Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 348
Workload-Driven Design and Evaluation - TCP in Cast
Prof.Dr.G.Manoj Someswar
1, Ch.Dhanunjaya Rao
21.Research Supervisor, Dr.APJ Abdul Kalam Technical University, Lucknow, U.P., India
2. Research Scholar, Dr.APJ Abdul Kalam Technical University, Lucknow, U.P., India
Abstract
Vast scale information driven frameworks enable associations to store, control, and get an incentive from
expansive volumes of information. They comprise of dispersed segments spread over an adaptable number of
associated machines and include complex programming equipment stacks with different semantic layers.
These frameworks enable associations to take care of built up issues including a lot of information, while
catalyzing new, information driven organizations, for example, web crawlers, interpersonal organizations,
and distributed computing and information stockpiling specialist organizations. The multifaceted nature,
decent variety, scale, and quick advancement of vast scale information driven frameworks make it trying to
create instinct about these frameworks, increase operational experience, and enhance execution. It is a critical
research issue to build up a technique to plan and assess such frameworks in light of the exact conduct of the
targeted workloads. Utilizing an exceptional gathering of nine mechanical workload hints of business-basic
huge scale information driven frameworks, we build up a workload-driven plan and assessment technique for
these frameworks and apply the strategy to address beforehand unsolved outline issues. Specifically, the
exposition contributes the accompanying:
1. A calculated structure of separating workloads for substantial scale information driven frameworks
into information get to designs, calculation examples, and load landing designs.
2. A workload investigation and union strategy that utilizations multi-dimensional, non-parametric
measurements to extricate bits of knowledge and create delegate conduct.
3. Case investigations of workload examination for modern arrangements of Map Reduce and
enterprise organize capacity frameworks, two cases of huge scale information driven frameworks.
4. Case investigations of workload-driven outline and assessment of a vitality efficient Map Reduce
framework and Internet server farm arrange transport convention pathologies, two research themes that
require workload-particular bits of knowledge to address. By and large, the postulation builds up a more
target and orderly comprehension of a rising and imperative class of PC frameworks. The work in this paper
advances quicken the reception of huge scale information driven frameworks to fathom genuine problems
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 349
Keywords: express clog notification (ECN), Analytical Model, retransmission time out (RTO), Flow rate models,
Stand-alone employments
INTRODUCTION
Recommend the solution to the infection. This is
the second of two sections that outline how
workload examination experiences trans-late to the
real plan and assessment of huge scale information
driven frameworks. The section additionally
outlines that the plan and assessment strategies
created in the paper enables designers to assess the
significance of a known issue with regards to
extensive scale information driven workloads.
We examine the TCP in cast pathology with
regards to vast scale information driven workloads.
TCP in cast is an as of late identified organize
transport issue that an effects many-to-one
correspondence patterns in Internet data centres.
Late years has seen a few endeavours to relieve or
stay away from in cast. In the meantime, a few
questions remained with respect to the amount it
impacts huge scale information driven
frameworks, for example, Map Reduce. We
introduce a quantitative, observationally verified
show for anticipating TCP in cast throughput
crumple. We contribute workloads-driven
assessment comes about that quantify the
execution effect of TCP in cast under practical
settings. The workload bits of knowledge grew
before in the research paper additionally enable us
to evaluate TCP in cast with regards to future
outline needs.
The first half of this part creates and approves a
quantitative model that accurately predicts the
beginning of in cast and TCP conduct both when
in cast happens. The second 50% of this part
researches how in cast an effects the Apache
Hadoop usage of Map Reduce, an imperative case
of a huge scale information driven application. We
close the part by reflecting on some innovation and
information examination patterns encompassing
vast scale information driven frameworks,
estimating on how these patterns communicate
with in cast, making proposals for data centre
administrators, and talking about the more
extensive ramifications of the work.
Motivation
TCP in cast is an as of late identified arrange
transport pathology that an affects many-to-one
correspondence designs in data centre. It is caused
by a perplexing transaction between data centre
applications, the fundamental switches, arrange
topology, and TCP, which was initially intended
for wide region systems. In cast expands the lining
postponement of flows, and abatements
application-level throughput to far beneath the
connection data transfer capacity. The issue
particularly an affects figuring standards in which
appropriated preparing can't advance until the
point when every single parallel string in a phase
finish. Cases of such ideal models incorporate
disseminated le frameworks, web seek, promotion
determination, and different applications with
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 350
There have been numerous proposed answers for
in cast. Agent approaches incorporate altering TCP
parameters or its blockage control calculation,
upgrading application-level information exchange
design, switch level modifications, for example,
bigger buffers or express clog notification (ECN)
abilities, and connect layer components, for
example, Ethernet clog control. Application-level
arrangements are the minimum meddling to send;
they can be conveyed without changing the basic
Internet data centre foundation, however require
altering every last application. Switch and
connection level arrangements require adjusting
the fundamental data centre foundation, and are
probably going to be strategically practical just
amid equipment redesigns.
Lamentably, regardless of these arrangements,
despite everything we have no quantitatively exact
and experimentally approved model to foresee in
cast conduct. So also, regardless of numerous
studies exhibiting in cast for micro benchmarks,
despite everything we don't see how in cast
impacts application-level execution subject to
genuine complexities in configuration, booking,
information measure, and other natural and
workload properties. These worries make justified
wariness on whether we really comprehend in cast
by any means, regardless of whether it is even a
vital issue for a wide class of workloads, and
whether it is justified regardless of the e ort to
convey different in cast arrangements in bleeding
edge, business-basic data centres.[1]
We try to see how in cast impacts the rising class
of substantial scale information driven workloads.
