in an unsupervised way, the networks learn to appropriately assign discrete
and continuous attributes to the discrete and continuous code respectively. In implementation,
the discriminator of InfoGAN not only checks if an image looks real or not, but also uses auxiliary networks to tell whether the latent information predicted from the generated images is close to
the input latent code. When the image data are unlabeled or partially labeled, the Categorical GAN
(CatGAN)[Spr15]learns to generate images of desired classes. It assumes that real images have peaked class distributions while fake images should be uniformly distributed. In other words, the
discriminator should be certain of the class of a real image, but uncertain of the label of a fake
image. On the other hand, the generator is encouraged to fool the discriminator such that generated images have high certainty of class assignments, while assuring the synthesized samples are evenly
distributed across all image classes. Salimans et al.[Sal16]change the discriminator to a “K+1”
classifier by adding a “generated” class to the originalKimage categories. The discriminator aims to assign correct class labels to real images and categorize fake images to the “generated” class while
the generator tries to synthesize realistic images with certain properties such that they could be
classified to the designated categories. Their model is able to generate images of multiple classes with one generative model.
2.5
Image-to-Image Translation
Image-to-image translation networks transform images from one domain to another, which can be
used for a variety of tasks, such as image style transfer[Gat15; Joh16; Tai16; Iso17; Zhu17b; Lia17;
Roy17; Li18], image super-resolution[Joh16], or face attribute editing[LT16; Don17; Liu17]. Human artists are able to capture the high level semantics of images and draw similar scenes of different
styles. Recently, some artificial systems (e.g. Prisma) are able to transfer a photo to other styles such
as Monet, Ukiyo-e etc. The main challenge is to disentangle the content and style representations of images. Early works[Gat15; Joh16]have studied the activations of different layers of CNN classifiers
and proposed the perceptual losses to quantify the differences between images in content and
style. The traditional reconstruction loss is defined by the Euclidean distances between pixel values of images, and encourages the generator to synthesize exactly the same images as ground-truth.
This does not work for the image style transfer tasks where the colors, textures, and patterns of
the transformed images are supposed to be different from the inputs. The CNN classifiers can be seen as feature extractors and the intermediate activation layers are considered as feature maps
of input images. Therefore, the content reconstruction loss is defined by the Euclidean distances between the neural features of a certain layer. The experiments of Johnson et al.[Joh16]showed
structures were preserved while their styles, such as textures and colors, were not. On the contrary,
the style reconstruction loss is defined by the Frobenius norm between the Gram matrices of two images, which penalizes the synthesized image when its style is different from a reference image.
By combining the content and style reconstruction loss, these approaches are able to transfer an
image to the style of a reference photo while preserving the content of the input image. Johnson et al.[Joh16]showed that the perceptual losses also help the image super-resolution task that translates
a low-resolution image to a high-resolution one. Instead of transferring photos to different art styles
like[Gat15; Joh16], Li et al.[Li18]focus on photo-realistic image stylization, which is a more difficult problem since human observers are more sensitive to artifacts in photo-realistic images. Li et al.
propose a two-step algorithm: stylization and smoothing. The stylization step is similar to previous
style transfer approaches[Gat15; Joh16; Li17c]and transforms an image to a different style according to a reference image. A second network (i.e. the smoothing network) is trained to remove the artifacts
of the intermediate results from the first step. Many researchers[Tai16; Roy17]focus on face or
portrait images and design algorithms to translate photos to cartoon avatars or emoji.
Many researchers are interested in the translation between two domains of images with different
characteristics, which is a more generic problem than style transfer. For instance, the two groups of
images could be the semantic labels and their corresponding street scene images[CK17], two related classes of animals like zebras and horses[Zhu17b], images of different styles (i.e. style transfer), etc.