These workloads help understand
needle-in-a-sheaf compose issues and concentrate noteworthy
bits of knowledge from vast scale, conceivably
perplexing and unformatted information. We do
not propose in this part yet another answer for in
cast. Or maybe, we centre around building up a
profound comprehension of one existing
arrangement: altering the TCP stack in the OS bit
to lessen the minimum length of TCP
retransmission time out (RTO ) from 200ms to
1ms. TCP in cast is in a general sense a vehicle
layer issue, therefore an answer at this level is
ideal.
Towards an Analytical Model
We utilize a straightforward system topology and
workload to build up a logical model for in cast,
appeared in Figure 1. This is an indistinguishable
setup from that utilized as a part of earlier work,
and is illustrative of the system traffic designs on
big business arrange capacity frameworks that
store les in allotments or stripes crosswise over
different servers. We pick this topology and
workload to make the investigation tractable.
The workload is as per the following. The recipient
demands k squares of information from an
arrangement of N stockpiling servers | in our tests
k = 100 and N shifts from 1 to 48. Each piece is
put away in parcels or stripes crosswise over N
stockpiling servers. For each piece ask for got, a
server reacts with a fixed measure of information.
Customers don't ask for square k + 1 until the point
when every one of the pieces of piece k have been
gotten | this prompts a synchronized read example
of information demands. We re-utilize the capacity
server and customer code. The execution metric
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 351
the aggregate bytes got from all senders isolated by
the finishing time of the last sender.[2]
We lead our trials on the DETER Lab test bed,
where we have full control over the
non-virtualized hub OS, and the system topology and
speed. We utilized 3GHz double centre Intel Xeon
machines with 1Gbps system joins. The hubs run
standard. This was the latest mainline Linux
appropriation in late 2009, when we got our earlier
outcomes. We perform tests utilizing both a
generally shallow-buffered Nortel 5500 switch
(4KB for every port), and an all the more
profoundly buffered HP Pro curve 5412 switch
(64KB for each port).
Sender 1 Sender
2
Bottleneck
Switch
…
Receiv er
Throughput drops to Sender
N
small % of link capacity
Figure 1: Simple setup to observe in cast. The receiver requests k blocks of data from a set of N
storage servers. Each block is striped across N storage servers. For each block request received, a
server responds with a fixed amount of data. Clients do not request block k + 1 until all the
fragments of block k have been received
Flow rate models
The simplest model for in cast is based on two
competing behaviours as we increase N, the
number of concurrent senders. The first behaviour
occurs before the onset of in cast, and reflects the
intuition that good put is the block size divided by
the transfer time. Ideal transfer time is just the sum
of a round trip time (RTT) and the ideal send time.
captures this idea.[3]
In cast occurs when there are some N > 1
concurrent senders, and the good put drops
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 352
retransmission time out (RTO) represents the
dominant effect. Transfer time becomes RTT +
RTO + ideal send time, as captured in Equation.
The good put collapse represents a transition
between the two behaviour modes. that TCP fast
retransmit does not get triggered, making RTO the
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 353
GoodputbeforeIncast = idealGoodputP erSender N
blockSize
= idealT ransf erT ime N
=
blockSize
N
RT T +
blockSize
perSenderBandwidth blockSize
=
N
RT T +
blockSize N
linkBandwidth
(1)
Goodputincast = goodputP erSender N
blockSize
=
N RT O + idealT ransf erT ime
=
blockSize
N
RT O + RT T +
blockSize
perSenderCapacity blockSize
=
N RT O + RT T +
blockSize N
linkCapacity
(2)
Figure 2: gives some intuition with regard to Equations 1 and 2. We substitute block Size = 64KB,
256KB, 1024KB, and 64MB, as well as RT T = 1ms, and RT O = 200ms. Before the onset of in cast
(Equation 1), the good put increases as N increases, though with diminishing rate, asymptotically
approaching the full link bandwidth. The curves move vertically upwards as block size increases.
This reflects the fact that larger blocks result in a larger fraction of the ideal transfer time spent
transmitting data, versus waiting for an RTT to acknowledge that the transmission completed.
After in cast occurs (Equation 2), RTO dominates the transfer time for small block sizes. Again,
larger blocks lead to RTO forming a smaller ratio versus ideal transmission time. The curves move
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 355 Goodput
(Mbps)
1000
800
600
400
200
0
0 8 16 24 32 40
48
Number of concurrent senders, N
64KB blocks, ideal 256KB blocks, ideal 1024KB blocks, ideal 64MB blocks, ideal 64KB blocks, 200ms RTO 256KB blocks, 200ms RTO 1024KB blocks, 200ms RTO 64MB blocks, 200ms RTO
Figure 2: Flow rate model for in cast. Showing ideal behaviour (solid lines, Equation 1) and in cast behaviour caused by RTOs (dotted lines, Equation 2). We substitute block Size = 64KB, 256KB, 1024KB, and 64MB, as well as RT T = 1ms, and RT O = 200ms. The in cast good put collapse comes from the transition between the two TCP operating modes
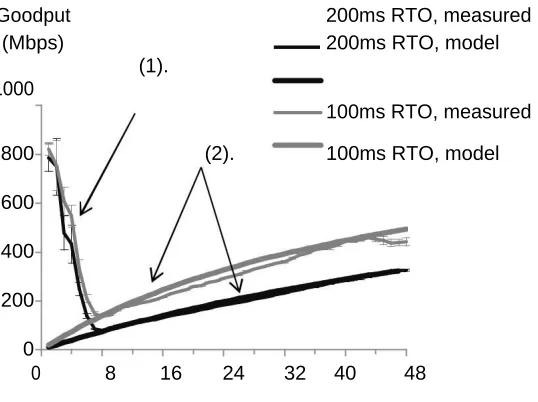
Goodput 200ms RTO, measured
(Mbps)
(1).