Assuming paired data are available in the dataset, Isola et al.[Iso17]propose a conditional image translation model. They use a UNet[Ron15]-like structure to translate images from one domain to
another. Instead of only checking whether the translated images look similar to the images in the
target group, the discriminator is also conditioned on images from the input domain. In other words, the input to the discriminator is a tuple of paired data from both groups and the discriminator
needs to decide if the tuple is real. Wang et al.[Wan17]extend this approach and improve the
resolution of this method from 256×256 to 2048×1024. However, in many cases, paired data are not available. For instance, if we want to transform a zebra to a horse, it is not well-defined what a
translated horse should look like. Therefore, the model needs to learn characteristics of two image
domains in an unsupervised way. Zhu et al.[Zhu17b]propose an architecture named CycleGAN with cycle-consistency loss. The idea is analogous to language translation. Suppose we have two
(forward and backward) translators between English and French. If we translate an English word,
say “hello” to French “bonjour”, and then translate “bonjour” back to English, the result should still be “hello”. By imposing the cycle-consistency loss, CycleGAN is able to capture the essential
characteristics of each domain and perform image translation when paired data are not available.
Many approaches[Iso17; Zhu17b; Wan17]translate an input image to a deterministic result once the model is trained. For many tasks, however, the mapping should be one-to-many. For instance,
when we translate a “night” scene to “day” images, there are multiple plausible correct answers:
The model learns a distribution of possible translated images and is able to translate an image to a
set of realistic results with diversity.
Many image translation approaches (e.g.[Iso17; Zhu17b]) are good at transferring colors, textures
and patterns between different domains, but work poorly when geometric transformation is involved,
for instance transforming a cat to a dog. Liu et al.[Liu17]propose an architecture consisting of two auto-encoders, one for each translation direction. They assume that the paired images in two
domains can be encoded to the same latent code in a shared latent space. This assumption actually
implies the cycle-consistency[Zhu17b]since a translated image in the target domain is expected to be able to reconstruct the input image after being translated back due to the nature of the shared
latent representation. But cycle-consistency does not necessarily imply that paired data have the
same latent code. This approach achieves significant improvements and is able to handle domains with dissimilar geometric structures. For instance, it is able to transform a cat to a cougar or tiger
while preserving semantics of the input data. Huang et al.[Hua18]extend this work and make two
assumptions. First, images can be encoded into content and style code in the latent space. Second, images from source and target domains have similar content code, but different style code. Therefore,
this approach does not need paired data, and is able to map an input image to diverse images by
combining the input content code with various style code from the target domain. Additionally, this method is also able to handle geometric transformations (e.g. translating cats to tigers), and
achieves better image quality over[Liu17].
Many image translation approaches can be applied to face attribute editing tasks. Upchurch et
al.[Upc16]propose the Deep Feature Interpolation (DFI) algorithm to interpolate deep features
from different image domains to manipulate face properties. For instance, given two groups of images “old” and “young,” DFI extracts deep features of images from both domains with pre-trained
classifiers (e.g. VGG[SZ14]). An attribute vector is defined as the differences between these two sets
of images in the deep feature space. Given an input image, its feature is linearly interpolated with the attribute vector to move its properties to a desired direction (e.g. from “young” to “old.”) The
interpolated feature is then reconstructed to a complete image by a decoder. Liu et al.[LT16]use
two GANs with shared weights to learn the mapping from one face domain (e.g. with “black hair”) to another (e.g. with “blond hair”). Dong et al.[Don17]learn the the image-to-image mapping with
two steps. First, it learns to map a latent code conditioned on class label to an image. Second, it
learns to encode images from different domains to a shared latent space. In inference, given an input image and desired class label, the image can be transformed to the target domain. This approach
is able to manipulate the gender and identity of faces (i.e. face swapping). Given face image data
with different properties (e.g. “smiling” vs. “not smiling”, “with glasses” vs. “without glasses”, etc.), many image translation networks[Liu17; Zhu17b; Hua18]can be applied to learning the translation
between different domains directly.
In order to learn the relations among multiple domains, a straightforward solution is to train a
translation model between each pair of domains. However, this will increase the complexity of this task significantly. StarGAN[Cho17]uses one-hot class labels to characterize each image domain.
Suppose we need to learn the mappings among three domains of face images “blond hair”, “male”,
“old”. StarGAN uses a three-dimensional vector to represent each domain. Each value in the vector is set to “1” if that attribute presents in the image, otherwise is set to “0”. For instance, a young female
face with blond hair will be assigned a label[1, 0, 0]. This method also combines cycle-consistency
loss and the InfoGAN model in training, and achieves good performance. An input image can be translated to multiple domains with a single trained model, depending on the input attribute labels.
Gan et al.[Gan17]propose a triangle architecture GAN and are able to translate an image to a text
description, and then reconstruct descriptions to images. In other words, this approach can handle translations between three domain pairs: image-to-image, image-to-label, and label-to-image.
However, there are few completion models that are able to manipulate the properties of
syn-thesized contents. Our conditional completion model is built on these image-to-image translation approaches and can complete corrupted images with multiple controllable attributes. Image
com-pletion networks often have similar architectures to the image-to-image translation approaches
since the image inpainting task can be seen as translating a corrupted image to a complete one.
2.6
Face Swapping and Facial Puppetry
Manipulation of the attributes of faces, such as identity, pose and expressions, is an essential task for various applications in the social media, movie and game industry. Specifically, approaches in
this area fall into two groups: face swapping and facial puppetry. Face swapping is to replace parts
of or the entire face of a target actor with components of source actors. De-identification is required by many applications. For instance, Google Street View is a system that allows users to interactively
explore street scenes. Without the consent of people captured in these images, measures have to
be taken to protect their privacy. Usually their faces are censored with blurriness, which, however, makes the scenes less aesthetic. Bitouk et al.[Bit08]propose a method to naturally swap faces of
target actors with faces in a database. Given a target face, its nearest neighbors in a face library are
detected based on pose and appearance similarity. The candidate source faces are adjusted to match the lighting, color and pose of the target, and are then blended with the target context. However,
this method fails when no appropriate samples can be found in the library. Blanz et al.[Bla04]focus
on solving the illumination and pose discrepancy in the swapping tasks by estimating 3D poses and textures from 2D images. A Morphable Model of 3D faces is used for face transferring. Yang
et al.[Yan11]design expression flow to replace parts of faces (e.g. mouths) to change the facial expressions. The expression flow is used to deform the target face such that it becomes consistent
feature points, this method learns to reconstruct a pair of faces with the same identity, but different
expressions each time so that the differences between the models of these two faces represent their distinct facial expressions. While aforementioned approaches address the image editing problem,
Dale et al.[Dal11]address the face swapping task in video. They propose a method to align the
source and target faces spatially and temporally for face replacement. Dynamic Time Warping (DTW)[RJ93]is also applied to preserve smooth transitions between adjacent frames.
Face puppetry is to transfer the facial expressions of a source actor to a target face. It can either be
a computer generated avatar (i.e. facial animation) or a photo-realistic face (i.e. face reenactment). For instace, Williams et al.[Wil90]propose a method to capture the expressions of a live performer
who wears a set of reflective spots on faces. 3D geometries and textures are estimated from the
captured video sequence and are used to animate a computer generated head model. Tracking faces is the most challenge task in facial animation systems. There are various approaches to address
it, such as marker-based[Gue05], with structured light[Wei09; Ma08; Zha08; Li09], or by using
multi-view stereo cameras[Bee11; Bra10; Jon06]. In order to generate more realistic faces while transferring expressions, some researchers[Bic07]design systems to capture wrinkles while actors
are making faces and are able to reconstruct 3D face models with natural and detailed skin textures
and wrinkles. More recently, some approaches[Wei11; Li13; Gar13]are capable of tracking faces with markerless systems using monocular videos and animating computer-generated avatars in
real time.
Instead of animating the 3D face models, many researchers are interested in the photo-realistic
expression transfer of real actors. In the movie industry, it is often necessary to puppeteer the
performance of a generated but realistic face. For instance, in the movie “The Curious Case of Benjamin Button,” artists needed to animate the faces of Brad Pitt at different ages. It took them
tremendous effort to match the live performance of Pitt and his avatar, and render photo-realistic
faces. However, with the development of face reenactment techniques, many tasks can be addressed automatically. Vlasic et al.[Vla05]propose a multilinear model to disentangle the representations of
face identity, expression, and geometry. These separated features can be recombined to reconstruct
faces with desired attributes. For instance, we can combine the identity of a target actor and the expression of a source face to generate the target face with the transferred expression.