200ms RTO, model
1000
100ms RTO, measured
800 (2). 100ms RTO, model
600
400
200
0
0 8 16 24 32 40 48
Number of concurrent senders, N
Figure 3: Empirical verification of flow rate in cast model. The graph shows our previously
presented data. The block Size is 256KB, RT O is set to 100ms and 200ms, and the model uses RT T
= 1ms. Error bars represent 95% confidence interval around the average of 5 repeated
measurements. The switch is a Nortel 5500 (4KB per port). Showing (1) in cast good put collapse
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 356
Goodput (1). (2).
(Mbps) 1000
800
16KB blocks, measured
600
32KB blocks, measured
64KB blocks, measured 400
128KB blocks, measured
200
0
0 8 16 24 32
Number of concurrent senders, N
Figure 4: Empirical verification of flow rate TCP model before onset of in cast. Measurements done
on HP Procure 5412 switches (64KB per port). RT O is 200ms. Error bars represent 95%
confidence interval around the average of 5 repeated measurements. Showing (1) behaviour before
good put collapse verifies Equation 1, and (2) onset of in cast good put collapse predicted by switch
buffer over flow during slow start (Equation 3)
Empirical verification
This model matches well with our empirical
measurements. Figure 3 super positions the model
on our previously presented data. There, we x
block Size at 256KB and set RT O to 100ms and
200ms. The switch is a Nortel 5500 (4KB per
port). For simplicity, we use RT T = 1ms for the
model.[4] Good put collapse begins at N = 2, and
we observe behaviour for Equation 2 only. The
empirical measurements (solid lines) match the
model (dotted-lines) almost exactly.
We use a more deeply buffered switch to verify
Equation 1. As we discuss later, the switch buffer
size determines the onset of in cast. Figure 4 shows
the behaviour using the HP Pro curve 5412 switch
(64KB per port). Behaviour before good put
collapse verifies Equation 1 | the good put
increases as N increases, though with diminishing
rate; the curves move vertically upwards as block
size increases. We can see this graphically by
comparing the curves in Figure 4 before the good
put collapse to the corresponding curves in Figure
2.
Insight: Flow rate model of Equation 1 captures
behaviour before onset of in cast. TCP RTO
dominates behaviour after onset of in cast
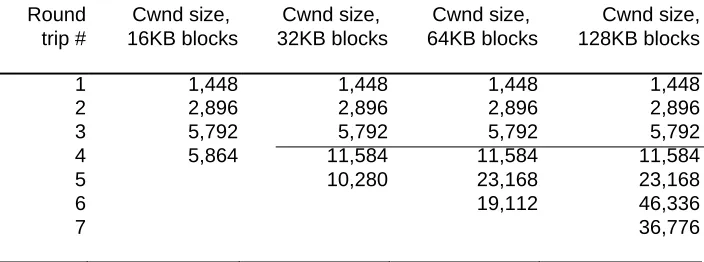
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 357 Round Cwnd size, Cwnd size, Cwnd size, Cwnd size,
trip # 16KB blocks 32KB blocks 64KB blocks 128KB blocks
1 1,448 1,448 1,448 1,448
2 2,896 2,896 2,896 2,896
3 5,792 5,792 5,792 5,792
4 5,864 11,584 11,584 11,584
5 10,280 23,168 23,168
6 19,112 46,336
7 36,776
Table 1: TCP slow start congestion window size in bytes versus number of round trips. Showing the
behaviour for block Size = 16KB, 32KB, 64KB, 128KB. We verified using sysctl that Linux begins
at (2 base MSS) = 1448 bytes
Predicting the onset of in cast
Figure 4 also shows that good put collapse occurs
at different N for different block sizes. We can
predict the location of the onset of good put
collapse by detailed modelling of TCP slow start
and buffer occupancy. Table 1 shows the slow start
congestion window sizes versus each packet round
trip. For 16KB blocks, 12 concurrent senders of
the largest congestion window of 5864 bytes
would require 70368 bytes of buffer, larger than
the available buffer of 64KB per port. Good put
collapse begins after N = 13 concurrent senders.
The discrepancy of 1 comes from the fact that
there is additional \buffer" on the network beyond
the packet buffer on the switch, e.g., packets in
fight or buffer at the sender machines. According
to this logic, good put collapse should take place
according to Equation 3. The equation accurately
predicts that for Figure 4, the good put collapse for
16KB, 32KB, and 64KB blocks begin at 13, 7, and
4 concurrent senders, and for Figure 3, the good
put collapse is well underway at 2 concurrent
senders.[5]
NinitialGoodputCollapse =
Per Sender Buffer
+ 1 (3)
largestSlowStartCwnd
This analysis also indicates why TCP fast
retransmit fails to prevent RTOs from taking place.