Kemelmacher-Shlizerman et al.[KS10]formulate this task as an image retrieval problem. Assuming we have
plentiful footage of the target actor, given a source image, the task becomes finding a target face in the dataset whose pose and expression are most similar to the source actor. However, an obvious
limitation of this approach is that it requires a large amount of face data from the target actor. Other
researchers focus on quantifying the facial features. Liu et al.[Liu01]design the Expression Ratio Image (ERI) to measure the deviation of illumination of face images from a neutral expression,
which is able to help transfer expressions in a more realistic way, such as adding wrinkles in the
using a data-driven approach, which is more accurate for retrieving images for face reenactment.
Garrido et al.[Gar14]characterize faces with 66 facial landmarks. Similarity metrics are defined based on histograms of local patterns. Different from other face reenactment methods, the system
of Garrido et al. transfers the identity of a source face to target while preserving the expression of
the target image. Recently, Thies et al.[Thi15; Thi16]propose real-time face reenactment systems. These systems track the source and target actors at the same time and detect features like identity,
illumination, pose and expression. The expression of the source actor is transferred to puppeteer the
CHAPTER
3
APPROACH
In this chapter, we formally discuss the generative models, and introduce conditional and
informa-tion models that can control attributes of images generated by GANs. The methodology of training models progressively is discussed, which is used to synthesize high-resolution images.
Based on these approaches, we formulate the problem of image completion, and then introduce
our progressively attentive GAN. First, we introduce the pipeline of our approach. Second, we discuss how to make use of generative models for image inpainting and address the high-resolution image
completion problem with a combination of a progressive training methodology and an attention
mechanism. In particular, a novel Frequency-Oriented Attentive Module (FAM) is designed to encourage our model to focus on learning facial structures in a coarse-to-fine manner to help
synthesize sharper images with enhanced details and less distortion. Third, we explain approaches
to control the attributes of synthesized content with conditional and information models. Finally, we define a set of designed loss functions that help stabilize training and enforce sharp image
3.1
Generative Models
Many generative models are built on the maximum likelihood estimation (MLE). Givenm
observa-tionsx1,x2, ...,xm, the likelihood is defined as m
Y
i=1
pmodel(xi;θ), (3.1)
in whichpmodelis a generative model that estimates a probability distribution over the training data xiandθdenotes the parameters of the model. The idea of MLE is to find the values ofθ such that the likelihood is maximized. In our problem domain, the objective is to find parameter values that
make the training data most plausible. In practice, MLE is often performed in log space since sum
operations are easier than multiplication. The logarithm function is monotonically increasing and does not change the maximum locations, by computing
θ∗=arg max
θ m
Y
i=1
pmodel(xi;θ) =arg max
θ m
X
i=1
logpmodel(xi;θ).
(3.2)
The computation of maximum likelihood estimation is equivalent to minimizing the
Kullback-Leibler divergence (KL divergence), which measures how one probability distribution diverges from
another, between the true data distributionpdataand the model distributionpmodel.
θ∗=arg min
θ DKL(pdata(x)||pmodel(x;θ)) (3.3) Practically, we do not have access to the true data distributionpdata. Instead, an approximate empirical distribution ˆpdataof the training set is used. Minimizing the KL divergence forces the generative model to recover the empirical distribution as precisely as possible, which is equivalent
to maximizing the likelihood of the training data.
Currently, there are three main approaches to generative models: fully visible belief nets (FVBN),
variational autoencoder (VAE)[KW13; Kin16]and generative adversarial networks (GAN)[Goo14].
Given ann×nimageI, which could be represented as a one-dimensional vector with pixel values v1,v2, ...,vn2, FVBNs (e.g. PixelRNN[Oor16b]) decompose the prediction of the joint distribution to the product of conditional distributions over pixels
p(I) = n2
Y
i=1
Noise Variable
z~pnoise(z) Generator G
G(z)
I Discriminator D
: tries to make be 1
D D(I)
: tries to make be 0
: tries to make be 1
D D(G(z))
G D(G(z))
Figure 3.1The Generative Adversarial Networks (GANs) consist of a generator networkG and a discrim-inator networkD. The generator learns to map a random noise variablez(e.g. white noise) to a realistic imageG(z)while the discriminator is trained simultaneously to tell whether an input image (I from the real data or a synthesizedG(z)) is real. The image generation problem is formulated as a minimax game: the generator tries to maximize the probabilityD(G(z))that a synthesized image is classified as real by the discriminator while the discriminator tries to minimizeD(G(z)). Both the generator and discriminator can be implemented as multi-layer neural networks.
The probability of theithpixel value is conditioned on previous pixelsv1, ...,vi−1. However, since FVBNs like PixelRNN generate one sample at each step, the generation process cannot be parallelized
because of the nature of the conditional modeling. On the other hand, VAEs estimate a lower bound:
L≤logpmodel(I;θ). (3.5)
However, the gap between the true likelihood and the lower bound can be significant and it is not guaranteed thatpmodelwill be similar topdatawhile a learning algorithm is maximizingL.
FVBNs and VAEs estimate the data distributionpdataby explicitly defining density functions. To overcome the drawbacks of explicit models, Goodfellow et al.[Goo14]formulate this problem implicitly by defining a minimax game between a generator and a discriminator (Figure 3.1), both of
which are differentiable functions and can be implemented as multilayer neural networks. LetI be
a RGB image, with the generator and data distribution denoted bypG(I)andpdata(I), respectively. pG(I)is trained to matchpdata(I). GAN parametrizespG(I)using a generator networkG(z;θG)with parametersθG, which transforms a random noise variable (e.g. white noise)z into a sampleG(z), overcoming the challenges of trying to compute probabilities for everyI in the data distribution in an explicit way. Under the minimax game, an adversarial discriminator networkD(I;θD)with parametersθD is trained simultaneously.D aims to differentiate generated sampleG(z)from real data with a binary classification real or generated.D(I)denotes the probability of an image being from the real data distributionpdatarather than the synthesizedpG. For a given generatorG, the optimal discriminator isD(I) = pdata(I)
![Figure 1.1 (a) Face completion results of our method on CelebA-HQ [Kar17]. Our model directly generatescompleted images based on the input contextual information, instead of searching for similar exemplarsin a database to fill in the “holes” (e.g](https://thumb-us.123doks.com/thumbv2/123dok_us/1490743.1182406/13.612.90.539.72.300/completion-directly-generatescompleted-contextual-information-searching-exemplarsin-database.webp)


![Figure 3.2 An example of the generator of DCGANvector [Rad15] to generate 64 × 64 color images, which consistsof a set of transposed convolutional layers that process images at different scales](https://thumb-us.123doks.com/thumbv2/123dok_us/1490743.1182406/34.612.90.539.71.290/generator-dcganvector-generate-consistsof-transposed-convolutional-process-different.webp)
![Figure 3.3 In order to control the attributes of synthesized images, both the generator and discriminatorwhereof CGAN [MO14] are conditioned on an additional attribute A in training](https://thumb-us.123doks.com/thumbv2/123dok_us/1490743.1182406/35.612.110.513.227.337/attributes-synthesized-generator-discriminatorwhereof-conditioned-additional-attribute-training.webp)
![Figure 3.4 Based on information theory, InfoGANQ [Che16] tries to disentangle the feature representa-tions in the latent space by maximizing mutual information � (A,G (z,A)) between the attribute vectorA and generated images G (z,A)](https://thumb-us.123doks.com/thumbv2/123dok_us/1490743.1182406/37.612.129.509.75.185/information-infoganq-disentangle-representa-maximizing-information-attribute-generated.webp)