Fast retransmit requires three duplicate
acknowledgements to trigger. Table 1 shows that
packet loss likely occurs during the last or second
last round trips. Hence, connections with little
additional data to send after a packet loss would
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 358
ACK. Fast retransmit does not get triggered, and
the connection enters RTO soon after. Insight: For
small flows, the switch buffer space determines the
onset of in cast.
Second order effects
Figure 4 also suggests the presence of second order
effects not explained by Equations 1 to 3. Equation
3 predicts that good put collapse for 128KB blocks
should begin at N = 2 concurrent senders, while
the empirically observed good put collapse be-gins
at N = 4 concurrent senders. It turns out that block
sizes of 128KB represent a transition point from
RTO-during-slow-start to more complex modes of
behaviour.
We repeat the experiment for block Size = 128KB,
256KB, 512KB, and 1024KB. Figure 5 shows the
results, which includes several interesting effects.
First, for block Size = 512KB and 1024KB, the
good put immediately after the onset of in cast is
given by Equation 4. It differs from Equation 2 by
the multiplier for the RT O in the denominator.
This is an empirical constant, and represents
behaviour that we call partial RTO. What happens
is as follows. When RTO takes place, TCP SACK
(turned on by default in Linux) allows
transmission of further data, until the congestion
window can no longer advance due to the lost
packet. Hence, the link is idle for a duration of less
than the full RTO value. Hence we call this effect
partial RTO. For block Size = 1024KB, is 0.6, and
for block Size = 512KB, is 0.8.
Goodput
1024KB blocks, measured (Mbps) (3). (2). (1).
1000 512KB blocks, measured
800
256KB blocks, measured
128KB blocks, measured
600
1024KB blocks, modeled, 0.6x RTO
400
1024KB blocks, modeled, 1.0x RTO
512KB blocks, modeled, 0.8x RTO
200
512KB blocks, modeled, 1.5x RTO
0
256KB blocks, modeled, 1.0x RTO
128KB blocks, modeled, 1.0x RTO
0 8 16 24 32 40 48
Number of concurrent senders, N
Figure 5: 2nd order effects other than RTO during slow start. Measurements done on HP Procure
5412 switches (64KB per port). RT O is 200ms. Error bars represent 95% confidence interval
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 359 modelling in cast behaviour for large blocks, (2) transition between single and multiple partial
RTOs, and (3) gradual onset of in cast that is independent of block Size
blockSize
Goodputincast = N
RT O + RT T +
blockSize N linkBandwidth
(4)
Second, past a specific number of simultaneous senders, advances to something that around duplicates its underlying
quality (0.6 to 1.0 for block Size = 1024KB, 0.8 to 1.5 for block Size = 512KB). This just speaks to that two
incomplete RTOs have happened
Third, the good put fall for block Size = 256KB,
512KB, and 1024KB is more progressive
contrasted and the snap like conduct in Figure 4.
Futher, this continuous good put crumple has a
similar slant crosswise over various block Size.
Two variables clarify this conduct.[6] In the first
place, flows with block Size 128KB have
significantly more information to send even after
the buffer space is called with bundles sent amid
moderate begin (Equation.3 and Table.1). Second,
notwithstanding when the switch drops bundles,
TCP can here and there recoup. Observational
proof of this reality exists in Figure 4. There, for
block Size = 16KB and N = 13 to 16 simultaneous
senders, no less than one of five rehashed
estimations figures out how to get good put near
90% of connection limit, as reflected by the huge
blunder bars. Good put fall occurs for different
runs in light of the fact that the bundles are
dropped in a way that an association with minimal
extra information to send would watch just a
solitary or twofold copy ACK, and go into RTO
before long. Bigger squares suffer less from this
issue in light of the fact that the progressing
information exchanges triggers triple copy ACK
with higher likelihood. Along these lines, the
association retransmits, enters clog evasion, and
dodges RTO. Thus the steady good put fall.[7]
The restricted transmit system possibly addresses
the issue of single or twofold copy ACK took after
by RTO. The restricted transmit instrument sends
another information fragment because of each of
the first two copy affirmations that land at the
sender. Turning on this instrument conceivably
makes fake retransmission, since copy ACKs
could be caused by either bundle misfortunes or
parcel requesting. An estimation of parcel
re-requesting properties in Internet data centre
systems would illuminate the cost-benefit
tradeoffs.
We ought to likewise bring up that SACK
semantics are free of copy ACKs, since SACK is
layered over existing cumulative ACK semantics.
Understanding: Second request effects incorporate
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 360
fractional RTOs, and triple copy ACKs causing
more steady beginning of in cast. Sufficiently
good model
Shockingly, a few sections of the model stay
subjective. We concede that the full connection
between triple copy ACKs, moderate begin, and
accessible buffer space requires expand treatment a
long ways past the flow rate and buffer in
hesitance examination exhibited here (Equations 1
to 4).
All things considered, the models here speak to the
first time we quantitatively clarify real highlights
of the in cast good put crumple. Practically
identical outcomes in related work can be clarified
by our models too. The investigation enables us to
reason about the significance of in cast for future
substantial scale information driven workloads
later in the part.[8]
In cast in Hadoop Map Reduce
Hadoop speaks to an intriguing contextual
investigation of how in cast an affects application
level behaviour. System traffic in Hadoop
comprises of little flows conveying control bundles
for different group coordination conventions, and
bigger flows conveying the genuine information
being prepared. In cast possibly an affects Hadoop
in complex ways. Further, Hadoop may well veil
in cast conduct, since arrange information
exchanges shapes just a piece of the general
calculation and information flow. Our objective for
this area is to answer whether in cast an affects
Hadoop, by how much, and under what conditions.
We perform two arrangements of tests. In the first
place, we run remain solitary, artificial Hadoop
occupations to find out how much in cast impacts
every part of the Map Reduce information flow.[9]
Second, we replay a downsized, genuine
generation workload utilizing already distributed
apparatuses and group follows from Facebook, a
main Hadoop client, to comprehend the degree to
which in cast an affects entire workloads. These
examinations occur on the same DETER machines
as those the past area. We utilize just the huge
buffer Procure switch for these trials.
Stand-alone employments
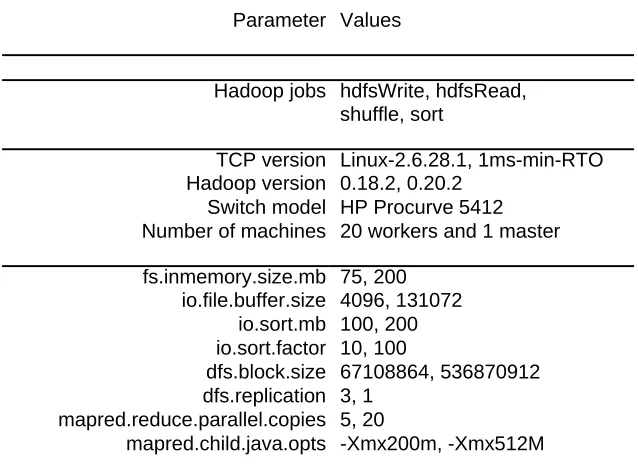
Table 2 records the Hadoop group settings we
considered. The genuine remain solitary Hadoop
occupations are hdfs Write, hdfsRead, rearrange,
and sort. The first three occupations push one a
player in the Hadoop IO pipeline at once. Sort
speaks to an occupation with 1-1-1 proportion
between read, shuffled, and composed information.
We actualize these occupations by altering the
random writer and random text writer illustrations
that are pre-bundled with late Hadoop
disseminations. We set the employments to
compose, read, shuffle, or sort 20GB of terasort
organize information on 20 machines.
Experiment setup
The TCP forms are the same as before { standard
Linux 2.6.28.1, and modified Linux 2.6.28.1 with
tcp rto min set to 1ms. We consider Hadoop
variants 0.18.2 and 0.20.2. Hadoop 0.18.2 is
viewed as a heritage and fundamental, yet at the
same time generally steady and develop
conveyance. Hadoop 0.20.2 is an all the more
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 361
some execution overhead for little occupations.
Resulting Hadoop upgrades have appeared on a
few disjoint branches that are at present being
blended, and 0.20.2 speaks to the last time there
was a solitary mainline Hadoop conveyance.
The rest of the parameters are detailed Hadoop
configuration settings. Tuning these parameters
can considerably improve performance, but
requires specialist knowledge about the interaction
between Hadoop and the cluster environment. The
first value for each configuration parameter in
Table 2 represents the default setting. The
remaining values are tuned values, drawn from a
combination of Hadoop sort benchmarking [10],
suggestions from enterprise Hadoop vendors, and
our own experiences tuning Hadoop for
performance. One configuration worth further
explaining is dfs. replication. It controls the degree
of data replication in HDFS. The default setting is
three-fold data replication to achieve fault
tolerance. For use cases constrained by storage
capacity, the preferred method is to use HDFS
RAID, which achieves fault tolerance with 1.4
overhead, much closer to the ideal one-fold
replication.
Parameter Values
Hadoop jobs hdfsWrite, hdfsRead, shuffle, sort
TCP version Linux-2.6.28.1, 1ms-min-RTO Hadoop version 0.18.2, 0.20.2
Switch model HP Procurve 5412 Number of machines 20 workers and 1 master
fs.inmemory.size.mb 75, 200 io.file.buffer.size 4096, 131072
io.sort.mb 100, 200 io.sort.factor 10, 100
dfs.block.size 67108864, 536870912 dfs.replication 3, 1
mapred.reduce.parallel.copies 5, 20
mapred.child.java.opts -Xmx200m, -Xmx512M
Table 2: Hadoop parameter values for experiments with stand-alone jobs. The map red. child. java.
opts parameter sets the maximum virtual memory of the Java child pro-cesses to 200MB and
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 362
Figure 6 shows the results for Hadoop 0.18.2. We
consider two performance metrics job completion
time, and in cast overhead. We de ne in cast
overhead according to Equation 5, i.e., difference
between job completion time under default and
1ms-min-RTO TCP, normalized by the job
completion time for 1ms-min-RTO TCP. The
default Hadoop has very high in cast overhead,
while for tuned Hadoop, the in cast overhead is
barely visible. However, the tuned Hadoop-0.18.2
setting leads to considerably lower job completion
times.
t = jobCompletionT ime
IncastOverhead = tdefaultT CP t1ms min RT O (7.5)
t1ms min RT O
The results illustrate a subtle form of Amdahl's
Law, which explains overall improvement to a
system when only a part of the system is being
improved. Here, the amount of Incast Overhead
depends on how much network data transfers
contribute to the overall job completion time. The
default Hadoop configurations lead to network
transfers contributing to a large fraction of the
overall job completion time.[11] Thus, in cast
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 363
default TCP
1ms min RTO
default TCP 1ms min RTO
Time (s) Time (s)
600 600 500 500
400 400
300 300
200 200 100 100
0 0 hdfsWrite hdfsRead shuffle sort hdfsWrite hdfsRead shuffle sort
Incast overhead Incast overhead
1.0 1.0
0.8
0.8
0.6
0.6
0.4
0.4
0.2
0.2
0.0 0.0
hdfsWrite hdfsRead shuffle sort hdfsWrite hdfsRead shuffle sort
Default Hadoop 0.18.2
Tuned Hadoop 0.18.2
Figure 6: Hadoop stand alone job completion times. HP Procurve 5412 switches. Showing job
completion times (top) and overhead introduced by incast (bottom) for default Hadoop-0.18.2 (left),
and tuned Hadoop-0.18.2 (right). The error bars show 95% confidence intervals from 20 repeated
measurements. The tuned Hadoop-0.18.2 leads to considerably lower job completion times. The
default Hadoop has higher in cast overhead
On the other hand, for tuned Hadoop, general
employment fulfilment time is as of now low. In
cast overhead is scarcely obvious in light of the
fact that the system exchange time is low. We
rehash these estimations on Hadoop 0.20.2.
Contrasted and Hadoop 0.18.2, the later form of
Hadoop sees an execution change for the default
setup. For the advanced arrangement, Hadoop
0.20.2 sees execution overhead of around 10
seconds for every one of the four occupation
writes. This outcome is in accordance with our
earlier examinations between Hadoop renditions
0.18.2 and 0.20.2. Lamentably, 10 seconds is
likewise the execution change for utilizing TCP
with 1ms-min-RTO. Consequently, the execution
overhead in Hadoop 0.20.2 covers the advantages
of tending to in cast.[12]
Knowledge: In cast affects Hadoop. The execution
affect relies upon bunch designs, and also
information and register designs in the workload.
Real life creation workloads
The outcomes in the above subsection show that to
find out how much in cast extremely an effects
Hadoop, we should analyze the default and
1ms-min-RTO TCP while replaying genuine creation
workloads. Before hand, such assessment
capacities are restrictive to ventures that run
extensive scale creation bunches. Late years have
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 364
open learning about bleeding edge creation
workloads, and also rising devices to replay such
workloads without generation information, code,
and equipment.
Workload examination
We got seven creation Hadoop workload follows
from five organizations in long range informal
communication, web based business, broadcast
communications, and retail. Among these
organizations,[13,14] just Facebook has so far
enabled us to discharge their name and engineered
forms of their workload. The accompanying
present some synopsis measurements of the more
itemized examination.
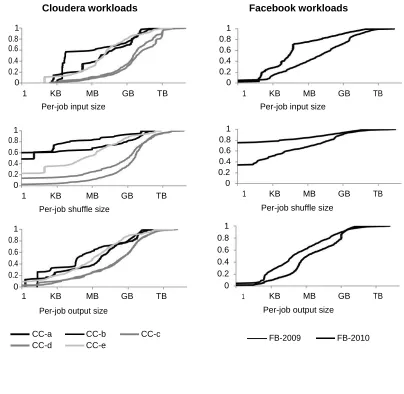
A few perceptions are particularly applicable to in
cast. Consider Figure 7, imitated from Figure 2,
which demonstrates the dispersion of per work
input, shuffle, and yield information for all
workloads. To begin with, all workloads are
commanded by occupations that include
information sizes of under 1GB. For employments
so little, planning and coordination overhead
command work finish time. Along these lines, in
cast will make a difference just if the workload
force is sufficiently high that Hadoop control
parcels alone would overpower the system.
Second, all workloads contain occupations at the
10s TB or even 100s TB scale. This urges the
administrators to utilize Hadoop 0.20.2. This form
of Hadoop is the first to consolidate the Hadoop
reasonable scheduler. Without it, the little
employments touching base behind substantial
occupations would see FIFO head-of-line
blocking, and suffer hold up times of hours or even
days. This element is critical to the point that
bunch administrators utilize it in spite of the
execution overhead for little employments.
Consequently, it is likely that in Hadoop 0.20.2, in
cast will be covered by the execution overhead.
Workload replay
We replay a day-long Facebook 2009 workload on
the default and 1ms-min-RTO variants of TCP. We
combine this workload utilizing the strategy. It
catches, in a generally short manufactured
workload, the agent work accommodation and
calculation designs for the whole half year follow.
Our estimations confirm the theory prior. Figure
7.8 demonstrates the appropriation of occupation
consummation times. We see that the
appropriation for 1ms-min-RTO is 10{20 seconds
right moved contrasted and the dispersion for
default TCP. This is in accordance with the 10{20
seconds overhead we found in the workload-level
estimations in, and also the remain solitary
employment estimations prior in the paper. The
benefits of tending to in cast are totally covered by
overhead from different parts of the
framework.[15]
We should highlight that the distribution of job
durations is longer for the 1ms-min-RTO TCP.
This result potentially shows the performance cost
of spurious RTOs. Spurious RTOs arise from
setting minimum RTO too low, which cause the
TCP sender to retransmit a packet that is delayed
but not lost. We could verify whether this is indeed
the case by looking at TCP packet level traces.
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 365
interferes network performance. Better tracing
infrastructure should be explored.
Figure 7: Per job input, shuffle, and output size for each workload. FB-* workloads come from
a six-months cluster trace in 2009 and a 45-days trace in 2010. CC-* workloads come from
traces of up to 2 months long at various customers of Cloudera, which is a vendor of enterprise
Hadoop
Cloudera workloads Facebook workloads
1
j o b s
0.8 0.6
o f
0.4
F r a c t i o n
0.2 0
1 KB MB GB TB
Per-job input size
1
j o b s
0.8 0.6
o f
F r a c t i o n
0.4 0.2 0
1 KB MB GB TB
Per-job shuffle size
1
j o b s
0.8 0.6
o f
F r a c t i o n
0.4 0.2 0
1 KB MB GB TB
Per-job output size
CC-a CC-b CC-c
CC-d CC-e
1 0.8 0.6 0.4 0.2 0
1 KB MB GB TB
Per-job input size
1 0.8 0.6 0.4 0.2 0
1 KB MB GB TB
Per-job shuffle size
1 0.8 0.6 0.4 0.2 0
1 KB MB GB TB
Per-job output size
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 366
Figure 9 offers another perspective on workload
level behaviour. The graphs show two sequences
of 100 jobs, ordered by submission time, i.e., we
take snapshots of two continuous sequences of 100
jobs out of the total 6000+ jobs in a day. These
graphs indicate the behaviour complexity once we
look at the entire workload of thousands of jobs
and diverse interactions between concurrently
running jobs. The 10{20 seconds performance
difference on small jobs becomes insignificant
noise in the baseline. The few large jobs take
significantly longer than the small jobs, and stand
out visibly from the baseline. For these jobs, there
are no clear patterns to the performance of
1ms-min-RTO versus standard TCP.
The Hadoop community is aware of the
performance overheads in Hadoop 0.20.2 for small
jobs. Subsequent versions partially address these
concerns. It would be worthwhile to repeat these
experiments once the various active Hadoop code
branches merge back into the next mainline
Hadoop.
Insight: Small jobs dominate several production
Hadoop workloads. Non-network overhead in
present Hadoop versions mask in cast behaviour
for these jobs.
Fraction of jobs
1
0.8
0.6 1ms-min-RTO TCP
0.4 default TCP
0.2
0
0 60 120 180 240 300
Completion time (sec)
Figure 8: Distribution of job completion times for the FB-2009 workload. The distribution for
1ms-min-RTO is 10{20 seconds right shifted compared with the distribution for default TCP
In cast for Future Large-Scale
Data-Centric Workloads
Hadoop is a case of the rising class of vast scale
information driven figuring ideal models, which
quite often include some measure of system
correspondences. To see how in cast an affects
future vast scale information driven workloads,
one needs to value the innovation inclines that
drives the rising unmistakable quality of such
frameworks, the computational requests that
outcome, the incalculable outline and mis-plan
openings, and additionally the main drivers of in
cast.
As examined in the best innovation patterns
driving the unmistakable quality of huge scale
information driven incorporate progressively
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 367
stockpiling and calculation foundation, universal
capacity to create, gather, and file information
about both innovation frameworks and the physical
world, and developing want and measurable
proficiency crosswise over numerous ventures to
comprehend and get an incentive from substantial
datasets.
A few information investigation patterns rise,
confirmed by the group administrators who gave
the follows in Figure 7 and talked about in detail:
1. There is expanding want to do intelligent
information investigation, and in addition gushing
examination. The objective is to have human with
non-master aptitudes investigate differing and
advancing information sources, and once they find
an approach to remove significant bits of
knowledge, such bits of knowledge ought to be
refreshed in view of approaching information in a
convenient and persistent form.
2. Bringing such information investigative
ability to non-authorities requires abnormal state
computation systems based over regular stages, for
example, Map Reduce. Illustrations of such
systems in the Hadoop Map Reduce biological
community incorporate HBase, Hive, Pig, Sqoop,
Oozie, and others.
3. Data sizes become quicker than the reduction
in the unit cost of capacity and calculation
framework. Thus, efficiently utilizing capacity and
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 368
default TCP 1ms-min-RTO
360
240
120
0
0 20 40 60 80 100
Job index
900
600
300
0
4620 4640 4660 4680 4700 4720
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 369 Figure 9: Sequences of job completion times. Showing two continuous job sequences of 100 jobs.
The few large jobs have long completion times, and stand out from the baseline of continuous
stream of small jobs
In cast plays into these patterns as takes after. The
want for intuitive and spilling investigation requires
exceptionally responsive frameworks. The
information measure required for these calculations
are little contrasted and those required for
calculations on recorded information. We realize
that when in cast happens, the RTO punishment is
particularly serious for little flows. Applications
would be possibly compelled to either postpone the
investigation reaction, or give answers in light of
fractional information. Therefore, in cast could
develop as a hindrance for top notch intelligent and
spilling investigation.
The want to have non-authorities utilize extensive
scale information driven frameworks propose that
usefulness and ease of use ought to be the best plan
needs. In cast an effects execution, which can be
deciphered as a sort of convenience. It turns into a
need simply after we have an utilitarian framework.
Additionally, as our Hadoop tests illustrate,
execution tuning for multi-layered programming
stacks would need to go up against various layers
of unpredictability and overhead.
The requirement for capacity limit efficiency
involves putting away packed information,
performing information de-duplication, or utilizing
RAID rather than information replication to
accomplish adaptation to internal failure. In such
conditions, memory territory turns into the best
concern, and plate or system area winds up
auxiliary. In the event that the workload qualities
allows an abnormal state of memory or plate area,
organize traffic gets diminished, the application
execution increments, and in cast turns out to be to
a lesser extent a worry.
The requirement for computational efficiency
suggests that processing foundation should be all
the more profoundly used. System requests will
accordingly increment. Merging various
applications and workloads multiplexes numerous
system traffic designs. In cast will probably happen
with more noteworthy recurrence. Further, extra
TCP pathologies might be uncovered, for example,
the likewise expressed TCP untouchable issue. This
issue includes a solitary yield port conglomerating
flows from numerous info ports, with a different
number of flows from each information port
(versus the traffic design for in cast where the yield
port totals a solitary flow from each information
port), and results in connect share injustice for
substantial flows.
Recommendations and Conclusions
Set TCP least RTO to 1ms.
Future extensive scale information driven
workloads likely uncover TCP pathologies other
than in cast. In cast and comparable conduct are on
a very basic level transport-level issues. It isn't
asset effective to update the whole TCP
convention, overhaul switches, or supplant the data
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 370
rto min is a configuration parameter change {low
overhead, instantly deployable, and, as we trust our
trials appear, it does no damage inside the data
centre.
Send better following framework
It isn't yet clear how much in cast impacts future
substantial scale information driven workloads.
This section talks about a few contributing
elements. We require additional data connecting
application-level execution to organize bundle level
conduct to figure out which factors rule under what
conditions. Better following helps evacuate the
vulnerability. Where conceivable, such bits of
knowledge ought to be imparted to the general
group. We trust the workload correlations in this
part energize comparative, cross-hierarchical e orts
somewhere else.
Apply a scientific configuration process
Future substantial scale information driven
frameworks request a takeoff from configuration
approaches that accentuate usage over estimation
and approval. The intricacy, decent variety, scale,
and fast advancement of such frameworks suggest
that mis-outline openings multiply, upgrade costs
increment, encounters quickly end up out of date,
and instincts turn out to be difficult to create. Our
approach in this part includes performing
simplified tests, creating models in view of first
standards, experimentally approving these models,
at that point interfacing the experiences to genuine
by presenting expanding levels of unpredictability.
Our encounters handling the in cast issue show the
estimation of a plan procedure established in
observational estimation and assessment.
References
[1] D. Ferrari. Computer Systems Performance
Evaluation. Prentice-Hall, 1978.
[2] D. Ferrari. Characterizing a workload for the
comparison of interactive services. Managing
Requirements Knowledge, International Workshop
on, 0, 1979.
[3] S. Floyd and V. Paxson. Difficulties in
simulating the internet. IEEE/ACM Trans. Netw.,
9(4):392{403, Aug. 2001.
[4] A. Ganapathi, Y. Chen, A. Fox, R. Katz, and D.
Patterson. Statistics-driven workload modelling for
the cloud. In ICDE Workshops 2010.
[5] S. Ghemawat, H. Gobio , and S.-T. Leung. The
Google le system. SIGOPS Oper. Syst. Rev.,
37(5):29{43, 2003.
[6] J. Gray et al. Quickly generating billion-record
synthetic databases. In SIGMOD 1994.
[7] A. Greenberg, J. R. Hamilton, N. Jain, S.
Kandula, C. Kim, P. Lahiri, D. A. Maltz,
[8] Patel, and S. Sengupta. Vl2: a scalable and
exible data centre network. In SIGCOMM 2009.
[9] The gzip algorithm.
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 371
[10] J. Hamilton. Overall Data Centre Costs.
http://perspectives.mvdirona.com/
2010/09/18/OverallDataCenterCosts.aspx, 2010.
[11] J. Hellerstein. Quantitative data cleaning for
large databases. Technical report, United Nations
Economic Commission for Europe, February 2008.
[12] Hewlett-Packard Corp., Intel Corp., Microsoft
Corp., Phoenix Technologies Ltd., Toshiba Corp.
Advanced Configuration and Power Interface 5.0.
http://www. acpi.info/.
[13] B. Hindman, A. Konwinski, M. Zaharia, A.
Ghodsi, A. D. Joseph, R. Katz,
[14] Shenker, and I. Stoica. Mesos: A platform for
ne-grained resource sharing in the data centre. In
NSDI 2011.
[15] B. Hindman, A. Konwinski, M. Zaharia, A.
Ghodsi, A. D. Joseph, S. Shenker, and Stoica.
Nexus: A common substrate for cluster computing.
Hot Cloud 2009: Workshop on Hot Topics in